
机器学习笔记之粒子滤波(一)序列重要性采样
机器学习笔记之粒子滤波——序列重要性采样
引言
上一节介绍了卡尔曼滤波以及其在滤波问题中的求解思想,本节将介绍粒子滤波(Particle Filter),并针对重要性采样的缺陷介绍序列重要性采样(Sequential Importance Sampling)。
回顾:动态模型
动态模型的划分
在隐马尔可夫模型(Hidden Markov Model,HMM)与卡尔曼滤波介绍(Karlman Filter)中介绍了动态模型(Dynamic Model)的概念。其概率图模型表示如下:
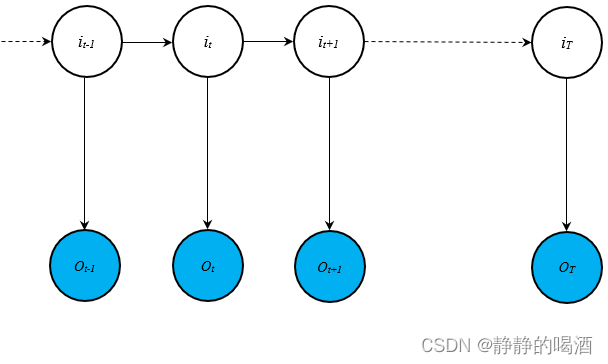
在关于变量概率的求解过程中,包含动态模型的两个假设:
- 齐次马尔可夫假设:该假设是由马尔可夫链(Markov Chain)中延伸过来的假设。文字描述为:给定当前状态变量
i
t
i_t
it的条件下,未来的状态变量只与当前状态相关,与过去状态无关。对应数学符号表示如下:
这里以‘一阶齐次马尔可夫假设’为例。
P ( i t + 1 ∣ i 1 , i 2 , ⋯ , i t ) = P ( i t + 1 ∣ i t ) \mathcal P(i_{t+1} \mid i_{1},i_2,\cdots,i_t) = \mathcal P(i_{t+1} \mid i_t) P(it+1∣i1,i2,⋯,it)=P(it+1∣it) - 观测独立性假设:某时刻观测变量
o
t
o_t
ot的后验概率,只与对应时刻的隐变量
i
t
i_t
it相关,与其他时刻的任意变量无关。对应数学符号表示如下:
需要注意的点:所有‘动态模型’均服从该假设,而不仅仅是‘隐马尔可夫模型’。
P ( o t ∣ i 1 , ⋯ , i T , o 1 , ⋯ , o T ) = P ( o t ∣ i t ) \mathcal P(o_t \mid i_1,\cdots,i_T,o_1,\cdots,o_T) = \mathcal P(o_t \mid i_t) P(ot∣i1,⋯,iT,o1,⋯,oT)=P(ot∣it)
从隐变量 i t ( i = 1 , 2 , ⋯ , T ) i_t(i=1,2,\cdots,T) it(i=1,2,⋯,T)的基本类型角度进行划分,可划分为如下形式:
-
隐变量是离散型随机变量的隐马尔可夫模型:隐马尔可夫模型对观测变量的基本类型没有过多要求。可以是连续,也可以是离散;
为计算方便起见,假设观测变量也服从离散型随机变量,因而隐马尔可夫模型的模型参数 表示如下:
λ = ( π , A , B ) \lambda = (\pi,\mathcal A,\mathcal B) λ=(π,A,B)
其中 π \pi π表示初始时刻隐变量的概率结果 P ( i 1 ) \mathcal P(i_1) P(i1)。由于是离散型随机变量,可以将概率分布表示为如下形式:离散结果 q 1 q_1 q1 q 2 q_2 q2 ⋯ \cdots ⋯ q K q_{\mathcal K} qK 对应概率 P ( i 1 = q 1 ) \mathcal P(i_1 = q_1) P(i1=q1) P ( i 1 = q 2 ) \mathcal P(i_1 = q_2) P(i1=q2) ⋯ \cdots ⋯ P ( i 1 = q K ) \mathcal P(i_1 = q_{\mathcal K}) P(i1=qK) A \mathcal A A为状态转移矩阵,矩阵中的每个元素表示相邻时刻隐变量的条件概率结果:
a i j = P ( i t = q j ∣ i t − 1 = q i ) a_{ij} = \mathcal P(i_t = q_j \mid i_{t-1} = q_i) aij=P(it=qj∣it−1=qi)
B \mathcal B B为发射矩阵,矩阵中的每个元素表示某时刻隐变量与对应时刻观测变量之间的条件概率结果:
b j ( k ) = P ( o t = v k ∣ i t = q j ) b_j(k) = \mathcal P(o_t = v_k \mid i_t = q_j) bj(k)=P(ot=vk∣it=qj) -
隐变量是连续型随机变量的有卡尔曼滤波、粒子滤波。其中卡尔曼滤波的模型参数 表示如下:
λ = ( A , B , C , D , Q , R , μ 1 , Σ 1 ) \lambda = (\mathcal A,\mathcal B,\mathcal C,\mathcal D,\mathcal Q,\mathcal R,\mu_1,\Sigma_1) λ=(A,B,C,D,Q,R,μ1,Σ1)并且卡尔曼滤波要求相邻隐变量之间、隐变量与对应观测变量之间属于线性关系。并且噪声服从高斯分布:
P ( i t ∣ i t − 1 ) ∼ N ( A ⋅ i t − 1 + B , Q ) P ( o t ∣ i t ) ∼ N ( C ⋅ i t + D , R ) \begin{aligned} \mathcal P(i_t \mid i_{t-1}) & \sim \mathcal N(\mathcal A \cdot i_{t-1} + \mathcal B,\mathcal Q) \\ \mathcal P(o_t \mid i_t) & \sim \mathcal N(\mathcal C \cdot i_t + \mathcal D,\mathcal R) \end{aligned} P(it∣it−1)P(ot∣it)∼N(A⋅it−1+B,Q)∼N(C⋅it+D,R)
并且卡尔曼滤波中初始时刻隐变量的概率分布 P ( i 1 ) \mathcal P(i_1) P(i1)服从高斯分布:
P ( i 1 ) ∼ N ( μ 1 , Σ 1 ) \mathcal P(i_1) \sim \mathcal N(\mu_1,\Sigma_1) P(i1)∼N(μ1,Σ1)
动态模型处理的任务
在动态模型基本介绍中已经提到了动态模型的相关处理任务。这里不再赘述。不同模型对于任务处理的侧重点 有所不同:
- 隐马尔可夫模型更关注 求值问题(Evaluation)与学习任务(Learning):
P ( O ∣ λ ) = P ( o 1 , o 2 , ⋯ , o T ∣ λ ) λ ^ = arg max λ P ( O ∣ λ ) λ = ( π , A , B ) \begin{aligned} \mathcal P(\mathcal O \mid \lambda) = \mathcal P(o_1,o_2,\cdots,o_T \mid \lambda) \\ \hat {\lambda} = \mathop{\arg\max}\limits_{\lambda} \mathcal P(\mathcal O \mid \lambda) \quad \lambda = (\pi,\mathcal A,\mathcal B) \\ \end{aligned} P(O∣λ)=P(o1,o2,⋯,oT∣λ)λ^=λargmaxP(O∣λ)λ=(π,A,B) - 卡尔曼滤波、粒子滤波更关注 滤波问题(Filtering):
P ( i t ∣ o 1 , ⋯ , o t ) \mathcal P(i_t \mid o_1,\cdots,o_t) P(it∣o1,⋯,ot)
而卡尔曼滤波处理滤波问题使用先预测,再对预测修正的迭代过程:- 预测步骤(Prediction):
