
基于Python比较不同学习算法(贝叶斯、神经网络、决策树)建立模型的准确率【100010173】
数据挖掘期末大作业
研究内容
根据数据进行分类模型的构建
要求:
- 用python实现学习算法
- 至少实现2-3种不同类型的学习算法(贝叶斯、神经网络、决策树等)
- 要求比较和分析通过不同学习算法建立的模型的准确率
- 数据自行查找合适的数据源,但不得少于1000条
研究环境
系统环境: Windows 10 学生版
语言环境: Python 3.7
IDE: PyCharm
研究过程
数据选择
数据选取: Kaggle的San Francisco Crime Classification
数据链接: https://www.kaggle.com/c/sf-crime/data
数据预处理
1.查看数据

总共有87w+的数据,9列属性,Category是我们的标签属性。
‘Dates’:犯罪日期时间
‘Category’:犯罪类型
‘Descript’:犯罪描述
‘DayOfWeek’:犯罪时间星期几 ‘PdDistrict’:犯罪地区
‘Resolution’:犯罪后的处理
‘Address’:犯罪地址
‘X’ ‘Y’ :犯罪地址坐标
2.数据分析
随机抽取1200条数据作为训练集,在训练集里抽取200条作为测试集。
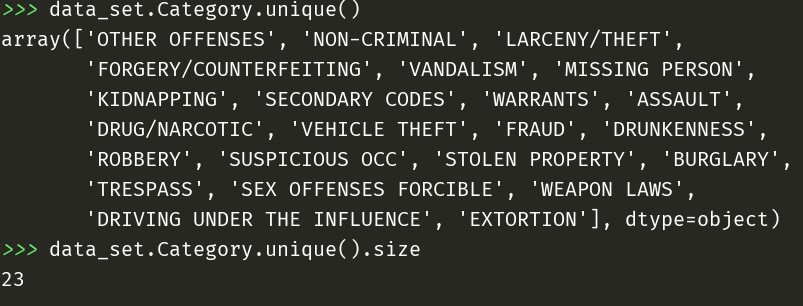
标签集有23种
根据观察,最终决定取‘Dates’,‘PdDistrict’,‘DayOfWeek’作为条件属性
Dates的格式是 2014-11-27 22:14:00,但是我们取hour作为研究属性
可知分布也在0-23点之间

PdDistrict不同地区也达到了10个

DayOfWeek星期也达到了7个
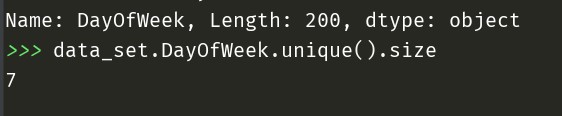
说明这些属性作为条件数据可靠。
3.特征处理
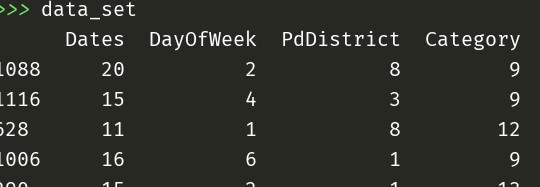
考虑到作为属性都不是数字,为了方便处理,把条件根据属性值的不同转化为数字。
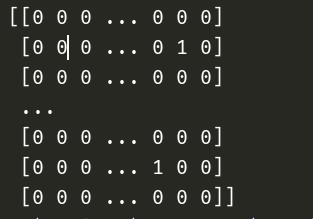
对于神经网络分类算法,需要对标签进行二进制矩阵化
算法实现
朴素贝叶斯实现
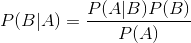
根据朴素贝叶斯公式,
要求P(Category=?| Dates,DayOfWeek,PdDistrict)则可以求 P( Dates,DayOfWeek,PdDistrict | Category=?) * P( Category = ? ) / P(Dates,DayOfWeek,PdDistrict)
由于我们要通过此算法模拟分类,所以我们进行比较只需要计算分子部分即可。
对此,实现算法我们只需要通过已知的的训练集,计算出所有P( Dates,DayOfWeek,PdDistrict | Category=?)与P(Category = ?),在测试时,计算每一类的最终概率值,就能比较得出哪一类概率最大。
Class Bayes:
calc_p_y(self,column_y_val):
calc_p_x_y(self,column_x_val,column_y_val):
set_test_x(self,Dates,DayOfWeek,PdDistrict):
predict_one(self,column_x_val):
predict_all(self,test_set):
方法实现:
calc_p_y
传入Category类别值,通过遍历训练集统计count值,最终计算返回占比率
calc_p_x_y
传入数据集条件与类别值,遍历数据集该类别下各条件的比例,并进行相乘,最终计算返回占比率
set_test_x
传入预测条件,返回列表形式
predict_one
传入列表形式的条件,计算每一类的最终概率,最终得出概率最大的类别。
predict_all 传入测试集,循环进行predict_one方法,最终返回正确率。
决策树分类实现
根据决策树分类原理的信息增益熵来按次序分类,通过Gain(S,A)作为信息增益熵。


