
基于MegEngine实现图像分类【附部分源码及模型】
文章目录
前言
本文主要讲解基于megengine深度学习框架实现图像分类,鉴于之前写chainer的麻烦,本结构代码也类似chainer的分类框架,各个模型只需要修改网络结构即可,本次直接一篇博文写完图像分类框架及网络结构的搭建,让志同道合者不需要切换文章。
环境配置:
python 3.8
megengine 1.9.1
cuda 10.1
图像分类发展史及意义
图像分类是图像处理中的一个重要任务。在传统机器学习领域,去识别分类一个一个图像的标准流程是特征提取、特征筛选,最后将特征向量输入合适的分类器完成特征分类。直到2012年Alex Krizhevsky突破性的提出AlexNet的网络结构,借助深度学习的算法,将图像特征的提取、筛选和分类三个模块集成于一体,设计5层卷积层加3层全连接层的深度卷积神经网络结构,逐层对图像信息进行不同方向的挖掘提取,譬如浅层卷积通常获取的是图像边缘等通用特征,深层卷积获取的一般是特定数据集的特定分布特征。AlexNet以15.4%的创纪录低失误率夺得2012年ILSVRC(ImageNet大规模视觉识别挑战赛)的年度冠军,值得一提的是当年亚军得主的错误率为26.2%。AlexNet超越传统机器学习的完美一役被公认为是深度学习领域里程碑式的历史事件,一举吹响了深度学习在计算机领域爆炸发展的号角。
时间转眼来到了2014年,GoogleNet横空出世,此时的深度学习,已经历ZF-net, VGG-net的进一步精炼,在网络的深度,卷积核的尺寸,反向传播中梯度消失问题等技术细节部分已有了详细的讨论,Google在这些技术基础上引入了Inception单元,大破了传统深度神经网络各计算单元之间依次排列,即卷积层->激活层->池化层->下一卷积层的范式,将ImageNet分类错误率提高到了6.7%的高水平。
在网络越来越深,网络结构越来越复杂的趋势下,深度神经网络的训练越来越难,2015年Microsoft大神何恺明(现就职于Facebook AI Research)为了解决训练中准确率先饱和后降低的问题,将residual learning的概念引入深度学习领域,其核心思想是当神经网络在某一层达到饱和时,利用接下来的所有层去映射一个f(x)=x的函数,由于激活层中非线性部分的存在,这一目标几乎是不可能实现的。
但ResNet中,将一部分卷积层短接,则当训练饱和时,接下来的所有层的目标变成了映射一个f(x)=0的函数,为了达到这一目标,只需要训练过程中,各训练变量值收敛至0即可。Resdiual learning的出现,加深网络深度提高模型表现的前提下保证了网络训练的稳定性。2015年,ResNet也以3.6%的超低错误率获得了2015年ImageNet挑战赛的冠军,这一技术也超越了人类的平均识别水平,意味着人工智能在人类舞台中崛起的开始。
一、数据集的准备
1.数据集描述
因ImageNet数据集过于庞大,在学习训练上比较费资源,因此本次数据集使用中国象棋数据集,中国象棋红黑棋子一共有14种类,经过预处理后会得到单独象棋图像,如图:

2.数据集准备
数据集主要以文件夹形式进行区分,每一个类别代表一个文件夹,如图:

在训练的时候直接把此文件夹目录放入代码中即可,对于训练集和验证集,代码会在这里的文件夹中做一个根据提供的划分比例随机拆分。
二、基于MegEngine的图像分类框架构建
本图像分类框架目录结构如下:

