
Redis_01_Redis的引入
文章目录
一、前言
二、Redis概要
2.1 关系型数据库和非关系型数据库
redis引入,什么是redis?
Redis 是一个开源的、使用ANSI C编写的、支持网络、基于内存的、可持久化的Key-Value 型的数据库,通过提供多种键值数据类型(5种基本数据类型 string hash list set sortedset)来适应不同场景下的存储需求,并且提供多种语言的API(当然包括Java语言的API)。redis官网如图:

理清几个易混淆的概念
SQL:全称为Structured Query Language,译为结构化查询语言,是一种计算机程序语言,一种解释型语言。
NoSQL:全称Not Only SQL,译为"不仅仅是SQL"(注意,NoSQL不是不使用SQL的意思),泛指所有的非关系型数据库。
关系型数据库:即RDB,全称为Relational Database,其实,一个更加常见的英文简称是RDBMS,Relational Database Management System,关系型数据库管理系统,所以,RDBMS就被认为是关系型数据库的简称。
非关系型数据库:不使用数据库表结构存储数据,用NoSQL表示。
相互对比辨析相近概念
(1) SQL与关系型数据库:SQL是SQL,关系型数据库是关系型数据库,两者是完全不同的两个东西,SQL是一种解释型语言,关系型数据库是数据库的一种类型,两者的关系是关系型数据库的CRUD操作使用SQL语言来完成,SQL语言被认为是关系型数据库的一种特征。
(2) NoSQL与非关系型数据库:对于程序员的工作中,NoSQL就是指非关系型数据库,即NoSQL==非关系型数据库,两者是同一个东西。
(3) SQL与NoSQL:SQL是一种语言,NoSQL表示非关系型数据库,一个是语言,一个是数据库,两个不同关系。
关系型数据库与非关系型数据库,如下表:
| 关系型数据库RDBMS | 非关系型数据库NoSQL | |
|---|---|---|
| 存储格式支持 | 数据库表结构 | 不使用数据库表结构存储,包括列存储、文档存储、key-value存储、图存储、对象存储、xml存储 |
| 特点 | 高度组织化结构化数据; 结构化查询语言(SQL); 数据和关系都存储在单独的表中; 数据操纵语言,数据定义语言; 严格的一致性; 基础事务 | 代表着不仅仅是SQL; 没有声明性查询语言; 没有预定义的模式; 键值对存储,列存储,文档存储,图形数据库; 最终一致性,而非ACID属性; 非结构化和不可预知的数据; CAP定理; 高性能,高可用性和可伸缩性 |
| 设计原则 | ACID:A (Atomicity) 原子性、C (Consistency) 一致性、I (Isolation) 独立性、D (Durability) 持久性,表示任何一个关系型数据库(使用表格式存储的数据库)必须同时满足四个特性要求 | BASE原则(同时满足CAP中的CA) Basically Availble --基本可用; Soft-state --软状态/柔性事务。 “Soft state” 可以理解为"无连接"的, 而 “Hard state” 是"面向连接"的; Eventual Consistency – 最终一致性, 也是是 ACID 的最终目的。 |
| 分类 | Mysql sqlserver oracle | 1)列存储:按列存储数据的,如Hbase、Cassandra、Hypertable 2)文档存储:用类似json的格式存储,存储的内容是文档型的,如MongoDB、CouchDB 3)key-value存储:Tokyo Cabinet / Tyrant、Berkeley DB、MemcacheDB、Redis 4)图存储:图形关系的最佳存储,如Neo4J、FlockDB 5)对象存储:通过对象的方式存取数据,如db4o、Versant 6)xml存储:存储XML数据,如Berkeley DB XML、BaseX |
