
ML之kNNC:基于iris莺尾花数据集(PCA处理+三维散点图可视化)利用kNN算法实现分类预测
2023-09-14 09:04:44 时间
ML之kNNC:基于iris莺尾花数据集(PCA处理+三维散点图可视化)利用kNN算法实现分类预测
目录
基于iris莺尾花数据集(PCA处理+三维散点图可视化)利用kNN算法实现分类预测
相关文章
ML之kNNC:基于iris莺尾花数据集(PCA处理+三维散点图可视化)利用kNN算法实现分类预测
ML之kNNC:基于iris莺尾花数据集(PCA处理+三维散点图可视化)利用kNN算法实现分类预测实现
基于iris莺尾花数据集(PCA处理+三维散点图可视化)利用kNN算法实现分类预测
设计思路

输出结果
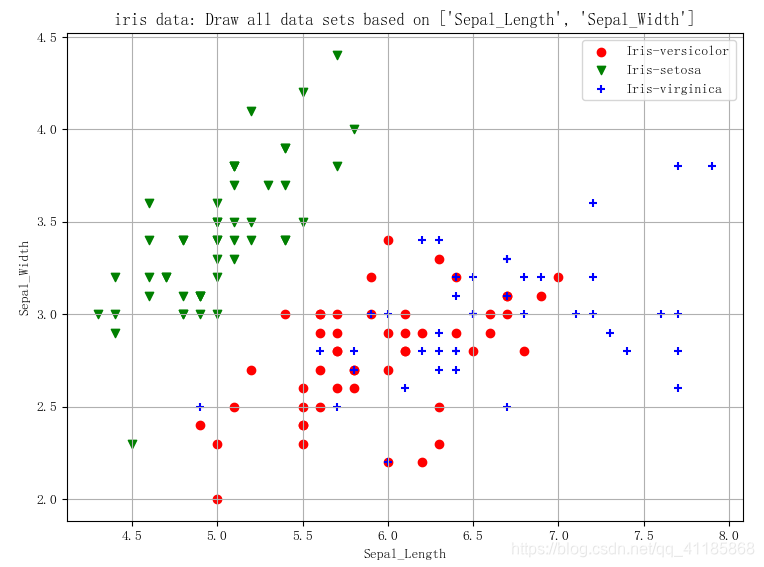
