
【Pytorch】第 4 章 :时间差异和 Q 学习
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在上一章中,我们通过蒙特卡洛方法解决了 MDP,这是一种无需环境先验知识的无模型方法。然而,在 MC 学习中,值函数和 Q 函数通常会更新到每一集结束。这可能会有问题,因为某些进程非常长,甚至无法终止。我们将在本章中使用时间差分( TD ) 方法来解决这个问题。在 TD 方法中,我们在一个 episode 的每个时间步更新动作值,这显着提高了学习效率。
本章将从设置 Cliff Walking 和 Windy Gridworld 环境游乐场开始,这将作为本章的主要讨论点用于 TD 控制方法。通过我们的分步指南,读者将获得用于离策略控制的 Q-learning 和用于在线策略控制的 SARSA 的实践经验。我们还将处理一个有趣的项目,出租车问题,并演示如何分别使用 Q-learning 和 SARSA 算法来解决它。最后,我们将通过奖金的方式介绍双 Q 学习算法。
我们将介绍以下食谱:
- 设置 Cliff Walking 环境游乐场
- 开发 Q 学习算法
- 设置 Windy Gridworld 环境游乐场
- 开发 SARSA 算法
- 用 Q-learning 解决出租车问题
- 用 SARSA 解决出租车问题
- 开发双 Q 学习算法
设置 Cliff Walking 环境游乐场
在第一个秘籍中,我们将从熟悉 Cliff Walking 环境开始,我们将在接下来的秘籍中使用 TD 方法解决这个问题。
Cliff Walking 是一个典型的gym环境,有很长的情节,而且不能保证终止。这是一个4 * 12板的网格问题。智能体在一个步骤中向上、向右、向下和向左移动。左下角的图块是代理的起点,右下角的图块是获胜点,如果到达该点,情节将结束。最后一行剩下的方块是悬崖,代理人踩到其中任何一个后都会重置到起始位置,但情节仍在继续。智能体采取的每一步都会产生 -1 奖励,但踩到悬崖除外,在悬崖上会产生 -100 奖励。
做好准备
要运行 Cliff Walking 环境,让我们首先在https://github.com/openai/gym/wiki/Table-of-environments的环境表中搜索它的名称。我们得到CliffWalking-v0并且还知道观察空间由一个从 0(左上图块)到 47(右下目标图块)的整数表示,并且有四种可能的动作(上 = 0,右 = 1,下= 2,左 = 3)。
怎么做...
让我们通过执行以下步骤来模拟 Cliff Walking 环境:
1.我们导入 Gym 库并创建 Cliff Walking 环境的实例:
>>> import gym
>>> env = gym.make("CliffWalking-v0")
>>> n_state = env.observation_space.n
>>> print(n_state)
48
>>> n_action = env.action_space.n
>>> print(n_action)
42.然后,我们重置环境:
>>> env.reset()
0代理以状态 36 作为左下图块开始。
3.然后,我们渲染环境:
>>> env.render()4.现在让我们无论如何做一个向下的运动,即使它是不可步行的:
>>> new_state, reward, is_done, info = env.step(2)
>>> env.render()
o o o o o o o o o o o o
o o o o o o o o o o o o
o o o o o o o o o o o o
x C C C C C C C C C C T代理人保持不动。现在,打印出我们刚刚获得的内容:
>>> print(new_state)
36
>>> print(reward)
-1同样,每个动作都会产生 -1 奖励:
>>> print(is_done)
False这一集还没有完成,因为代理还没有达到他们的目标:
>>> print(info)
{'prob': 1.0}这意味着运动是确定性的。
现在,让我们执行向上运动,因为它是可步行的:
>>> new_state, reward, is_done, info = env.step(0)
>>> env.render()
o o o o o o o o o o o o
o o o o o o o o o o o o
x o o o o o o o o o o o
o C C C C C C C C C C T打印出我们刚刚得到的:
>>> print(new_state)
24代理向上移动:
>>> print(reward)
-1这会产生 -1 奖励。
5.现在让我们尝试做一个向右和向下的运动:
>>> new_state, reward, is_done, info = env.step(1)
>>> new_state, reward, is_done, info = env.step(2)
>>> env.render()
o o o o o o o o o o o o
o o o o o o o o o o o o
o o o o o o o o o o o o
x C C C C C C C C C C T代理人踩到了悬崖,因此被重置为起点并获得 -100 的奖励:
>>> print(new_state)
36
>>> print(reward)
-100
>>> print(is_done)
False6.最后,让我们尝试走最短路径到达目标:
>>> new_state, reward, is_done, info = env.step(0)
>>> for _ in range(11):
... env.step(1)
>>> new_state, reward, is_done, info = env.step(2)
>>> env.render()
o o o o o o o o o o o o
o o o o o o o o o o o o
o o o o o o o o o o o o
o C C C C C C C C C C x
>>> print(new_state)
47
>>> print(reward)
-1
>>> print(is_done)
True这个怎么运作...
在第 1 步中,我们导入 Gym 库并创建 Cliff Walking 环境的实例。然后,我们在步骤 2中重置环境。
在第 3 步中,我们渲染环境,您将看到一个 4 * 12 矩阵,如下所示,代表一个网格,其中包含智能体站立的起始瓦片 (x)、目标瓦片 (T)、10 个悬崖瓦片 (C)、和普通瓷砖(o):

在第4、5和6步中,我们进行了各种移动,并查看了这些移动的各种结果和收到的奖励。
正如您所想象的,悬崖行走情节可能会很长甚至无穷无尽,因为踏上悬崖会重置游戏。而且越早达到目标越好,因为每一步都会得到-1或-100的奖励。在下一个秘籍中,我们将借助时间差分法解决悬崖行走问题。
开发 Q 学习算法
Temporal difference (TD) learning 和 MC learning 一样,也是一种 model-free 学习算法。你会记得 Q 函数在 MC 学习的整个情节结束时更新(无论是在第一次访问还是每次访问模式)。TD 学习的主要优点是它会为情节中的每个步骤更新 Q 函数。
在这个秘籍中,我们将研究一种流行的 TD 方法,称为Q- learning。Q-learning是一种off-policy学习算法。它根据以下等式更新 Q 函数:
这里,s' 是在状态 s 中采取行动 a 后的结果状态;r 是相关奖励;α 是学习率;γ 是贴现因子。此外,![]() 意味着行为策略是贪婪的,其中选择状态 s' 中 Q 值最高的行为策略来生成学习数据。在 Q-learning 中,根据 epsilon-greedy 策略采取行动。
意味着行为策略是贪婪的,其中选择状态 s' 中 Q 值最高的行为策略来生成学习数据。在 Q-learning 中,根据 epsilon-greedy 策略采取行动。
怎么做...
