
图像算法所用软件下载汇总
0.Matlab
首先,送个福利:matlab在线使用网址:https://matlab.mathworks.com/

如果在外没有软件的话,用这个在线工具很方便

另外,如果要安装matlab,可以通过下边这个链接安装破解版:
链接:https://pan.baidu.com/s/1zhO8n8CupFOUIbxE7-Jthw
提取码:rwen
1.VS2017
VS2012-2022: https://visualstudio.microsoft.com/zh-hans/vs/older-downloads/

2.Qt5.12.2
注:qt断网安装可以跳过注册
中国科学技术大学镜像:http://mirrors.ustc.edu.cn/qtproject/
清华大学:https://mirrors.tuna.tsinghua.edu.cn/qt/


- 点击QT VS Tool,选择Qt option,点击Versions,添加一个new Qt version,Path中找到5.14.2/msvc2017_64/bin/qmake.exe
3.Opencv+Contrib455
opencv可以直接官网下载,速度也挺快:
Opencv官网下载: https://opencv.org/releases/
下边是Opencv contrib4.5.5的下载链接:
链接:https://pan.baidu.com/s/1JdT8Ecye76xYuzFxzubDKw
提取码:dqp6
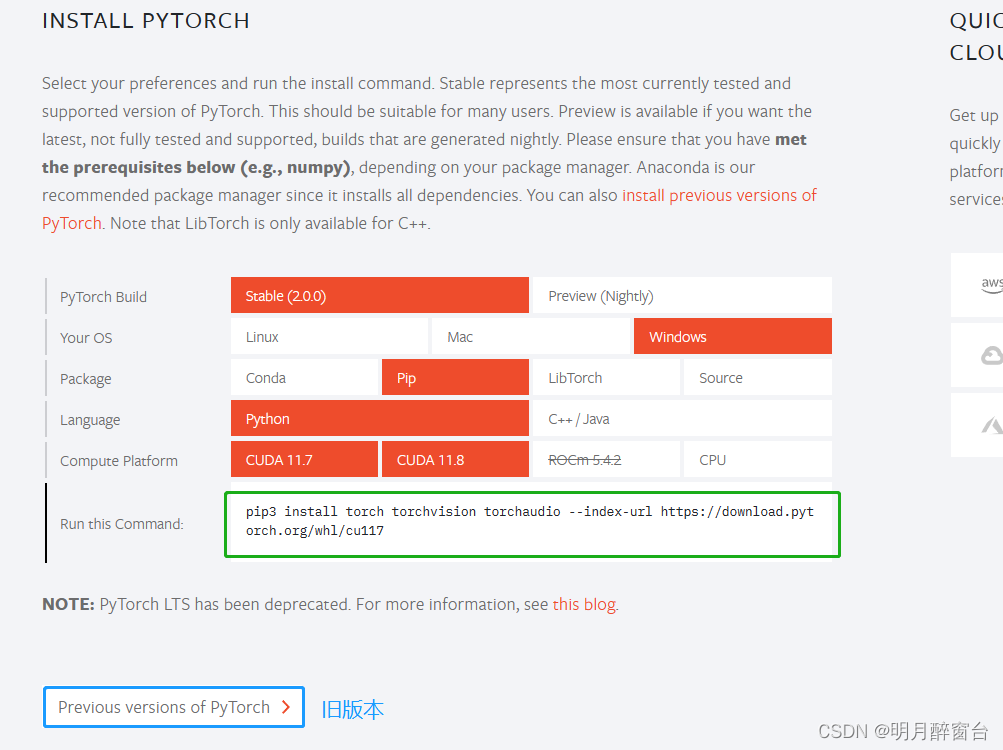
4.Pytorch
- 一个用于深度学习训练+推理的框架:https://pytorch.org/
5.CUDA下载:
CUDA是NVIDIA推出的用于自家GPU的并行计算框架,也就是说CUDA只能在NVIDIA的GPU上运行,而且只有当要解决的计算问题是可以大量并行计算的时候才能发挥CUDA的作用。
在 CUDA 的架构下,一个程序分为两个部份:host 端和 device 端。Host 端是指在 CPU 上执行的部份,而 device 端则是在显示芯片上执行的部份。Device 端的程序又称为 “kernel”。通常 host 端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行 device 端程序,完成后再由 host 端程序将结果从显卡的内存中取回。
官方网站:https://developer.nvidia.com/cuda-toolkit-archive
从中选择适合自己的版本,注意配置环境变量

- 对于cuda10.2,针对下载内存最大的安装需要自定义下载,其他可以默认下载,注意事项如下:

- 打开cmd键入命令 nvidia-smi 查看 cuda 版本,如果未定义命令,则查找默认路径添加环境变量或者使用如下命令:
cd C:\Program Files\NVIDIA Corporation\NVSMI
nvidia-smi