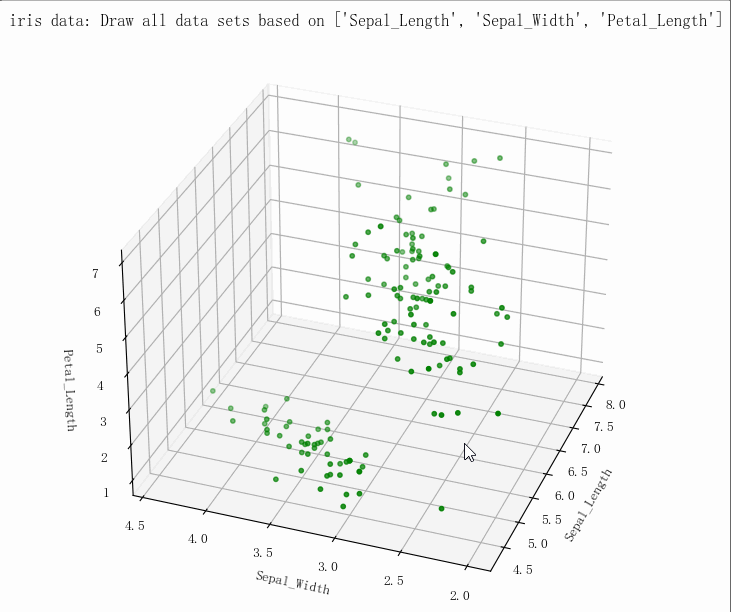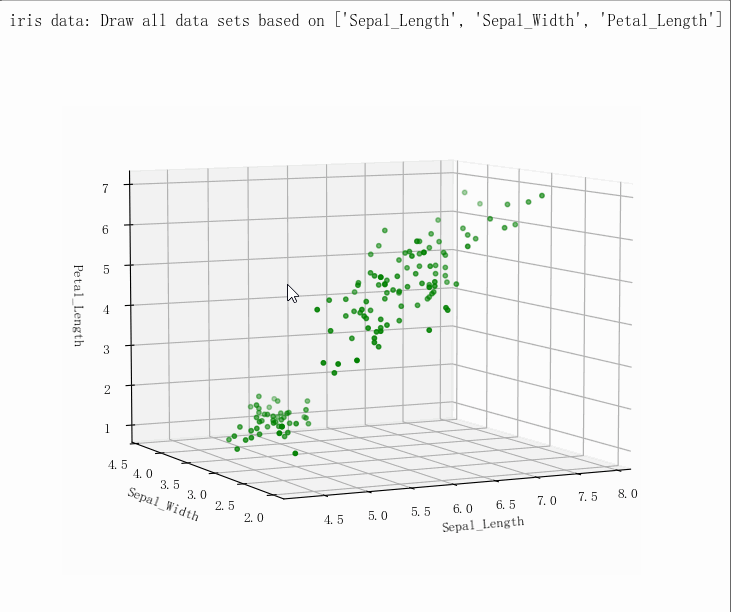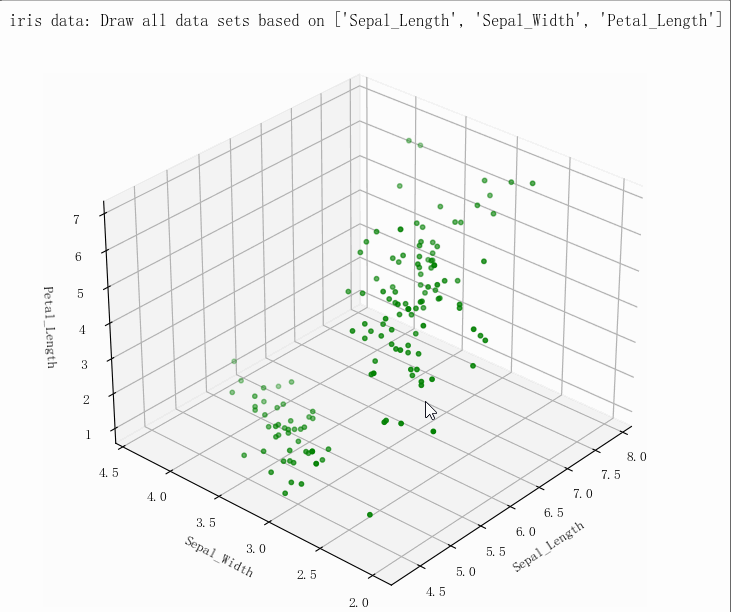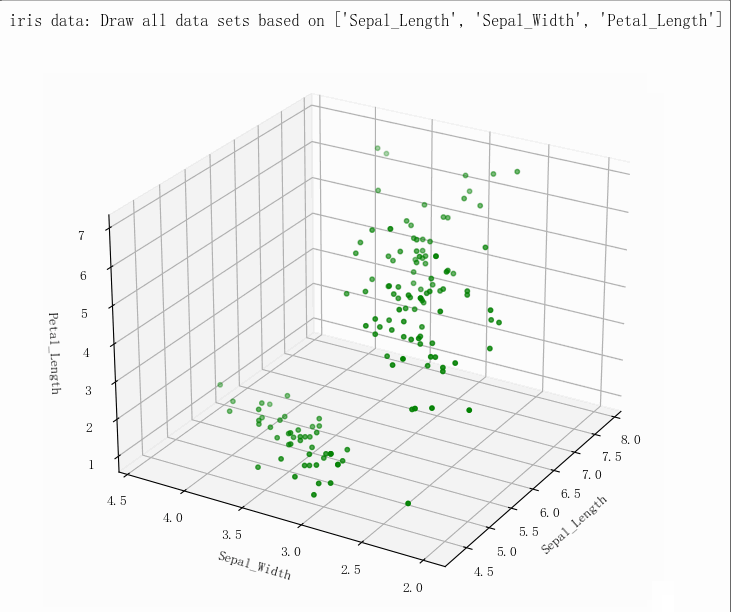
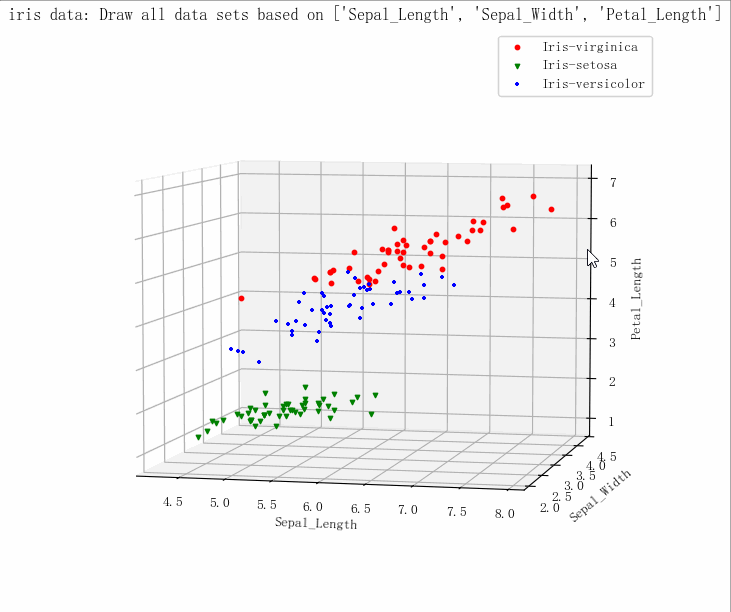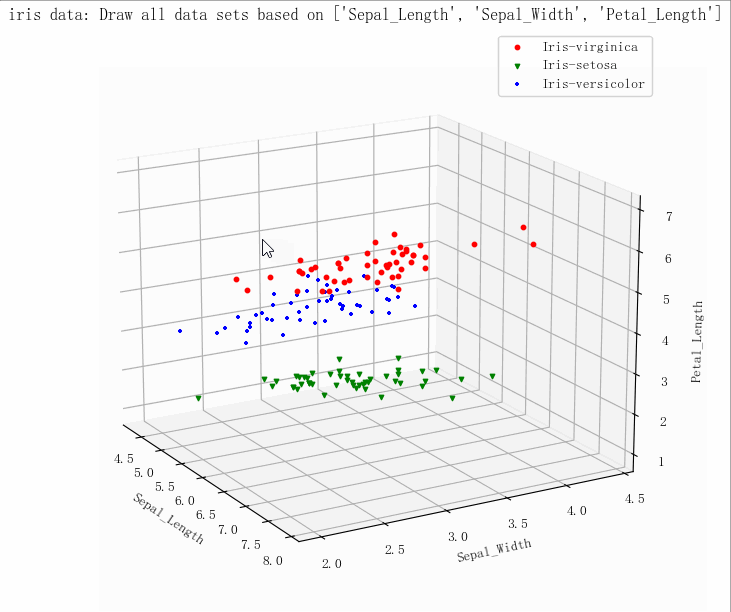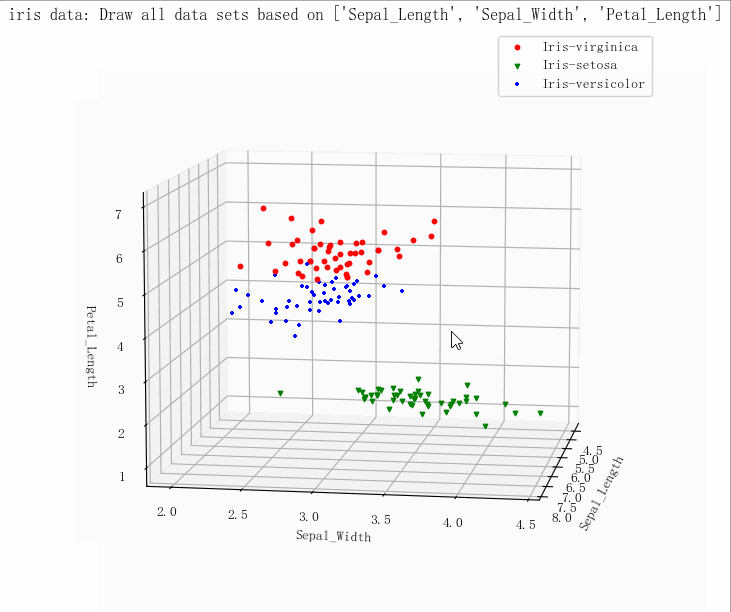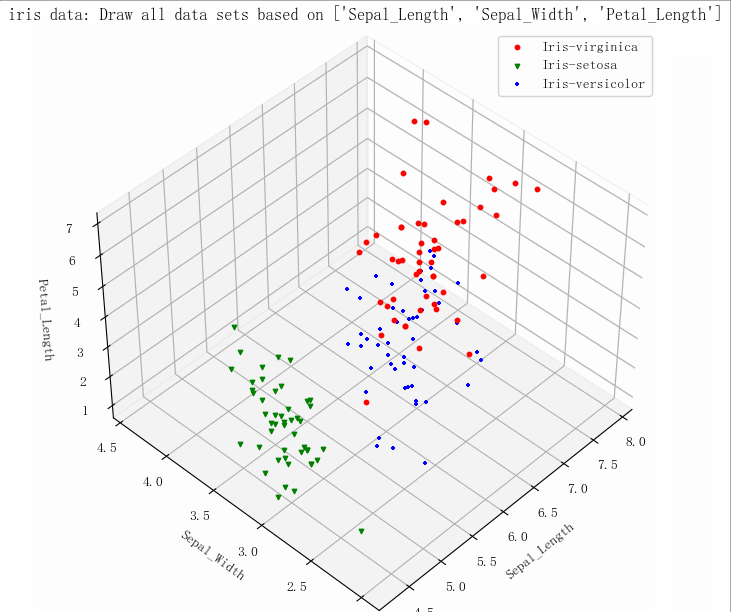
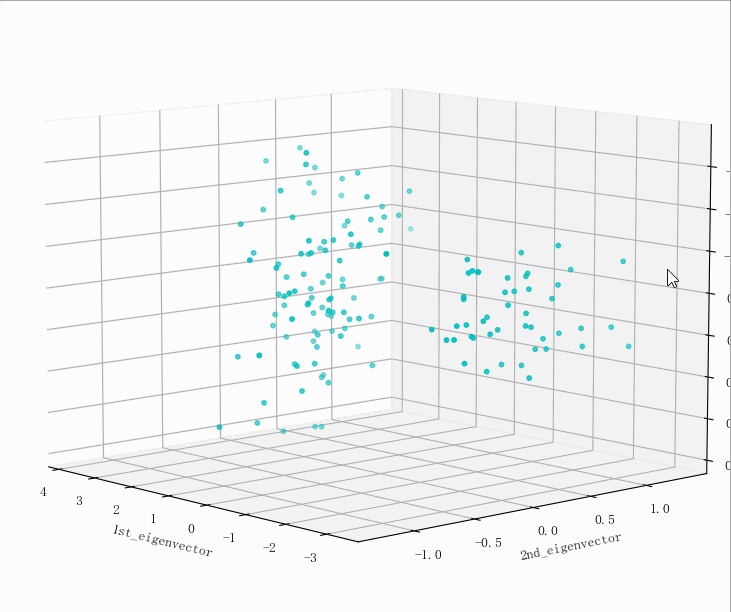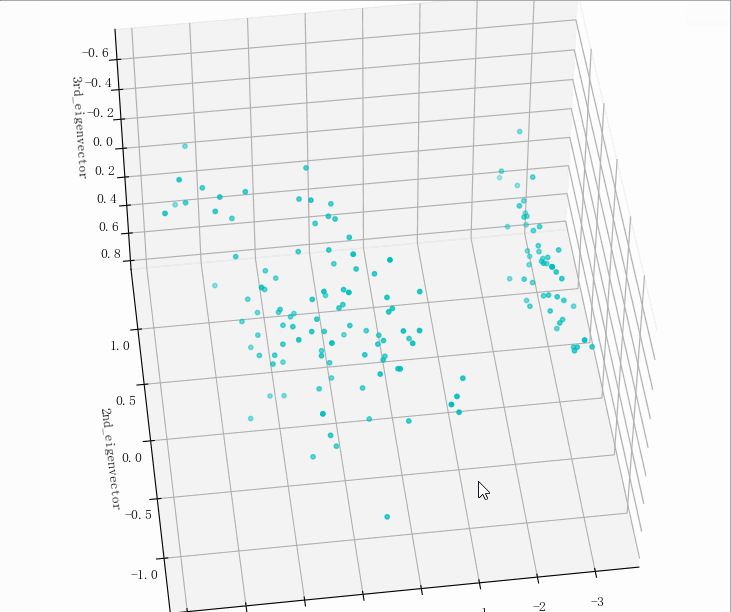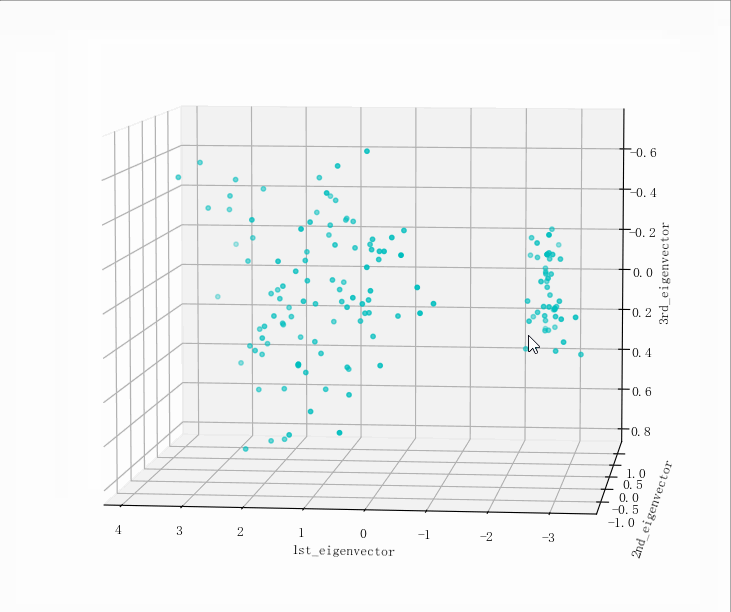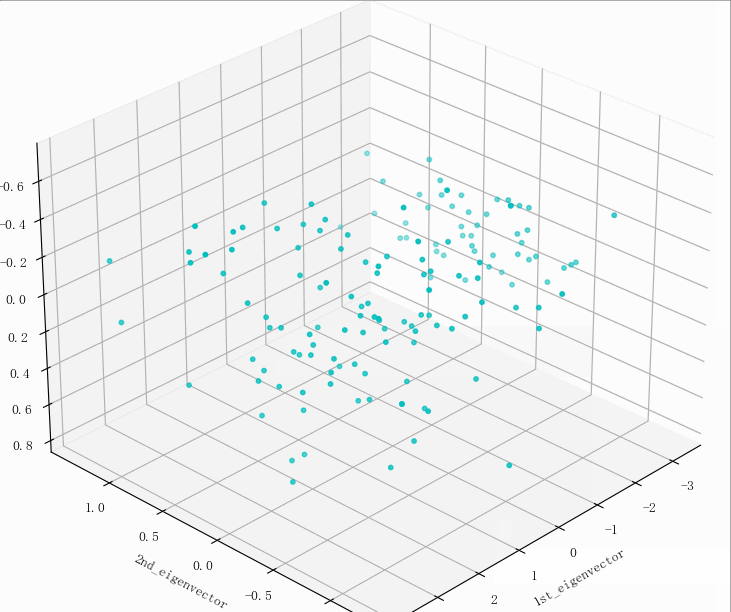