我们执行 Q-learning 来解决 Cliff Walking 环境,如下所示:
1.导入 PyTorch 和 Gym 库并创建 Cliff Walking 环境的实例:
>>> import torch
>>> import gym
>>> env = gym.make("CliffWalking-v0")
>>> from collections import defaultdict2.让我们从定义 epsilon-greedy 策略开始:
>>> def gen_epsilon_greedy_policy(n_action, epsilon):
... def policy_function(state, Q):
... probs = torch.ones(n_action) * epsilon / n_action
... best_action = torch.argmax(Q[state]).item()
... probs[best_action] += 1.0 - epsilon
... action = torch.multinomial(probs, 1).item()
... return action
... return policy_function3.现在,定义执行Ql收入的函数:
>>> def q_learning(env, gamma, n_episode, alpha):
... """
... 使用off-policy Q-learning方法获取最优策略
... @param env: OpenAI Gym环境
... @ param gamma:折扣因子
... @param n_episode:剧集数
... @return:最佳Q函数和最佳策略
... """
... n_action = env.action_space.n
... Q = defaultdict(lambda: torch.zeros(n_action))
... for episode in range(n_episode):
... state = env.reset()
... is_done = False
... while not is_done:
... action = epsilon_greedy_policy(state, Q)
... next_state, reward, is_done, info =
env.step(action)
... td_delta = reward +
gamma * torch.max(Q[next_state])
- Q[state][action]
... Q[state][action] += alpha * td_delta
... if is_done:
... break
... state = next_state
... policy = {}
... for state, actions in Q.items():
... policy[state] = torch.argmax(actions).item()
... return Q, policy4.我们将折扣率指定为1,学习率指定为0.4,epsilon 指定为0.1;我们模拟 500 集:
>>> gamma = 1
>>> n_episode = 500
>>> alpha = 0.4
>>> epsilon = 0.15.接下来,我们创建一个 epsilon-greedy 策略的实例:
>>> epsilon_greedy_policy = gen_epsilon_greedy_policy(env.action_space.n, epsilon)6.最后,我们使用之前定义的输入参数执行Ql收益并打印出最优策略:
>>> optimal_Q, optimal_policy = q_learning(env, gamma, n_episode, alpha)
>>> print('The optimal policy:\n', optimal_policy)
The optimal policy:
{36: 0, 24: 1, 25: 1, 13: 1, 12: 2, 0: 3, 1: 1, 14: 2, 2: 1, 26: 1, 15: 1, 27: 1, 28: 1, 16: 2, 4: 2, 3: 1, 29: 1, 17: 1, 5: 0, 30: 1, 18: 1, 6: 1, 19: 1, 7: 1, 31: 1, 32: 1, 20: 2, 8: 1, 33: 1, 21: 1, 9: 1, 34: 1, 22: 2, 10: 2, 23: 2, 11: 2, 35: 2, 47: 3}这个怎么运作...
在步骤 2中,epsilon-greedy 策略接受一个参数 ε,其值从 0 到 1,以及 |A|,可能的操作数。每个动作都以 ε/|A| 的概率采取,并以 1-ε+ε/|A| 的概率选择具有最高状态-动作值的动作。
在步骤 3中,我们在以下任务中执行 Q -l收入:
- 我们用全零初始化 Q 表。
- 在每一集中,我们让代理遵循 epsilon-greedy 策略来选择要采取的行动。并且我们为每一步更新 Q 函数。
- 我们运行n_episode剧集。
- 我们根据最优 Q 函数获得最优策略。
在第 6 步中,同样,up = 0,right = 1,down = 2,left = 3;因此,按照最优策略,智能体从状态 36 开始,然后向上移动到状态 24,然后一直向右移动到状态 35,最后通过向下移动达到目标:
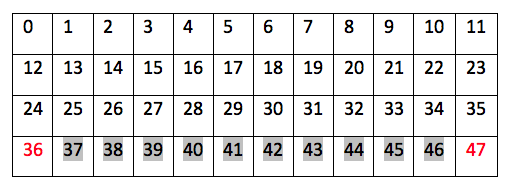
正如您在 Q -l earning中看到的那样,它通过学习另一个策略产生的经验来优化 Q 函数。这与 off-policy MC 控制方法非常相似。不同之处在于它会即时更新 Q 函数,而不是在整集之后更新。它被认为对于具有长剧集的环境是有利的,在这些环境中将学习延迟到剧集结束是低效的。在 Q -l earning (或任何其他 TD 方法)的每一步中,我们都会获得有关环境的更多信息,并使用此信息立即更新值。在我们的案例中,我们仅通过运行 500 个学习片段就获得了最优策略。
还有更多...
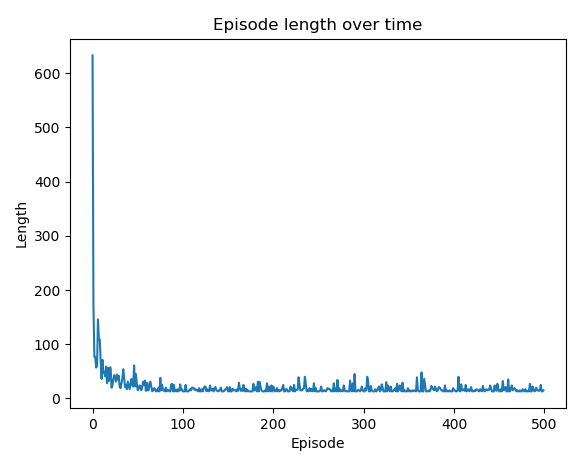
事实上,最优策略是在大约 50 集之后获得的。我们可以随时间绘制每一集的长度来验证这一点。随着时间的推移在每个情节中获得的总奖励也是一个选项。
1.我们定义了两个列表来分别存储每一集的长度和总奖励:
>>> length_episode = [0] * n_episode
>>> total_reward_episode = [0] * n_episode2.我们在学习过程中跟踪每一集的长度和总奖励。以下是更新后的版本q_learning:
>>> def q_learning(env, gamma, n_episode, alpha):
... n_action = env.action_space.n
... Q = defaultdict(lambda: torch.zeros(n_action))
... for episode in range(n_episode):
... state = env.reset()
... is_done = False
... while not is_done:
... action = epsilon_greedy_policy(state, Q)
... next_state, reward, is_done, info =
env.step(action)
... td_delta = reward +
gamma * torch.max(Q[next_state])
- Q[state][action]
... Q[state][action] += alpha * td_delta
... length_episode[episode] += 1
... total_reward_episode[episode] += reward
... if is_done:
... break
... state = next_state
... policy = {}
... for state, actions in Q.items():
... policy[state] = torch.argmax(actions).item()
... return Q, policy3.现在,显示情节长度随时间的变化:
>>> import matplotlib.pyplot as plt
>>> plt.plot(length_episode)
>>> plt.title('Episode length over time')
>>> plt.xlabel('Episode')
>>> plt.ylabel('Length')
>>> plt.show()这将导致以下情节:
4.显示情节奖励随时间变化的情节:
>>> plt.plot(total_reward_episode)
>>> plt.title('Episode reward over time')
>>> plt.xlabel('Episode')
>>> plt.ylabel('Total reward')
>>> plt.show()这将导致以下情节:
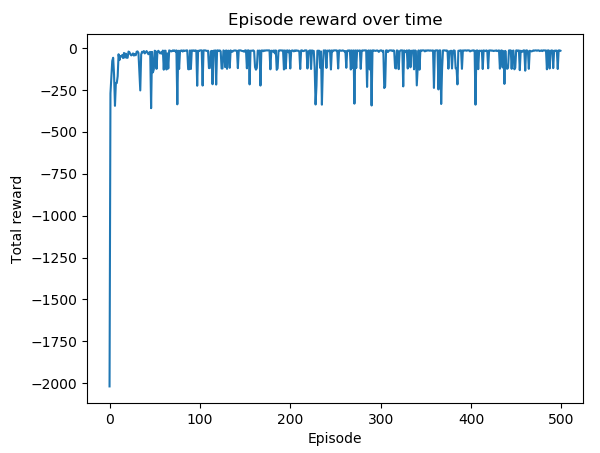
同样,如果减小 epsilon 的值,您会看到更小的波动,这是 epsilon-greedy 策略中随机探索的效果。
设置 Windy Gridworld 环境游乐场
