
《深度学习》李宏毅 -- task1机器学习介绍
机器学习介绍
机器学习(Machine Learning),就是让机器自动找函数。如语音识别,就是让机器找一个函数,输入是声音信号,输出是对应的文字。如下棋,就是让机器找一个函数,输入是当前棋盘上黑子白子的位置,输出是下一步应该落子何处。
机器学习任务——我们想要机器找什么样的函数
1.回归(regression)
输出是数值。如房价、PM2.5预测。
2.二元分类(binary classification)
输出只有两种可能,正面或负面。
3.多元分类(multi-class classification)
输出当前输入属于既定N个类别的概率值,并将N个概率值中最大者所对应的类别作为正确答案。
4.生成(generation)
输出有结构的复杂东西。如翻译,画图。
机器学习相关的技术
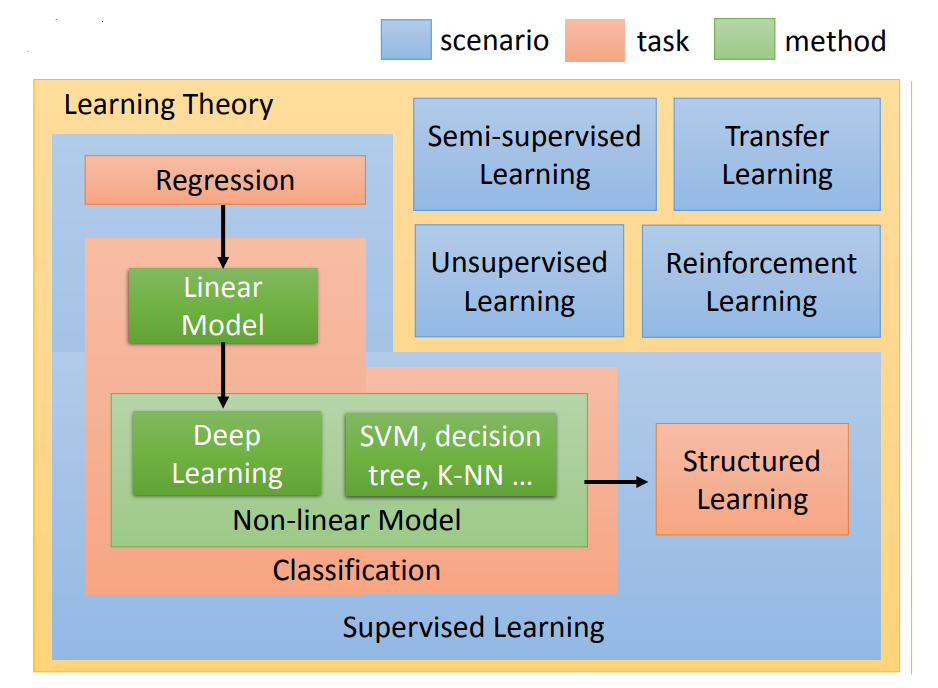
主要包括监督学习、半监督学习、迁移学习、无监督学习、监督学习中单结构化学习、强化学习
监督学习
相当于我们告诉他过去的PM2.5资料是什么,让他去预测未来新的PM2.5的资料。output往往没有办法用很自然的方式取得,需要人工的力量把它标注出来,这些function的output叫做label。
分类问题
这里说的是需要让机器做选择,一个是二分类,一个是多分类。这里还有一个模型选择,就是是否是线性的或者非线性的,比如线性最简单的就是线性回归,。深度学习大部分是非线性的 ,机器学习中SVM支持向量机也是非线性的。
半监督学习
其实就是少量有标记的数据,大部分是未标记的数据。让机器自己去识别,这里老师说这个可能没有标记的数据可能会对机器学习的学习过程有帮助,说后面会说。
迁移学习
假设我们要做猫和狗的分类问题,我们也一样,只有少量的有label的data。但是我们现在有大量的data,这些大量的data中可能有label也可能没有label。但是他跟我们现在要考虑的问题是没有什么特别的关系的,我们要分辨的是猫和狗的不同,但是这边有一大堆其他动物的图片还是动画图片(凉宫春日,御坂美琴)你有这一大堆不相干的图片,它到底可以带来什么帮助。这个就是迁移学习要讲的问题。
无监督学习
通俗,就是没有任何标记的数据下,让机器自己学习。
监督学习中的结构化学习
很多教科书说,机器学习只有分类和回归问题,其实还有大量的结构化学习,没有探究问题。
强化学习
原来Alpha GO就是强化学习的产物啊。
相关文章
- 【机器学习】K-Means聚类算法原理
- Coursera台大机器学习技法课程笔记03-Kernel Support Vector Machine
- Coursera台大机器学习课程笔记11 -- Nonlinear Transformation
- Coursera台大机器学习课程笔记8 -- Linear Regression
- Coursera台大机器学习课程笔记7 -- Noise and Error
- Coursera台大机器学习基础课程学习笔记1 -- 机器学习定义及PLA算法
- 机器学习基础题目
- 机器学习数学系列(4):参数估计
- 机器学习数学系列(2):微分选讲
- 【Machine Learning】机器学习及其基础概念简介
- 生产机器禁止ROOT远程SSH登录
- 机器学习笔记 - AutoML框架AutoKeras初体验
- 机器学习笔记 - 构建推荐系统(2) 深度推荐系统概览
- 机器学习笔记 - Keras中的回调函数Callback使用教程
- 数学建模暑期集训24:机器学习与Classification Learner工具箱实操
- Paper:《Multimodal Machine Learning: A Survey and Taxonomy,多模态机器学习:综述与分类》翻译与解读
- 机器学习笔记(六) ---- 支持向量机(SVM)
- 斯坦福《机器学习》Lesson4感想--1、Logistic回归中的牛顿方法
- 【大数据 & AI 人工智能】数据科学家必学的 9 个核心机器学习算法
- 机器学习——梯度下降法
- 【机器学习】P问题、NP问题、NP-hard、NP-C问题解析与举例理解
- 【机器学习】逻辑回归和线性回归的区别?(面试回答)
- 机器学习:Python实现聚类算法(三)之总结
- 最常用的Python库--机器学习和数据科学必备神器
- 机器学习入门(七)神经网络--代价函数、前向反向传播算法及问题