(149, 5)
5.1 3.5 1.4 0.2 Iris-setosa
0 4.9 3.0 1.4 0.2 Iris-setosa
1 4.7 3.2 1.3 0.2 Iris-setosa
2 4.6 3.1 1.5 0.2 Iris-setosa
3 5.0 3.6 1.4 0.2 Iris-setosa
4 5.4 3.9 1.7 0.4 Iris-setosa
(149, 5)
Sepal_Length Sepal_Width Petal_Length Petal_Width type
0 4.5 2.3 1.3 0.3 Iris-setosa
1 6.3 2.5 5.0 1.9 Iris-virginica
2 5.1 3.4 1.5 0.2 Iris-setosa
3 6.3 3.3 6.0 2.5 Iris-virginica
4 6.8 3.2 5.9 2.3 Iris-virginica
切分点: 29
label_classes: ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica']
kNNDIY模型预测,基于原数据: 0.95
kNN模型预测,基于原数据预测: [0.96666667 1. 0.93333333 1. 0.93103448]
kNN模型预测,原数据PCA处理后: [1. 0.96 0.95918367]
核心代码
class KNeighborsClassifier Found at: sklearn.neighbors._classification
class KNeighborsClassifier(NeighborsBase, KNeighborsMixin,
SupervisedIntegerMixin, ClassifierMixin):
"""Classifier implementing the k-nearest neighbors vote.
Read more in the :ref:`User Guide <classification>`.
Parameters
----------
n_neighbors : int, default=5
Number of neighbors to use by default for :meth:`kneighbors` queries.
weights : {'uniform', 'distance'} or callable, default='uniform'
weight function used in prediction. Possible values:
- 'uniform' : uniform weights. All points in each neighborhood
are weighted equally.