在前面的秘籍中,我们解决了一个相对简单的环境,我们可以很容易地获得最优策略。在这个秘籍中,让我们模拟一个更复杂的网格环境,Windy Gridworld,其中一个外力将代理从某些瓦片上移开。这将使我们准备好在下一节中使用 TD 方法搜索最优策略。
Windy Gridworld是一个7*10棋盘的网格问题,显示如下:
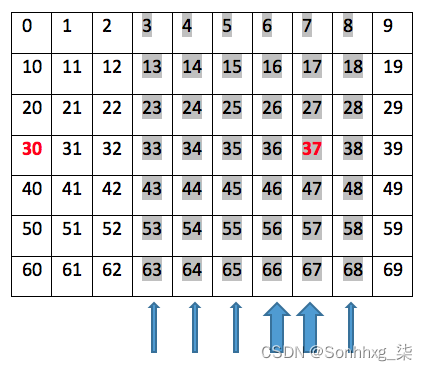
智能体在一个步骤中向上、向右、向下和向左移动。第 30 个图块是代理的起点,第 37 个图块是获胜点,如果到达该点,情节将结束。代理采取的每一步都会产生 -1 奖励。
此环境的复杂性在于第 4 至 9 列中存在额外的风力。从这些列上的瓷砖移动时,智能体将经历额外的向上推力。第七列和第八列的风力为1,第四列、第五列、第六列和第九列的风力为2。例如,如果智能体试图从状态43向右移动,它们将降落在状态34 ; 如果智能体试图从状态 48 向左移动,他们将降落在状态 37;如果代理人试图从状态 67 向上移动,他们将降落在状态 37,因为代理人向上接收额外的 2 个单位的力;如果代理试图从状态 27 向下移动,他们将降落在状态 17,因为向上的 2 个额外力抵消了向下的 1 个力。
怎么做...
让我们开发 Windy Gridworld 环境:
1.从 Gym导入必要的模块、NumPy 和discrete类:
>>> import numpy as np
>>> import sys
>>> from gym.envs.toy_text import discrete2.定义四个动作:
>>> UP = 0
>>> RIGHT = 1
>>> DOWN = 2
>>> LEFT = 33.让我们从在类中定义__init__ 方法开始WindyGridworldEnv :
>>> class WindyGridworldEnv(discrete.DiscreteEnv):
... def __init__(self):
... self.shape = (7, 10)
... nS = self.shape[0] * self.shape[1]
... nA = 4
... # Wind 位置
... winds = np.zeros(self.shape)
... winds[:,[3,4,5,8]] = 1
... winds[:,[6,7]] = 2
... self.goal = (3, 7)
... # 计算转移概率和奖励
... P = {}
... for s in range(nS):
... position = np.unravel_index(s, self.shape)
... P[s] = {a: [] for a in range(nA)}
... P[s][UP] = self._calculate_transition_prob(
position, [-1, 0], winds)
... P[s][RIGHT] = self._calculate_transition_prob(
position, [0, 1], winds)
... P[s][DOWN] = self._calculate_transition_prob(
position, [1, 0], winds)
... P[s][LEFT] = self._calculate_transition_prob(
position, [0, -1], winds)
... # 计算初始状态分布
... # 我们总是从状态 (3, 0) 开始
... isd = np.zeros(nS)
... isd[np.ravel_multi_index((3,0), self.shape)] = 1.0
... super(WindyGridworldEnv, self).__init__(nS, nA, P, isd)这定义了观察空间、风区和力、转换和奖励矩阵以及初始状态。
4.接下来,我们定义_calculate_transition_prob确定动作结果的方法,包括概率(为 1)、新状态、奖励(始终为 -1)以及是否完成:
... def _calculate_transition_prob(self, current,
delta, winds):
... """
... 确定动作的结果。转换概率始终为 1.0
... @param current: (row, col), 网格上的当前位置
... @param delta:转换位置的变化
... @param delta:转换位置的变化
... @return: (1.0, new_state, reward, is_done)
... """
... new_position = np.array(current) + np.array(delta)
+ np.array([-1, 0]) * winds[tuple(current)]
... new_position = self._limit_coordinates(
new_position).astype(int)
... new_state = np.ravel_multi_index(
tuple(new_position), self.shape)
... is_done = tuple(new_position) == self.goal
... return [(1.0, new_state, -1.0, is_done)]这会根据当前状态、移动和风效应计算状态,并确保新位置在网格内。最后,它检查代理是否已达到目标状态。
5.接下来,我们定义_limit_coordinates防止代理脱离网格世界的方法:
... def _limit_coordinates(self, coord):
... coord[0] = min(coord[0], self.shape[0] - 1)
... coord[0] = max(coord[0], 0)
... coord[1] = min(coord[1], self.shape[1] - 1)
... coord[1] = max(coord[1], 0)
... return coord6.最后,我们添加render方法以显示代理和网格环境:
... def render(self):
... outfile = sys.stdout
... for s in range(self.nS):
... position = np.unravel_index(s, self.shape)
... if self.s == s:
... output = " x "
... elif position == self.goal:
... output = " T "
... else:
... output = " o "
... if position[1] == 0:
... output = output.lstrip()
... if position[1] == self.shape[1] - 1:
... output = output.rstrip()
... output += "\n"
... outfile.write(output)
... outfile.write("\n")X代表代理的当前位置,T是目标瓦片,其余瓦片表示为o。
现在,让我们按照以下步骤模拟 Windy Gridworld 环境:
1.创建 Windy Gridworld 环境的实例:
>>> env = WindyGridworldEnv()2.重置并渲染环境:
>>> env.reset()
>>> env.render()
o o o o o o o o o o
o o o o o o o o o o
o o o o o o o o o o
x o o o o o o T o o
o o o o o o o o o o
o o o o o o o o o o
o o o o o o o o o o代理从状态 30 开始。
3.做一个正确的动作:
>>> print(env.step(1))
>>> env.render()
(31, -1.0, False, {'prob': 1.0})
o o o o o o o o o o
o o o o o o o o o o
o o o o o o o o o o
o x o o o o o T o o
o o o o o o o o o o
o o o o o o o o o o
o o o o o o o o o o代理到达状态 31,奖励为 -1。
4.做两个正确的动作:
>>> print(env.step(1))
>>> print(env.step(1))
>>> env.render()
(32, -1.0, False, {'prob': 1.0})
(33, -1.0, False, {'prob': 1.0})
o o o o o o o o o o
o o o o o o o o o o
o o o o o o o o o o
o o o x o o o T o o
o o o o o o o o o o
o o o o o o o o o o
o o o o o o o o o o5.现在,再做一个正确的动作:
>>> print(env.step(1))
>>> env.render()
(24, -1.0, False, {'prob': 1.0})
o o o o o o o o o o
o o o o o o o o o o
o o o o x o o o o o
o o o o o o o T o o
o o o o o o o o o o
o o o o o o o o o o
o o o o o o o o o o随着 1 个单位的向上风,代理降落在状态 24。
随意与环境玩耍,直到达到目标。
这个怎么运作...