P ( i t ∣ o 1 , ⋯ , o t − 1 ) = ∫ i t − 1 P ( i t ∣ i t − 1 ) ⋅ P ( i t − 1 ∣ o 1 , ⋯ , o t − 1 ) d i t − 1 \begin{aligned} \mathcal P(i_t \mid o_1,\cdots,o_{t-1}) & = \int_{i_{t-1}} \mathcal P(i_t \mid i_{t-1}) \cdot \mathcal P(i_{t-1} \mid o_1,\cdots,o_{t-1}) di_{t-1}\\ \end{aligned} P(it∣o1,⋯,ot−1)=∫it−1P(it∣it−1)⋅P(it−1∣o1,⋯,ot−1)dit−1 - 更新步骤(Update):
P ( i t ∣ o 1 , ⋯ , o t ) = P ( o 1 , ⋯ , o t − 1 ) P ( o , ⋯ , o t ) ⋅ [ P ( o t ∣ i t ) ⋅ P ( i t ∣ o 1 , ⋯ , o t − 1 ) ] ∝ P ( o t ∣ i t ) ⋅ P ( i t ∣ o 1 , ⋯ , o t − 1 ) \begin{aligned} \mathcal P(i_t \mid o_1,\cdots,o_t) & = \frac{\mathcal P(o_1,\cdots,o_{t-1})}{\mathcal P(o_,\cdots,o_t)} \cdot \left[\mathcal P(o_t \mid i_t) \cdot \mathcal P(i_t \mid o_1,\cdots,o_{t-1})\right] \\ & \propto \mathcal P(o_t \mid i_t) \cdot \mathcal P(i_t \mid o_1,\cdots,o_{t-1}) \end{aligned} P(it∣o1,⋯,ot)=P(o,⋯,ot)P(o1,⋯,ot−1)⋅[P(ot∣it)⋅P(it∣o1,⋯,ot−1)]∝P(ot∣it)⋅P(it∣o1,⋯,ot−1)
- 预测步骤(Prediction):
粒子滤波关于滤波问题的求解
粒子滤波在动态模型中最显著的特点是:相邻时刻隐变量之间、观测变量与对应时刻隐变量之间的关联关系均是非线性的,并且对应噪声也是非高斯分布的。
由于卡尔曼滤波中变量之间的优质特性,因此可以通过高斯分布的一系列变换在每一次预测步骤(Prediction)与更新步骤(Update)中能够精确得到隐变量 i t i_t it概率的精确结果。
而粒子滤波对于变量之间的关联关系是模糊的,从而没有办法得到解析解。因此,需要借助采样(Sampling)的方式得到隐变量 i t i_t it概率的近似结果。
蒙特卡洛方法
蒙特卡洛方法本身是近似推断(Approximate Inference)中的一系列方法。
推断(Inference)在概率图模型(六)推断基本介绍中提到,其本质上是求解变量的概率。在包含隐变量 Z \mathcal Z Z的任务中,推断的目标是求解给定观测变量 X \mathcal X X的条件下,隐变量 Z \mathcal Z Z的后验概率结果 P ( Z ∣ X ) \mathcal P(\mathcal Z \mid \mathcal X) P(Z∣X)。
由于分布的复杂性,
P
(
Z
∣
X
)
\mathcal P(\mathcal Z \mid \mathcal X)
P(Z∣X)可能无法直接求解,并且
P
(
Z
∣
X
)
\mathcal P(\mathcal Z \mid \mathcal X)
P(Z∣X)在应用过程中,我们更加关心的是
P
(
Z
∣
X
)
\mathcal P(\mathcal Z \mid \mathcal X)
P(Z∣X)分布下的期望结果:
E
Z
∣
X
[
f
(
X
)
]
=
∫
Z
f
(
X
)
⋅
P
(
Z
∣
X
)
d
Z
\mathbb E_{\mathcal Z \mid \mathcal X}[f(\mathcal X)] = \int_{\mathcal Z} f(\mathcal X) \cdot \mathcal P(\mathcal Z \mid \mathcal X) d\mathcal Z
EZ∣X[f(X)]=∫Zf(X)⋅P(Z∣X)dZ
而蒙特卡洛方法(Monte Carlo Method)通过采样的方式直接近似求解
E
Z
∣
X
[
f
(
X
)
]
\mathbb E_{\mathcal Z \mid \mathcal X}[f(\mathcal X)]
EZ∣X[f(X)]:
- 从
P
(
Z
∣
X
)
\mathcal P(\mathcal Z \mid \mathcal X)
P(Z∣X)分布中采集
N
N
N个样本:
虽然P ( Z ∣ X ) \mathcal P(\mathcal Z \mid \mathcal X) P(Z∣X)的概率分布我们不能精确得知,但并不影响采集样本。
z ( 1 ) , z ( 2 ) , ⋯ , z ( N ) ∼ P ( Z ∣ X ) z^{(1)},z^{(2)},\cdots,z^{(N)} \sim \mathcal P(\mathcal Z \mid \mathcal X) z(1),z(2),⋯,z(N)∼P(Z∣X) - 根据大数定律,通过样本均值的形式求解
E
Z
∣
X
[
f
(
X
)
]
\mathbb E_{\mathcal Z \mid \mathcal X}[f(\mathcal X)]
EZ∣X[f(X)]:
E Z ∣ X [ f ( X ) ] ≈ 1 N ∑ i = 1 N f ( z ( i ) ) \mathbb E_{\mathcal Z \mid \mathcal X}[f(\mathcal X)] \approx \frac{1}{N} \sum_{i=1}^N f(z^{(i)}) EZ∣X[f(X)]≈N1i=1∑Nf(z(i))
重要性采样
针对 P ( Z ∣ X ) \mathcal P(\mathcal Z \mid \mathcal X) P(Z∣X)过于复杂,亦或是维度过高,导致 无法高效地从 P ( Z ∣ X ) \mathcal P(\mathcal Z \mid \mathcal X) P(Z∣X)分布中采集到样本。
通过重要性采样(Importance Sampling)方法,引入一个 简单分布/可采样的分布
Q
(
Z
)
\mathcal Q(\mathcal Z)
Q(Z)并对其进行采样,通过重要性权重(Importance Weight)的筛选,从而得到有效的采样结果:
称
Q
(
Z
)
\mathcal Q(\mathcal Z)
Q(Z)为‘提议分布/候选分布’。
E
Z
∣
X
[
f
(
X
)
]
=
∫
Z
f
(
X
)
⋅
P
(
Z
∣
X
)
d
Z
=
∫
Z
Q
(
Z
)
⋅
[
f
(
X
)
⋅
P
(
Z
∣
X
)
Q
(
Z
)
]
d
Z
=
E
Q
(
Z
)
[
f
(
X
)
⋅
P
(
Z
∣
X
)
Q
(
Z
)
]
