
ML之LoR&Bagging&RF:依次利用LoR、Bagging、RF算法对titanic(泰坦尼克号)数据集 (Kaggle经典案例)获救人员进行二分类预测(最全)
2023-09-14 09:04:45 时间
ML之LoR&Bagging&RF:依次利用LoR、Bagging、RF算法对titanic(泰坦尼克号)数据集 (Kaggle经典案例)获救人员进行二分类预测
目录
输出结果
1、数据集可视化以及统计分析



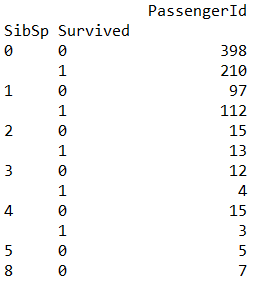
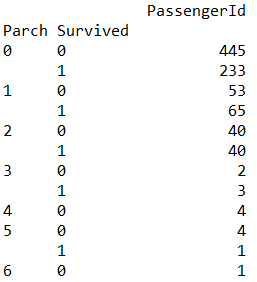











2、优化baseline模型
ML之LoR&Bagging&RF:依次利用LoR、Bagging、RF算法对泰坦尼克号数据集 (Kaggle经典案例)获救人员进行二分类预测——优化baseline模型
3、模型融合
ML之LoR&Bagging&RF:依次利用Bagging、RF算法对泰坦尼克号数据集 (Kaggle经典案例)获救人员进行二分类预测——模型融合
设计思路


核心代码
LoR算法
clf_LoR = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf_LoR.fit(X, y)
#LoR算法
class LogisticRegression Found at: sklearn.linear_model.logistic
class LogisticRegression(BaseEstimator, LinearClassifierMixin,
SparseCoefMixin):
"""Logistic Regression (aka logit, MaxEnt) classifier.
In the multiclass case, the training algorithm uses the one-vs-rest (OvR)
scheme if the 'multi_class' option is set to 'ovr', and uses the cross-
entropy loss if the 'multi_class' option is set to 'multinomial'.
(Currently the 'multinomial' option is supported only by the 'lbfgs',
'sag' and 'newton-cg' solvers.)
This class implements regularized logistic regression using the
'liblinear' library, 'newton-cg', 'sag' and 'lbfgs' solvers. It can handle
both dense and sparse input. Use C-ordered arrays or CSR matrices
containing 64-bit floats for optimal performance; any other input
format
will be converted (and copied).
The 'newton-cg', 'sag', and 'lbfgs' solvers support only L2
regularization
with primal formulation. The 'liblinear' solver supports both L1 and L2
regularization, with a dual formulation only for the L2 penalty.
Read more in the :ref:`User Guide <logistic_regression>`.
Parameters
----------
penalty : str, 'l1' or 'l2', default: 'l2'
Used to specify the norm used in the penalization. The 'newton-cg',
'sag' and 'lbfgs' solvers support only l2 penalties.
.. versionadded:: 0.19
l1 penalty with SAGA solver (allowing 'multinomial' + L1)
dual : bool, default: False
Dual or primal formulation. Dual formulation is only implemented for
l2 penalty with liblinear solver. Prefer dual=False when
n_samples > n_features.
tol : float, default: 1e-4
Tolerance for stopping criteria.
C : float, default: 1.0
Inverse of regularization strength; must be a positive float.
Like in support vector machines, smaller values specify stronger
regularization.
fit_intercept : bool, default: True
Specifies if a constant (a.k.a. bias or intercept) should be
added to the decision function.
intercept_scaling : float, default 1.
Useful only when the solver 'liblinear' is used
and self.fit_intercept is set to True. In this case, x becomes
[x, self.intercept_scaling],
i.e. a "synthetic" feature with constant value equal to
intercept_scaling is appended to the instance vector.
The intercept becomes ``intercept_scaling * synthetic_feature_weight``.
Note! the synthetic feature weight is subject to l1/l2 regularization
as all other features.
To lessen the effect of regularization on synthetic feature weight
(and therefore on the intercept) intercept_scaling has to be increased.
class_weight : dict or 'balanced', default: None
Weights associated with classes in the form ``{class_label: weight}``.
If not given, all classes are supposed to have weight one.
The "balanced" mode uses the values of y to automatically adjust
weights inversely proportional to class frequencies in the input data
as ``n_samples / (n_classes * np.bincount(y))``.