我们刚刚开发了一个类似于 Cliff Walking 的网格环境。Windy Gridworld 和 Cliff Walking 之间的区别在于额外的向上推动力。Windy Gridworld 情节中的每个动作都会导致 -1 的奖励。因此,最好早点达到目标。在下一个秘籍中,我们将使用另一种 TD 控制方法来解决 Windy Gridworld 问题。
开发 SARSA 算法
你会记得 Q -l earning是一种 off-policy TD 学习算法。在本秘籍中,我们将使用一种名为状态-动作-奖励-状态-动作( SARSA )的在线 TD 学习算法来解决 MDP 。
与 Q -1收入类似,SARSA 关注国家行动价值。它根据以下等式更新 Q 函数:
![]()
这里,s'是在状态 s 中采取动作 a 后的结果状态;r 是相关奖励;α 是学习率;γ 是贴现因子。您会记得,在 Q -l earning中,行为贪婪策略![]() 用于更新 Q 值。在 SARSA 中,我们a'通过同样遵循 epsilon-greedy 策略更新 Q 值来简单地选择下一个动作 。并且在下一步中执行动作a'。因此,SARSA 是一种 on-policy 算法。
用于更新 Q 值。在 SARSA 中,我们a'通过同样遵循 epsilon-greedy 策略更新 Q 值来简单地选择下一个动作 。并且在下一步中执行动作a'。因此,SARSA 是一种 on-policy 算法。
怎么做...
我们执行 SARSA 来解决 Windy Gridworld 环境,如下所示:
1.导入 PyTorch 和WindyGridworldEnvmodule(假设它在一个名为 的文件中windy_gridworld.py),并创建 Windy Gridworld 环境的实例:
>>> import torch
>>> from windy_gridworld import WindyGridworldEnv
>>> env = WindyGridworldEnv()2.让我们从定义 epsilon-greedy 行为策略开始:
>>> def gen_epsilon_greedy_policy(n_action, epsilon):
... def policy_function(state, Q):
... probs = torch.ones(n_action) * epsilon / n_action
... best_action = torch.argmax(Q[state]).item()
... probs[best_action] += 1.0 - epsilon
... action = torch.multinomial(probs, 1).item()
... return action
... return policy_function3.我们指定剧集的数量并初始化两个用于跟踪每个剧集的长度和总奖励的变量:
>>> n_episode = 500
>>> length_episode = [0] * n_episode
>>> total_reward_episode = [0] * n_episode4.现在,我们定义执行 SARSA 的函数:
>>> from collections import defaultdict
>>> def sarsa(env, gamma, n_episode, alpha):
... """
... 使用on-policy SARSA算法获取最优策略
... @param env: OpenAI Gym 环境
... @param gamma: discount factor
... @param n_episode: number of episodes
... @return: 最优Q函数,最优策略
... """
... n_action = env.action_space.n
... Q = defaultdict(lambda: torch.zeros(n_action))
... for episode in range(n_episode):
... state = env.reset()
... is_done = False
... action = epsilon_greedy_policy(state, Q)
... while not is_done:
... next_state, reward, is_done, info
= env.step(action)
... next_action = epsilon_greedy_policy(next_state, Q)
... td_delta = reward +
gamma * Q[next_state][next_action]
- Q[state][action]
... Q[state][action] += alpha * td_delta
... length_episode[episode] += 1
... total_reward_episode[episode] += reward
... if is_done:
... break
... state = next_state
... action = next_action
... policy = {}
... for state, actions in Q.items():
... policy[state] = torch.argmax(actions).item()
... return Q, policy5.我们指定折扣率为 1,学习率为 0.4,epsilon 为 0.1:
>>> gamma = 1
>>> alpha = 0.4
>>> epsilon = 0.16.接下来,我们创建一个 epsilon-greedy 策略的实例:
>>> epsilon_greedy_policy = gen_epsilon_greedy_policy(env.action_space.n, epsilon)7.最后,我们使用前面步骤中定义的输入参数执行 SARSA,并打印出最优策略:
>>> optimal_Q, optimal_policy = sarsa(env, gamma, n_episode, alpha)
>>> print('The optimal policy:\n', optimal_policy)
The optimal policy:
{30: 2, 31: 1, 32: 1, 40: 1, 50: 2, 60: 1, 61: 1, 51: 1, 41: 1, 42: 1, 20: 1, 21: 1, 62: 1, 63: 2, 52: 1, 53: 1, 43: 1, 22: 1, 11: 1, 10: 1, 0: 1, 33: 1, 23: 1, 12: 1, 13: 1, 2: 1, 1: 1, 3: 1, 24: 1, 4: 1, 5: 1, 6: 1, 14: 1, 7: 1, 8: 1, 9: 2, 19: 2, 18: 2, 29: 2, 28: 1, 17: 2, 39: 2, 38: 1, 27: 0, 49: 3, 48: 3, 37: 3, 34: 1, 59: 2, 58: 3, 47: 2, 26: 1, 44: 1, 15: 1, 69: 3, 68: 1, 57: 2, 36: 1, 25: 1, 54: 2, 16: 1, 35: 1, 45: 1}这个怎么运作...
