
云时代的大数据存储-云HBase
纵观数据库发展的几十年,从网状数据库、层次数据库到RDBMS数据库,在最近几年的NewSQL的兴起,加上开源的运动,再加上云的特性,可以说是日新月异。在20世纪80年代后,大部分的业务确定了使用RDBMS数据为存储基础。新世纪开始,随着互联网的发展,数据量的增大,慢慢RDBMS数据库撑不住了,就出现了读写分离策略。随着压力增加,Master撑不住了,这时就要分库了,把关联不大的数据分开部署,一些join查询不能用了,需要借助中间层。随着数据量的进一步增加,一个表的记录越来越大,查询就变得很慢,于是又得搞分表,比如按ID取模分成多个表以减少单个表的记录数。经历过这些事的人都知道过程是多么的折腾。在不同的场景下,就出现各自优秀的分布式数据库,比如在文档型存储下的MongoDB,KV类型的Redis,再比如今天讲的列族类型的HBase。
大数据时代数据存储的特点为:基础量大、增长快、计算与存储的实时性要求迫切、支持时效性短、易发散、易产生脏数据,这些HBase自出生起,就满足这些需求。在大数据时代,我们认为HBase是公认的大数据存储。HBase的原型出自Google的BigTable,这个跟大数据的GFS及MapReduce齐名的三篇论文,由此开创了大数据时代。目前在阿里,已经有上万台的HBase集群,在各个场景下有广泛的应用。
为什么要上云,需要了解到HBase本身比较复杂,这涉及到分布式、数据存储、响应延迟,索引等一些分布式、数据库的知识,对于运维好这个复杂系统还是有一定的难度;要有很好的使用姿势,虽然API比较简单,但是各种组合情况下,畅玩好HBase还是需要一定的功力; 上云是趋势,自己去基于ECS建设又不太了解云环境下,怎么正确部署HBase,怎么跟OSS等云上组件配合。
为此,我们提供云HBase加上专家服务 解决以上3个问题
最后,HBase在阿里集团使用了6年之久,已经在HBase的性能、运维等积累了大量的经验,我们希望把这些回馈给客户,例如:我们仅仅单条低字节高频写入情况就比社区版本高出30%+的性能。
目前提供的价值点有,以下几点:
高可靠: 数据备份,数据可靠性9个9 高可用:Master节点强制HA机制,出现问题后直接切换 易运维:一键构建、配置修改、一键扩容、自动备份、数据流入 高性能:比如开源性能大幅度提升30%+ 低成本:后续本地盘、云盘、OSS分级别存储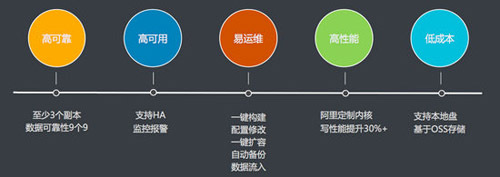
技术架构
从技术架构层面看,大致如下:
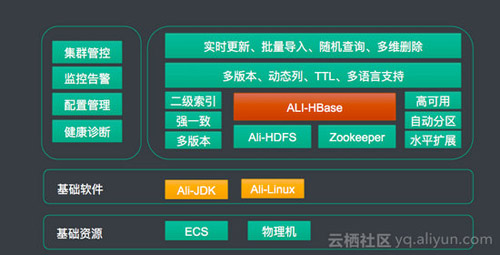
基础资源层:我们底层使用了ECS及本地磁盘的架构,保证在低成本的同时又具备高性能
基础软件层,我们使用了ALi-JDK及ALi-Liunx,这两个都有专门的团队在维护,对云HBase的贡献,比如:改进gc算法减少毛刺,改进linux中断提升性能。
HBase内核层,目前使用是跟阿里集团内部一致的版本,也就是说内部所有的性能优化、功能增强在公有云的客户都可以享受到。这些包括但不限于:提升读写性能、增强稳定性、降低磁盘、网络抖动引起的毛刺等等。 -另外就是运维平台,逐步完善,后续会包括 监控报警、配置管理、健康诊断等等 易于运维的功能。
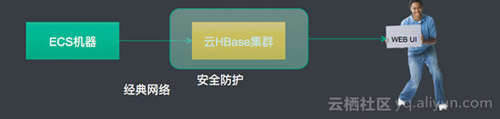
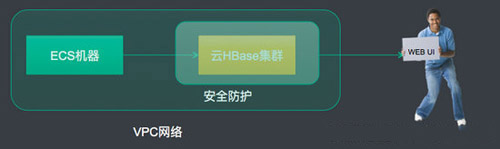
目前支持两种访问网络类型,第一种是经典网络、第二种是VPC网络。区别就是VPC再加了一层网络隔离。