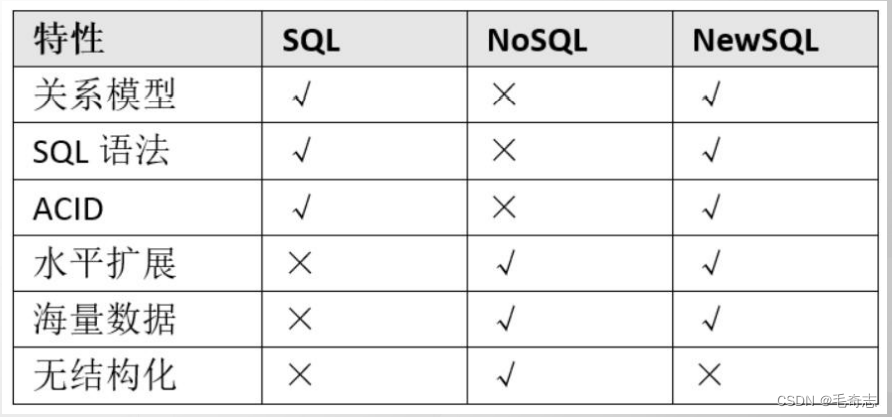
由上表可知,Redis是一种使用key-value键值对来存储数据的非关系型数据库。
另外,还存在一种NewSQL(下图中SQL表示关系型数据库,NoSQL表示非关系型数据库)
2.2 关系型数据库
2.2.1 关系型数据库的特点
关系型数据库的特点
1、基于行存储数据,二维的模式
2、存储结构化的数据,数据存储有固定的模式(schema)
3、表与表之间存在联(Relationship)
4、大都支持SQL(结构化查询语言)的操作,支持复杂的联查询
5、通过支持事务ACID(酸)来提供严格或者实时的数据一致性
2.2.2 关系型数据库的不足
关系型数据库的不足
1、要实现扩容的话,只能向(垂直)扩展,不支持动态的扩缩容
2、表结构修改困难,因此存储的数据格式也受到限制
3、高并发情况下,基于磁盘的读写压力比较大
2.3 非关系型数据库
2.3.1 非关系型数据库特点
非关系型数据库特点(non-relational)
1、存储非结构化的数据,比如文本、图片、音频、视频
2、表与表之间没有联,可扩展性强
3、保证数据的最终一致性,遵循BASE(碱)理论
4、支持海量数据的存储和高并发的高效读写
5、支持分布式,能够对数据进行分片存储,扩缩容简单
2.3.2 各种类型的非关系型数据库
各种类型的非关系型数据库
1、KV存储:Redis和Memcached
2、文档存储:MongoDB
3、列存储:HBase
4、图存储:Neo4j
5、对象存储
6、XML存储
所以,Redis的本质是一种基于键值对的非关系型数据库,即 Redis全称 Remote Dictionary Service 远程字典服务,就是指 Redis 是使用 键值对/字典 存储的。
redis与NoSQL的关系:NoSQL表示非关系型数据库,redis一种使用key-value键值对存储的非关系型数据库,是NoSQL的一种这就是两者的关系。
Redis和Memcached 都是使用键值对存储的非关系型数据库,都是运行在内存中,都是底层树形存储结构(mysql是表型存储结构)。
另外,还有一种和redis一样,基于文档存储的非关系型数据库,叫mongdb。
redis查询速度快,但是由于是存储在内存中,适用于存放临时、少量的数据,比如验证码有效期5秒;
mongdb查询速度快,但是由于是存储在磁盘上的,适用于存放永久、大量的数据,比如 购物车中的商品。
2.4 Redis是运行在内存中基于键值对存储的非关系型数据库
Redis是运行在内存中基于键值对存储的非关系型数据库,存储结构是树型。
Redis基本特性
速度快
支持多种数据类型
支持多种编程语言
持久化、内存淘汰
功能丰富:事务、发布订阅、pipeline、lua
集群、分布式
Redis 2020 新动向( Redis 6.0)
http://antirez.com/news/131
http://antirez.com/news/133
三、Redis如何与MySQL保持数据一致性
既然Redis是一种使用key-value键值对来存储数据的非关系型数据库,我们来介绍Redis是如何与MySQL保持数据一致性,这一点不需要的程序员干预,Redis会自动与MySQL保持数据一致性,让我们的程序从Redis取数据不会出错,我们只要简单知道原理就好。
3.1 从“处理器-缓存-内存”到“后台-redis-数据库”
在物理计算机中,由于处理器CPU与内存的速度不匹配问题,所有我们在处理器和内存之间加一个高速缓存,
缓存的数据是主存中热点数据的副本,处理器读取数据时,优先读取缓存中的数据,缓存中没有,再到主存中取,同时这个数据成为热点数据,写入到缓存中,下次处理器直接从缓存中取。
对于写操作,为了保证主存缓存中数据一致性问题,有“写直达法”和“写回法”两种方式。整个架构变化如图:

工作中,web项目开发,由于网络请求与数据库查询数据不匹配问题,所以我们在后台程序与数据库之间加一个redis/redis-cluster缓存,其读写操作与计算机的存储一样,优先读写redis缓存,整个架构变化如下:

这里用硬件对比软件后台,用高速缓存cache对比redis/redis-cluster,两者基本上是一样的,唯一不同的恐怕就是Cache是硬件,redis是软件。
3.2 不使用缓存与使用缓存(读操作+写操作)
在介绍redis读写之前,引入一个知识,redis支持的数据类型(我们起码要知道读写操作,读写的是什么)
redis支持五种数据类型
目前为止Redis支持的键值数据类型一共五种,如下:String字符串类型、hash散列类型、list列表类型、set集合类型、sorted set有序集合类型。
不使用缓存读

不使用缓存写

使用缓存读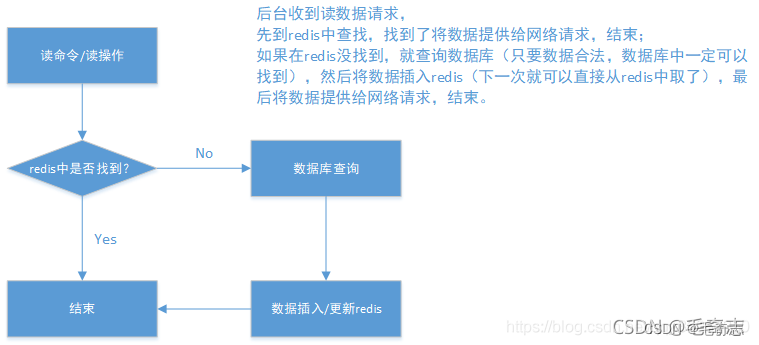

使用缓存写(先更新数据库,再更新redis缓存,类似写直达法)

使用缓存写(先更新redis缓存,再更新数据库,类似写回法)

四、Redis典型问题
4.1 缓存穿透,不存在的商品X
从名称上来解释含义:传统意义上的穿透,即水滴石穿,滴水能把石穿透,就是说水滴穿透石头的整个过程。
这里的缓存穿透,是指网络请求查询一个数据库一定不存在的数据(假设为-1,一个无意义数字)。因为这是一个数据库中绝对不存在的数据,所有redis缓存中也一定不存在,执行过程中,因为redis中一定找不到,所有一定会去数据库中找,结果就是数据库也找不到。因为这个网络请求查询过程是 “前端/客户端/移动端—网络请求—redis缓存—数据库” ,整个过程穿透redis,直达数据库,与水滴石穿有类似之意,所以称为缓存穿透。
正常的使用缓存流程大致是,数据查询先进行缓存查询,如果key不存在或者key已经过期,再对数据库进行查询,并把查询到的对象,放进缓存。如果数据库查询对象为空,则不放进缓存(这是重点,查不到就不进入缓存,所以第二次请求同样的数据还是要查询数据库)。
缓存穿透的问题再哪里?在于它每次都要请求数据库,redis缓存形同虚设,起不到减少数据库查询、提升性能的作用。
我们知道,每一次查询数据库的代价是比较大的(所以我们引用了redis缓存),因为请求的是一个数据库一定不存在的数据,所有每一次都要查数据库,而且因为数据库查询为空,这次的数据也不会放入缓存,下一次还是查询这个数据又要到数据库中查询,不断循环,一个不存在的数据多次请求就可以让后台系统崩溃。
假如有恶意攻击,就可以利用这个漏洞(网络请求一个数据库中一定不存在的数据,不断请求),对数据库造成压力,甚至压垮数据库。即便是采用UUID,也是很容易找到一个不存在的KEY,进行攻击。
举例:

解决方案:
思考:第一次请求redis中找不到,访问数据库不是什么大问题,后面N-1次都要访问数据库这就是个大问题了。核心在于:如果数据库查询对象为空,则不放进缓存。这是默认规则,如果能消除这条规则,即数据库查询为空也写入redis,后面进直接从redis中取,取不到就结束(因为数据库和redis已经同步了)。
解决:会采用缓存空值null的方式,如果从数据库查询的对象为空,也放入缓存,即将null放入缓存,将key:value=(x,null)写入redis,下一次查询key=x,直接在redis中返回value=null.
4.2 缓存雪崩,双十一抢购
从名称上来解释含义:传统意义上的雪崩就是指一种当山坡积雪内部的内聚力抗拒不了它所受到的重力拉引时,便向下滑动,引起大量雪体崩塌的自然现象。

雪崩之所以可怕,是因为其规模之大,局部雪崩可能引起全局雪崩,一次严重的雪崩可能造成整座雪山的崩塌。这里的缓存雪崩是指在某一个时间段,缓存集中过期失效,造成整个redis不可用(对应整座雪山崩塌)。
关于缓存雪崩,粗体标记,注意两个词语,一是“集中”,二是“过期”,一是集中失效,二是过期失效
关于集中:redis默认有16个库,db0~db15,“集中”表示redis缓存中的大部分库是失效了
关于过期:表示redis缓存雪崩中多个库是由于缓存时间到期而失效的
缓存雪崩就是缓存失效,“集中”告诉我们是大部分库失效了,不是小部分或者个别;“过期”是指这种库失效是由于缓存时间到期而失效的(即是正常的失效),不是异常错误导致库失效
举例:产生雪崩的原因之一,以淘宝双十一抢购为例,假设淘宝后台将热门商品放入redis/redis-cluster(像淘宝这么大的肯定是redis-cluster redis集群喽),设置缓存时间为一小时(当然淘宝系统不会如此愚蠢,这里是假设,皮),那么午夜12点开始抢购,到了午夜1点,所有的热门商品的缓存都过期了,如果用户再购买商品,后台就是读写数据库(而不是直接读写redis)了,这样造成访问速度慢,带来无法容忍的用户体验。如图:

这样的缓存集体过期就是缓存雪崩,是使用缓存的一种危险,开发者一定要记住。
解决:
思考方式一:如果发生了集体缓存过期,即缓存雪崩,是非常可怕且很难挽救的,在发生后的一段时间内相当于没有使用redis缓存技术,退化为原始的持久层数据库操作。所以,我们的思考不是发生缓存雪崩之后如何解决,而是如何避免缓存雪崩的发生。
解决方案一——过期错开:将key的过期时间后面加上一个随机数,让key均匀的失效;或者使用一种特定的算法,使过期时间赋值更符合实际业务。
思考方式二:第一种方案均摊过期时间或使用特定算法,旨在最大程度在避免出现缓存雪崩,但是如果缓存雪崩确实发生了,程序如何应对呢?
解决方案二——排队处理:使用优先队列或者锁让程序执行在压力范围之内,如果访问量达到阈值,排队处理业务请求,即为了保证系统的不会崩溃,不要同时处理所有请求。
4.3 缓存击穿,iphoneX上市了
从名称上来解释含义:传统意义上的击穿(电压击穿)是指在电场作用下绝缘体内部产生破坏性的放电,绝缘电阻下降,电流增大,并产生破坏和穿孔的现象。

