
机器学习之概率论
简介
概率论研究的是事物的不确定性。它是大学数学课程之一,是统计学、信息论的前置课程。相对其他数学课而言,概率论的难度系数属中等,毕竟你在高中就学习过如何计算一个随机变量的期望、方差。从机器学习的视角来看,概率论是必须要了解的,但远不需要达到精通的程度。你只需要灵活运用它,去把机器学习世界的不确定性变量算清楚就足够了。因此,当你掌握概率论的窍门后,概率论就是纸老虎。
概率计算的两个原理
加法原理
我们先从计算某个事件的概率说起。概率是对事件发生可能性的刻画,概率越大事件发生的可能性越大。例如,中国国足与巴西国足将会在明天踢一场友谊赛。既有经验告诉我们,巴西国足实力较强,那么巴西队获胜的概率是比较高的。
这是个很简单的问题,然而当事件相对复杂时,计算概率就没那么容易了。对于复杂事件概率的计算方法,本讲介绍加法原理和乘法原理。
先看加法原理。一个事件的发生可能是多种分支路径的某一个,那么这个事件发生的概率就是全部可能分支的概率之和。
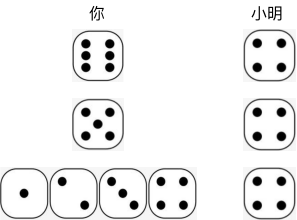
举个例子,假设你在和小明玩掷骰子比大小的游戏。某一局游戏,小明掷了4点,求这一局你获胜的概率是多少。你获胜是个事件,这个事件有两个可能的分支路径:
-
你掷了 6 点,6 大于 4,获胜;
-
你掷了 5 点,5 大于 4,获胜。
其他的分支就无法获胜了。根据加法原理,你最终获胜的概率就是 1/6 + 1/6,等于 1/3。
乘法原理
接着,我们再来看乘法原理。除了多个分支以外,一个事件的发生,还有可能是多个子事件联合发生的结果。此时最终这个事件发生的概率,就是所有子事件发生概率的乘积,这就是乘法原理。

假设你还在和小明玩掷骰子比大小的游戏。这次不同的是,求某一局游戏中,小明掷 4 点并且你最终获胜的概率是多少。此时要计算的事件,包含两个子事件:
-
小明掷 4 点;
-
小明掷 4 点后,你最终获胜。
分析发现,第一个子事件,小明掷4点的概率是1/6。第二个子事件和前面例子一样,概率为1/3。这样根据乘法原理,小明掷4点并且你最终获胜的概率就是1/6×1/3,等于1/18。
加法原理和乘法原理是概率计算的基础,它们可以解决绝大多数事件概率的计算。
极大似然估计原理
核心原理
学会了计算概率的意义是什么呢?其实,概率可以帮助我们决策某个未知的变量。举个例子。假设有两场足球赛在某地同时进行。对阵的双方分别是,巴西队对阵中国队,英国队对阵法国队。我们知道足球赛是户外运动,天气对比赛结果有着重要影响。在此,我们只考虑降水量对比赛结果的影响。


假设在降水量为x时,巴西队获胜的概率是1/(1+2x),反之巴西队不胜的概率就是2x/(1+2x);英国队获胜的概率为2x/(1+3x),英国队不胜的概率为(1+x)/(1+3x)。假设这两场比赛进行时,你在外地出差。比赛结束后,你通过新闻发现结果为巴西胜、英国胜。那么根据乘法原理,你会发现巴西胜、英国胜的概率为 2x/[(1+2x)(1+3x)]。
接下来,你可能会思考,到底比赛那天降水量x这个变量是多少呢?如果我们加一个强约束,即让结果发生可能性最大的变量值,就是真实的值。那么问题就变为,x取值多少时,巴西胜且英国胜的概率2x/[(1+3x)(1+2x)] 能取得最大值。
通过第一讲偏导法或者梯度下降法,我们都能找到当 x= 1/√6 时,这个概率的最大值为 0.2020。所以,在我们没有其他信息输入时,有理由估计出降水量 x=1/√6 是最可信的结果。
用法
上面对降水量的估计,就是极大似然估计的核心原理。不知不觉中,我们已经使用它对未知事件降水量做了一次决策。我们先向它打个招呼。极大似然估计是根据结果,反过来估计过程中某个变量值的过程。因此,从流程上来说,极大似然估计分为两个步骤:
- 假设未知变量x已知,计算某个事件或组合事件发生的概率,得到一个关于 x 的似然函数 P(x)。
- 计算似然函数的最大值maxP(x),并用取得最大值时的x*值,作为真实x的估计值。
机器学习中,极大似然估计在逻辑回归中被用作损失函数,它的用法就是首先假定模型参数已知,并建立样本的似然函数;再对似然函数求解最大值,推导出模型的参数值。关于逻辑回归,我们会在后面深入讲解。
熵
熵的含义
关于基础的概率论知识,我们掌握了极大似然估计就足够在机器学习的世界中呼风唤雨了。除此之外,我们再介绍一下概率论的延伸内容,这就是熵。从学科的边界来说,熵属于信息论的内容。然而,信息论又是以概率论为基础,所以在这门课我们把这两部分内容放在一讲中。刚刚接触熵时,你可能会很蒙,“熵“这个字就让人很困惑费解,生活中很少出现这个字眼。因此,先介绍一下熵的含义。