在第 4 步中,SARSA 函数执行以下任务:
- 它用全零初始化 Q 表。
- 在每一集中,它让代理遵循 epsilon-greedy 策略来选择要采取的行动。对于每一步,它都会根据方程 更新 Q 函数
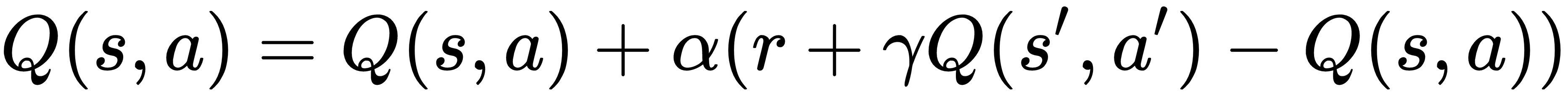 ,其中a'是根据 epsilon-greedy 策略选择的。然后在新状态下执行新操作 a' s'。
,其中a'是根据 epsilon-greedy 策略选择的。然后在新状态下执行新操作 a' s'。 - 我们运行n_episode剧集。
- 我们根据最优 Q 函数获得最优策略。
正如您在 SARSA 方法中看到的那样,它通过采取在相同策略下选择的操作来优化 Q 函数,即 epsilon-greedy 策略。这与 on-policy MC 控制方法非常相似。不同之处在于,它在各个步骤中通过小导数更新 Q 函数,而不是在整个事件之后。它被认为对于具有长剧集的环境是有利的,在这些环境中将学习延迟到剧集结束是低效的。在 SARSA 的每一步中,我们都会获得更多关于环境的信息,并使用这些信息立即更新值。在我们的案例中,我们仅通过运行 500 个学习片段就获得了最优策略。
还有更多...
事实上,最优策略是在大约 200 集之后获得的。我们可以绘制随时间变化的每一集的长度和总奖励以验证这一点:
1.显示随时间变化的情节长度图:
>>> import matplotlib.pyplot as plt
>>> plt.plot(length_episode)
>>> plt.title('Episode length over time')
>>> plt.xlabel('Episode')
>>> plt.ylabel('Length')
>>> plt.show()这将导致以下情节:

您可以看到剧集长度在 200 集后开始饱和。请注意,那些小的波动是由于 epsilon-greedy 策略中的随机探索造成的。
2.显示情节奖励随时间的变化:
>>> plt.plot(total_reward_episode)
>>> plt.title('Episode reward over time')
>>> plt.xlabel('Episode')
>>> plt.ylabel('Total reward')
>>> plt.show()这将导致以下情节:

同样,如果减小 epsilon 的值,您会看到更小的波动,这是 epsilon-greedy 策略中随机探索的效果。
在接下来的两个秘籍中,我们将使用刚刚学到的两种 TD 方法来解决具有更多可能状态和动作的更复杂环境。让我们从 Q 学习开始。
用 Q-learning 解决出租车问题
Taxi 问题 ( https://gym.openai.com/envs/Taxi-v2/ ) 是另一个流行的网格世界问题。在 5 * 5 的网格中,智能体充当出租车司机,在一个位置接载乘客,然后将乘客送至目的地。看看下面的例子:
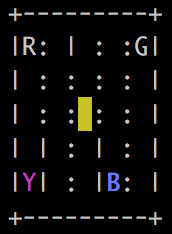
彩色瓷砖具有以下含义:
- 黄色:出租车的起始位置。每集的起始位置是随机的。
- 蓝色:乘客的位置。它也是在每一集中随机选择的。
- 紫色:乘客的目的地。同样,它是在每一集中随机选择的。
- 绿色:出租车与乘客的位置。
四个字母 R、Y、B 和 G 表示唯一允许上下乘客的板块。其中之一是目的地,一个是乘客所在的位置。
出租车可以采取以下六种确定性行动:
- 0 : 向南移动
- 1 : 向北移动
- 2:向东移动
- 3:向西移动
- 4:接载乘客
- 5 : 乘客掉落
有柱子 | 在两块地砖之间,防止出租车从一块地砖移动到另一块地砖。
每一步的奖励一般为-1,以下情况除外:
- +20 : 乘客被送到目的地。一个情节将结束。
- -10:试图非法上车或下车(不在 R、Y、B 或 G 中的任何一个)。
还有一点需要注意的是,观察空间比25(5*5)大很多,因为我们还要考虑乘客的位置和目的地,以及出租车是空的还是满的。因此,观察空间应为 25 * 5(乘客或已经在出租车中的 4 个可能位置)* 4(目的地)= 500 个维度。
做好准备
要运行 Taxi 环境,我们首先在环境表Table of environments · openai/gym Wiki · GitHub中搜索它的名称。我们得到 Taxi-v2 并且还知道观察空间由 0 到 499 之间的整数表示,并且有四种可能的动作(上 = 0,右 = 1,下 = 2,左 = 3)。
怎么做...
让我们按照以下步骤模拟 Taxi 环境:
1.我们导入 Gym 库并创建 Taxi 环境的实例:
>>> import gym
>>> env = gym.make('Taxi-v2')
>>> n_state = env.observation_space.n
>>> print(n_state)
500
>>> n_action = env.action_space.n
>>> print(n_action)
62.然后,我们重置环境:
>>> env.reset()
2623.然后,我们渲染环境:
>>> env.render()你会看到一个类似的 5 * 5 矩阵,如下所示:
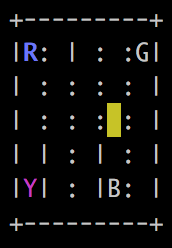
乘客在 R 位置,目的地在 Y。你会看到一些不同的东西,因为初始状态是随机生成的。
4.现在让我们去接乘客,向西走三格,向北走两格(你可以根据你的初始状态调整),然后执行接载。然后,我们再次渲染环境:
>>> print(env.step(3))
(242, -1, False, {'prob': 1.0})
>>> print(env.step(3))
(222, -1, False, {'prob': 1.0})
>>> print(env.step(3))
(202, -1, False, {'prob': 1.0})
>>> print(env.step(1))
(102, -1, False, {'prob': 1.0})
>>> print(env.step(1))
(2, -1, False, {'prob': 1.0})
>>> print(env.step(4))
(18, -1, False, {'prob': 1.0})
Render the environment:
>>> env.render()5.您将看到更新的最新矩阵(同样,您可能会根据初始状态获得不同的输出):
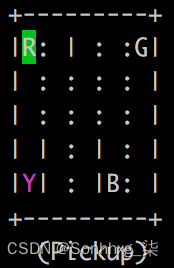
出租车变绿了。
6.现在,我们通过向南行驶四个方块(您可以将其调整为您的初始状态)到达目的地,然后执行下车:
>>> print(env.step(0))
(118, -1, False, {'prob': 1.0})
>>> print(env.step(0))
(218, -1, False, {'prob': 1.0})
>>> print(env.step(0))
(318, -1, False, {'prob': 1.0})
>>> print(env.step(0))
(418, -1, False, {'prob': 1.0})
>>> print(env.step(5))
(410, 20, True, {'prob': 1.0})
它最终获得了+20 的奖励,情节结束。
现在,我们渲染环境:
>>> env.render()您将看到以下更新后的矩阵:

我们现在将执行 Q-learning 来解决 Taxi 环境,如下所示:
1.导入 PyTorch 库:
>>> import torch2.然后,开始定义 epsilon-greedy 策略。我们将重用在开发 Q 学习算法一节gen_epsilon_greedy_policy中定义的函数。
3.现在,我们指定剧集的数量并初始化两个用于跟踪每个剧集的长度和总奖励的变量:
>>> n_episode = 1000
>>> length_episode = [0] * n_episode
>>> total_reward_episode = [0] * n_episode4.接下来,我们定义执行 Q-learning 的函数。我们将重用开发 Q 学习算法一节q_learning中定义的函数。
5.现在,我们指定其余参数,包括折扣率、学习率和 epsilon,并创建 epsilon-greedy-policy 的实例:
>>> gamma = 1
>>> alpha = 0.4
>>> epsilon = 0.1
>>> epsilon_greedy_policy = gen_epsilon_greedy_policy(env.action_space.n, epsilon)6.最后,我们执行 Q-learning 以获得出租车问题的最优策略:
>>> optimal_Q, optimal_policy = q_learning(env, gamma, n_episode, alpha)这个怎么运作...