这里的缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存(类似电压穿破绝缘体),直接请求数据库,就像在一个屏障上凿开了一个洞。
缓存穿透与缓存击穿异同:
相同点:都是数据库承受不了巨大压力,导致崩溃。
不同点:
缓存穿透是指redis没作用,形同虚设,每一次访问都要查询数据库,导致崩溃,这是技术上可以解决的,redis中记录一个(x,null)键值对;
缓存击穿是指redis作用了,但是数据量实在是太大了,实在是承受不了这么大的数据量,数据库连带redis缓存一起崩溃,这时在固定的硬件成本下,缓存、数据库软件方面已经达到理论上的最优了,技术上解决不了。
举例:以iphoneX发布为例,一下子就成了热款,所有人通过淘宝线上购买,巨大的并发量某一时刻击穿缓存,直接请求数据库,而数据库又无法高速查表,导致系统崩溃。如图:

解决方案
思考:现在的问题是数据量实在太大了,redis和数据库的设计已经达到最优了。
步骤一:热卖商品redis有效期设置为永久,绝对不要出现过期问题,redis方面达到最优。
步骤二:在固定的硬件成本下,数据库(mysql或oracle)在表设计达到最优,框架(如mybatis)sql查询语句设计达到最优
步骤三:设置一个优先队列(如12306 买春运往返票),控制并发数,防止系统崩溃。
实际上,其实,大多数情况下这种爆款很难对数据库服务器造成压垮性的压力,能达到这种并发的可能也只有“12306春运购票”、“淘宝双十一” 、“春晚跨年”这样的事情了,从另外一个方面来讲,如果真的有某个单一商品销售量达到使用让redis、数据库崩溃,开始考虑redisCluster,mysql分库+水平分表的方案。
五、尾声
本文介绍了因现实需求(mysql读写速度慢)引入了Redis、Redis如何与Mysql保持数据一致性、Redis三种典型问题。
Redis的引入,完成了。
相关文章
- Redis分布式锁的实现原理看这篇就够了~
- python 学习笔记 redis操作
- Redis的Python客户端redis-py的初步使用
- Redis配置文件详解(redis.conf)
- spring boot集成redis
- Redis的7个应用场景
- 彻底清除Linux centos minerd木马 实战 跟redis的设置有关
- redis 简单整理——redis 准备篇[一]
- Redis 基本架构:一个键值数据库包含什么?
- Docker搭建Redis高可用集群(基于redis-sentinel)
- 理解redis高可用方案
- 【服务器安装Redis】Centos7离线安装redis
- 〖Python 数据库开发实战 - Python与Redis交互篇④〗- 利用 redis-py 实现集合与有序集合的常用指令操作
- 〖Python 数据库开发实战 - Python与Redis交互篇⑤〗- 利用 redis-py 实现哈希数据类型的常用指令操作
- 〖Python 数据库开发实战 - Python与Redis交互篇⑧〗- 利用 redis-py 实现缓存观众投票数据信息案例
- 〖Python 数据库开发实战 - Python与Redis交互篇⑫〗- 综合案例 - 新闻管理系统 - 删除新闻(含redis缓存)
- Redis源代码分析(十二)--- redis-check-dump本地数据库检測
- redis_02 _ 数据结构:快速的Redis有哪些慢操作?
- docker 基于Dockerfile构建redis
- redis auth php操作
- 几分钟搞定redis存储session共享——设计实现
- Redis进阶学习10---redis最佳实践
- Redis 主从复制-服务器搭建【薪火相传/哨兵模式】
- ASP.NET Core微服务(六)——【redis命令详细列表3】
- 【redis】Redis缓存失效、雪崩、穿透、击穿、并发等案例分析难题解决方案
- Java面试——Redis系列总结
- Redis常见面试题与答案
- 【redis】redis内存管理、淘汰机制、内存优化