\begin{aligned} \mathbb E_{\mathcal Z \mid \mathcal X} [f(\mathcal X)] & = \int_{\mathcal Z} f(\mathcal X) \cdot \mathcal P(\mathcal Z \mid \mathcal X) d\mathcal Z \\ & = \int_{\mathcal Z} \mathcal Q(\mathcal Z) \cdot \left[f(\mathcal X) \cdot \frac{\mathcal P(\mathcal Z \mid \mathcal X)}{\mathcal Q(\mathcal Z)}\right] d\mathcal Z \\ & = \mathbb E_{\mathcal Q(\mathcal Z)}\left[f(\mathcal X) \cdot \frac{\mathcal P(\mathcal Z \mid \mathcal X)}{\mathcal Q(\mathcal Z)}\right] \end{aligned}
EZ∣X[f(X)]=∫Zf(X)⋅P(Z∣X)dZ=∫ZQ(Z)⋅[f(X)⋅Q(Z)P(Z∣X)]dZ=EQ(Z)[f(X)⋅Q(Z)P(Z∣X)]
其中
P
(
Z
∣
X
)
Q
(
Z
)
\frac{\mathcal P(\mathcal Z \mid \mathcal X)}{\mathcal Q(\mathcal Z)}
Q(Z)P(Z∣X)即 重要性权重,针对上述期望形式,通过蒙特卡洛采样方法近似求解
E
Z
∣
X
[
f
(
X
)
]
\mathbb E_{\mathcal Z \mid \mathcal X} [f(\mathcal X)]
EZ∣X[f(X)]:
z
(
1
)
,
z
(
2
)
,
⋯
,
z
(
N
)
∼
Q
(
Z
)
E
Z
∣
X
[
f
(
X
)
]
≈
1
N
∑
i
=
1
N
f
(
z
(
i
)
)
⋅
P
(
z
(
i
)
)
Q
(
z
(
i
)
)
\begin{aligned} z^{(1)},z^{(2)}, \cdots,z^{(N)} \sim \mathcal Q(\mathcal Z) \\ \mathbb E_{\mathcal Z \mid \mathcal X} [f(\mathcal X)] \approx \frac{1}{N} \sum_{i=1}^N f(z^{(i)}) \cdot \frac{\mathcal P(z^{(i)})}{\mathcal Q(z^{(i)})} \end{aligned}
z(1),z(2),⋯,z(N)∼Q(Z)EZ∣X[f(X)]≈N1i=1∑Nf(z(i))⋅Q(z(i))P(z(i))
重要性采样处理滤波任务的缺陷
针对滤波问题
P
(
i
t
∣
o
1
,
⋯
,
o
t
)
\mathcal P(i_t \mid o_1,\cdots,o_t)
P(it∣o1,⋯,ot),使用重要性采样方法得到
t
t
t时刻第
i
i
i次重要性采样得到的重要性权重
W
t
(
i
)
\mathcal W_t^{(i)}
Wt(i) 表示如下:
W
t
(
i
)
=
P
(
z
t
(
i
)
∣
o
1
,
⋯
,
o
t
)
Q
(
z
t
(
i
)
∣
o
1
,
⋯
,
o
t
)
\mathcal W_t^{(i)} = \frac{\mathcal P(z_t^{(i)} \mid o_1,\cdots,o_t)}{\mathcal Q(z_t^{(i)} \mid o_1,\cdots,o_t)}
Wt(i)=Q(zt(i)∣o1,⋯,ot)P(zt(i)∣o1,⋯,ot)
其中,
z
t
(
i
)
z_t^{(i)}
zt(i)表示
t
t
t时刻在
Q
(
Z
)
\mathcal Q(\mathcal Z)
Q(Z)中采集的第
i
i
i个样本;而需要注意的点是:观测变量
o
1
,
⋯
,
o
t
o_1,\cdots,o_t
o1,⋯,ot是给定的信息,不经过采样过程。
观察执行一次采样,需要运算的步骤(依然以 z t ( i ) z_t^{(i)} zt(i)为例):
-
计算 P ( z t ( i ) ∣ o 1 , ⋯ , o t ) \mathcal P(z_t^{(i)}\mid o_1,\cdots,o_t) P(zt(i)∣o1,⋯,ot):
P ( z t ( i ) ∣ o 1 , ⋯ , o t ) = P ( z t ( i ) , o 1 , ⋯ , o t ) P ( o 1 , ⋯ , o t ) ∝ P ( z t ( i ) , o 1 , ⋯ , o t ) \begin{aligned} \mathcal P(z_t^{(i)} \mid o_1,\cdots,o_t) & = \frac{\mathcal P(z_t^{(i)},o_1,\cdots,o_t)}{\mathcal P(o_1,\cdots,o_t)} \\ & \propto \mathcal P(z_t^{(i)},o_1,\cdots,o_t) \end{aligned} P(zt(i)∣o1,⋯,ot)=P(o1,⋯,ot)P(zt(i),o1,⋯,ot)∝P(zt(i),o1,⋯,ot)
继续对 P ( z t ( i ) , o 1 , ⋯ , o t ) \mathcal P(z_t^{(i)},o_1,\cdots,o_t) P(zt(i),o1,⋯,ot)进行求解。实际情况是:求解 P ( z t ( i ) , o 1 , ⋯ , o t ) \mathcal P(z_t^{(i)},o_1,\cdots,o_t) P(zt(i),o1,⋯,ot)过于复杂,运算代价很高。在介绍求值问题(Evaluation)时,无论是前向算法(Forward Algorithm)还是后向算法(Backward Algorithm),都需要从某一端开始遍历,从而时间复杂度均为 O ( T ) \mathcal O(T) O(T)。
-
上述运算仅仅是某时刻的某一次采样结果,而整个过程一共需要采样 N × T N \times T N×T次,即 每个时刻都需要采集 N N N个样本,最终它的时间复杂度为 O ( T 2 × N ) \mathcal O(T^2 \times N) O(T2×N)。
这里假设‘每一时刻采样的数量是相同的’,最终的时间复杂度只是一个粗略结果。
序列重要性采样
由于滤波问题本身是一个在线算法,一个朴素的想法是:将某时刻的重要性权重结果 W t \mathcal W_t Wt与上一时刻的结果 W t − 1 \mathcal W_{t-1} Wt−1之间建立联系,如果找到联系,可以通过迭代方式简化大量运算。
根据动态模型的性质,引入一种重要性采样的改进算法:序列重要性采样(Sequential Important Sampling,SIS)
其核心在于找出当前时刻采样的重要性权重
W
t
\mathcal W_t
Wt和上一时刻采样的重要性权重
W
t
−
1
\mathcal W_{t-1}
Wt−1之间的关联关系。
这里并不关注采样的编号,它只是一个采样顺序编号,没有具体用处。
W
t
−
1
=
P
(
i
t
−
1
∣
o
1
,
⋯
,
o
t
−
1
)
Q
(
i
t
−
1
∣
o
1
,
⋯
,
o
t
−
1
)
W
t
=
P
(
i
t
∣
o
1
,
⋯
,
o
t
)
Q
(
i
t
∣
o
1
,
⋯
,
o
t
)
W
t
−
1
↔
?