Note that these weights will be multiplied with sample_weight (passed
through the fit method) if sample_weight is specified.
.. versionadded:: 0.17
*class_weight='balanced'*
random_state : int, RandomState instance or None, optional, default:
None
The seed of the pseudo random number generator to use when
shuffling
the data. If int, random_state is the seed used by the random number
generator; If RandomState instance, random_state is the random
number
generator; If None, the random number generator is the RandomState
instance used by `np.random`. Used when ``solver`` == 'sag' or
'liblinear'.
solver : {'newton-cg', 'lbfgs', 'liblinear', 'sag', 'saga'},
default: 'liblinear'
Algorithm to use in the optimization problem.
- For small datasets, 'liblinear' is a good choice, whereas 'sag' and
'saga' are faster for large ones.
- For multiclass problems, only 'newton-cg', 'sag', 'saga' and 'lbfgs'
handle multinomial loss; 'liblinear' is limited to one-versus-rest
schemes.
- 'newton-cg', 'lbfgs' and 'sag' only handle L2 penalty, whereas
'liblinear' and 'saga' handle L1 penalty.
Note that 'sag' and 'saga' fast convergence is only guaranteed on
features with approximately the same scale. You can
preprocess the data with a scaler from sklearn.preprocessing.
.. versionadded:: 0.17
Stochastic Average Gradient descent solver.
.. versionadded:: 0.19
SAGA solver.
max_iter : int, default: 100
Useful only for the newton-cg, sag and lbfgs solvers.
Maximum number of iterations taken for the solvers to converge.
multi_class : str, {'ovr', 'multinomial'}, default: 'ovr'
Multiclass option can be either 'ovr' or 'multinomial'. If the option
chosen is 'ovr', then a binary problem is fit for each label. Else
the loss minimised is the multinomial loss fit across
the entire probability distribution. Does not work for liblinear
solver.
.. versionadded:: 0.18
Stochastic Average Gradient descent solver for 'multinomial' case.
verbose : int, default: 0
For the liblinear and lbfgs solvers set verbose to any positive
number for verbosity.
warm_start : bool, default: False
When set to True, reuse the solution of the previous call to fit as
initialization, otherwise, just erase the previous solution.
Useless for liblinear solver.
.. versionadded:: 0.17
*warm_start* to support *lbfgs*, *newton-cg*, *sag*, *saga* solvers.
n_jobs : int, default: 1
Number of CPU cores used when parallelizing over classes if
multi_class='ovr'". This parameter is ignored when the ``solver``is set
to 'liblinear' regardless of whether 'multi_class' is specified or
not. If given a value of -1, all cores are used.
Attributes
----------
coef_ : array, shape (1, n_features) or (n_classes, n_features)
Coefficient of the features in the decision function.
`coef_` is of shape (1, n_features) when the given problem
is binary.
intercept_ : array, shape (1,) or (n_classes,)
Intercept (a.k.a. bias) added to the decision function.
If `fit_intercept` is set to False, the intercept is set to zero.
`intercept_` is of shape(1,) when the problem is binary.
n_iter_ : array, shape (n_classes,) or (1, )
Actual number of iterations for all classes. If binary or multinomial,
it returns only 1 element. For liblinear solver, only the maximum
number of iteration across all classes is given.
See also
--------
SGDClassifier : incrementally trained logistic regression (when given
the parameter ``loss="log"``).
sklearn.svm.LinearSVC : learns SVM models using the same algorithm.
Notes
-----
The underlying C implementation uses a random number generator to
select features when fitting the model. It is thus not uncommon,
to have slightly different results for the same input data. If
that happens, try with a smaller tol parameter.
Predict output may not match that of standalone liblinear in certain
cases. See :ref:`differences from liblinear <liblinear_differences>`
in the narrative documentation.
References
----------
LIBLINEAR -- A Library for Large Linear Classification
http://www.csie.ntu.edu.tw/~cjlin/liblinear/
SAG -- Mark Schmidt, Nicolas Le Roux, and Francis Bach
Minimizing Finite Sums with the Stochastic Average Gradient
https://hal.inria.fr/hal-00860051/document
SAGA -- Defazio, A., Bach F. & Lacoste-Julien S. (2014).
SAGA: A Fast Incremental Gradient Method With Support
for Non-Strongly Convex Composite Objectives
https://arxiv.org/abs/1407.0202
Hsiang-Fu Yu, Fang-Lan Huang, Chih-Jen Lin (2011). Dual coordinate
descent
methods for logistic regression and maximum entropy models.
