
机器学习之MCMC算法
1、MCMC概述
从名字我们可以看出,MCMC由两个MC组成,即蒙特卡罗方法(Monte Carlo Simulation,简称MC)和马尔科夫链(Markov Chain ,也简称MC)。之前已经介绍过蒙特卡洛方法,接下来介绍马尔科夫链,以及结合两者的采样算法。
2、马尔科夫链
马尔科夫链的概念在很多地方都被提及过,它的核心思想是某一时刻状态转移的概率只依赖于它的前一个状态。
我们用数学定义来描述,则假设我们的序列状态是...Xt−2, Xt−1, Xt, Xt+1,...,那么我们的在时刻Xt+1的状态的条件概率仅仅依赖于时刻Xt,即:
![]()
既然某一时刻状态转移的概率只依赖于它的前一个状态,那么我们只要能求出系统中任意两个状态之间的转换概率,这个马尔科夫链的模型就定了。状态转移情况如下图所示
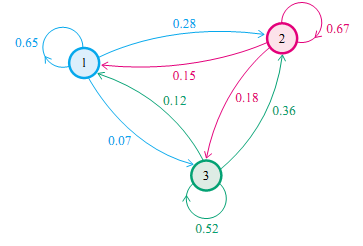
则状态转移矩阵可以表示为

此时,我们给定一个初始状态,然后经过该状态转移矩阵的转换,最终会收敛到一个稳定的状态,具体如马尔科夫链定理所示

由于马尔科夫链能收敛到平稳分布, 于是有了一个想法:如果我们能构造一个转移矩阵为P的马氏链,使得该马氏链的平稳分布恰好是p(x), 那么我们从任何一个初始状态x0出发沿着马氏链转移, 得到一个转移序列 x0, x1, x2,⋯xn, xn+1⋯, 如果马氏链在第n步已经收敛了,于是我们就得到了 π(x) 的样本xn, xn+1⋯(也就是从第n步收敛时开始,之后的x都服从同一个平稳分布,我们可以将这个分布设定为我们的目标采样分布)。
从上面可以看出马尔科夫链的平稳分布收敛主要依赖于状态转移矩阵,所以关键是如何构建状态转移矩阵,使得最终的平稳分布是我们所要的分布。想做到这一点主要依赖于细致平稳定理

3、MCMC采样和M-H采样
在MCMC采样中先随机一个状态转移矩阵Q,然而该矩阵不一定能满足细致平稳定理,一次会做一些改进,具体过程如下

MCMC采样算法的具体流程如下

然而关于MCMC采样有收敛太慢的问题,所以在MCMC的基础上进行改进,引出M-H采样算法

M-H算法的具体流程如下

M-H算法在高维时同样适用

一般来说M-H采样算法较MCMC算法应用更广泛,然而在大数据时代,M-H算法面临着两个问题:
1)在高维时的计算量很大,算法效率很低,同时存在拒绝转移的问题,也会加大计算量
2)由于特征维度大,很多时候我们甚至很难求出目标的各特征维度联合分布,但是可以方便求出各个特征之间的条件概率分布(因此就思考是否能只知道条件概率分布的情况下进行采样)。
4、Gibbs采样


因此可以得出在二维的情况下Gibbs采样算法的流程如下

而在多维的情况下,比如一个n维的概率分布π(x1, x2, ...xn),我们可以通过在n个坐标轴上轮换采样,来得到新的样本。对于轮换到的任意一个坐标轴xi上的转移,马尔科夫链的状态转移概率为P(xi|x1, x2, ..., xi−1, xi+1, ..., xn),即固定n−1个坐标轴,在某一个坐标轴上移动。而在多维的情况下Gibbs采样算法的流程如下

由于Gibbs采样在高维特征时的优势,目前我们通常意义上的MCMC采样都是用的Gibbs采样。当然Gibbs采样是从M-H采样的基础上的进化而来的,同时Gibbs采样要求数据至少有两个维度,一维概率分布的采样是没法用Gibbs采样的,这时M-H采样仍然成立。
相关文章
- (《机器学习》完整版系列)第7章 贝叶斯分类器——7.10 EM算法的使用场景及步骤(反复循环执行E步和M步)
- (《机器学习》完整版系列)第5章 神经网络——5.4 BP算法的高级表达(简洁之美)
- (《机器学习》完整版系列)第14章 概率图模型——14.8 吉布斯采样算法的详细推导(将“多变量”联合采样变为交替地“单变量”采样)
- (《机器学习》完整版系列)第13章 半监督学习——13.5 基于分歧的方法(多学习器间的差异、协同训练算法)
- [吴恩达机器学习笔记]15.1-3非监督学习异常检测算法/高斯回回归模型
- 机器学习面试题——KNN(K Nearest Neighbors)K近邻分类算法
- 机器学习笔记之EM算法(五)广义EM的总结与其他变种形式
- 机器学习算法一览(附python和R代码)
- 阿里亿级并发册 + 机器学习算法 + 面试册 + 优化册 + 代码册 笔记!!!
- opencv3中的机器学习算法之:EM算法
- 机器学习算法与理论用到的数学知识
- 【方法论】机器学习算法概览
- 机器学习九大算法---随机森林
- 10种流行的机器学习算法进行泰坦尼克幸存者分析
- 机器学习——“防干扰训练”《全新算法助机器学习抵抗干扰》
- 【机器学习】支持向量机(SVM)算法
- 【阿里云大学课程】机器学习入门:概念原理及常用算法