W
t
\begin{aligned} \mathcal W_{t-1} & = \frac{\mathcal P(i_{t-1} \mid o_1,\cdots,o_{t-1})}{\mathcal Q(i_{t-1} \mid o_1,\cdots,o_{t-1})} \\ \mathcal W_t & = \frac{\mathcal P(i_t \mid o_1,\cdots,o_t)}{\mathcal Q(i_t \mid o_1,\cdots,o_t)} \\ \mathcal W_{t-1} & \overset{\text{?}}{\leftrightarrow} \mathcal W_{t} \end{aligned}
Wt−1WtWt−1=Q(it−1∣o1,⋯,ot−1)P(it−1∣o1,⋯,ot−1)=Q(it∣o1,⋯,ot)P(it∣o1,⋯,ot)↔?Wt
序列重要性采样的核心思想在于 它并没有直接求解滤波问题 P ( i t ∣ o 1 , ⋯ , o t ) \mathcal P(i_t \mid o_1,\cdots,o_t) P(it∣o1,⋯,ot),而是求解概率分布 P ( i 1 , ⋯ , i t ∣ o 1 , ⋯ , o t ) \mathcal P(i_1,\cdots,i_t \mid o_1,\cdots,o_t) P(i1,⋯,it∣o1,⋯,ot)
该算法的设想是:通过求解联合概率分布的比值,来近似看作滤波问题的比值。数学符号表示如下:
W
t
=
P
(
i
t
∣
o
1
,
⋯
,
o
t
)
Q
(
i
t
∣
o
1
,
⋯
,
o
t
)
∝
P
(
i
1
,
⋯
,
i
t
∣
o
1
,
⋯
,
o
t
)
Q
(
i
1
,
⋯
,
i
t
∣
o
1
,
⋯
,
o
t
)
\mathcal W_t = \frac{\mathcal P(i_t \mid o_1,\cdots,o_t)}{\mathcal Q(i_t \mid o_1,\cdots,o_t)} \propto \frac{\mathcal P(i_1,\cdots,i_t \mid o_1,\cdots,o_t)}{\mathcal Q(i_1,\cdots,i_t \mid o_1,\cdots,o_t)}
Wt=Q(it∣o1,⋯,ot)P(it∣o1,⋯,ot)∝Q(i1,⋯,it∣o1,⋯,ot)P(i1,⋯,it∣o1,⋯,ot)
从下面开始,先通过个人想法来解释该设想的合理性。
对于SIS设想的个人解释
关于该式:
W
t
=
P
(
i
t
∣
o
1
,
⋯
,
o
t
)
Q
(
i
t
∣
o
1
,
⋯
,
o
t
)
∝
P
(
i
1
,
⋯
,
i
t
∣
o
1
,
⋯
,
o
t
)
Q
(
i
1
,
⋯
,
i
t
∣
o
1
,
⋯
,
o
t
)
\mathcal W_t = \frac{\mathcal P(i_t \mid o_1,\cdots,o_t)}{\mathcal Q(i_t \mid o_1,\cdots,o_t)} \propto \frac{\mathcal P(i_1,\cdots,i_t \mid o_1,\cdots,o_t)}{\mathcal Q(i_1,\cdots,i_t \mid o_1,\cdots,o_t)}
Wt=Q(it∣o1,⋯,ot)P(it∣o1,⋯,ot)∝Q(i1,⋯,it∣o1,⋯,ot)P(i1,⋯,it∣o1,⋯,ot)
其中分母部分是关于
Q
\mathcal Q
Q的分布,该分布是人为设置的简单分布,变量关系随着
P
\mathcal P
P的变化而变化,因此将关注点放在
P
\mathcal P
P分布中变量的关联关系上:
P
(
i
t
∣
o
1
,
⋯
,
o
t
)
↔
P
(
i
1
,
⋯
,
i
t
∣
o
1
,
⋯
,
o
t
)
\mathcal P(i_t \mid o_1,\cdots,o_t) \leftrightarrow \mathcal P(i_1,\cdots,i_t \mid o_1,\cdots,o_t)
P(it∣o1,⋯,ot)↔P(i1,⋯,it∣o1,⋯,ot)
将
P
(
i
1
,
⋯
,
i
t
∣
o
1
,
⋯
,
o
t
)
\mathcal P(i_1,\cdots,i_t \mid o_1,\cdots,o_t)
P(i1,⋯,it∣o1,⋯,ot)通过联合概率分布进行展开:
P
(
i
1
,
⋯
,
i
t
∣
o
1
,
⋯
,
o
t
)
=
P
(
i
1
,
⋯
,
i
t
,
o
1
,
⋯
,
o
t
)
P
(
o
1
,
⋯
,
o
t
)
\mathcal P(i_1,\cdots,i_t \mid o_1,\cdots,o_t) = \frac{\mathcal P(i_1,\cdots,i_t, o_1,\cdots,o_t)}{\mathcal P(o_1,\cdots,o_t)}
P(i1,⋯,it∣o1,⋯,ot)=P(o1,⋯,ot)P(i1,⋯,it,o1,⋯,ot)
对分子使用全概率公式继续展开:
为了方便观看,后续将
P
(
o
1
,
⋯
,
o
t
)
\mathcal P(o_1,\cdots,o_t)
P(o1,⋯,ot)简写为
P
(
o
1
:
t
)
\mathcal P(o_{1:t})
P(o1:t),其他同理。
全概率公式只展开一部分,
P
(
o
1
:
t
)
\mathcal P(o_{1:t})
P(o1:t)部分不展开。
P
(
i
1
:
t
∣
o
1
:
t
)
=
P
(
i
1
:
t
,
o
1
:
t
)
P
(
o
1
:
t
)
=
P
(
i
1
∣
i
2
:
t
,
o
1
:
t
)
⋅
P
(
i
2
∣
i
3
:
t
,
o
1
:
t
)
⋯
P
(
i
t
∣
o
1
:
t
)
⋅
P
(
o
1
:
t
)
P
(
o
1
:
t
)
\begin{aligned} \mathcal P(i_{1:t} \mid o_{1:t}) & = \frac{\mathcal P(i_{1:t},o_{1:t})}{\mathcal P(o_{1:t})} \\ & = \frac{\mathcal P(i_1 \mid i_{2:t},o_{1:t}) \cdot \mathcal P(i_2 \mid i_{3:t},o_{1:t}) \cdots \mathcal P(i_t \mid o_{1:t})\cdot \mathcal P(o_{1:t})} {\mathcal P(o_{1:t})} \end{aligned}
P(i1:t∣o1:t)=P(o1:t)P(i1:t,o1:t)=P(o1:t)P(i1∣i2:t,o1:t)⋅P(i2∣i3:t,o1:t)⋯P(it∣o1:t)⋅P(o1:t)
这里面取巧的部分在于:使用全概率公式对联合概率分布展开时,展开顺序对联合概率分布结果不产生影响:
P
(
X
,
Y
)
=
P
(
X
∣
Y
)
⋅
P
(
Y
)
=
P
(
Y
∣
X
)
⋅
P
(
X
)
\mathcal P(\mathcal X,\mathcal Y) = \mathcal P(\mathcal X \mid \mathcal Y) \cdot \mathcal P(\mathcal Y) = \mathcal P(\mathcal Y\mid \mathcal X) \cdot \mathcal P(\mathcal X)
P(X,Y)=P(X∣Y)⋅P(Y)=P(Y∣X)⋅P(X)
言归正传,分子、分母约分,得到如下结果:
其中最后一项,就是要关联的项
P
(
i
t
∣
o
1
:
t
)
\mathcal P(i_t \mid o_{1:t})
P(it∣o1:t)
P
(
i
1
:
t
∣
o
1
:
t
)