经典网络:
VPC网络:
使用场景
HBase作为默认的大数据时代的存储,基本解决以下三大类的场景:
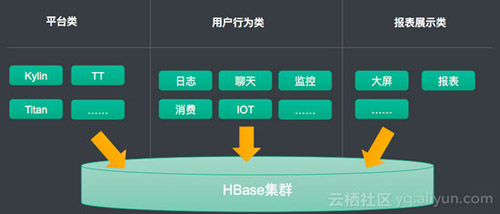
平台类,基本存放是平台的产品,就是其它软件的存储,比如 目前很就行的kylin,阿里内部的日志同步工具TT,图组件Titan等。此类存放的往往平台的数据,有时候往往是无业务含义的。作为平台的底层存储使用。
用户行为类,此类主要是面向各个业务系统。这里的用户不仅仅指的人,也包括物,比如物联网。在阿里主要还是人产生的数据,比如:淘宝收藏夹、交易数据、旺旺聊天记录等等。这里使用比较直接,就直接存放HBase,再读取。难度就是需要支持千万级别的并发写访问及读取,需要解决服务质量的问题,比如GC了,就出现大量的毛刺。
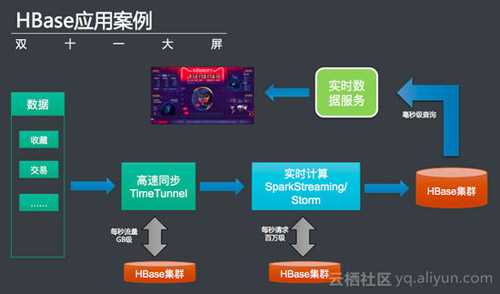
报表类的需求,比如报表、大屏等,最出名的就是阿里巴巴的天猫双十一大屏。
基本上:Mysql支持小数据量,查询较为复杂的数据应用;HBase支持大数据,查询较为简单的数据应用。
后续计划
一些功能,比如同步等,产品化,直接从rds及离线系统导入数据到云HBase系统中
完善云HBase功能,不断做精细化
提供HBase on OSS的能力,降低数据存储的成本
提供双集群多写多度的能力,做多区多地域容灾
本文作者:佚名
来源:51CTO
大数据上云-HDFS数据迁移方案 大数据时代,大数据处理系统已成为各行业各类公司经营过程中不可或缺的重要生产系统之一,不管是辅助业务经营分析,为企业运营提供决策数据依据,还是进行用户行为信息分析,提供精确的用户画像,在数据计算处理(批式、流式)、查询分析都发挥着重要的作用。Hadoop 作为目前应用最为广泛的分布式大数据平台,基本都采用HDFS分布式文件系统作为整个hadoop体系的存储底座,负责数据的存储与管理。在上云过程中,阿里云提供一系列便利的迁移服务和工具来实现HDFS的数据迁移上云,用户可根据自身网络带宽情况,选择离线迁移及在线迁移两种方式进行HDFS的数据迁移。本文主要讨论在上云过程中HDFS数据迁移的方案和步骤
HBase介绍: 走进大数据存储的世界 HBase非常好地契合了大数据存储的特性。 首先是HBase具有突出的数据写入能力,在面对大数据的特性时,可以快速地把数据处理消化。 另外HBase具有超强弹性升缩能力,在面对大数据的体量的时候,能够无限水平扩展来存储数据。 同时,HBase具有强大的业务适应能力,适应业务的变化多端,从而能够满足大数据的特点。 最后,HBase具有高效的多维删除能力,来满足大数据真实性、脏数据的特点,能够帮助用户快速处理脏数据和过期 数据。 简而言之,HBase是一个为大数据而生的数据库。
全方位认识HBase:一个值得拥有的NoSQL数据库(一) 前言:说起HBase这门技术,在认知上对于稍微接触或使用过它的人来讲,可能只是百千数据库中一个很普通的库,大概就像我对Redis的认知一样:缓存嘛!可对于HBase,我确实是带着某些感情在的。今日突然萌生了一个生趣的想法,想抛开技术的视角,从情感的角度,像写小说一样,写写这位老朋友,这可能会有点滑稽吧,不过我觉得很放松。
阿里云HBase数据安全实践 受近期“微盟员工删库事件”的影响,大量客户咨询云HBase在备份恢复方面的能力。数据是客户的核心资产,数据安全是生命线,本文总结了云HBase在数据安全方面的使用实践,希望可以帮助用户建立更完善的数据安全保护。