关于熵,你可以直观地理解为事件结果的不确定性,或者信息量,其单位为bit。举个例子,如果有人告诉你,1+1=2,你可能会说这是“废话“。原因就在于,这个事件的信息量太少、不确定性太低,换个信息论中的说法,就是 1+1=2 的熵太小。有了这个认知后,我们给出熵的计算方法。
熵的计算
熵描述的是个事件的不确定性,如果某个事件有 n 个结果,每个结果的概率为 pn。那么这个事件的熵 H§ 的定义式为
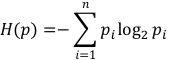
我们看个例子。假设有这样的足球赛,对阵的双方是巴西队和中国队。假设巴西队获胜的概率为0.9,不胜的概率为0.1。那么这场比赛结果的熵就是,-0.9×log0.9-0.1×log0.1,等于 0.4690。
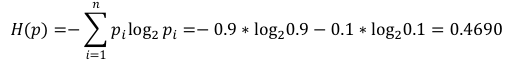
假设另一场焦点之战,对阵的双方是英国队与法国队。其中英国队获胜或不胜的概率都是0.5。此时比赛结果的熵就是,-0.5×log0.5-0.5×log0.5,等于1。后者的熵比前者大,可见结果的不确定更大,比赛结果的信息量就更大。
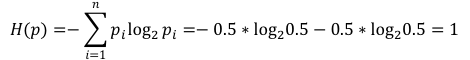
条件熵
熵是对事件结果不确定性的度量,但在某些条件下,这个不确定性会变小。例如,烟民大多是男性,女性吸烟者较少。因此,一个人是否吸烟这个事件的不确定性,会随着知道此人的性别而降低。此时,衡量的就是在某个条件 X 下,事件 Y 的不确定性,也叫做条件熵,记作 H(Y|X) 。其定义式为
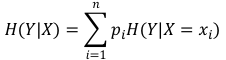
理解为,X 事件每个可能性的结果的熵乘以发生概率的求和。
关于条件熵,再以足球赛的结果的胜负为例。假设中国队与巴西国足比赛。正常情况下,巴西队获胜的概率几乎为1。但最近巴西的气候不太好,球员有可能患病。假设患病的概率为0.5。而一旦球员患病,则巴西队获胜概率将降低为 0.5。计算比赛结果关于球员身体状况的条件熵。

假设Y为比赛结果,X为球员是否健康。根据定义式,你需要计算巴西球员患病后比赛结果的熵,和巴西球员健康比赛时结果的熵。分别为:
-
H(患病)=-0.5×log0.5-0.5×log0.5=1
-
H(健康)=-1×log1-0×log0=0
因此,比赛结果关于球员是否患病的条件熵为 0.5×H(患病) + 0.5×H(健康),结果为 0.5。
信息增益