=
P
(
i
1
∣
i
2
:
t
,
o
1
:
t
)
⋅
P
(
i
2
∣
i
3
:
t
,
o
1
:
t
)
⋯
P
(
i
t
∣
o
1
:
t
)
\mathcal P(i_{1:t} \mid o_{1:t}) = \mathcal P(i_1 \mid i_{2:t},o_{1:t}) \cdot \mathcal P(i_2 \mid i_{3:t},o_{1:t}) \cdots \mathcal P(i_t \mid o_{1:t})
P(i1:t∣o1:t)=P(i1∣i2:t,o1:t)⋅P(i2∣i3:t,o1:t)⋯P(it∣o1:t)
观察除最后一项外的其他所有项:
- 以第一项为例,由于 齐次马尔可夫假设,变量
i
1
i_1
i1与
i
2
:
t
,
o
1
:
t
i_{2:t},o_{1:t}
i2:t,o1:t中的任意一项都没有关系。从而有:
P ( i 1 ∣ i 2 : t , o 1 : t ) = P ( i 1 ) \mathcal P(i_1 \mid i_{2:t},o_{1:t}) = \mathcal P(i_1) P(i1∣i2:t,o1:t)=P(i1) - 再举一个第二项例子,变量
i
2
i_2
i2只与
i
1
i_1
i1相关,而
i
3
:
t
,
o
1
:
t
i_{3:t},o_{1:t}
i3:t,o1:t中不含
i
1
i_1
i1。从而有:
P ( i 2 ∣ i 3 : t , o 1 : t ) = P ( i 2 ) \mathcal P(i_2 \mid i_{3:t},o_{1:t}) = \mathcal P(i_2) P(i2∣i3:t,o1:t)=P(i2)
以此类推。最终有:
P ( i 1 : t ∣ o 1 : t ) = ∏ k = 1 t − 1 P ( i k ) ⋅ P ( i t ∣ o 1 : t ) \mathcal P(i_{1:t} \mid o_{1:t}) = \prod_{k=1}^{t-1} \mathcal P(i_k) \cdot \mathcal P(i_t \mid o_{1:t}) P(i1:t∣o1:t)=k=1∏t−1P(ik)⋅P(it∣o1:t)
那
∏
k
=
1
t
−
1
P
(
i
k
)
\prod_{k=1}^{t-1} \mathcal P(i_k)
∏k=1t−1P(ik)如何求解?由于第一项是初始概率,这里以第二项为例:
P
(
i
2
)
=
∫
i
1
P
(
i
1
,
i
2
)
d
i
1
=
∫
i
1
P
(
i
2
∣
i
1
)
⋅
P
(
i
1
)
d
i
1
\begin{aligned} \mathcal P(i_2) & = \int_{i_1} \mathcal P(i_1,i_2) di_1 \\ & = \int_{i_1} \mathcal P(i_2 \mid i_1) \cdot \mathcal P(i_1) di_1 \end{aligned}
P(i2)=∫i1P(i1,i2)di1=∫i1P(i2∣i1)⋅P(i1)di1
其中
P
(
i
2
∣
i
1
)
\mathcal P(i_2 \mid i_1)
P(i2∣i1)是动态模型中隐变量
i
1
→
i
2
i_1 \to i_2
i1→i2的状态转移概率,
P
(
i
1
)
\mathcal P(i_1)
P(i1)是初始概率,因此可以求出
P
(
i
2
)
\mathcal P(i_2)
P(i2)的结果。
同理,第三项求解过程如下:
P
(
i
3
)
=
∫
i
1
,
i
2
P
(
i
1
,
i
2
,
i
3
)
d
i
1
,
i
2
=
∫
i
1
,
i
2
P
(
i
3
∣
i
1
,
i
2
)
⋅
P
(
i
1
,
i
2
)
d
i
1
,
i
2
\begin{aligned} \mathcal P(i_3) & = \int_{i_1,i_2} \mathcal P(i_1,i_2,i_3) di_1,i_2 \\ & = \int_{i_1,i_2} \mathcal P(i_3 \mid i_1,i_2) \cdot \mathcal P(i_1,i_2) di_1,i_2 \end{aligned}
P(i3)=∫i1,i2P(i1,i2,i3)di1,i2=∫i1,i2P(i3∣i1,i2)⋅P(i1,i2)di1,i2
由于齐次马尔可夫假设,有:
P
(
i
3
∣
i
1
,
i
2
)
=
P
(
i
3
∣
i
2
)
\mathcal P(i_3 \mid i_1,i_2) = \mathcal P(i_3 \mid i_2)
P(i3∣i1,i2)=P(i3∣i2)。此时该项中不含
i
1
i_1
i1,将积分号后移,最终表示为:
P
(
i
3
)
=
∫
i
2
P
(
i
3
∣
i
2
)
[
∫
i
1
P
(
i
1
,
i
2
)
d
i
1
]
d
i
2
=
∫
i
2
P
(
i
3
∣
i
2
)
⋅
P
(
i
2
)
d
i
2
\begin{aligned} \mathcal P(i_3) & = \int_{i_2} \mathcal P(i_3 \mid i_2) \left[\int_{i_1}\mathcal P(i_1,i_2) di_1\right] di_2 \\ & = \int_{i_2} \mathcal P(i_3 \mid i_2) \cdot \mathcal P(i_2) di_2 \end{aligned}
P(i3)=∫i2P(i3∣i2)[∫i1P(i1,i2)di1]di2=∫i2P(i3∣i2)⋅P(i2)di2
P
(
i
2
)
\mathcal P(i_2)
P(i2)上面刚求解完,
P
(
i
3
∣
i
2
)
\mathcal P(i_3 \mid i_2)
P(i3∣i2)是隐变量
i
2
→
i
3
i_2 \to i_3
i2→i3的状态转移概率,以此可以求出
P
(
i
3
)
\mathcal P(i_3)
P(i3)的结果。
以此类推,最终 可以求出
∏
k
=
1
t
−
1
P
(
i
k
)
\prod_{k=1}^{t-1} \mathcal P(i_k)
∏k=1t−1P(ik)。并且可以发现,该式中的项不与
P
(
i
t
∣
o
1
:
t
)
\mathcal P(i_{t}\mid o_{1:t})
P(it∣o1:t)存在关联关系,因此可视作常数。从而有:
P
(
i
1
:
t
∣
o
1
:
t
)
=
∏
k
=
1
t
−
1
P
(
i
k
)
⋅
P
(
i
t
∣
o
1
:
t
)
∝
P
(
i
t
∣
o
1
:
t
)
\begin{aligned} \mathcal P(i_{1:t} \mid o_{1:t}) & = \prod_{k=1}^{t-1} \mathcal P(i_k) \cdot \mathcal P(i_t \mid o_{1:t}) \\ & \propto \mathcal P(i_t \mid o_{1:t}) \end{aligned}
P(i1:t∣o1:t)=k=1∏t−1P(ik)⋅P(it∣o1:t)∝P(it∣o1:t)
这只是基于视频逻辑的一个认识,中间有取巧的部分,欢迎大家批评指正。
序列重要性采样的推导过程
在重要性权重
W
t
\mathcal W_{t}
Wt满足如下关系的条件下,推导
W
t
\mathcal W_{t}
Wt和
W
t
−
1
\mathcal W_{t-1}
Wt−1的关联关系:
W
t
∝
P
(
i
1
:
t
∣
o
1
:
t
)
Q
(
i
1
:
t
∣
o
1
:
t
)
\mathcal W_{t} \propto \frac{\mathcal P(i_{1:t} \mid o_{1:t})}{\mathcal Q(i_{1:t} \mid o_{1:t})}
