
hbase详解

HBase 1.3 发布,性能大幅提升详解数据库
Apache HBase 1.3.0版在2017年1月中旬正式发布了,新版本支持分层数据的压缩和多个方面的性能提升,像预写日志(WAL)、一个新的RPC机制,等等。HBase 1.3.0一共修复了1,700多个问题。 在一些像OpenTSDB的项目中,HBase通常被直接用作时序应用或者通过项目本身用作时序应用。在时序应用中,数据常常按照抵达时
日期 2023-06-12 10:48:40
Hbase(一)基础知识详解大数据
1、简介 HBase 是 BigTable 的开源 java 版本。是建立在 HDFS 之上,提供高可靠性、高性能、列存储、 可伸缩、实时读写 NoSQL 的数据库系统。 NoSQL = NO SQL &nb
日期 2023-06-12 10:48:40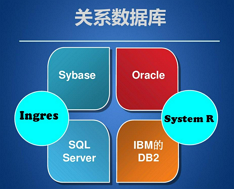
Hbase(三) hbase协处理器与二级索引详解大数据
一、协处理器—Coprocessor 1、 起源Hbase 作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执 行求和、计数、排序等操作。比如,在旧版本的( 0.92)Hbase 中,统计数据表的总行数,需 要使用 Counter 方法,执行一次 MapReduce Job 才能得到。虽然
日期 2023-06-12 10:48:40
Hadoop综合练习第十节–HBase安装部署详解大数据
1 运行环境说明 1.1 硬软件环境 l 主机操作系统:Windows 64 bit,双核4线程,主频2.2G,6G内存 l 虚拟软件:VMware® Workstation 9.0.0 build-812388 l 虚拟机操作系统:CentOS 64位,单核,1G内存 l JDK:1.7.0_55 64 bit l&
日期 2023-06-12 10:48:40
Hadoop综合练习第十一节–HBase作业详解大数据
1书面作业1:举例子说明HBase相对简单 1.1 书面作业题目1 请举出一例子,使用关系型数据库较难进行数据建模,而采用HBase则相对简单 1.2 回答 HBase的应用场景 l 存储大量的数据(100s TB级数据) l 需要很高的写吞吐量 l 在大规模数据集中进行很好性能的随机访问(按列) l 需要进行
日期 2023-06-12 10:48:40
HBase学习之路 (十)HBase表的设计原则详解大数据
建表高级属性 下面几个 shell 命令在 hbase 操作中可以起到很大的作用,且主要体现在建表的过程中,看 下面几个 create 属性 1、 BLOOMFILTER 默认是 NONE 是否使用布隆过虑及使用何种方式,布隆过滤可以每列族单独启用 使用 HColumnDescriptor.setBloomFilterType(NONE | ROW | ROWCOL) 对列族单独启用布隆
日期 2023-06-12 10:48:40HBase学习之路 (七)HBase 原理详解大数据
这张图是有一个错误点:应该是每一个 RegionServer 就只有一个 HLog,而不是一个 Region 有一个 HLog。 从HBase的架构图上可以看出,HBase中的组件包括Client、Zookeeper、HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等,接下来介绍他们的作
日期 2023-06-12 10:48:40HBase学习之路 (五)MapReduce操作Hbase详解大数据
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.
日期 2023-06-12 10:48:40HBase学习之路 (四)HBase的API操作详解大数据
Eclipse环境搭建 具体的jar的引入方式可以参考http://www.cnblogs.com/qingyunzong/p/8623309.html HBase API操作表和数据 1 import java.io.IOException; 2 import java.util.Date; 4 import org.apache.hadoop.conf.Configurat
日期 2023-06-12 10:48:40HBASE详解大数据
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$HADOOP_HOME/bin:${HBASE_HOME}:${ZK_HOME}/bin:$PATH 添加如下代码 configuration ! Site specific YARN configuration properties property name hbase.rootdir /n
日期 2023-06-12 10:48:40大数据时代数据库-云HBase架构&生态&实践详解大数据
存储量量/并发计算增大 现如今大量的中小型公司并没有大规模的数据,如果一家公司的数据量超过100T,且能通过数据产生新的价值,基本可以说是大数据公司了 。起初,一个创业公司的基本思路就是首先架构一个或者几个ECS,后面加入MySQL,如果有图片需求还可加入磁盘,该架构的基本能力包括事务、存储、索引和计算力。随着公司的慢慢发展,数据量在不断地增大,其通过MySQL及磁盘基本无法满足需
日期 2023-06-12 10:48:40Hbase一基础详解大数据
HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java。 是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,因此可以容错地存储海量稀疏的数据 行存储: – 优点:写入一次性完成,保持数据完整性 – 缺点:数据读取过程中产生冗余数据,若有少量数据可以忽略 列存储 – 优点:读取过程,不会产生冗余数据
日期 2023-06-12 10:48:40MapReduce操作HBase详解大数据
运行HBase时常会遇到个错误,我就有这样的经历。 ERROR: org.apache.hadoop.hbase.MasterNotRunningException: Retried 7 times 检查日志:org.apache.hadoop.ipc.RPC$VersionMismatch: Protocol org.apache.hadoop.hdfs.protocol.