思考一下熵和条件熵的关系。熵衡量的是事件的不确定性;条件熵衡量的是知道了某个条件后,事件的不确定性。不难发现,对于同一个事件,熵的值肯定是大于或等于条件熵的。原因在于,增加了某个条件后,肯定会辅助降低事件的不确定性,最不济也是让不确定性没有变化。因此,就有了信息增益的概念,写作 g(X,Y)。它的计算方式为熵减去条件熵,如下
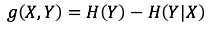
继续以足球赛的结果为例。所有条件和前面一样。即正常情况下,巴西队获胜的概率几乎为1。但最近巴西气候不好,导致球员患病的概率为0.5。且一旦球员患病,则巴西队获胜概率将降低为0.5。根据加法原理和乘法原理,巴西队获胜的概率就是0.5×1 + 0.5×0.5,等于 0.75;则巴西队不胜的概率为 0.25。因此,比赛结果的熵为H(Y)=-0.75×log0.75-0.25×log0.25=0.81。
刚刚我们计算过条件熵,为 0.5。因此,球员是否患病对比赛结果的信息增益为 0.81-0.5,等于 0.31;信息增益比为 0.31/0.81,等于 38%。
基尼系数
最后,我们介绍基尼系数。与熵一样,基尼系数表征的也是事件的不确定性,它的计算方法,只需要把熵定义式中的“-logpi”替换为 1-pi 即可。也就是
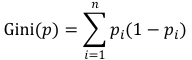
基尼系数定义式可以做个小的变形,也就是
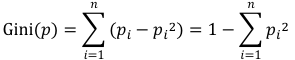
关于基尼系数,你只需要记住定义式,以及它是表征事件不确定性的另一种方式就够了。
总结
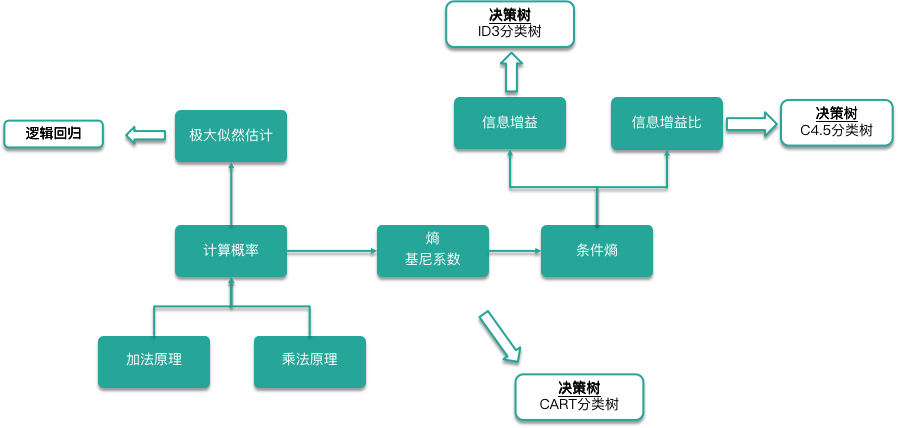
最后,我们对这一讲进行一个总结。按照顺序,这一讲先后学习了计算概率的两个原理,也就是加法原理和乘法原理。
掌握了如何计算概率后,我们学习了极大似然估计的知识。极大似然估计利用使某个结果发生可能性最大的参数值对未知变量进行估计。随后,我们将概率论的知识向信息论方面进行了一定的延伸,学习了描述事件不确定的熵、基尼系数,在某个条件下事件不确定的条件熵,以及这个条件对不确定性降低程度的信息增益和信息增益比。
这些知识只是概率论、信息论中的冰山一角。如果你以为这样就掌握了概率论、信息论,那就大错特错了。但是,有了这些知识,已经足够你在机器学习的世界中驰骋了。以经典模型为例,极大似然估计是逻辑回归计算模型参数的算法。熵、条件熵等内容,可被用作决策树建模时的损失函数。这些知识是掌握逻辑回归,ID3、C4.5、CART 等决策树模型的前置知识。
相关文章
- Spark2.0机器学习系列之5:随机森林
- 机器学习笔记六-----------------使用Prophet(时间序列模型)预测空气质量的数据的例程的笔记
- 机器学习相关数学基础——概率论知识点1
- 利用简单的python机器学习库玩转『低代码』
- 【机器学习】QQ-plot深入理解与实现
- 【机器学习】ICA 原理以及相关概率论,信息论知识简介
- Python 电子病历(EMR)机器学习和深度学习数据预处理,医学文本标签数据预处理
- 机器学习:贝叶斯网络
- 机器学习-无监督学习-聚类:聚类方法(五)--- 均值漂移聚类
- 国际顶会【自然语言处理:ACL、EMNLP、NAACL、Coling】【机器学习:ICML、NIPS、UAI、AISTATS】【深度学习:ICLR】【数据挖掘:KDD、WSDM】【人工智能:AAAI】
- 机器学习
- 《白话深度学习与TensorFlow》——第1章 1.0机器学习是什么
- 一文了解人工智能、机器学习与数据挖掘
- 机器学习之逻辑回归
- B.数据挖掘机器学习[四]---汽车交易价格预测详细版本{嵌入式特征选择(XGBoots,LightGBM),模型调参(贪心、网格、贝叶斯调参)}
- 机器学习笔记之聚类算法 层次聚类 Hierarchical Clustering
- 超越黑名单,运用机器学习检测恶意URL
- 机器学习:模型选择与调优交叉验证和网格搜索
- [Python]机器学习:PageRank原理与实现
- 机器学习入门:线性回归及梯度下降
- 机器学习算法中随机数的生成
- 机器学习数学知识积累之概率论
- 机器学习中的监督学习和非监督学习有什么区别?
- OpenCV人工智能图像处理学习笔记 第6章 计算机视觉加强之机器学习中 SVM和HOG特征
- 七月算法机器学习2 数理统计与参数估计2
- Spark视频王家林大神第8课:彻底理解大数据机器学习
- 【机器学习算法-python实现】svm支持向量机(2)—简化版SMO算法
- 《机器学习》二刷超详细笔记|第三章 线性模型
- 「机器学习」推荐系统简介——一起来看看你是怎么被大数据杀熟的(四)