6.cuDNN下载
cuDNN(CUDA Deep Neural Network library):是NVIDIA打造的针对深度神经网络的加速库,是一个用于深层神经网络的GPU加速库。如果你要用GPU训练模型,cuDNN不是必须的,但是一般会采用这个加速库。因为cudnn能够很大程度的把加载到显卡上的网络层数据进行优化计算,比如卷积,pooling,归一化,以及激活层等等。cuda就像一个傻大粗的加速库,其主要是依靠的是显卡计算速度跟一些算法的优化,而且其也是进行显卡加速的入口。所以cudnn需要在有cuda的基础上进行。
官方网站: https://developer.nvidia.com/rdp/cudnn-archive
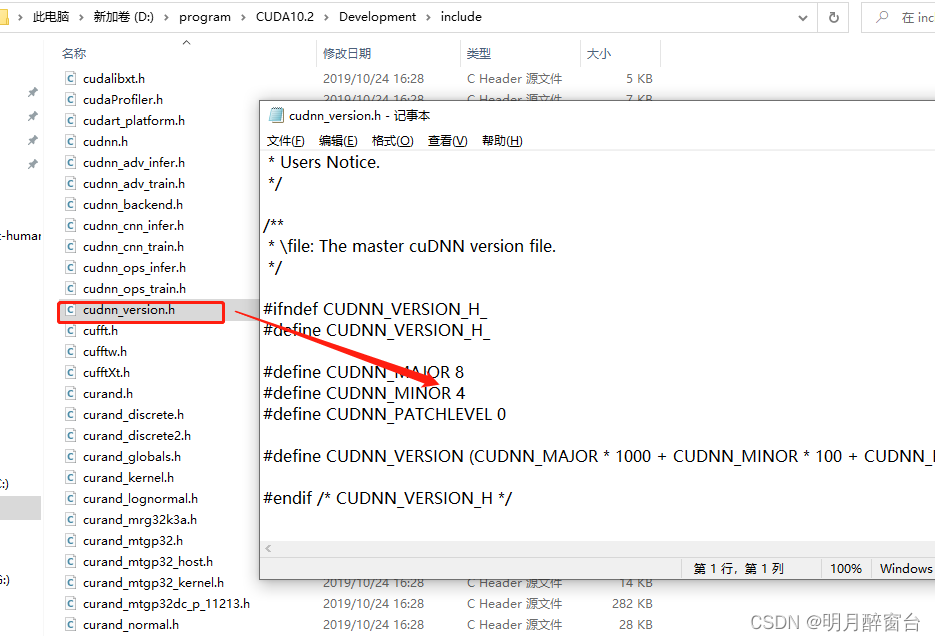
其中,cudnn版本查看在其安装路径下:我的安装路径是将他们都放在了cuda的路径中,.h中的 840 即是版本
7.CMake
8.OpenVINO
- OpenVINO™全称是Open Visual Inference & neural network optimization,直译为“ 开放式视觉推断与神经网络优化 ”。OpenVINO对各种图形图像处理算法进行了针对性的优化,从而扩展了Intel的各类算力硬件以及相关加速器的应用空间,实现了AI领域的异构计算,使传统平台的视觉推断能力得到了很大程度的提高。OpenVINO实现了一套通用的API,可以混合调用CPU、GPU、Movidius NCS和FGPA的算力来共同完成一次视觉推断,预先实现了一系列的功能库、OpenCL kernel等,可以缩短产品面世时间。
- OpenVINO™ toolkit, OpenVINO™工具包可快速部署模拟人类视觉的应用程序和解决方案。该工具包基于卷积神经网络(CNN),可在英特尔®硬件上扩展计算机视觉(CV)工作负载,从而最大限度地提软硬件高性能。OpenVINO™工具箱包括深度学习部署工具箱(DLDT)、深度学习模型优化器(Model Optimizer)、深度学习推理引擎(Inference Engine)、Open Model Zoo开放式模型库。
安装:https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/download.html