日期 2023-06-12 10:48:40HBase学习详解大数据
HBase简介 HBase是Apache Hadoop的数据库,能够对大型数据提供随机、实时的读写访问,是Google的BigTable的开源实现。HBase的目标是存储并处理大型的数据,更具体地说仅用普通的硬件配置,能够处理成千上万的行和列所组成的大型数据库。 HBase是一个开源的、分布式的、多版本的、面向列的存储模型。可以直接使用本地文件系统也可使用Hadoop的HDFS文件存储系统。为
日期 2023-06-12 10:48:40Hbase安装详解大数据
环境:CentOS6.5 Hadoop2.7.2 HBase1.2.1 1.安装好 hadoop 集群,并启动 [[email protected] ~]$ sh hadoop-2.7.2/sbin/start-dfs.sh [[email protected] ~]$ sh hadoop-2.7.2/sbin/start-yarn.sh 查看
日期 2023-06-12 10:48:40HBase数据库检索性能优化策略详解大数据
HBase 数据表介绍 HBase 数据库是一个基于分布式的、面向列的、主要用于非结构化数据存储用途的开源数据库。其设计思路来源于 Google 的非开源数据库”BigTable”。 HDFS 为 HBase 提供底层存储支持,MapReduce 为其提供计算能力,ZooKeeper 为其提供协调服务和 failover(失效转移的备份操作)机制。Pig 和 Hive 为 HBase 提供
日期 2023-06-12 10:48:40HBase深入学习(1)详解大数据
HBase架构组成 HBase采用Master/Slave架构搭建集群,它隶属于Hadoop生态系统,由一下类型节点组成:HMaster节点、HRegionServer节点、ZooKeeper集群,而在底层,它将数据存储于HDFS中,因而涉及到HDFS的NameNode、DataNode等,总体结构如下: 其中HMaster节点用于: 管理HRegionServer,实现其负载均衡
日期 2023-06-12 10:48:40HBase RegionServer详解大数据
RegionServer是HBase集群运行在每个工作节点上的服务。它是整个HBase系统的关键所在,一方面它维护了Region的状态,提供了对于Region的管理和服务;另一方面,它与Master交互,参与Master的分布式协调管理。 MemStoreFlusher MemStoreFlusher主要功能是将MemStore刷新到文件中,当满足一下条件时会出发MemStore执行flush
日期 2023-06-12 10:48:40hadoop2.2.0_hbase0.96_zookeeper3.4.5全分布式安装文档下载详解大数据
此页面是否是列表页或首页?未找到合适正文内容。
日期 2023-06-12 10:48:40HBase集群安装过程中的问题集锦详解大数据
1、HRegionServer启动不正常 在namenode上执行jps,则可看到hbase启动是否正常,进程如下: [[email protected] bin]# jps26341 HMaster26642 Jps7840 ResourceManager7524 NameNode7699 SecondaryNameNode 由上可见,hadoop启动正常。HBase少了一个进程,猜测应该
日期 2023-06-12 10:48:40HBase数据迁移到Kafka实战详解大数据
1.概述 在实际的应用场景中,数据存储在HBase集群中,但是由于一些特殊的原因,需要将数据从HBase迁移到Kafka。正常情况下,一般都是源数据到Kafka,再有消费者处理数据,将数据写入HBase。但是,如果逆向处理,如何将HBase的数据迁移到Kafka呢?今天笔者就给大家来分享一下具体的实现流程。 一般业务场景如下,数据源头产生数据,进入Kafka,然后由消费者(如Flink、Spa
日期 2023-06-12 10:48:40HBase BulkLoad批量写入数据实战详解大数据
1.概述 在进行数据传输中,批量加载数据到HBase集群有多种方式,比如通过HBase API进行批量写入数据、使用Sqoop工具批量导数到HBase集群、使用MapReduce批量导入等。这些方式,在导入数据的过程中,如果数据量过大,可能耗时会比较严重或者占用HBase集群资源较多(如磁盘IO、HBase Handler数等)。今天这篇博客笔者将为大家分享使用HBase BulkLoad的方式