Wt∝Q(i1:t∣o1:t)P(i1:t∣o1:t)
观察
P
(
i
1
:
t
∣
o
1
:
t
)
\mathcal P(i_{1:t} \mid o_{1:t})
P(i1:t∣o1:t),使用条件概率公式展开:
推导的目标是找出
P
(
i
1
:
t
∣
o
1
:
t
)
\mathcal P(i_{1:t} \mid o_{1:t})
P(i1:t∣o1:t)与
P
(
i
1
:
t
−
1
∣
o
1
:
t
−
1
)
\mathcal P(i_{1:t-1} \mid o_{1:t-1})
P(i1:t−1∣o1:t−1)之间的关联关系,而对应
Q
\mathcal Q
Q中的变量关系不去深究。
由于
P
(
o
1
:
t
)
\mathcal P(o_{1:t})
P(o1:t)是基于观测变量的‘联合概率分布’,因此将其视作已知量(常数)
C
1
\mathcal C_1
C1。
P
(
i
1
:
t
∣
o
1
:
t
)
=
P
(
i
1
:
t
,
o
1
:
t
)
P
(
o
1
:
t
)
=
1
C
1
P
(
i
1
:
t
,
o
1
:
t
)
\begin{aligned} \mathcal P(i_{1:t} \mid o_{1:t}) & = \frac{\mathcal P(i_{1:t},o_{1:t})}{\mathcal P(o_{1:t})} \\ & = \frac{1}{\mathcal C_1} \mathcal P(i_{1:t},o_{1:t}) \end{aligned}
P(i1:t∣o1:t)=P(o1:t)P(i1:t,o1:t)=C11P(i1:t,o1:t)
后续目标是将
P
(
i
1
:
t
−
1
∣
o
1
:
t
−
1
)
\mathcal P(i_{1:t-1} \mid o_{1:t-1})
P(i1:t−1∣o1:t−1)凑出来:
- 将联合概率分布
P
(
i
1
:
t
,
o
1
:
t
)
\mathcal P(i_{1:t},o_{1:t})
P(i1:t,o1:t)对
o
t
o_t
ot展开:
基于’观测独立性假设‘,有:P ( o t ∣ i 1 : t , o 1 : t − 1 ) = P ( o t ∣ i t ) \mathcal P(o_t \mid i_{1:t},o_{1:t-1}) = \mathcal P(o_t \mid i_t) P(ot∣i1:t,o1:t−1)=P(ot∣it)
P ( i 1 : t ∣ o 1 : t ) = 1 C 1 P ( o t ∣ i 1 : t , o 1 : t − 1 ) ⋅ P ( i 1 : t , o 1 : t − 1 ) = 1 C 1 P ( o t ∣ i t ) ⋅ P ( i 1 : t , o 1 : t − 1 ) \begin{aligned} \mathcal P(i_{1:t} \mid o_{1:t}) & = \frac{1}{\mathcal C_1} \mathcal P(o_t \mid i_{1:t},o_{1:t-1}) \cdot \mathcal P(i_{1:t},o_{1:t-1}) \\ & = \frac{1}{\mathcal C_1} \mathcal P(o_t \mid i_t) \cdot \mathcal P(i_{1:t},o_{1:t-1}) \end{aligned} P(i1:t∣o1:t)=C11P(ot∣i1:t,o1:t−1)⋅P(i1:t,o1:t−1)=C11P(ot∣it)⋅P(i1:t,o1:t−1) - 将上述结果产生的联合概率分布
P
(
i
1
:
t
,
o
1
:
t
−
1
)
\mathcal P(i_{1:t},o_{1:t-1})
P(i1:t,o1:t−1)对
i
t
i_t
it展开:
根据’齐次马尔可夫假设‘,有:P ( i t ∣ i 1 : t − 1 , o 1 : t − 1 ) = P ( i t ∣ i t − 1 ) \mathcal P(i_t \mid i_{1:t-1},o_{1:t-1}) = \mathcal P(i_t \mid i_{t-1}) P(it∣i1:t−1,o1:t−1)=P(it∣it−1)
P ( i 1 : t ∣ o 1 : t ) = 1 C 1 P ( o t ∣ i t ) ⋅ P ( i t ∣ i 1 : t − 1 , o 1 : t − 1 ) ⋅ P ( o 1 : t − 1 , o 1 : t − 1 ) = 1 C 1 P ( o t ∣ i t ) ⋅ P ( i t ∣ i t − 1 ) ⋅ P ( i 1 : t − 1 , o 1 : t − 1 ) \begin{aligned} \mathcal P(i_{1:t} \mid o_{1:t}) & = \frac{1}{\mathcal C_1} \mathcal P(o_t \mid i_t) \cdot \mathcal P(i_t \mid i_{1:t-1},o_{1:t-1}) \cdot \mathcal P(o_{1:t-1},o_{1:t-1}) \\ & = \frac{1}{\mathcal C_1} \mathcal P(o_t \mid i_t) \cdot \mathcal P(i_t \mid i_{t-1}) \cdot \mathcal P(i_{1:t-1},o_{1:t-1}) \end{aligned} P(i1:t∣o1:t)=C11P(ot∣it)⋅P(it∣i1:t−1,o1:t−1)⋅P(o1:t−1,o1:t−1)=C11P(ot∣it)⋅P(it∣it−1)⋅P(i1:t−1,o1:t−1)
将上述结果的联合概率分布 P ( i 1 : t − 1 , o 1 : t − 1 ) \mathcal P(i_{1:t-1},o_{1:t-1}) P(i1:t−1,o1:t−1)对 i 1 : t − 1 i_{1:t-1} i1:t−1展开:
同上,P ( o 1 : t − 1 ) \mathcal P(o_{1:t-1}) P(o1:t−1)也是观测变量的’联合概率分布‘,将其视作常数C 2 \mathcal C_2 C2。
P ( i 1 : t ∣ o 1 : t ) = 1 C 1 P ( o t ∣ i t ) ⋅ P ( i t ∣ i t − 1 ) ⋅ P ( i 1 : t − 1 ∣ o 1 : t − 1 ) ⋅ P ( o 1 : t − 1 ) = C 2 C 1 P ( o t ∣ i t ) ⋅ P ( i t ∣ i t − 1 ) ⋅ P ( i 1 : t − 1 ∣ o 1 : t − 1 ) \begin{aligned} \mathcal P(i_{1:t} \mid o_{1:t}) & = \frac{1}{\mathcal C_1} \mathcal P(o_t\mid i_t) \cdot \mathcal P(i_t \mid i_{t-1}) \cdot \mathcal P(i_{1:t-1} \mid o_{1:t-1}) \cdot \mathcal P(o_{1:t-1}) \\ & = \frac{\mathcal C_2}{\mathcal C_1} \mathcal P(o_t \mid i_t) \cdot \mathcal P(i_t\mid i_{t-1}) \cdot \mathcal P(i_{1:t-1} \mid o_{1:t-1}) \end{aligned} P(i1:t∣o1:t)=C11P(ot∣it)⋅P(it∣it−1)⋅P(i1:t−1∣o1:t−1)⋅P(o1:t−1)=C1C2P(ot∣it)⋅P(it∣it−1)⋅P(i1:t−1∣o1:t−1)