9.TensorRT
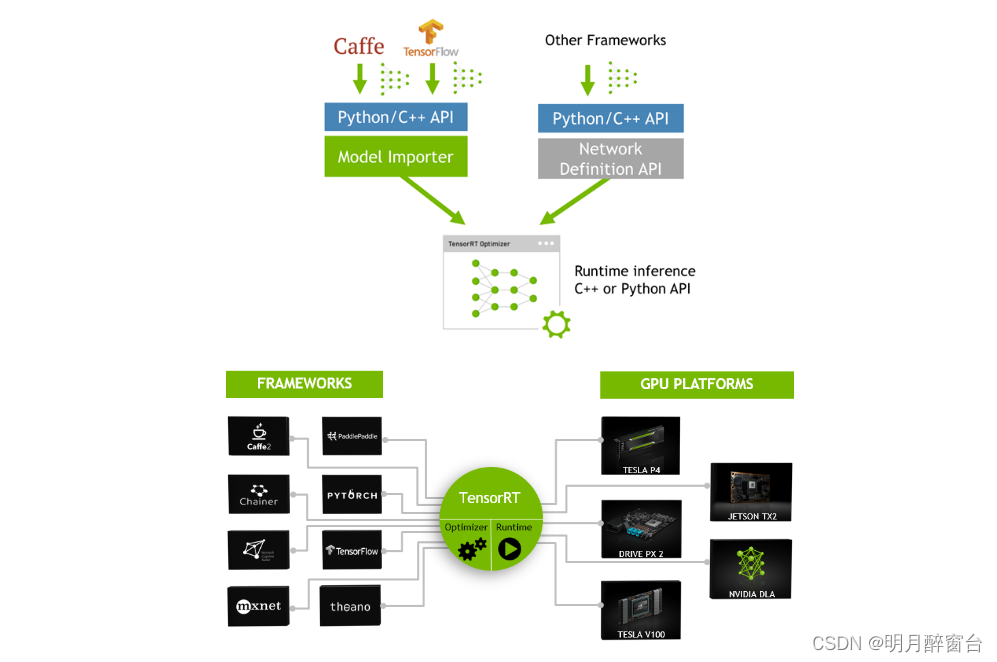
TensorRT是由Nvidia推出的C++语言开发的高性能神经网络推理库,是一个用于生产部署的优化器和运行时引擎。其高性能计算能力依赖于Nvidia的图形处理单元。它专注于推理任务,与常用的神经网络学习框架形成互补,包括TensorFlow、Caffe、PyTorch、MXNet等。 TensorRT 就只是推理优化器。当你的网络训练完之后,可以将训练模型文件直接丢进 TensorRT中,而不再需要依赖深度学习框架(Caffe,TensorFlow 等),如下:
安装:https://developer.nvidia.com/tensorrt

- 如果是
python调用,则需要pip安装.whl文件:

- 将tensorRT中对应文件夹下的内容复制到CUDA安装目录下的对应文件夹中:

- 验证安装成功:
#通过python导入:
#进入python环境:
import tensorrt as trt
print(trt.__version__)
10.onnxruntime
- ONNX 是微软与Facebook和AWS共同开发的深度学习和传统机器学习模型的开放格式。ONNX格式是开放式生态系统的基础,使人工智能技术更易于访问,而且可以为不同人群创造价值.
- ONNX Runtime是适用于Linux,Windows和Mac上ONNX格式的机器学习模型的高性能推理引擎。

当cudnn的版本为10.*时,选择下面链接下载
https://github.com/microsoft/onnxruntime/releases/tag/v1.3.0
当cudnn的版本为11.*时,选择下面链接下载
https://github.com/microsoft/onnxruntime/releases/tag/v1.9.0
相关文章
- Java实现 蓝桥杯 算法提高 抽卡游戏
- Java实现 蓝桥杯VIP 算法训练 新生舞会
- Java实现 蓝桥杯VIP 算法训练 输出米字形
- Java蓝桥杯 算法提高 九宫格
- Java实现蓝桥杯 算法提高 八皇后 改
- 【学习总结】java数据结构和算法-第三章-稀疏数组和队列
- Paxos算法
- Atitit.软件中见算法 程序设计五大种类算法
- DL之模型调参:深度学习算法模型优化参数之对LSTM算法进行超参数调优
- CV之NS之VGG16:基于TF Slim库利用VGG16算法的预训练模型实现七种不同快速图像风格迁移设计(cubist/denoised_starry/mosaic/scream/wave)案例
- DayDayUp:平均每篇文章1毛! 本博主自2020年6月1日起,如有任何问题可在博客贴吧留言或者私信博主(包括并不限于GUI软件编写、安装及编程语言中的bug、AI算法设计等),非诚勿扰!
- m基于自适应门限软切换的3G和Wifi垂直切换算法的matlab仿真
- m基于背景差法与GMM混合高斯模型结合的红外目标检测与跟踪算法matlab仿真
- 智能优化算法:寄生-捕食算法-附代码
- 算法书
- LabVIEW视觉软件使用什么算法
- 一步一步写算法(之单向链表)
- 倒排列表求交集算法汇总
- Ribbon,主要提供客户侧的软件负载均衡算法。
- 【数学建模】11 数学建模常用算法和计算机辅助软件
- 【C++】算法集锦(10)通俗讲kmp算法