日期 2023-06-12 10:48:40HBase查询优化详解大数据
1.概述 HBase是一个实时的非关系型数据库,用来存储海量数据。但是,在实际使用场景中,在使用HBase API查询HBase中的数据时,有时会发现数据查询会很慢。本篇博客将从客户端优化和服务端优化两个方面来介绍,如何提高查询HBase的效率。 这里,我们先给大家介绍如何从客户端优化查询速度。 2.1 客户端优化 客户端查询HBase,均通过HBase API的来获取数据,如果在实现代码
日期 2023-06-12 10:48:40剖析HBase负载均衡和性能指标详解大数据
1.概述 在分布式系统中,负载均衡是一个非常重要的功能,在HBase中通过Region的数量来实现负载均衡,HBase中可以通过hbase.master.loadbalancer.class来实现自定义负载均衡算法。下面将为大家剖析HBase负载均衡的相关内容以及性能指标。 在HBase系统中,负载均衡是一个周期性的操作,通过负载均衡来均匀分配Region到各个RegionServer上,
日期 2023-06-12 10:48:40HBase MemStore和Compaction剖析详解大数据
1.概述 客户端读写数据是先从Zookeeper中获取RegionServer的元数据信息,比如Region地址信息。在执行数据写操作时,HBase会先写MemStore,为什么会写到MemStore。本篇博客将为读者剖析HBase MemStore和Compaction的详细内容。 HBase的内部通信和数据交互是通过RPC来实现,关于HBase的RPC实现机制下篇博客为大家分享。客户端
日期 2023-06-12 10:48:40HBase – Phoenix剖析详解大数据
1.概述 在《Hadoop-Drill深度剖析》一文当中,给大家介绍了Drill的相关内容,就实时查询来说,Drill基本能够满足要求,同时还可以做一个简单业务上的聚合,如果在使用Hive做一些简单的业务统计(不涉及多维度,比如CUBE,ROLLUP之类的函数),只是用一些基本的聚合函数或是JOIN ON之类的,Drill基本满足要求,而且响应速度可比OLTP。今天给大家剖析的是另外一种工具,
日期 2023-06-12 10:48:40高可用Hadoop平台-HBase集群搭建详解大数据
1.概述 今天补充一篇HBase集群的搭建,这个是高可用系列遗漏的一篇博客,今天抽时间补上,今天给大家介绍的主要内容目录如下所示: 基础软件的准备 HBase介绍 HBase集群搭建 单点问题验证 那么,接下来我们开始今天的HBase集群搭建学习。 2.基础软件的准备 由于HBase的数据是存放在HDFS上的,所以我们在使用HBase时,确保Hadoop集群已搭建完成,并运行
日期 2023-06-12 10:48:40Hbase 常用工具类详解编程语言
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor;
日期 2023-06-12 10:48:40kafka+storm+hbase详解编程语言
project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.x
日期 2023-06-12 10:48:40hbase-1.2.1之协处理器的源码学习详解编程语言
Observer: RegionServerObserver:钩子函数主要是针对对region的管理的,比如merge,writeWAL,createRElplicationEndPoint,replicateLogEntries. RegionObserver:钩子函数主要是针对client端对region上的数据操作,比如get,put,delete,batchMutate等。 Mast
日期 2023-06-12 10:48:40hbase-1.2.1之scan、batch操作的源码学习详解编程语言
Scan操作: 1、 实例化Configuration类 Configuration conf = HbaseConfiguration.create(); 同Get操作。 2、 实例化HTable类 HTable hTable = new HTable(conf,tableName); 同Get操作。 3、 实例化Scan类 Scan
日期 2023-06-12 10:48:40