在这个秘籍中,我们通过离策略 Q-learning 解决了 Taxi 问题。
在第 6 步之后,您可以绘制随时间变化的每个情节的长度和总奖励,以验证模型是否收敛。情节长度随时间的变化显示如下:
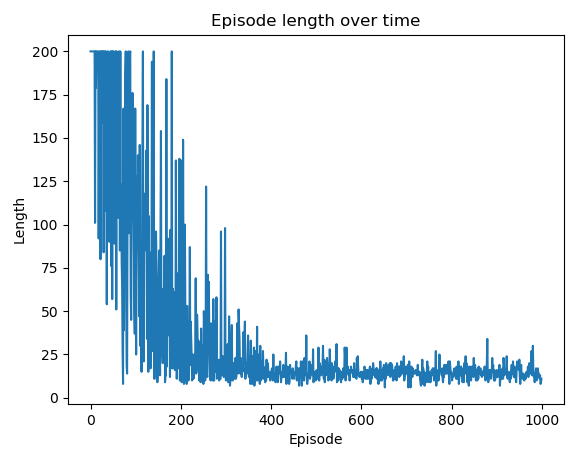
episode奖励随时间变化的剧情如下:
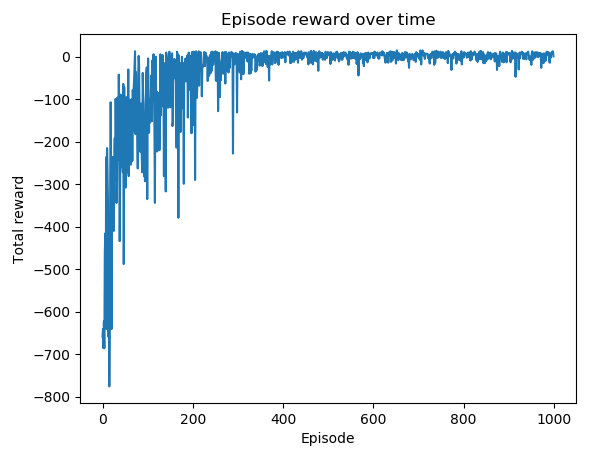
您可以看到优化在 400 集后开始饱和。
Taxi 环境是一个相对复杂的网格问题,具有 500 个离散状态和 6 个可能的动作。Q-learning 通过从贪婪策略产生的经验中学习,在一个 episode 的每一步中优化 Q 函数。我们在学习过程中获得有关环境的信息,并使用此信息通过遵循 epsilon-greedy 策略立即更新值。
用 SARSA 解决出租车问题
在这个秘籍中,我们将使用 SARSA 算法解决 Taxi 环境,并使用网格搜索算法微调超参数。
我们将从 SARSA 模型下的默认超参数值集开始。这些是根据直觉和大量试验选择的。继续前进,我们将提出最好的价值观。
怎么做...
我们执行 SARSA 来解决 Taxi 环境,如下所示:
1.导入 PyTorch 和gym模块,并创建 Taxi 环境的实例:
>>> import torch
>>> import gym
>>> env = gym.make('Taxi-v2')2.然后,开始定义 epsilon-greedy 行为策略。我们将重用在开发 SARSA 算法gen_epsilon_greedy_policy一节中定义的函数。
3.然后我们指定剧集的数量并初始化两个用于跟踪每个剧集的长度和总奖励的变量:
>>> n_episode = 1000
>>> length_episode = [0] * n_episode
>>> total_reward_episode = [0] * n_episode4.现在,我们定义执行 SARSA 的函数。我们将重用在开发 SARSA 算法sarsa一节中定义的函数。
5.我们将折扣率指定为1,将默认学习率指定为0.4,并将默认 epsilon 指定为0.1:
>>> gamma = 1
>>> alpha = 0.4
>>> epsilon = 0.016.接下来,我们创建一个 epsilon-greedy-policy 的实例:
>>> epsilon_greedy_policy = gen_epsilon_greedy_policy(env.action_space.n, epsilon)7.最后,我们使用前面步骤中定义的输入参数执行 SARSA:
>>> optimal_Q, optimal_policy = sarsa(env, gamma, n_episode, alpha)这个怎么运作...
在第 7 步之后,您可以绘制随时间变化的每个情节的长度和总奖励,以验证模型是否收敛。情节长度随时间的变化显示如下:
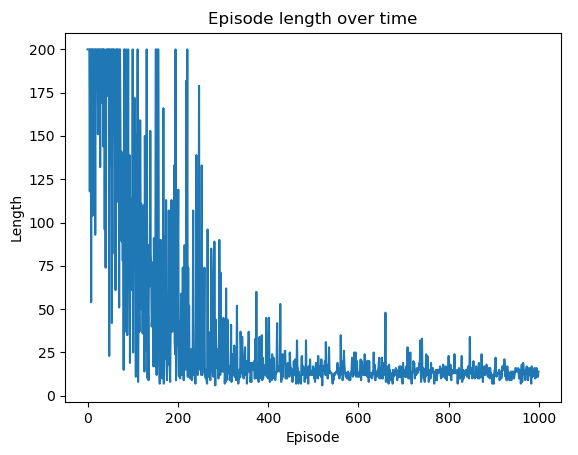
episode奖励随时间变化的剧情如下:
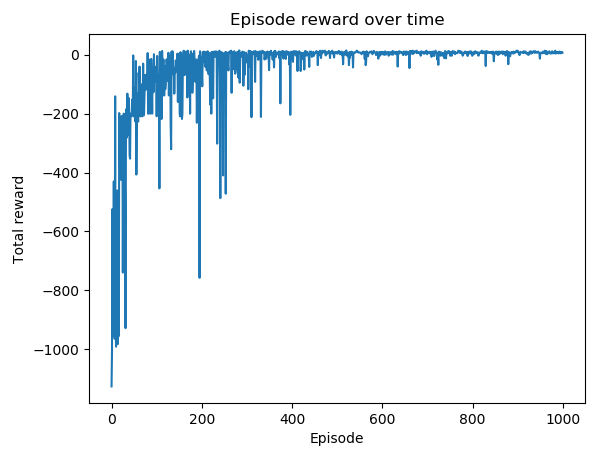
这个 SARSA 模型运行良好,但不一定是最好的。稍后我们将使用网格搜索来搜索 SARSA 模型下的最佳超参数集。
Taxi 环境是一个相对复杂的网格问题,具有 500 个离散状态和 6 个可能的动作。SARSA 算法通过学习和优化目标策略,在每一步中优化 Q 函数。我们在学习过程中获得有关环境的信息,并使用此信息通过遵循 epsilon-greedy 策略立即更新值。
还有更多...
