
分类算法:决策树(C4.5)
C4.5是机器学习算法中的另一个分类决策树算法,它是基于ID3算法进行改进后的一种重要算法,相比于ID3算法,改进有如下几个要点:
用信息增益率来选择属性。ID3选择属性用的是子树的信息增益,这里可以用很多方法来定义信息,ID3使用的是熵(entropy, 熵是一种不纯度度量准则),也就是熵的变化值,而C4.5用的是信息增益率。 在决策树构造过程中进行剪枝,因为某些具有很少元素的结点可能会使构造的决策树过适应(Overfitting),如果不考虑这些结点可能会更好。 对非离散数据也能处理。 能够对不完整数据进行处理。首先,说明一下如何计算信息增益率。
熟悉了ID3算法后,已经知道如何计算信息增益,计算公式如下所示(来自Wikipedia):
或者,用另一个更加直观容易理解的公式计算:
按照类标签对训练数据集D的属性集A进行划分,得到信息熵: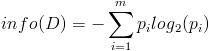 按照属性集A中每个属性进行划分,得到一组信息熵:
按照属性集A中每个属性进行划分,得到一组信息熵: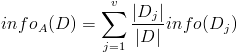 计算信息增益
计算信息增益
然后计算信息增益,即前者对后者做差,得到属性集合A一组信息增益:
这样,信息增益就计算出来了。 计算信息增益率
下面看,计算信息增益率的公式,如下所示(来自Wikipedia):
其中,IG表示信息增益,按照前面我们描述的过程来计算。而IV是我们现在需要计算的,它是一个用来考虑分裂信息的度量,分裂信息用来衡量属性分 裂数据的广度和均匀程序,计算公式如下所示(来自Wikipedia):
其中,V表示属性集合A中的一个属性的全部取值。
我们以一个很典型被引用过多次的训练数据集D为例,来说明C4.5算法如何计算信息增益并选择决策结点。
上面的训练集有4个属性,即属性集合A={OUTLOOK, TEMPERATURE, HUMIDITY, WINDY};而类标签有2个,即类标签集合C={Yes, No},分别表示适合户外运动和不适合户外运动,其实是一个二分类问题。
我们已经计算过信息增益,这里直接列出来,如下所示:
数据集D包含14个训练样本,其中属于类别“Yes”的有9个,属于类别“No”的有5个,则计算其信息熵:
下面对属性集中每个属性分别计算信息熵,如下所示:
Info(OUTLOOK) = 5/14 * [- 2/5 * log2(2/5) – 3/5 * log2(3/5)] + 4/14 * [ - 4/4 * log2(4/4) - 0/4 * log2(0/4)] + 5/14 * [ - 3/5 * log2(3/5) – 2/5 * log2(2/5)] = 0.694Info(TEMPERATURE) = 4/14 * [- 2/4 * log2(2/4) – 2/4 * log2(2/4)] + 6/14 * [ - 4/6 * log2(4/6) - 2/6 * log2(2/6)] + 4/14 * [ - 3/4 * log2(3/4) – 1/4 * log2(1/4)] = 0.911
Info(HUMIDITY) = 7/14 * [- 3/7 * log2(3/7) – 4/7 * log2(4/7)] + 7/14 * [ - 6/7 * log2(6/7) - 1/7 * log2(1/7)] = 0.789
Info(WINDY) = 6/14 * [- 3/6 * log2(3/6) – 3/6 * log2(3/6)] + 8/14 * [ - 6/8 * log2(6/8) - 2/8 * log2(2/8)] = 0.892
根据上面的数据,我们可以计算选择第一个根结点所依赖的信息增益值,计算如下所示:
Gain(OUTLOOK) = Info(D) - Info(OUTLOOK) = 0.940 - 0.694 = 0.246OUTLOOK属性
属性OUTLOOK有3个取值,其中Sunny有5个样本、Rainy有5个样本、Overcast有4个样本,则
H(OUTLOOK) = - 5/14 * log2(5/14) - 5/14 * log2(5/14) - 4/14 * log2(4/14) = 1.577406282852345 TEMPERATURE属性属性TEMPERATURE有3个取值,其中Hot有4个样本、Mild有6个样本、Cool有4个样本,则
H(TEMPERATURE) = - 4/14 * log2(4/14) - 6/14 * log2(6/14) - 4/14 * log2(4/14) = 1.5566567074628228 HUMIDITY属性属性HUMIDITY有2个取值,其中Normal有7个样本、High有7个样本,则
H(HUMIDITY) = - 7/14 * log2(7/14) - 7/14 * log2(7/14) = 1.0 WINDY属性属性WINDY有2个取值,其中True有6个样本、False有8个样本,则
H(WINDY) = - 6/14 * log2(6/14) - 8/14 * log2(8/14) = 0.9852281360342516根据上面计算结果,我们可以计算信息增益率,如下所示:
IGR(OUTLOOK) = Gain(OUTLOOK) / H(OUTLOOK) = 0.246/1.577406282852345 = 0.15595221261270145IGR(TEMPERATURE) = Gain(TEMPERATURE) / H(TEMPERATURE) = 0.029 / 1.5566567074628228 = 0.018629669509642094
根据计算得到的信息增益率进行选择属性集中的属性作为决策树结点,对该结点进行分裂。
C4.5算法的优点是:产生的分类规则易于理解,准确率较高。
C4.5算法的缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
决策树算法 决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法怎么理解这句话?