- 'distance' : weight points by the inverse of their distance.
in this case, closer neighbors of a query point will have a
greater influence than neighbors which are further away.
- [callable] : a user-defined function which accepts an
array of distances, and returns an array of the same shape
containing the weights.
algorithm : {'auto', 'ball_tree', 'kd_tree', 'brute'}, default='auto'
Algorithm used to compute the nearest neighbors:
- 'ball_tree' will use :class:`BallTree`
- 'kd_tree' will use :class:`KDTree`
- 'brute' will use a brute-force search.
- 'auto' will attempt to decide the most appropriate algorithm
based on the values passed to :meth:`fit` method.
Note: fitting on sparse input will override the setting of
this parameter, using brute force.
leaf_size : int, default=30
Leaf size passed to BallTree or KDTree. This can affect the
speed of the construction and query, as well as the memory
required to store the tree. The optimal value depends on the
nature of the problem.
p : int, default=2
Power parameter for the Minkowski metric. When p = 1, this is
equivalent to using manhattan_distance (l1), and euclidean_distance
(l2) for p = 2. For arbitrary p, minkowski_distance (l_p) is used.
metric : str or callable, default='minkowski'
the distance metric to use for the tree. The default metric is
minkowski, and with p=2 is equivalent to the standard Euclidean
metric. See the documentation of :class:`DistanceMetric` for a
list of available metrics.
If metric is "precomputed", X is assumed to be a distance matrix and
must be square during fit. X may be a :term:`sparse graph`,
in which case only "nonzero" elements may be considered neighbors.
metric_params : dict, default=None
Additional keyword arguments for the metric function.
n_jobs : int, default=None
The number of parallel jobs to run for neighbors search.
``None`` means 1 unless in a :obj:`joblib.parallel_backend` context.
``-1`` means using all processors. See :term:`Glossary <n_jobs>`
for more details.
Doesn't affect :meth:`fit` method.
Attributes
----------
classes_ : array of shape (n_classes,)
Class labels known to the classifier
effective_metric_ : str or callble
The distance metric used. It will be same as the `metric` parameter
or a synonym of it, e.g. 'euclidean' if the `metric` parameter set to
'minkowski' and `p` parameter set to 2.
effective_metric_params_ : dict
Additional keyword arguments for the metric function. For most
metrics
will be same with `metric_params` parameter, but may also contain the
`p` parameter value if the `effective_metric_` attribute is set to
'minkowski'.
outputs_2d_ : bool
False when `y`'s shape is (n_samples, ) or (n_samples, 1) during fit
otherwise True.
Examples
--------
>>> X = [[0], [1], [2], [3]]
>>> y = [0, 0, 1, 1]
>>> from sklearn.neighbors import KNeighborsClassifier
>>> neigh = KNeighborsClassifier(n_neighbors=3)
>>> neigh.fit(X, y)
KNeighborsClassifier(...)
>>> print(neigh.predict([[1.1]]))
[0]
>>> print(neigh.predict_proba([[0.9]]))
[[0.66666667 0.33333333]]
See also
--------
RadiusNeighborsClassifier
KNeighborsRegressor
RadiusNeighborsRegressor
NearestNeighbors
Notes
-----
See :ref:`Nearest Neighbors <neighbors>` in the online
documentation
for a discussion of the choice of ``algorithm`` and ``leaf_size``.
.. warning::
Regarding the Nearest Neighbors algorithms, if it is found that two
neighbors, neighbor `k+1` and `k`, have identical distances
but different labels, the results will depend on the ordering of the
training data.
https://en.wikipedia.org/wiki/K-nearest_neighbor_algorithm
"""
@_deprecate_positional_args
def __init__(self, n_neighbors=5,
*, weights='uniform', algorithm='auto', leaf_size=30,
p=2, metric='minkowski', metric_params=None, n_jobs=None, **
kwargs):
super().__init__(n_neighbors=n_neighbors, algorithm=algorithm,
leaf_size=leaf_size, metric=metric, p=p, metric_params=metric_params,
n_jobs=n_jobs, **kwargs)
self.weights = _check_weights(weights)
def predict(self, X):
"""Predict the class labels for the provided data.
Parameters
----------
X : array-like of shape (n_queries, n_features), \
or (n_queries, n_indexed) if metric == 'precomputed'
Test samples.
Returns
-------
y : ndarray of shape (n_queries,) or (n_queries, n_outputs)
Class labels for each data sample.