至此,将
P
(
i
1
:
t
−
1
∣
o
1
:
t
−
1
)
\mathcal P(i_{1:t-1} \mid o_{1:t-1})
P(i1:t−1∣o1:t−1)凑出来了。
于此同时,对人为设定的简单分布
Q
\mathcal Q
Q进行假设。假设存在容易采样的概率分布
Q
\mathcal Q
Q,使得
Q
(
i
1
:
t
∣
o
1
:
t
)
\mathcal Q(i_{1:t} \mid o_{1:t})
Q(i1:t∣o1:t)和
Q
(
i
1
:
t
−
1
∣
o
1
:
t
−
1
)
\mathcal Q(i_{1:t-1} \mid o_{1:t-1})
Q(i1:t−1∣o1:t−1)之间满足如下关系:
这里和视频部分存在一些出入,该操作只是上面操作的’完整版‘,因为
Q
\mathcal Q
Q和
P
\mathcal P
P不同,他并没有’齐次马尔可夫假设‘和’观测独立性假设‘的支持。;
这里令
Q
(
o
1
:
t
)
=
C
1
′
,
Q
(
o
1
:
t
−
1
)
=
C
2
′
\mathcal Q(o_{1:t}) = \mathcal C_1',\mathcal Q(o_{1:t-1})=\mathcal C_2'
Q(o1:t)=C1′,Q(o1:t−1)=C2′。
Q
(
i
1
:
t
∣
o
1
:
t
)
=
Q
(
o
1
:
t
−
1
)
Q
(
o
1
:
t
)
Q
(
i
t
∣
i
1
:
t
−
1
,
o
1
:
t
)
⋅
Q
(
o
t
∣
i
1
:
t
−
1
,
o
1
:
t
−
1
)
⋅
Q
(
i
1
:
t
−
1
∣
o
1
:
t
−
1
)
=
C
2
′
C
1
′
Q
(
i
t
∣
i
1
:
t
−
1
,
o
1
:
t
)
⋅
Q
(
o
t
∣
i
1
:
t
−
1
,
o
1
:
t
−
1
)
⋅
Q
(
i
1
:
t
−
1
∣
o
1
:
t
−
1
)
\begin{aligned} \mathcal Q(i_{1:t} \mid o_{1:t}) & = \frac{\mathcal Q(o_{1:t-1})}{\mathcal Q(o_{1:t})} \mathcal Q(i_t \mid i_{1:t-1},o_{1:t}) \cdot \mathcal Q(o_t \mid i_{1:t-1},o_{1:t-1}) \cdot \mathcal Q(i_{1:t-1} \mid o_{1:t-1}) \\ & = \frac{\mathcal C_2'}{\mathcal C_1'}\mathcal Q(i_t \mid i_{1:t-1},o_{1:t}) \cdot \mathcal Q(o_t \mid i_{1:t-1},o_{1:t-1}) \cdot \mathcal Q(i_{1:t-1} \mid o_{1:t-1}) \end{aligned}
Q(i1:t∣o1:t)=Q(o1:t)Q(o1:t−1)Q(it∣i1:t−1,o1:t)⋅Q(ot∣i1:t−1,o1:t−1)⋅Q(i1:t−1∣o1:t−1)=C1′C2′Q(it∣i1:t−1,o1:t)⋅Q(ot∣i1:t−1,o1:t−1)⋅Q(i1:t−1∣o1:t−1)
则
W
t
\mathcal W_t
Wt和
W
t
−
1
\mathcal W_{t-1}
Wt−1之间存在如下关联关系:
将
C
2
C
1
,
C
2
′
C
1
′
\frac{\mathcal C_2}{\mathcal C_1},\frac{\mathcal C_2'}{\mathcal C_1'}
C1C2,C1′C2′消掉,用
∝
\propto
∝替代,因为它们是可求的项,不影响迭代规律。
W
t
∝
P
(
i
1
:
t
∣
o
1
:
t
)
Q
(
i
1
:
t
∣
o
1
:
t
)
=
C
2
C
1
P
(
o
t
∣
i
t
)
⋅
P
(
i
t
∣
i
t
−
1
)
⋅
P
(
i
1
:
t
−
1
∣
o
1
:
t
−
1
)
C
2
′
C
1
′
Q
(
i
t
∣
i
1
:
t
−
1
,
o
1
:
t
)
⋅
Q
(
o
t
∣
i
1
:
t
−
1
,
o
1
:
t
−
1
)
⋅
Q
(
i
1
:
t
−
1
∣
o
1
:
t
−
1
)
∝
P
(
o
t
∣
i
t
)
⋅
P
(
i
t
∣
i
t
−
1
)
Q
(
i
t
∣
i
1
:
t
−
1
,
o
1
:
t
)
⋅
Q
(
o
t
∣
i
1
:
t
−
1
,
o
1
:
t
−
1
)
⋅
P
(
i
1
:
t
−
1
∣
o
1
:
t
−
1
)
Q
(
i
1
:
t
−
1
∣
o
1
:
t
−
1
)
=
P
(
o
t
∣
i
t
)
⋅
P
(
i
t
∣
i
t
−
1
)
Q
(
i
t
∣
i
1
:
t
−
1
,
o
1
:
t
)
⋅
Q
(
o
t
∣
i
1
:
t
−
1
,
o
1
:
t
−
1
)
⋅
W
t
−
1
\begin{aligned} \mathcal W_t & \propto \frac{\mathcal P(i_{1:t} \mid o_{1:t})}{\mathcal Q(i_{1:t} \mid o_{1:t})} \\ & = \frac{\frac{\mathcal C_2}{\mathcal C_1} \mathcal P(o_t \mid i_t) \cdot \mathcal P(i_t\mid i_{t-1}) \cdot \mathcal P(i_{1:t-1} \mid o_{1:t-1})}{\frac{\mathcal C_2'}{\mathcal C_1'}\mathcal Q(i_t \mid i_{1:t-1},o_{1:t}) \cdot \mathcal Q(o_t \mid i_{1:t-1},o_{1:t-1}) \cdot \mathcal Q(i_{1:t-1} \mid o_{1:t-1})} \\ & \propto \frac{\mathcal P(o_t \mid i_t) \cdot \mathcal P(i_t \mid i_{t-1})}{\mathcal Q(i_t \mid i_{1:t-1},o_{1:t}) \cdot \mathcal Q(o_t \mid i_{1:t-1},o_{1:t-1})} \cdot \frac{\mathcal P(i_{1:t-1} \mid o_{1:t-1})}{\mathcal Q(i_{1:t-1} \mid o_{1:t-1})} \\ & = \frac{\mathcal P(o_t \mid i_t) \cdot \mathcal P(i_t \mid i_{t-1})}{\mathcal Q(i_t \mid i_{1:t-1},o_{1:t}) \cdot \mathcal Q(o_t \mid i_{1:t-1},o_{1:t-1})} \cdot \mathcal W_{t-1} \end{aligned}
Wt∝Q(i1:t∣o1:t)P(i1:t∣o1:t)=C1′C2′Q(it∣i1:t−1,o1:t)⋅Q(ot∣i1:t−1,o1:t−1)⋅Q(i1:t−1∣o1:t−1)C1C2P(ot∣it)⋅P(it∣it−1)⋅P(i1:t−1∣o1:t−1)∝Q(it∣i1:t−1,o1:t)⋅Q(ot∣i1:t−1,o1:t−1)P(ot∣it)⋅P(it∣it−1)⋅Q(i1:t−1∣o1:t−1)P(i1:t−1∣o1:t−1)=Q(it∣i1:t−1,o1:t)⋅Q(ot∣i1:t−1,o1:t−1)P(ot∣it)⋅P(it∣it−1)⋅Wt−1
至此,得到了
t
t
t时刻重要性权重
W
t
\mathcal W_t
Wt与
t