Machine Learning 85(1-2):41-75.
http://www.csie.ntu.edu.tw/~cjlin/papers/maxent_dual.pdf
"""
def __init__(self, penalty='l2', dual=False, tol=1e-4, C=1.0,
fit_intercept=True, intercept_scaling=1, class_weight=None,
random_state=None, solver='liblinear', max_iter=100,
multi_class='ovr', verbose=0, warm_start=False, n_jobs=1):
self.penalty = penalty
self.dual = dual
self.tol = tol
self.C = C
self.fit_intercept = fit_intercept
self.intercept_scaling = intercept_scaling
self.class_weight = class_weight
self.random_state = random_state
self.solver = solver
self.max_iter = max_iter
self.multi_class = multi_class
self.verbose = verbose
self.warm_start = warm_start
self.n_jobs = n_jobs
def fit(self, X, y, sample_weight=None):
"""Fit the model according to the given training data.
Parameters
----------
X : {array-like, sparse matrix}, shape (n_samples, n_features)
Training vector, where n_samples is the number of samples and
n_features is the number of features.
y : array-like, shape (n_samples,)
Target vector relative to X.
sample_weight : array-like, shape (n_samples,) optional
Array of weights that are assigned to individual samples.
If not provided, then each sample is given unit weight.
.. versionadded:: 0.17
*sample_weight* support to LogisticRegression.
Returns
-------
self : object
Returns self.
"""
if not isinstance(self.C, numbers.Number) or self.C < 0:
raise ValueError(
"Penalty term must be positive; got (C=%r)" % self.C)
if not isinstance(self.max_iter, numbers.Number) or self.max_iter < 0:
raise ValueError(
"Maximum number of iteration must be positive;"
" got (max_iter=%r)" %
self.max_iter)
if not isinstance(self.tol, numbers.Number) or self.tol < 0:
raise ValueError("Tolerance for stopping criteria must be "
"positive; got (tol=%r)" %
self.tol)
if self.solver in ['newton-cg']:
_dtype = [np.float64, np.float32]
else:
_dtype = np.float64
X, y = check_X_y(X, y, accept_sparse='csr', dtype=_dtype,
order="C")
check_classification_targets(y)
self.classes_ = np.unique(y)
n_samples, n_features = X.shape
_check_solver_option(self.solver, self.multi_class, self.penalty, self.
dual)
if self.solver == 'liblinear':
if self.n_jobs != 1:
warnings.warn("'n_jobs' > 1 does not have any effect when"
" 'solver' is set to 'liblinear'. Got 'n_jobs'"
" = {}.".
format(self.n_jobs))
self.coef_, self.intercept_, n_iter_ = _fit_liblinear(X, y, self.C, self.
fit_intercept, self.intercept_scaling, self.class_weight, self.penalty, self.
dual, self.verbose, self.max_iter, self.tol, self.random_state,
sample_weight=sample_weight)
self.n_iter_ = np.array([n_iter_])
return self
if self.solver in ['sag', 'saga']:
max_squared_sum = row_norms(X, squared=True).max()
else:
max_squared_sum = None
n_classes = len(self.classes_)
classes_ = self.classes_
if n_classes < 2:
raise ValueError(
"This solver needs samples of at least 2 classes"
" in the data, but the data contains only one"
" class: %r" %
classes_[0])
if len(self.classes_) == 2:
n_classes = 1
classes_ = classes_[1:]
if self.warm_start:
warm_start_coef = getattr(self, 'coef_', None)
else:
warm_start_coef = None
if warm_start_coef is not None and self.fit_intercept:
warm_start_coef = np.append(warm_start_coef,
self.intercept_[:np.newaxis],
axis=1)
self.coef_ = list()
self.intercept_ = np.zeros(n_classes)
# Hack so that we iterate only once for the multinomial case.
if self.multi_class == 'multinomial':
classes_ = [None]
warm_start_coef = [warm_start_coef]
if warm_start_coef is None:
warm_start_coef = [None] * n_classes
path_func = delayed(logistic_regression_path)