"""
X = check_array(X, accept_sparse='csr')
neigh_dist, neigh_ind = self.kneighbors(X)
classes_ = self.classes_
_y = self._y
if not self.outputs_2d_:
_y = self._y.reshape((-1, 1))
classes_ = [self.classes_]
n_outputs = len(classes_)
n_queries = _num_samples(X)
weights = _get_weights(neigh_dist, self.weights)
y_pred = np.empty((n_queries, n_outputs), dtype=classes_[0].
dtype)
for k, classes_k in enumerate(classes_):
if weights is None:
mode, _ = stats.mode(_y[neigh_indk], axis=1)
else:
mode, _ = weighted_mode(_y[neigh_indk], weights, axis=1)
mode = np.asarray(mode.ravel(), dtype=np.intp)
y_pred[:k] = classes_k.take(mode)
if not self.outputs_2d_:
y_pred = y_pred.ravel()
return y_pred
def predict_proba(self, X):
"""Return probability estimates for the test data X.
Parameters
----------
X : array-like of shape (n_queries, n_features), \
or (n_queries, n_indexed) if metric == 'precomputed'
Test samples.
Returns
-------
p : ndarray of shape (n_queries, n_classes), or a list of n_outputs
of such arrays if n_outputs > 1.
The class probabilities of the input samples. Classes are ordered
by lexicographic order.
"""
X = check_array(X, accept_sparse='csr')
neigh_dist, neigh_ind = self.kneighbors(X)
classes_ = self.classes_
_y = self._y
if not self.outputs_2d_:
_y = self._y.reshape((-1, 1))
classes_ = [self.classes_]
n_queries = _num_samples(X)
weights = _get_weights(neigh_dist, self.weights)
if weights is None:
weights = np.ones_like(neigh_ind)
all_rows = np.arange(X.shape[0])
probabilities = []
for k, classes_k in enumerate(classes_):
pred_labels = _y[:k][neigh_ind]
proba_k = np.zeros((n_queries, classes_k.size))
# a simple ':' index doesn't work right
for i, idx in enumerate(pred_labels.T): # loop is O(n_neighbors)
proba_k[all_rowsidx] += weights[:i]
# normalize 'votes' into real [0,1] probabilities
normalizer = proba_k.sum(axis=1)[:np.newaxis]
normalizer[normalizer == 0.0] = 1.0
proba_k /= normalizer
probabilities.append(proba_k)
if not self.outputs_2d_:
probabilities = probabilities[0]
return probabilities
相关文章
- 【NLP基础】英文关键词抽取RAKE算法
- 【万字专栏总结】离线强化学习(OfflineRL)总结(原理、数据集、算法、复杂性分析、超参数调优等)
- Nagle算法 TCP_NODELAY和TCP_CORK
- 智驾车技术栈 | Apollo规划模块详解(二):算法实现-数据检查及更新
- C++——随机数算法
- 最近大环境有些吃紧,赶紧用数据来分析一下算法岗!
- 【视频】K近邻KNN算法原理与R语言结合新冠疫情对股票价格预测|数据分享|附代码数据
- 什么是高维数据可视化的降维方法_数据降维具体算法有哪几种
- 数据结构面试常见问题总结怎么写_前端数据结构与算法面试题
- 数据分享|R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病|附代码数据
- 前端工程师leetcode算法面试之二叉树深度广度遍历
- [Nucleic Acids Research | 论文简读] 基于大规模数据整合的单细胞基因调控网络推理算法
- 复杂网络社区发现算法聚类分析全国电梯故障数据和可视化:诊断电梯“安全之殇”
- 【Android RTMP】Android Camera 视频数据采集预览 ( NV21 图像格式 | I420 图像格式 | NV21 与 I420 格式对比 | NV21 转 I420 算法 )
- 去除双下巴有奇招,浙大00后本科生全新美颜算法登上ACM SIGGRAPH
- Python 进阶指南(编程轻松进阶):十三、性能测量和大 O 算法分析
- Python用机器学习算法进行因果推断与增量、增益模型Uplift Modeling智能营销模型|附代码数据
- 算法-数组中的逆序对详解编程语言
- MySQL 数据库压缩备份:使用 Zip 算法快速高效压缩数据!(mysqlzip)
- 算法在Oracle中实现md5算法数据加密(Oracle中有md5)
- 数据、算法、算力将是资产管理公司新核心能力
- 删除重复数据的算法
- Javascript堆排序算法详解