−
1
t-1
t−1时刻的
W
t
−
1
\mathcal W_{t-1}
Wt−1的关联关系。在采样的过程中,我们只在初始时刻采集了
N
N
N个样本,从而构成了
N
N
N个重要性权重,而后续时刻的样本均通过前一时刻的结果计算得到:
t
=
1
:
W
1
(
1
)
,
⋯
,
W
1
(
N
)
t
=
k
:
W
k
(
i
)
←
W
k
−
1
(
i
)
(
i
=
1
,
2
,
⋯
,
N
)
\begin{aligned} & t=1: \quad \mathcal W_1^{(1)},\cdots,\mathcal W_1^{(N)} \\ & t = k: \quad \mathcal W_k^{(i)} \gets \mathcal W_{k-1}^{(i)}\quad (i=1,2,\cdots,N) \end{aligned}
t=1:W1(1),⋯,W1(N)t=k:Wk(i)←Wk−1(i)(i=1,2,⋯,N)
关于简单分布 Q \mathcal Q Q的补充(2022/11/3)
相比于概率分布 P \mathcal P P,概率分布 Q \mathcal Q Q是人设定的易于采样的分布,对于 Q \mathcal Q Q的相关假设也更宽松。
在视频和其他文献中,对于
Q
(
i
1
:
t
∣
o
1
:
t
)
\mathcal Q(i_{1:t} \mid o_{1:t})
Q(i1:t∣o1:t)的假设表示如下:
Q
(
i
1
:
t
∣
o
1
:
t
)
=
Q
(
i
t
∣
i
1
:
t
−
1
,
o
1
:
t
)
⋅
Q
(
i
1
:
t
−
1
∣
o
1
:
t
−
1
)
\mathcal Q(i_{1:t}\mid o_{1:t}) = \mathcal Q(i_t \mid i_{1:t-1},o_{1:t}) \cdot \mathcal Q(i_{1:t-1} \mid o_{1:t-1})
Q(i1:t∣o1:t)=Q(it∣i1:t−1,o1:t)⋅Q(i1:t−1∣o1:t−1)
从而得到如下的迭代结果:
W
t
∝
P
(
o
t
∣
i
t
)
⋅
P
(
i
t
∣
i
t
−
1
)
Q
(
i
t
∣
i
1
:
t
−
1
,
o
1
:
t
)
⋅
W
t
−
1
\mathcal W_t \propto \frac{\mathcal P(o_t \mid i_t) \cdot \mathcal P(i_t \mid i_{t-1})}{\mathcal Q(i_t \mid i_{1:t-1},o_{1:t}) } \cdot \mathcal W_{t-1}
Wt∝Q(it∣i1:t−1,o1:t)P(ot∣it)⋅P(it∣it−1)⋅Wt−1
根据上面的推导,假设的等式明显是不相等的(要不然说是假设呢~),和上面的推导相比,该假设明显少了一项:
Q
(
o
t
∣
i
1
:
t
−
1
,
o
1
:
t
−
1
)
\mathcal Q(o_t \mid i_{1:t-1},o_{1:t-1})
Q(ot∣i1:t−1,o1:t−1)
对比结果,便于观察。
{
Q
(
i
1
:
t
∣
o
1
:
t
)
=
Q
(
i
t
∣
i
1
:
t
−
1
,
o
1
:
t
)
⋅
Q
(
i
1
:
t
−
1
∣
o
1
:
t
−
1
)
Q
(
i
1
:
t
∣
o
1
:
t
)
=
Q
(
i
t
∣
i
1
:
t
−
1
,
o
1
:
t
)
⋅
Q
(
o
t
∣
i
1
:
t
−
1
,
o
1
:
t
−
1
)
⋅
Q
(
i
1
:
t
−
1
∣
o
1
:
t
−
1
)
\begin{cases} \mathcal Q(i_{1:t}\mid o_{1:t}) = \mathcal Q(i_t \mid i_{1:t-1},o_{1:t}) \cdot \mathcal Q(i_{1:t-1} \mid o_{1:t-1}) \\ \mathcal Q(i_{1:t}\mid o_{1:t}) = \mathcal Q(i_t \mid i_{1:t-1},o_{1:t}) \cdot \mathcal Q(o_t \mid i_{1:t-1},o_{1:t-1}) \cdot \mathcal Q(i_{1:t-1} \mid o_{1:t-1}) \end{cases}
{Q(i1:t∣o1:t)=Q(it∣i1:t−1,o1:t)⋅Q(i1:t−1∣o1:t−1)Q(i1:t∣o1:t)=Q(it∣i1:t−1,o1:t)⋅Q(ot∣i1:t−1,o1:t−1)⋅Q(i1:t−1∣o1:t−1)
为什么会少一项,或者说 这种假设的意义在哪?
个人理解:
在算法过程中,在 t t t时刻通过分布 Q \mathcal Q Q采样隐变量 i t ( k ) i_t^{(k)} it(k),自然要从关于 i t i_t it的后验分布中进行采样;
i t ( 1 ) , i t ( 2 ) , ⋯ , i t ( N ) ∼ Q ( i t ∣ ⋯ ) i_t^{(1)},i_t^{(2)},\cdots,i_t^{(N)} \sim \mathcal Q(i_t \mid \cdots) it(1),it(2),⋯,it(N)∼Q(it∣⋯)
并且,相比之下,观测变量 o t o_t ot是已知的,是给定的数据集合。它的后验结果本身对于迭代过程没有意义。因此, Q ( o t ∣ i 1 : t − 1 , o 1 : t ) \mathcal Q(o_t \mid i_{1:t-1},o_{1:t}) Q(ot∣i1:t−1,o1:t)和 C 1 , C 2 \mathcal C_1,\mathcal C_2 C1,C2类似,只是看作是一个常量。即:
Q ( i 1 : t ∣ o 1 : t ) ∝ Q ( i t ∣ i 1 : t − 1 , o 1 : t ) ⋅ Q ( i 1 : t − 1 ∣ o 1 : t − 1 ) \mathcal Q(i_{1:t}\mid o_{1:t}) \propto \mathcal Q(i_t \mid i_{1:t-1},o_{1:t}) \cdot \mathcal Q(i_{1:t-1} \mid o_{1:t-1}) Q(i1:t∣o1:t)∝Q(it∣i1:t−1,o1:t)⋅Q(i1:t−1∣o1:t−1)
下一节将继续介绍基于重采样(Resampling)的粒子滤波。
相关参考:
【PRML】高斯分布
机器学习-粒子滤波1-背景介绍
机器学习-粒子滤波2-重要性采样(Importance Sampling &SIS)
相关文章
- 【华为云技术分享】机器学习(02)——学习资料链接
- 鲲鹏云实验-Python+Jupyter机器学习基础环境
- 鲲鹏云实验-Python+Jupyter机器学习基础环境
- 机器学习笔记 - 时间序列使用机器学习进行预测
- 机器学习笔记 - 时间序列的混合模型
- 机器学习-NLP(一):朴素贝叶斯进行垃圾邮件检测
- 机器学习-时间序列(一):日期和时间处理
- 【关于时间序列的ML】项目 10 :用机器学习预测降雨
- 【关于时间序列的ML】项目 6 :机器学习中使用 LSTM 的时间序列
- 【关于时间序列的ML】项目 4 :使用机器学习预测迁移
- 【阶段三】Python机器学习32篇:机器学习项目实战:关联分析的基本概念和Apriori算法的数学演示
- OpenMLDB + Jupyter Notebook:快速搭建机器学习应用
- 基于机器学习的web异常检测——基于HMM的状态序列建模,将原始数据转化为状态机表示,然后求解概率判断异常与否
- 机器学习案例学习【每周一例】之 Titanic: Machine Learning from Disaster
- 《深度学习》李宏毅 -- task1机器学习介绍