集成学习方法之随机森林 集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
决策树之 GBDT 算法 - 回归部分 GBDT(Gradient Boosting Decision Tree)是被工业界广泛使用的机器学习算法之一,它既可以解决回归问题,又可以应用在分类场景中,该算法由斯坦福统计学教授 Jerome H. Friedman 在 1999 年发表。本文中,我们主要学习 GBDT 的回归部分。 在学习 GBDT 之前,你需要对 [CART](https://www.atatech.org/ar
决策树之 GBDT 算法 - 分类部分 上一次我们一起学习了 [GBDT 算法的回归部分](https://www.atatech.org/articles/158821),今天我们继续学习该算法的分类部分。使用 GBDT 来解决分类问题和解决回归问题的本质是一样的,都是通过不断构建决策树的方式,使预测结果一步步的接近目标值。 因为是分类问题,所以分类 GBDT 和回归 GBDT 的 Loss 函数是不同的,具体原因我们在《[深入
决策树算法之 AdaBoost AdaBoost 是一种更高级的「森林」类型的决策树,和随机森林比起来,它有以下三个特点 1. AdaBoost 的每棵树都只有一个根节点和两个叶子节点,实际上叫树桩(stump)可能会更合适 2. AdaBoost 的每个树桩的权重是不同的,而随机森林中的每棵树的权重是相同的 3. 前一个树桩的错误数据会影响后一个树桩的生成,意味着后面的树桩是前面树桩的补足。这种思想也被称为 Boos
相关文章
- 【华为云技术分享】【Python算法】分类与预测——支持向量机
- 分类算法:决策树(ID3)
- java实现Floyd算法
- Java实现 蓝桥杯VIP 算法训练 麦森数
- Java实现 蓝桥杯算法提高金明的预算方案
- (算法)二叉树中两个结点的最近公共父结点
- 程序员的算法趣题Q62: 日历中的最大矩形
- XAI之SHAP:SHAP算法(How—每个特征如何重要/解释单个样本的预测)的简介(背景/思想/作用/原理/核心技术点/优缺点)、常用工具库、应用案例之详细攻略
- ML之DT:基于DT决策树算法(对比是否经特征筛选FS处理)对Titanic(泰坦尼克号)数据集进行二分类预测
- ML之kNN:利用kNN算法对莺尾(Iris)数据集进行多分类预测
- ML之LoR&Bagging&RF:依次利用LoR、Bagging、RF算法对titanic(泰坦尼克号)数据集 (Kaggle经典案例)获救人员进行二分类预测(最全)
- ML之LiR之PLiR:惩罚线性回归PLiR算法简介、分类、代码实现之详细攻略
- ML之分类预测:以六类机器学习算法(kNN、逻辑回归、SVM、决策树、随机森林、提升树、神经网络)对糖尿病数据集(8→1)实现二分类模型评估案例来理解和认知机器学习分类预测的模板流程
- DL之CNN:利用卷积神经网络算法(2→2,基于Keras的API-Functional)利用MNIST(手写数字图片识别)数据集实现多分类预测
- 第十四届蓝桥杯集训——练习解题阶段(无序阶段)-ALGO-436 算法训练 正六边形
- 人工智能——最大熵与EM算法
- 基于海洋捕食者算法的极限学习机(ELM)分类算法-附代码
- 基于黏菌算法的极限学习机(ELM)分类算法-附代码
- 基于鲸鱼算法的极限学习机(ELM)分类算法-附代码
- 基于蜣螂算法优化的SVM数据分类预测-附代码
- 基于生物地理学算法优化的BP神经网络(预测应用) - 附代码
- 【项目实战】Python实现xgboost分类模型(XGBClassifier算法)项目实战
- 从决策树学习谈到贝叶斯分类算法、EM、HMM
- 从决策树学习谈到贝叶斯分类算法、EM、HMM
- spark 决策树分类算法demo
- 【数据挖掘】十大算法之ID3决策树生成算法和CART分类回归树算法
- 【排序算法】图解简单选择排序(图解堪比Debug显示每次循环结果)