JindoFS: 云上大数据的高性能数据湖存储方案 JindoFS 是EMR打造的高性能大数据存储服务,可以为不同的计算引擎提供不同的存储服务,可以根据应用的场景来选择不同的存储模式。在2019杭州云栖大会大数据生态专场,阿里巴巴计算平台事业部EMR团队技术专家殳鑫鑫和Intel大数据团队软件开发经理徐铖共同向大家分享了云上大数据的高性能数据湖存储方案JindoFS的产生背景、架构以及与Intel DCPM的性能评测。
混合云模式下 MaxCompute + Hadoop 混搭大数据架构实践 2019杭州云栖大会大数据企业级服务专场,由斗鱼大数据高级专家张龙带来以 “混合云模式下 MaxCompute+Hadoop 混搭大数据架构实践” 为题的演讲。本文讲述了从 Apache Hadoop 阶段到 Cloudera CDH 阶段斗鱼大数据架构的发展历程。提出了上云过程中斗鱼遇到的问题和跳战,包括数据安全、数据同步以及迁移任务。概括了混合云模式给斗鱼带来资源效率更高和资源成本更低的变化。
【大数据技术】什么是HBase ?所有的基础都在这儿了 2006 年10 月Google 发布三架马车之一的《Bigtable:A Distributed Storage System for Strctured Data》论文之后,Powerset 公司就宣布 HBase 在 Hadoop 项目中成立,作为子项目存在。
平台篇-58 HBase 平台实践和应用 HBase 是一个基于 Hadoop 的分布式、面向列的 Key-Value 存储系统,可以对需 要实时读写、随机访问大规模数据集的场景提供高可靠、高性能的服务,在大数 据相关领域应用广泛。HBase 可以对数据进行透明的切分,使得存储和计算本身 具有良好的水平扩展性。
相关文章
- 带你了解 HBase 数据模型和 HBase 架构
- 技术实操丨HBase 2.X版本的元数据修复及一种数据迁移方式
- Hadoop组件:HDFS(离线存储)、Hive(离线分析数仓)、HBase(实时读写)【Hive分析后的结果可以写入MySQL或HBase供实时调用】
- Hive、HBase对比【相同:HDFS作为底层存储】【区别:①Hive用于离线数据的批处理,Hbase用于实时数据的处理;②Hive是纯逻辑表,无物理存储功能,HBase是物理表,放非结构数据】
- ApsaraDB for HBase - 规格的的选择
- HBASE的集群搭建
- 基于HBase的大数据存储的应用场景分析
- HBase 学习一(基础入门).
- Hive、Pig、HBase的关系与区别
- 青云QingCloud推出HBase集群服务 支持SQL等高级功能
- HBase 的存储结构
- HBase概念学习(四)Java API之扫描和过滤器
- Java Hbase查询接口条件正确查询不到踩坑记录,查询大小写不敏感,存储必须小写
- 云HBase全面支持金融云可用区-支持实时安全风控金融时序大数据量存储及高并发访问
- HBase脚本命令
- Hbase理论要点
- 对给定的数据利用MapReduce编程实现数据的清洗和预处理,编程实现数据存储到HBase数据库,实现数据的增删改查操作接口
- Elasticsearch+Hbase实现海量数据秒回查询
- 利用Hbase做二度关系人脉存储
- HBase API
- hbase集群写不进去数据的问题追踪过程
- HBase行锁原理及实现
- HBase-1.2.4LruBlockCache实现分析(二)