网格搜索是一种编程方式,用于在强化学习中找到超参数的最佳值集。每组超参数的性能由以下三个指标衡量:
- 前几集的平均总奖励:我们希望尽早获得最大的奖励。
- 前几集的平均剧集长度:我们希望出租车尽快到达目的地。
- 前几集每个时间步的平均奖励:我们希望尽快获得最大奖励。
让我们继续实施它:
1.我们在此使用三个 alpha 候选 [0.4、0.5 和 0.6] 和三个 epsilon 候选 [0.1、0.03 和 0.01],并且只考虑前 500 集:
>>> alpha_options = [0.4, 0.5, 0.6]
>>> epsilon_options = [0.1, 0.03, 0.01]
>>> n_episode = 5002.我们通过使用每组超参数训练 SARSA 模型并评估相应的性能来执行网格搜索:
>>> for alpha in alpha_options:
... for epsilon in epsilon_options:
... length_episode = [0] * n_episode
... total_reward_episode = [0] * n_episode
... sarsa(env, gamma, n_episode, alpha)
... reward_per_step = [reward/float(step) for
reward, step in zip(
total_reward_episode, length_episode)]
... print('alpha: {}, epsilon: {}'.format(alpha, epsilon))
... print('Average reward over {} episodes: {}'.format(
n_episode, sum(total_reward_episode) / n_episode))
... print('Average length over {} episodes: {}'.format(
n_episode, sum(length_episode) / n_episode))
... print('Average reward per step over {} episodes:
{}\n'.format(n_episode, sum(reward_per_step) / n_episode))运行前面的代码会生成以下结果:
alpha: 0.4, epsilon: 0.1
Average reward over 500 episodes: -75.442
Average length over 500 episodes: 57.682
Average reward per step over 500 episodes: -0.32510755063660324
alpha: 0.4, epsilon: 0.03
Average reward over 500 episodes: -73.378
Average length over 500 episodes: 56.53
Average reward per step over 500 episodes: -0.2761201410280632
alpha: 0.4, epsilon: 0.01
Average reward over 500 episodes: -78.722
Average length over 500 episodes: 59.366
Average reward per step over 500 episodes: -0.3561815084186654
alpha: 0.5, epsilon: 0.1
Average reward over 500 episodes: -72.026
Average length over 500 episodes: 55.592
Average reward per step over 500 episodes: -0.25355404831497264
alpha: 0.5, epsilon: 0.03
Average reward over 500 episodes: -67.562
Average length over 500 episodes: 52.706
Average reward per step over 500 episodes: -0.20602525679639022
alpha: 0.5, epsilon: 0.01
Average reward over 500 episodes: -75.252
Average length over 500 episodes: 56.73
Average reward per step over 500 episodes: -0.2588407558703358
alpha: 0.6, epsilon: 0.1
Average reward over 500 episodes: -62.568
Average length over 500 episodes: 49.488
Average reward per step over 500 episodes: -0.1700284221229244
alpha: 0.6, epsilon: 0.03
Average reward over 500 episodes: -68.56
Average length over 500 episodes: 52.804
Average reward per step over 500 episodes: -0.24794191768600077
alpha: 0.6, epsilon: 0.01
Average reward over 500 episodes: -63.468
Average length over 500 episodes: 49.752
Average reward per step over 500 episodes: -0.14350124172091722我们可以看到在这种情况下最好的超参数集是 alpha: 0.6, epsilon: 0.01,它实现了最大的每步奖励和大的平均奖励和短的平均剧集长度。
开发双 Q 学习算法
这是一个额外的秘诀,在本章中我们将开发双 Q 学习算法。
Q-learning 是一种强大且流行的 TD 控制强化学习算法。但是,它在某些情况下可能表现不佳,主要是因为贪心组件maxa'Q(s', a')。它可能会高估行动价值并导致绩效不佳。双 Q 学习的发明是为了通过使用两个 Q 函数来克服这个问题。我们将两个 Q 函数表示为Q1和Q2。在每一步中,随机选择一个Q函数进行更新。如果选择 Q1,则Q1更新如下:
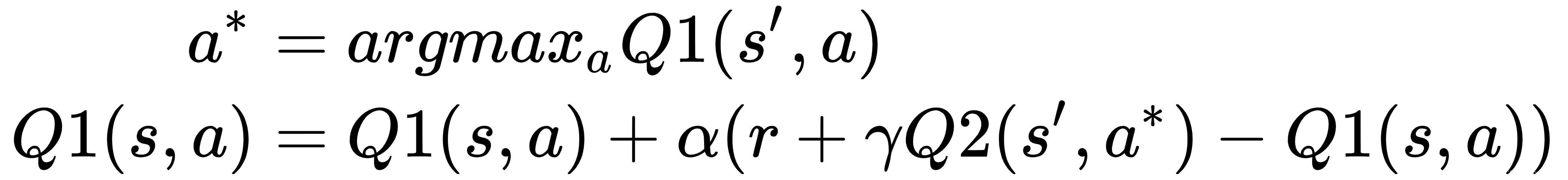
如果选择 Q2,则更新如下:
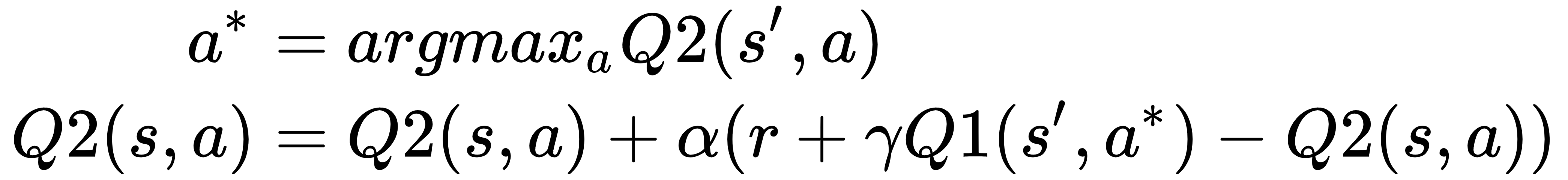
这意味着每个 Q 函数都在贪婪搜索之后从另一个更新,这减少了使用单个 Q 函数对动作值的高估。
怎么做...
