
Hadoop: Why Not Use RAID?
一、针对hadoop集群的磁盘配置建议
针对datanode,建议采用一组单独的磁盘,针对namenode节点,建议采用raid5或raid1来实现针对metadata的冗灾。
二、针对此问题讨论的资料
针对此问题,两篇文章从不同角度论证为什么Hadoop更青睐JBOD而不是RAID-0。分别是:
Raid0的资料:
将多个磁盘合并成一个大的磁盘,不具有冗余,并行I/O,速度最快。RAID 0亦称为带区集。它是将多个磁盘并列起来,成为一个大磁盘。在存放数据时,其将数据按磁盘的个数来进行分段,然后同时将这些数据写进这些盘中,所以在所有的级别中,RAID 0的速度是最快的。但是RAID 0没有冗余功能,如果一个磁盘(物理)损坏,则所有的数据都会丢失,危险程度与JBOD相当。
理论上越多的磁盘性能就等于“单一磁盘性能”ד磁盘数”,但实际上受限于总线I/O瓶颈及其它因素的影响,详见:http://zh.wikipedia.org/wiki/RAID#RAID_0
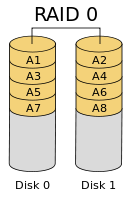
Steve Loughran认为,其并不适合Hadoop。
与RAID-0阵列的同组管理相比,Hadoop更喜欢一组单独磁盘。在Hadoop集群中,读取速度是最能体现性能的重要指标。在Steve Loughran文章中,尤其强调了这一点,他还指出,由于驱动器速度显著不同,RAID-0读取速度往往取决于阵列中最慢的一块磁盘。很多时候,RAID-0配置读取速度甚至会比non-RAID更慢。更大的问题是可靠性。如果一组磁盘被配置为RAID-0阵列,一旦一个磁盘出现故障,将使得整组都宕机。如果所有磁盘都在一个节点中,那么势必会影响整个节点的数据都出现问题。所以,如果配置多个RAID-0阵列,那么单故障发生时,整体系统出问题的概率得到了无限放大
三、Hadoop:定义指导给出的建议
在Hadoop集群中,有一个建议:在配置时,将每个磁盘都分开。有人形象地将之称为“JBOD(Just a Box of Disks)
《Hadoop:The.Definitive.Guide》Chapter 9: Setting Up a Hadoop Cluster中,阐述了hadoop为什么不用raid, 及namenode,datanode应该使用的磁盘配置方式。原文如下:

相关文章
- Hadoop生态圈各种组件介绍
- 大数据spark、hadoop、hive、hbase面试题及解析[通俗易懂]
- Hadoop入门——初识Hadoop
- hadoop中的token认证
- 基于商业版Hadoop搭建的数据仓库解决方案
- 大数据必知必会:Hadoop(2)伪分布式安装
- Hadoop中nameNode与dataNode关系是什么?他们是如何协作的
- ORA-22344: can not specify CONVERT TO SUBSTITUTABLE option for ALTER TYPE other than NOT FINAL change ORACLE 报错 故障修复 远程处理
- Hadoop(十五)MapReduce程序实例详解大数据
- Hadoop入门进阶课程12–Flume介绍、安装与应用案例详解大数据
- Hadoop入门进阶课程13–Chukwa介绍与安装部署详解大数据
- Hadoop文件存储系统-HDFS详解以及java编程实现大数据
- Hadoop学习之SecondaryNameNode详解大数据
- 初次接触Hadoop详解大数据
- 高可用Hadoop平台-Ganglia安装部署详解大数据
- 高可用Hadoop平台-启航详解大数据
- 配置高可用的Hadoop平台详解大数据
- Linux系统下安装配置Hadoop(linux下安装hadoop)
- MySQL中NOT的使用方法(mysql中not的用法)
- MySQL中的Not用法如何在查询中使用Not运算符(mysql中not用法)
- 关键字在 Oracle 中使用 NOT 关键字的实践(oracle 中 not)