决策树分类是通过sklearn库的方法调用实现。模拟完成后,输出准确率,生成决策树文件,需要通过GvEdit软件打开。
神经网络实现
Class NeuralNetwork:
__init__(self,neuron_list):
fit(self, X, y, learning_rate=0.2, epochs=10000):
predict_one(self, x):
predict_all(self,test_x,test_y):
方法实现:
__init__
初始化模型,neuron_list作为神经元列表传入模型,将权值全部随机赋值。
fit
训练函数,将学习速率,更新最大次数,训练集和标签集作为输入,随机选取训练集某一行,对网
络进行更新,进行正向更新,之后计算权重后,通过随机梯度函数进行反向更新权值。
predict_one
根据传入训练集的一项,预测标签类别。
predict_all
一次性预测整个训练集,并输出混淆矩阵和分类情况。
结果对比
| 朴素贝叶斯 | 决策树 | 神经网络 | |
|---|---|---|---|
| 准确率 | 0.3 | 0.07 | 0.08-0.20 |
结果分析
-
朴素贝叶斯由于数据较多,表现较好;
-
而决策树条件太多24710=1680个分类节点,使得决策树过于肿胀,导致准确率很低。
-
神经网络稳定性不高,很可能是它是局部最优搜索方法,很可能会陷入局部极值,使训练失败,条件太多,可能会出现“过拟合”的现象。
结论
各分类算法各有各的优点,对于贝叶斯实现简单,数据越多,可能表现越好,越准确,但是仅仅在各条件之间相互独立,这个情况在实际应用中往往不成立,随着属性的增多,分类效果会下降。
对于决策树分类算法,前期的数据预处理很重要,如果标签类太多,条件太多,决策树可能会变得很庞大,加入旧的数据效果可能不错,但当加入一个全新的数据,决策树分类效果可能会下降。
对于神经网络分类算法,其能够自适应学习,是现在比较火的学习方法,但是在实际应用中学习成本较高,并且容易被无关数据干扰。
研究总结
这次作业主要研究了三种分类算法,其中朴素贝叶斯分类算法是最容易实现的算法,而神经网络和决策树分类算法花了较长时间实现,可能是对算法理解还不是吃的很透。
♻️ 资源

大小: 815KB
➡️ 资源下载:https://download.csdn.net/download/s1t16/87302114
相关文章
- 【Python成长之路】python 基础篇 -- global/nonlocal关键字使用
- 快速排序算法回顾 (Python实现)
- Python实现的寻找前5个默尼森数算法示例
- 机器学习之决策树(ID3)算法与Python实现
- 机器学习之决策树(ID3)算法与Python实现
- 小姐姐带你一起学:如何用Python实现7种机器学习算法(附代码)
- 机器学习10种经典算法的Python实现
- 【python cookbook】【数据结构与算法】19.同时对数据做转换和换算
- 【python cookbook】【数据结构与算法】15.根据字段将记录分组
- Python语言学习:利用python获取当前/上级/上上级目录路径(获取路径下的最后叶目录的文件名、合并两个不同路径下图片文件名等目录/路径案例、正确加载图片路径)之详细攻略
- Python编程语言学习:python的列表的特殊应用之一行命令实现if判断中的两类判断
- Python编程语言学习:python编程语言中重要函数讲解之map函数等简介、使用方法之详细攻略
- Python语言编程学习:利用python输出当前python版本、MSC版本型号
- Python语言学习之打印输出那些事:python输出图表和各种吊炸天的字符串或图画、版权声明(如README.md)等之详细攻略
- Python语言学习:基于python五种方法实现使用某函数名【func_01】的字符串格式('func_01')来调用该函数【func_01】执行功能
- Python语言学习之图表可视化:python语言中可视化工具包的简介、安装、使用方法、经典案例之详细攻略
- 已解决2.Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and wi
- 从零开始学习python | 实例讲解如何制作Python模式程序
- 【阶段三】Python机器学习29篇:机器学习项目实战:DBSCAN算法的基本原理与DBCSAN新闻聚类分群模型
- 【阶段三】Python机器学习28篇:机器学习项目实战:KMeans算法的基本原理与KMeans聚类分群模型
- 【阶段三】Python机器学习25篇:机器学习项目实战:LigthGBM算法的核心思想、原理与LightGBM分类模型
- Python实现LDA和SVM支持向量机人脸识别模型(LinearDiscriminantAnalysis和SVC算法)并通过网格搜索算法寻找最优参数值项目实战
- Python实现KNN(K近邻)回归模型(KNeighborsRegressor算法)并应用网格搜索算法寻找最优参数值项目实战
- python基础===jieba模块,Python 中文分词组件
- python中5个json库的速度对比
- 基于改进粒子群优化算法的柔性车间调度问题(Python代码实现)
- Winograd算法的python实现