
Hadoop & Spark & Hive & HBase
2023-09-27 14:24:27 时间
Hadoop:http://hadoop.apache.org/docs/r2.6.4/hadoop-project-dist/hadoop-common/SingleCluster.html
bin/hdfs namenode -formatsbin/start-dfs.sh
bin/hdfs dfs -mkdir /userbin/hdfs dfs -mkdir /user/<username>these are for testing:
bin/hdfs dfs -put etc/hadoop inputbin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep input output 'dfs[a-z.]+'bin/hdfs dfs -cat output/*testing results:
6 dfs.audit.logger4 dfs.class3 dfs.server.namenode.2 dfs.period2 dfs.audit.log.maxfilesize2 dfs.audit.log.maxbackupindex1 dfsmetrics.log1 dfsadmin1 dfs.servers1 dfs.replication1 dfs.fileHistoryServer
./sbin/mr-jobhistory-daemon.sh start historyserverSpark:start:
./sbin/start-slaves.sh spark://<your-computer-name>:7077You will see:
- Alive Workers: 1
This is for testing:
./bin/spark-shell --master spark://<your-computer-name>:7077You will see the scala shell.use :q to quit.
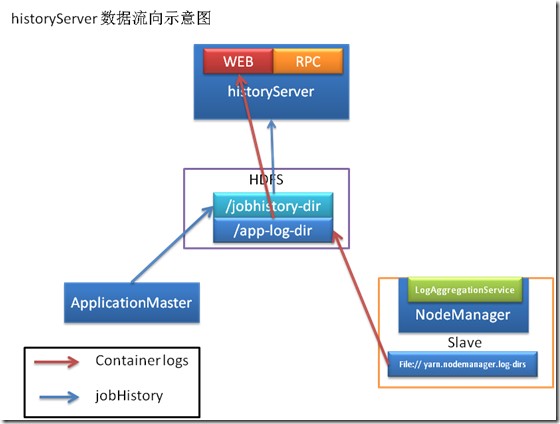
To see the history:
http://spark.apache.org/docs/latest/monitoring.htmlhttp://blog.chinaunix.net/uid-29454152-id-5641909.htmlhttp://www.cloudera.com/documentation/cdh/5-1-x/CDH5-Installation-Guide/cdh5ig_spark_configure.html
./sbin/start-history-server.sh
Hive:
Bug:
in mysql 5.7 you should use :
jdbc:mysql://localhost:3306/hivedb?useSSL=false&createDatabaseIfNotExist=true
start hiveserver2:
nohup hiveserver2 &
Bug:
User: is not allowed to impersonate anonymous (state=,code=0)
See more:
Hwi 界面Bug:
HWI WAR file not found at