# The SAG solver releases the GIL so it's more efficient to use
# threads for this solver.
if self.solver in ['sag', 'saga']:
backend = 'threading'
else:
backend = 'multiprocessing'
fold_coefs_ = Parallel(n_jobs=self.n_jobs, verbose=self.verbose,
backend=backend)(
path_func(X, y, pos_class=class_, Cs=[self.C],
fit_intercept=self.fit_intercept, tol=self.tol,
verbose=self.verbose, solver=self.solver,
multi_class=self.multi_class, max_iter=self.max_iter,
class_weight=self.class_weight, check_input=False,
random_state=self.random_state, coef=warm_start_coef_,
penalty=self.penalty,
max_squared_sum=max_squared_sum,
sample_weight=sample_weight) for
(class_, warm_start_coef_) in zip(classes_, warm_start_coef))
fold_coefs_, _, n_iter_ = zip(*fold_coefs_)
self.n_iter_ = np.asarray(n_iter_, dtype=np.int32)[:0]
if self.multi_class == 'multinomial':
self.coef_ = fold_coefs_[0][0]
else:
self.coef_ = np.asarray(fold_coefs_)
self.coef_ = self.coef_.reshape(n_classes, n_features +
int(self.fit_intercept))
if self.fit_intercept:
self.intercept_ = self.coef_[:-1]
self.coef_ = self.coef_[::-1]
return self
def predict_proba(self, X):
"""Probability estimates.
The returned estimates for all classes are ordered by the
label of classes.
For a multi_class problem, if multi_class is set to be "multinomial"
the softmax function is used to find the predicted probability of
each class.
Else use a one-vs-rest approach, i.e calculate the probability
of each class assuming it to be positive using the logistic function.
and normalize these values across all the classes.
Parameters
----------
X : array-like, shape = [n_samples, n_features]
Returns
-------
T : array-like, shape = [n_samples, n_classes]
Returns the probability of the sample for each class in the model,
where classes are ordered as they are in ``self.classes_``.
"""
if not hasattr(self, "coef_"):
raise NotFittedError("Call fit before prediction")
calculate_ovr = self.coef_.shape[0] == 1 or self.multi_class == "ovr"
if calculate_ovr:
return super(LogisticRegression, self)._predict_proba_lr(X)
else:
return softmax(self.decision_function(X), copy=False)
def predict_log_proba(self, X):
"""Log of probability estimates.
The returned estimates for all classes are ordered by the
label of classes.
Parameters
----------
X : array-like, shape = [n_samples, n_features]
Returns
-------
T : array-like, shape = [n_samples, n_classes]
Returns the log-probability of the sample for each class in the
model, where classes are ordered as they are in ``self.classes_``.
"""
return np.log(self.predict_proba(X))
相关文章
EL之Bagging:kaggle比赛之利用泰坦尼克号数据集建立Bagging模型对每个人进行获救是否预测
ML之LoR:kaggle比赛之利用泰坦尼克号数据集建立LoR模型对每个人进行获救是否预测
ML之RF:kaggle比赛之利用泰坦尼克号数据集建立RF模型对每个人进行获救是否预测
ML之SVM:基于Js代码利用SVM算法的实现根据Kaggle数据集预测泰坦尼克号生存人员
相关文章
- 南理工&上海AI Lab提出Uniform Masking,为基于金字塔结构的视觉Transformer进行MAE预训练!
- 最大三角形面积 鞋带公式&海伦公式
- 第2章 WEB02-CSS&JS篇-视频教程-第二部分
- 【文本检测与识别白皮书-3.2】第二节:基于CTC的无需分割的场景文本识别方法&基于注意力机制的无需分割的场景文本识别方法
- 零零信安-D&D数据泄露报警日报【第36期】
- compose--CompositionLocal、列表LazyColumn&LazyRow、约束布局ConstraintLayout
- 接口测试|HttpRunner模拟发送GET请求&自动生成测试报告
- 解密Prompt系列1. Tunning-Free Prompt:GPT2 & GPT3 & LAMA & AutoPrompt
- Geekpwn 2020云端挑战赛 Noxss & umsg
- 微信公众平台开发(二)——自定义菜单、模板消息&微信素材
- 微信公众平台开发(四)——微信网页授权:获取用户openid&用户基本信息
- 7 Papers & Radios | 人类首次实现高压下室温超导;可变形DETR目标检测器
- 在macOS上安装&配置PostgreSQL
- 只对支持amp加速的搜索引擎开放amp功能
- Python迭代器&生成器:分享贴近实际运维开发场景的小案例
- Oracle中插入特殊字符:&和'的解决方法汇总
- JDBC&servlet&jsp题目详解编程语言
- AMP MySQL升级提升数据库性能的必要之举(amp mysql升级)
- 跟我学Laravel之视图&Response