
【机器学习算法-python实现】扫黄神器-朴素贝叶斯分类器的实现
(转载请注明出处:http://blog.csdn.net/buptgshengod)
以前我在外面公司实习的时候,一个大神跟我说过,学计算机就是要一个一个贝叶斯公式的套用来套用去。嗯,现在终于用到了。朴素贝叶斯分类器据说是好多扫黄软件使用的算法,贝叶斯公式也比较简单,大学做概率题经常会用到。核心思想就是找出特征值对结果影响概率最大的项。公式如下: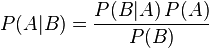
什么是朴素贝叶斯,就是特征值相互独立互不影响的情况。贝叶斯可以有很多变形,这里先搞一个简单的,以后遇到复杂的再写。 2.数据集 摘自机器学习实战。
[[my,dog,has,flea,problems,help,please], 0
[maybe,not,take,him,to,dog,park,stupid], 1
[my,dalmation,is,so,cute,I,love,him], 0
[stop,posting,stupid,worthless,garbage], 1
[mr,licks,ate,my,steak,how,to,stop,him], 0
[quit,buying,worthless,dog,food,stupid]] 1
以上是六句话,标记是0句子的表示正常句,标记是1句子的表示为粗口。我们通过分析每个句子中的每个词,在粗口句或是正常句出现的概率,可以找出那些词是粗口。#以矩阵形式创建数据集 def loadDataSet(): postingList=[[my, dog, has, flea, problems, help, please], [maybe, not, take, him, to, dog, park, stupid], [my, dalmation, is, so, cute, I, love, him], [stop, posting, stupid, worthless, garbage], [mr, licks, ate, my, steak, how, to, stop, him], [quit, buying, worthless, dog, food, stupid]] classVec = [0,1,0,1,0,1] #1 is abusive, 0 not return postingList,classVec
vocabSet = vocabSet | set(document) #union of the two sets return list(vocabSet)
returnVec[vocabList.index(word)] = 1 else: print "the word: %s is not in my Vocabulary!" % word return returnVec
def trainNB0(trainMatrix,trainCategory): numTrainDocs = len(trainMatrix) numWords = len(trainMatrix[0]) pAbusive = sum(trainCategory)/float(numTrainDocs)#脏句的比例 p0Num = zeros(numWords); p1Num = zeros(numWords) #zero是numpy带的函数,zeros(i)长度为i的list p0Denom = 0.0; p1Denom = 0.0 for i in range(numTrainDocs): if trainCategory[i] == 1:#如果是粗口句,每个词在p1num加一 p1Num += trainMatrix[i] p1Denom += sum(trainMatrix[i]) else: p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) p1Vect = p1Num/p1Denom #粗口字概率 p0Vect = p0Num/p0Denom return p0Vect,p1Vect,pAbusive
实现效果: 输出粗口字概率list:
[ 0. 0. 0. 0.05263158 0.05263158 0. 0.
0. 0.05263158 0.05263158 0. 0. 0.
0.05263158 0.05263158 0.05263158 0.05263158 0.05263158 0.
0.10526316 0. 0.05263158 0.05263158 0. 0.10526316
0. 0.15789474 0. 0.05263158 0. 0. 0. ]
出现概率最大项:
0.157894736842
对应的词是:stupid
[cute, love, help, garbage, quit, I, problems, is, park, stop, flea, dalmation, licks, food, not, him, buying, posting, has, worthless, ate, to, maybe, please, dog, how, stupid, so, take, mr, steak, my]
下载地址(Bayes)Python机器学习算法入门教程(四) 我们知道有监督学习分为“回归问题”和“分类问题”,前面我们已经认识了什么是“回归问题”,从本节开始我们将讲解“分类问题”的相关算法。在介绍具体的算法前,我们先聊聊到底什么是分类问题。
Python机器学习算法入门教程(三) 本节讲解如何构建线性回归算法中的“线性模型”,所谓“线性”其实就是一条“直线”。因此,本节开篇首先普及一下初中的数学知识“一次函数”。
Python机器学习算法入门教程(二) 常言道“工欲善其事,必先利其器”,在学习机器学习算法之前,我们需要做一些准备工作,首先要检查自己的知识体系是否完备,其次是要搭建机器学习的开发环境。
Python机器学习算法入门教程(一)(下) 机器学习(Machine Learning,简称 ML)是人工智能领域的一个分支,也是人工智能的核心,其涉及知识非常广泛,比如概率论、统计学、近似理论、高等数学等多门学科。
Python机器学习算法入门教程(一)(上) 机器学习(Machine Learning,简称 ML)是人工智能领域的一个分支,也是人工智能的核心,其涉及知识非常广泛,比如概率论、统计学、近似理论、高等数学等多门学科。
Python机器学习算法入门指南(全) 机器学习 作为人工智能领域的核心组成,是计算机程序学习数据经验以优化自身算法,并产生相应的“智能化的”建议与决策的过程。
机器学习实战 | Python机器学习算法应用实践 本篇文章详解机器学习应用流程,应用在结构化数据和非结构化数据(图像)上,借助案例重温机器学习基础知识,并学习应用机器学习解决问题的基本流程。
傲海 著有《机器学习实践应用》,阿里云机器学习PAI产品经理,个人微信公众号 ldquo;凡人机器学习 rdquo;。
相关文章
- python tkinter-菜单栏
- Python 数据竞赛常用 | 可视化数据集缺失情况
- 教你用Python 编写 Hadoop MapReduce 程序
- python机器学习——朴素贝叶斯算法笔记详细记录
- 【Python开发】python PIL读取图像转换为灰度图及另存为其它格式(也可批量改格式)
- python 字符和数值转换
- 学习python技术难吗?
- Python爬虫之自制英汉字典
- python yield 和 yield from用法总结
- Python密码学编程
- Python有哪些常用的机器学习库?
- 机器学习深度学习高阶内容系列-Python实现凸优化求解器
- PyQt(Python+Qt)学习随笔:QScrollArea滚动区域的scrollAreaWidgetContents、widget及setWidget等相关概念解释
- 【机器学习算法-python实现】采样算法的简单实现
- 【机器学习算法-python实现】K-means无监督学习实现分类
- 【机器学习算法-python实现】矩阵去噪以及归一化
- 【机器学习算法-python实现】svm支持向量机(1)—理论知识介绍
- 【机器学习算法-python实现】决策树-Decision tree(2) 决策树的实现
- python 读取Excel(二)之xlwt
- Python赶超R语言,成为数据科学、机器学习平台中最热门的语言?
- Python:机器视觉与Tesseract介绍
- python 关键字:nonlocal 与 global
- 机器学习之路:python 特征降维 主成分分析 PCA
- 机器学习之路:python 集成回归模型 随机森林回归RandomForestRegressor 极端随机森林回归ExtraTreesRegressor GradientBoostingRegressor回归 预测波士顿房价
- 机器学习之路: python 线性回归LinearRegression, 随机参数回归SGDRegressor 预测波士顿房价
- 机器学习之路:python线性回归分类器 LogisticRegression SGDClassifier 进行良恶性肿瘤分类预测