pack the war file yourself, then copy it to the right place, then add needed setting into hive-site.xml
Problem: failed to create task or type componentdef- Or:
sudo apt-get install libjasperreports-java
sudo apt-get install ant
_________________________________________________________________________________not finished
自定义配置:
数据库连接软件:
默认 用户名就是登录账号 密码为空
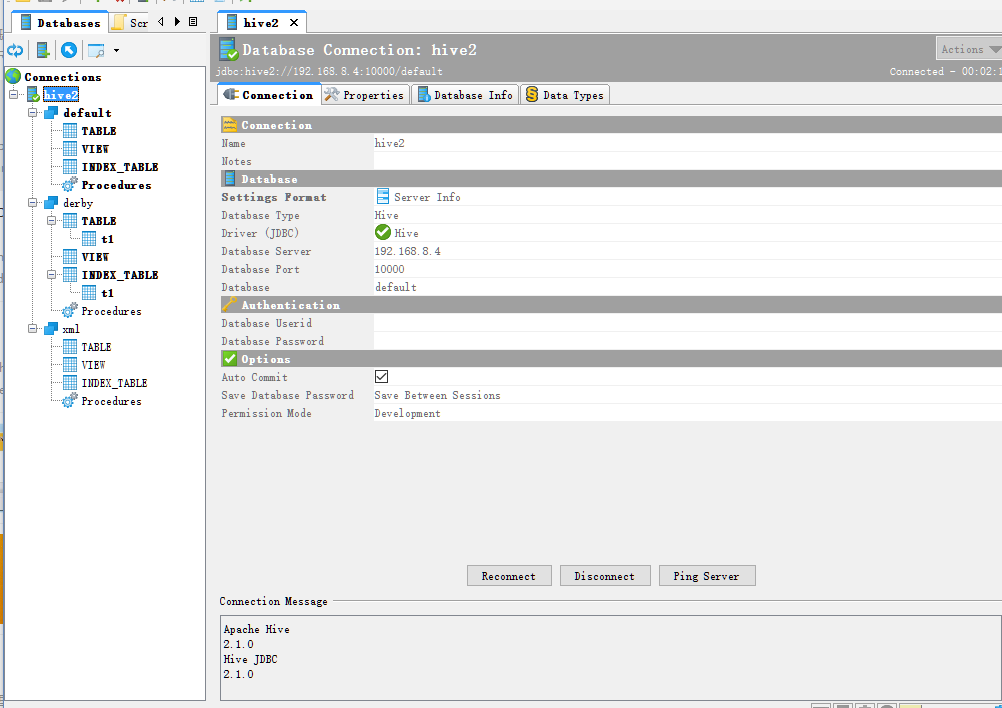
语法
more info:
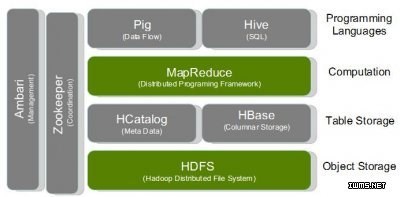
HBase
./bin/start-hbase.sh
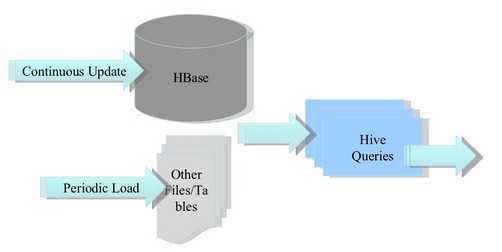
HBase & Hive
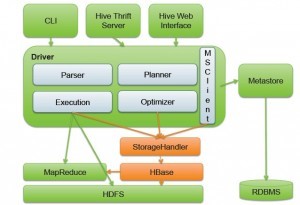
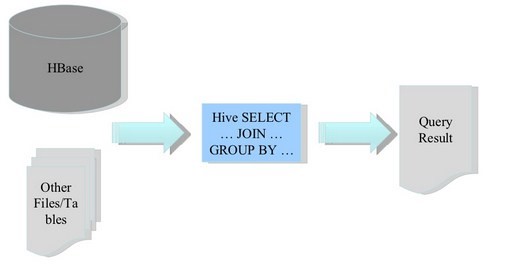
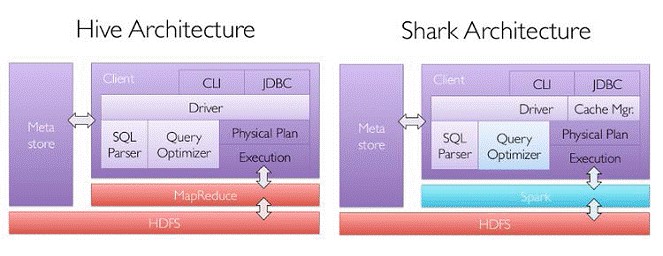
Hive & Shark & SparkSQL

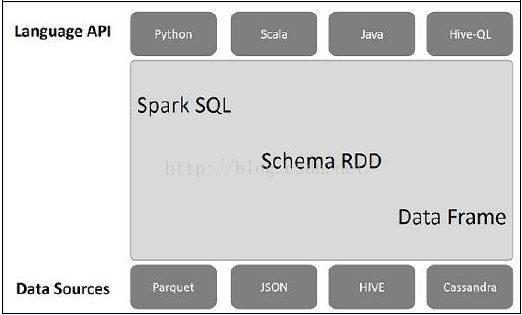
Spark SQL架构如下图所示:
http://blog.csdn.net/wzy0623/article/details/52249187
phoenix
- queryserver.py start
- jdbc:phoenix:thin:url=http://localhost:8765;serialization=PROTOBUF
Or:
phoenix-sqlline.py localhost:2181
相关文章
- HBase与Phoenix表映射
- HBase-建表(普通建表及预分区建表)
- HBase协处理器的使用(添加Solr二级索引)
- Hadoop+HBase 集群搭建
- Lars George , 关于Hadoop和HBase的Blog
- Hbase报错:org.apache.hadoop.hbase.ipc.ServerNotRunningYetException: Server is not running yet
- HBase 常用Shell命令
- HBase学习笔记——配置及Shell操作
- 《HBase管理指南》一1.8 Hadoop/ZooKeeper/HBase基本配置
- 《HBase实战》一导读
- 《HBase权威指南》一3.5 扫描
- HBase(四)HBase集群Shell操作
- HBase 是列式存储数据库吗
- 《HBase企业应用开发实战》—— 1.3 HBase与Hadoop的关系
- 《HBase企业应用开发实战》—— 3.4 数据模型的特殊属性
- 基于Hbase和SpringBoot的分布式HOS文件存储系统
- HBase 数据备份
- Zookeeper的作用,在Hadoop及hbase中具体作用
- CentOS 安装 hadoop hbase 使用 cloudera 版本。(一)
- 【HBase】HBase系列之HBase HA集群搭建