
Python实现KNN(K近邻)回归模型(KNeighborsRegressor算法)并应用网格搜索算法寻找最优参数值项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。
1.项目背景
K近邻算法回归模型则将离待预测样本点最近的K个训练样本点的平均值进行待预测样本点的回归预测。
K近邻除了能进行分类分析,还能进行回归分析,即预测连续变量,此时的KNN称为K近邻回归模型。回归问题是一类预测连续值的问题,而能满足这样要求的数学模型称作回归模型,本项目应用K近邻回归模型进行探索新冠疫情、原材料、人工、物流等因素对零部件价格的影响。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
数据详情如下(部分展示):
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:
关键代码:
3.2 数据缺失查看
使用Pandas工具的info()方法查看数据信息:
从上图可以看到,总共有9个变量,数据中无缺失值,共101条数据。
关键代码:
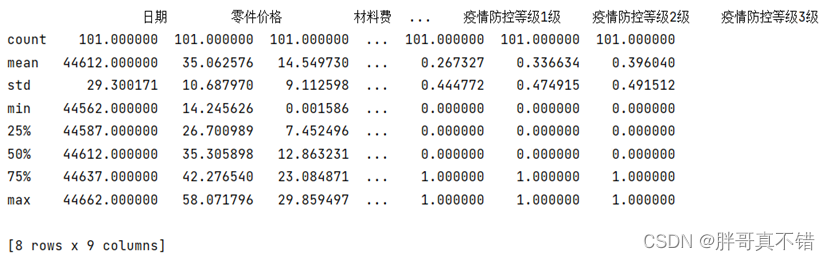
3.3 数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
关键代码如下:

4.探索性数据分析
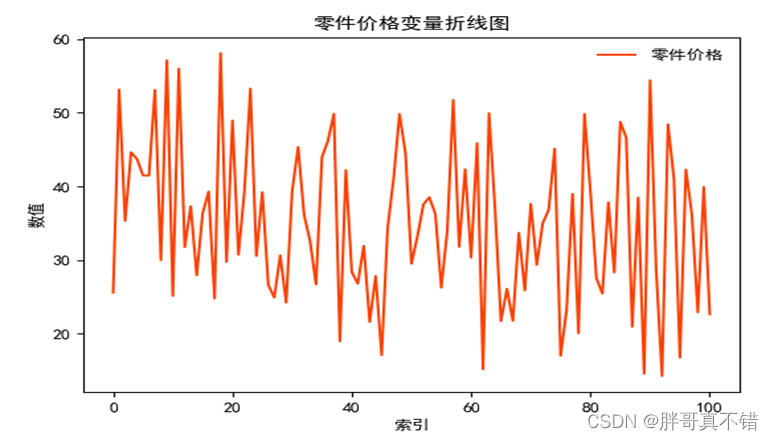
4.1 零件价格变量的折线图
用Matplotlib工具的plot()方法绘制折线图:
从上图可以看到,零部件价格整体在20到60之间波动。
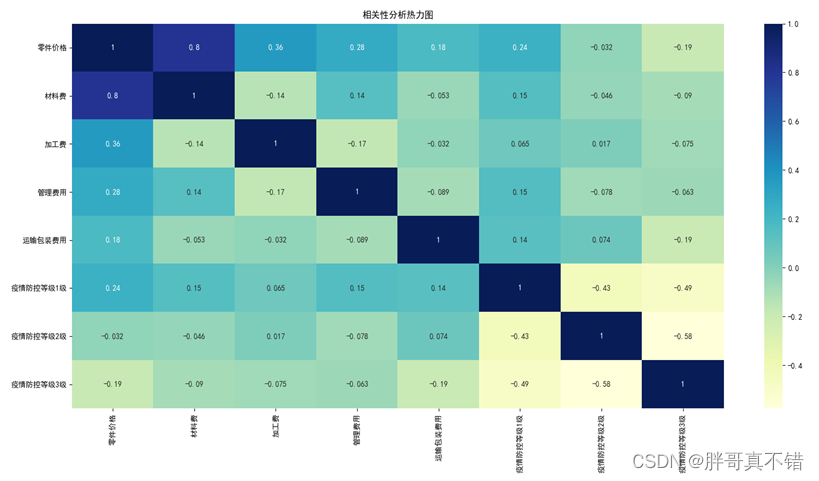
4.2 相关性分析
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
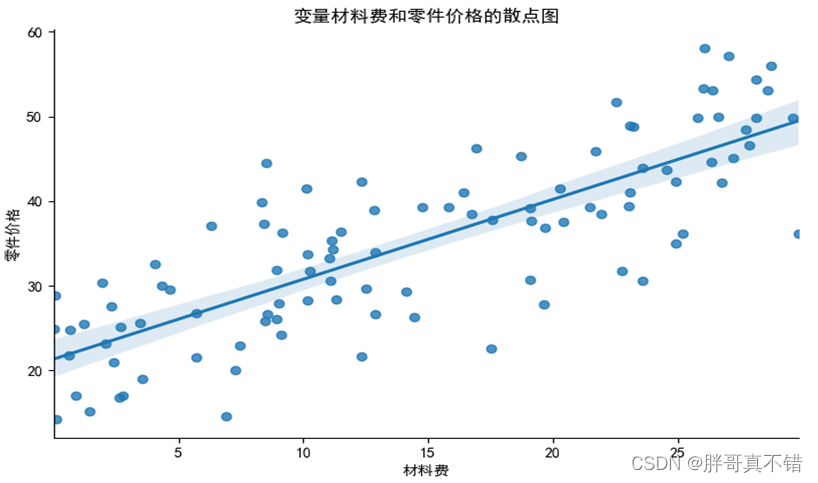
4.3 数据散点图
用seaborn工具的lmplot()方法绘制散点图:
从上图中可以看到,材料费变量和零售价格变量成线性相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:
5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:
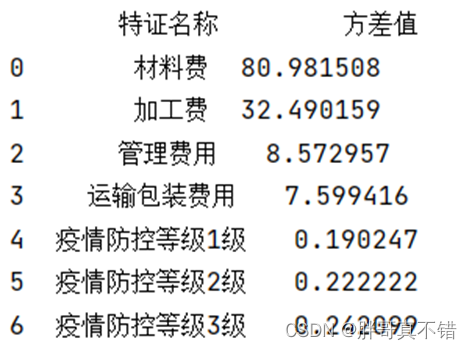
5.3 低方差特征选择
从上图可以看出,疫情防控等级1级为0.19低于阈值0.21,即可将此特征删除。
5.4 数据标准化
关键代码如下:
6.构建KNN回归模型
主要使用KNeighborsRegressor算法和网格搜索优化算法,用于目标回归。
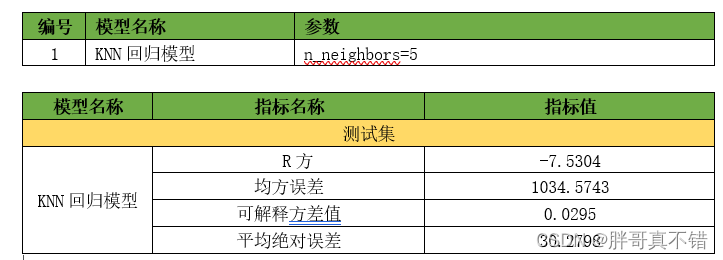
6.1默认参数构建模型
6.2 通过网格搜索寻找最优参数值
关键代码:
最优参数:
6.3 最优参数值构建模型
7.模型评估
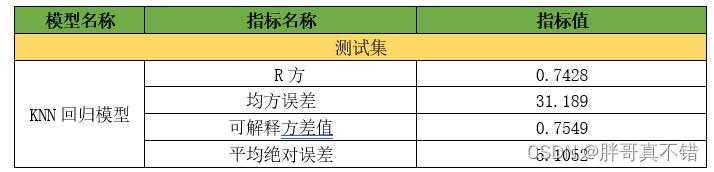
7.1评估指标及结果
评估指标主要包括可解释方差值、平均绝对误差、均方误差、R方值等等。
从上表可以看出,R方为0. 7428较默认参数优有较大的提升;可解释方差值为0. 7549较默认参数优较大的提升,优化后的回归模型效果良好。
关键代码如下:
7.2 真实值与预测值对比图
从上图可以看出真实值和预测值波动基本一致,模型拟合效果良好。
8.结论与展望
综上所述,本文采用了KNN回归算法来构建回归模型,通过网格搜索算法找到最优的参数值,最终证明了我们提出的模型效果很好,可用于实际生产中进行预测,使企业发展得更好,利润更多。












本次机器学习项目实战所需的资料,项目资源如下:
项目说明:
链接:https://pan.baidu.com/s/1dW3S1a6KGdUHK90W-lmA4w
提取码:bcbp
相关文章
- pycharm怎么导包_python自动到包快捷键
- python读取txt文件中的json数据
- python实现RSA算法
- Python算法-汉诺塔
- python全局变量赋值_Python全局变量和局部变量[通俗易懂]
- Python 技巧篇-pip卸载python库实例演示,查看pip命令大全方法[通俗易懂]
- 遗传算法的应用实例python实现_遗传算法Python解决一个问题
- python语言关键字是_Python 关键字
- 粒子群优化算法python程序_粒子群算法的具体应用
- python分段线性插值_Python实现分段线性插值
- a算法求解八数码问题_a*算法解决八数码问题python
- 【干货书】Python强化学习算法:学习、理解和开发智能算法以应对人工智能挑战
- python_day09_作业详解编程语言
- Linux系统如何运行Python脚本(linux执行python脚本)
- python中*和**的打包和解包详解编程语言
- Linux环境下安装Python(linux装python)
- python中正则表达式的使用详解
- kNN算法python实现和简单数字识别的方法
- python使用心得之获得github代码库列表
- python实现在pickling的时候压缩的方法