
【数字图像处理】霍夫曼编码(Huffman Coding)
霍夫曼编码(Huffman Coding)是一种编码方法,霍夫曼编码是可变字长编码(VLC)的一种。
霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
思想:常用的数据用短码表示,不常用的数据用长码表示。
霍夫曼编码的具体步骤如下:
- 将信源符号的概率按减小的顺序排队。
- 把两个最小的概率相加,并继续这一步骤,始终将较高的概率分支放在右边,直到最后变成概率1。
- 画出由概率1处到每个信源符号的路径,顺序记下沿路径的0和1,所得就是该符号的霍夫曼码字。
- 将每对组合的左边一个指定为0,右边一个指定为1(或相反)。
例:现有一个由5个不同符号组成的30个符号的字符串:
BABACAC ADADABB CBABEBE DDABEEEBB
1.首先计算出每个字符出现的次数(概率):
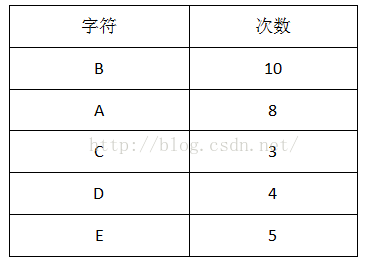
2.把出现次数(概率)最小的两个相加,并作为左右子树,重复此过程,直到概率值为1

第一次:将概率最低值3和4相加,组合成7:
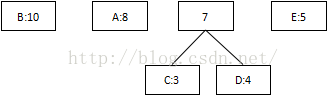
第二次:将最低值5和7相加,组合成12:

第三次:将8和10相加,组合成18:
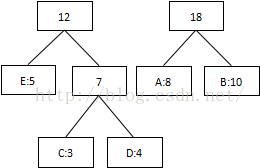
第四次:将最低值12和18相加,结束组合:
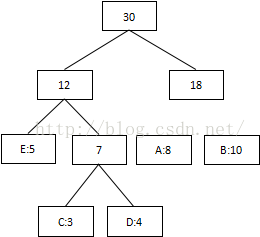
3.将每个二叉树的左边指定为0,右边指定为1
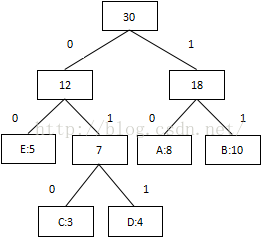
4.沿二叉树顶部到每个字符路径,获得每个符号的编码
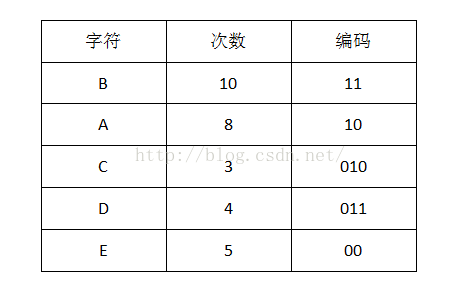
我们可以看到出现次数(概率)越多的会越在上层,编码也越短,出现频率越少的就越在下层,编码也越长。当我们编码的时候,我们是按“bit”来编码的,解码也是通过bit来完成,如果我们有这样的bitset “10111101100″ 那么其解码后就是 “ABBDE”。所以,我们需要通过这个二叉树建立我们Huffman编码和解码的字典表。
这里需要注意的是,Huffman编码使得每一个字符的编码都与另一个字符编码的前一部分不同,不会出现像’A’:00, ’B’:001,这样的情况,解码也不会出现冲突。
霍夫曼编码的局限性
利用霍夫曼编码,每个符号的编码长度只能为整数,所以如果源符号集的概率分布不是2负n次方的形式,则无法达到熵极限;输入符号数受限于可实现的码表尺寸;译码复杂;需要实现知道输入符号集的概率分布;没有错误保护功能。
相关文章
- 「Python 编程」编码实现网络请求库中的 URL 解析器
- JavaScript进行UTF-8编码与解码
- python3之编码详解
- 曼彻斯特编码 vs NRZ编码
- 《安富莱嵌入式周报》第282期:CMSIS-DSP手册引入计算图,树莓派单片机RP2040超频到1GHz,COBS字节编码算法,纯手工为PS1打造全新亚克力外壳
- NLP:自然语言处理技术中常用的文本特征表示方法之字典特征抽取(对字典型数据通过特征抽取和向量化进而实现特征数字化,one-hot编码/仅有值稀疏矩阵,如对类别型特征转换数字型)代码实现
- 【信号处理】天线分集与空时编码技术——瑞利衰落信道下MRC性能(matlab代码实现)
- g711u与g729比較编码格式
- XML文件编码问题
- 007-TreeMap、Map和Bean互转、BeanUtils.copyProperties(A,B)拷贝、URL编码解码、字符串补齐,随机字母数字串
- FFMPEG H264/H265 编码延迟问题
- Windows自带渗透工具Certutil介绍(免杀、哈希计算、md5、sha256、下载文件、base64编码)
- 【信号处理】天线分集与空时编码技术——空时格码(matlab代码实现)