
KNN算法
算法 KNN
2023-09-14 09:00:32 时间
KNN算法的思想总结:
就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,
其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
K通常是不大于20的整数。
案例
下面通过一个简单的例子说明一下:如下图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
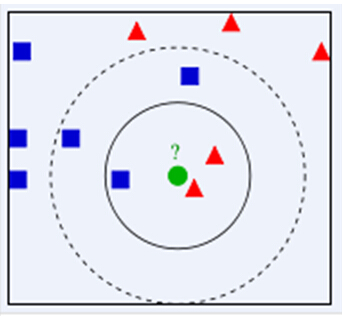
由此也说明了KNN算法的结果很大程度取决于K的选择。
计算举例的公式
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:

相关文章
- KNN算法与Kd树
- Java实现 蓝桥杯VIP 算法提高 多项式输出
- java算法 -- 归并排序
- 程序员的算法趣题Q53: 同数包夹
- Atitti knn实现的具体四个距离算法 欧氏距离、余弦距离、汉明距离、曼哈顿距离
- CV之IPE之MobiLenet:基于openpose利用CMU/MobilenetV2算法实现对多人体姿态估计检测(以勒布朗詹姆斯扣篮姿态为例)案例应用
- DL之CNN:利用CNN(keras, CTC loss, {image_ocr})算法实现OCR光学字符识别
- ML之kNNC:基于iris莺尾花数据集(PCA处理+三维散点图可视化)利用kNN算法实现分类预测
- ML之回归预测:利用十类机器学习算法(线性回归、kNN、SVM、决策树、随机森林、极端随机树、SGD、提升树、LightGBM、XGBoost)对波士顿数据集回归预测(模型评估、推理并导到csv)
- ML之kNN:k最近邻kNN算法的简介、应用、经典案例之详细攻略
- 基于鲸鱼算法优化的lssvm回归预测-附代码
- Python实现贝叶斯优化器(Bayes_opt)优化卷积神经网络分类模型(CNN分类算法)项目实战
- 关于KNN算法的新理解新运用
- Python实现KNN算法和交叉验证
- 机器学习算法原理归纳总结:回归、聚类、支持向量、推荐、降维与神经网络
- 深度学习(2)之机器学习(部分深度学习)算法原理简述