
【阶段三】Python机器学习28篇:机器学习项目实战:KMeans算法的基本原理与KMeans聚类分群模型
2023-09-14 09:06:13 时间
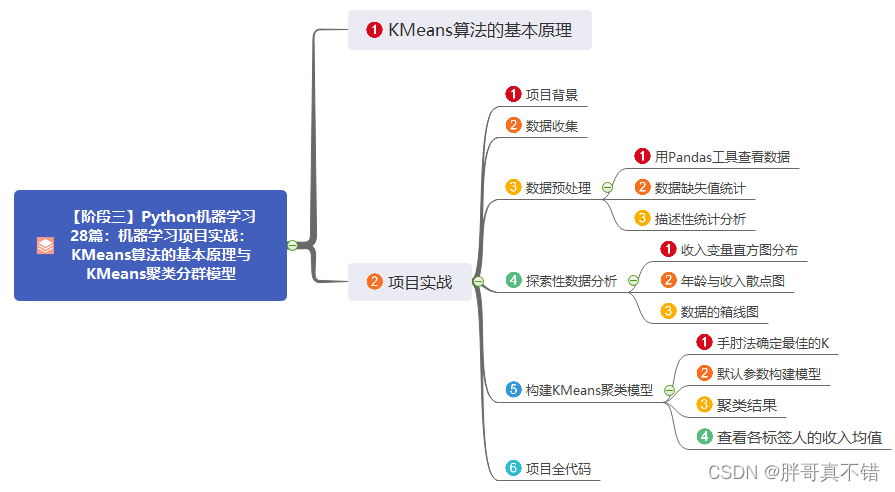
本篇的思维导图:
KMeans模型
KMeans算法的基本原理
KMeans算法名称中的K代表类别数量,Means代表每个类别内样本的均值,所以KMeans算法又称为K-均值算法。KMeans算法以距离作为样本间相似度的度量标准,将距离相近的样本分配至同一个类别。样本间距离的计算方式可以是欧氏距离、曼哈顿距离、余弦相似度等,KMeans算法通常采用欧氏距离来度量各样本间的距离。
KMeans算法的核心思想是对每个样本点计算到各个中心点的距离,并将该样本点分配给距离最近的中心点代表的类别,一次迭代完成后,根据聚类结果更新每个类别的中心点,然后重复之前操作再次迭代,直到前后两次分类结果没有差别。如下图所示的简单案例解释了KMeans算法的原理,该案例的目的是将8个样本点聚成3个类别(K=3)。
相关文章
- Python攻防-暴力激活成功教程附近局域网WIFI密码「建议收藏」
- 快速入门Python机器学习(33)
- python求逆矩阵的方法,Python 如何求矩阵的逆「建议收藏」
- python识别文字位置_如何利用Python识别图片中的文字
- Python入门系列(十一)一篇搞定python操作MySQL数据库
- python的sorted函数
- 符合python命名规范的标识符是什么_Python标识符命名规范
- 【说站】python使用字节处理文件
- 【说站】python缩进和空格的好处
- python调用通达信公式_通达信公式-主力雷达Python化[通俗易懂]
- python自定义异常的简单使用
- python win32api sendmessage_Python win32api.SendMessage方法代码示例[通俗易懂]
- python设置时间过期改变状态_Python Redis设置过期时间「建议收藏」
- python入门
- Python用逻辑回归、决策树、SVM、XGBoost 算法机器学习预测用户信贷行为数据分析报告
- 【Python】字符串 ④ ( Python 浮点数精度控制 | 控制数字的宽度和精度 )
- python 定义异常类
- python-Python与MongoDB数据库-使用Python执行MongoDB查询(二)
- python-Python与PostgreSQL数据库-使用Python执行PostgreSQL查询(一)
- python获得本机机器名详解编程语言
- 一份不可多得的数据科学与机器学习Python库
- 如何在Linux中安装Python?(linux安装python)
- Python爬取MySQL数据,助力数据分析(python读取mysql数据)
- python基础入门详解(文件输入/输出内建类型字典操作使用方法)
- 从零学Python之入门(五)缩进和选择
- python在windows下实现备份程序实例
- python实现通过shelve修改对象实例