我们现在开发双 Q 学习来解决 Taxi 环境,如下所示:
1.导入所需的库并创建 Taxi 环境的实例:
>>> import torch
>>> import gym
>>> env = gym.make('Taxi-v2')2.然后,开始定义 epsilon-greedy 策略。我们将重用开发 Q-Learning 算法配方gen_epsilon_greedy_policy中定义的函数。
3.然后我们指定剧集的数量并初始化两个用于跟踪每个剧集的长度和总奖励的变量:
>>> n_episode = 3000
>>> length_episode = [0] * n_episode
>>> total_reward_episode = [0] * n_episode在这里,我们模拟了 3,000 集,因为双 Q 学习需要更多集才能收敛。
4.接下来,我们定义执行双 Q 学习的函数:
>>> def double_q_learning(env, gamma, n_episode, alpha):
... """
... 使用off-policy双Q学习方法获取最优策略
... @param env: OpenAI Gym环境
... @param gamma:折扣因子
... @param n_episode:剧集数
... @return:最佳Q函数和最佳策略
... """
... n_action = env.action_space.n
... n_state = env.observation_space.n
... Q1 = torch.zeros(n_state, n_action)
... Q2 = torch.zeros(n_state, n_action)
... for episode in range(n_episode):
... state = env.reset()
... is_done = False
... while not is_done:
... action = epsilon_greedy_policy(state, Q1 + Q2)
... next_state, reward, is_done, info
= env.step(action)
... if (torch.rand(1).item() < 0.5):
... best_next_action = torch.argmax(Q1[next_state])
... td_delta = reward +
gamma * Q2[next_state][best_next_action]
- Q1[state][action]
... Q1[state][action] += alpha * td_delta
... else:
... best_next_action = torch.argmax(Q2[next_state])
... td_delta = reward +
gamma * Q1[next_state][best_next_action]
- Q2[state][action]
... Q2[state][action] += alpha * td_delta
... length_episode[episode] += 1
... total_reward_episode[episode] += reward
... if is_done:
... break
... state = next_state
... policy = {}
... Q = Q1 + Q2
... for state in range(n_state):
... policy[state] = torch.argmax(Q[state]).item()
... return Q, policy5.然后我们指定其余参数,包括折扣率、学习率和 epsilon,并创建 epsilon-greedy-policy 的实例:
>>> gamma = 1
>>> alpha = 0.4
>>> epsilon = 0.1
>>> epsilon_greedy_policy = gen_epsilon_greedy_policy(env.action_space.n, epsilon)6.最后,我们执行双 Q 学习以获得 Taxi 问题的最优策略:
>>> optimal_Q, optimal_policy = double_q_learning(env, gamma, n_episode, alpha)这个怎么运作...
我们已经使用本秘籍中的双 Q 学习算法解决了 Taxi 问题。
在第 4 步中,我们使用以下任务进行双 Q 学习:
- 用全零初始化两个 Q 表。
- 在每一集的每个步骤中,我们随机选择一个 Q 函数进行更新。让代理遵循 epsilon-greedy 策略来选择要采取的操作,并使用另一个 Q 函数更新所选的 Q 函数。
- 运行n_episode剧集。
- 通过求和(或平均)两个 Q 函数,得到基于最优 Q 函数的最优策略。
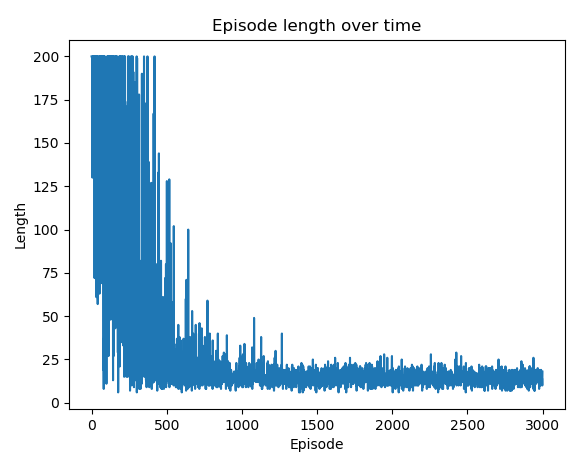
在第 6 步之后,您可以绘制随时间变化的每个情节的长度和总奖励,以验证模型是否收敛。剧集长度随时间变化的图如下所示:
episode奖励随时间变化的剧情如下:
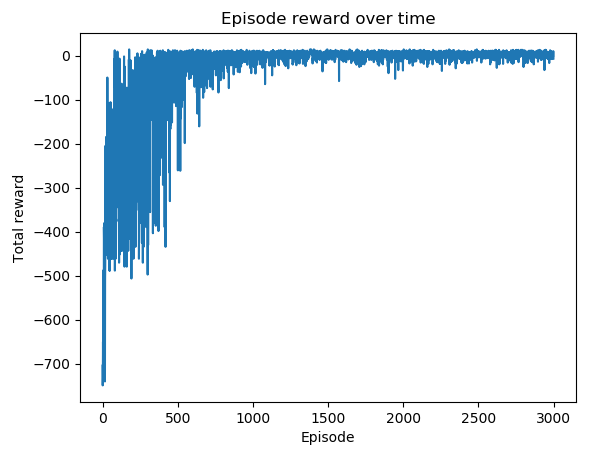
双 Q 学习克服了复杂环境中单 Q 学习的潜在缺点。它随机轮换两个 Q 函数并更新它们,这可以防止来自一个 Q 函数的动作值被高估。同时,它可能会低估 Q 函数,因为它不会随时间步长更新相同的 Q 函数。因此,我们可以看到最佳动作值需要更多的情节才能收敛。
也可以看看
有关双 Q 学习背后的理论,请查看原始论文,https ://papers.nips.cc/paper/3964-double-q-learning,作者 Hado van Hasselt,发表于Advances in Neural Information Processing Systems 23 ( NIPS 2010), 2613-2621, 2010.
相关文章
- 深度学习小白实现残差网络resnet18 ——pytorch「建议收藏」
- Activity工作流引擎学习笔记(一)「建议收藏」
- PyTorch学习系列教程:三大神经网络在股票数据集上的实战
- PyTorch学习系列教程:构建一个深度学习模型需要哪几步?
- PyTorch学习系列教程:循环神经网络【RNN】
- Pytorch模型训练实用教程学习笔记:二、模型的构建
- Pytorch模型训练实用教程学习笔记:三、损失函数汇总
- pytorch(8)– resnet101 迁移学习记录
- Pytorch创建多任务学习模型
- 新版TCGAbiolinks包学习:批量下载数据
- Python中用PyTorch机器学习神经网络分类预测银行客户流失模型|附代码数据
- 【学习图片】05:GIF
- 2023年值得学习的云计算技术有哪些?
- 深度学习Pytorch(一)
- 基于PyTorch、易上手,细粒度图像识别深度学习工具库Hawkeye开源
- 使用PyTorch实现简单的AlphaZero的算法(3):神经网络架构和自学习
- PyTorch中学习率调度器可视化介绍
- 24小时入门PyTorch深度学习
- 深度学习Pytorch(二)
- PyTorch深度学习领域框架
- 纯Rust编写的机器学习框架Neuronika,速度堪比PyTorch
- MySQL学习之基础命令实操总结
- 面操作深入学习 Oracle 数据库书面操作(oracle数据库书)
- torchLinux下学习PyTorch(linuxpy)
- Linux 手动分区:一步一步学习(linux手动分区)
- ORACLE与OB完美结合的学习之路(ob和oracle)
- PyTorch 的预训练,是时候学习一下了
- 独家丨2017全国深度学习技术应用大会回顾:传统的AI研究方法,在DL时代该如何变革?