BaseModel:此目录保存基于ImageNet已经训练好的模型,可直接测试1000类图像分类
core:此目录主要保存标准的py文件,功能如图像分类正确了计算等
data:此目录主要保存标准py文件,功能如数据加载器,迭代器等
nets:此目录主要保存模型结构
result_Model:此目录是自定义训练数据集的保存模型位置
Ctu_Classification.py:图像分类主类实现及主入口
1.引入库
import os, sys, megengine,math,time,json,cv2
sys.path.append('.')
import numpy as np
from PIL import Image
import megengine.distributed as dist
import megengine.data
import megengine.data.transform as T
import megengine.functional as F
import megengine.autodiff as autodiff
import megengine.optimizer as optim
2.CPU/GPU配置
if USEGPU!='-1' and dist.helper.get_device_count_by_fork("gpu") > 0:
megengine.set_default_device('gpux')
else:
megengine.set_default_device('cpux')
USEGPU='-1'
os.environ['CUDA_VISIBLE_DEVICES']= USEGPU
3.设置模型字典
这里主要是体现本图像分类工程的网络结构,可根据自己爱好自行选择:
self.model_dict={
'resnet18':resnet18,
'resnet34':resnet34,
'resnet50':resnet50,
'resnet101':resnet101,
'resnet152':resnet152,
'mobilenet_v2':mobilenet_v2,
'shufflenet_v1_x0_5_g3':shufflenet_v1_x0_5_g3,
'shufflenet_v1_x1_0_g3':shufflenet_v1_x1_0_g3,
'shufflenet_v1_x1_5_g3':shufflenet_v1_x1_5_g3,
'shufflenet_v1_x2_0_g3':shufflenet_v1_x2_0_g3,
'resnext50_32x4d':resnext50_32x4d,
'resnext101_32x8d':resnext101_32x8d,
'shufflenet_v2_x0_5':shufflenet_v2_x0_5,
'shufflenet_v2_x1_0':shufflenet_v2_x1_0,
'shufflenet_v2_x1_5':shufflenet_v2_x1_5,
'shufflenet_v2_x2_0':shufflenet_v2_x2_0,
'alexnet':alexnet,
'espnetv2_s_0_5':espnetv2_s_0_5,
'espnetv2_s_1_0':espnetv2_s_1_0,
'espnetv2_s_1_25':espnetv2_s_1_25,
'espnetv2_s_1_5':espnetv2_s_1_5,
'espnetv2_s_2_0':espnetv2_s_2_0,
'vgg11':vgg11,
'vgg11_bn':vgg11_bn,
'vgg13':vgg13,
'vgg13_bn':vgg13_bn,
'vgg16':vgg16,
'vgg16_bn':vgg16_bn,
'vgg19':vgg19,
'vgg19_bn':vgg19_bn,
'swin_tiny_patch4_window7_224':swin_tiny_patch4_window7_224,
'swin_small_patch4_window7_224': swin_small_patch4_window7_224,
'swin_base_patch4_window7_224': swin_base_patch4_window7_224,
'swin_base_patch4_window12_384': swin_base_patch4_window12_384,
'swin_large_patch4_window7_224': swin_large_patch4_window7_224,
'swin_large_patch4_window12_384': swin_large_patch4_window12_384
}
4.解析数据集到列表中
def CreateDataList(DataDir,train_split=0.9):
class_name = os.listdir(DataDir)
DataList=[]
for each_Num in range(len(class_name)):
for img_path in os.listdir(os.path.join(DataDir,class_name[each_Num])):
DataList.append(os.path.join(DataDir,class_name[each_Num],img_path) + ",%d" % each_Num)
random.shuffle(DataList)
if train_split>0 and train_split<1:
train_data_list = DataList[:int(len(DataList)*train_split)]
val_data_list = DataList[int(len(DataList)*train_split):]
else:
train_data_list = DataList
val_data_list = DataList
return train_data_list, val_data_list, class_name
5.设置数据迭代器
class ImageDataSet(VisionDataset):
def __init__(self, data_list):
super().__init__(data_list, order=("image", "image_category"))
self.data_list = data_list
def __getitem__(self, index: int):
path, label = self.data_list[index].split(',')
img = cv2.imdecode(np.fromfile(path, dtype=np.uint8), 1)
return img, int(label)
def __len__(self):
return len(self.data_list)
6.数据增强
这里包含随机裁减,随机反转,颜色空间改变,像素的标准化,通道修改等操作
self.transform = [
T.RandomResizedCrop(self.image_size),
T.RandomHorizontalFlip(),
T.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4),
T.Normalize(
mean=[103.530, 116.280, 123.675], std=[57.375, 57.120, 58.395]
), # BGR
T.ToMode("CHW"),
]
7.获取loader
self.train_dataloader = megengine.data.DataLoader(train_dataset, sampler=train_sampler, transform=T.Compose(self.transform), num_workers=num_workes)
self.valid_dataloader = megengine.data.DataLoader(valid_dataset, sampler=valid_sampler, transform=T.Compose(self.transform), num_workers=num_workes)
8.模型构建
这里根据模型字典及类别即可得到模型结构,后续会对此模型字典内部实现进行解析
self.model = self.model_dict[self.model_name](num_classes = len(self.classes_names))
9.模型训练
1.优化器及参数初始化
gm = autodiff.GradManager().attach(self.model.parameters(), callbacks=None)
params_wd = []
params_nwd = []
for n, p in self.model.named_parameters():
if n.find("weight") >= 0 and len(p.shape) > 1:
params_wd.append(p)
else:
params_nwd.append(p)
opt = optim.SGD(
[
{"params": params_wd},
{"params": params_nwd, "weight_decay": 1e-4},
],
lr=learning_rate * dist.get_world_size(),
momentum=0.9,
weight_decay=4e-5)
2.模型训练
with gm:
logits = self.model(image)
loss = F.nn.cross_entropy(logits, label, label_smooth=0.1)
acc1, acc5 = F.topk_accuracy(logits, label, topk=(1, 5))
gm.backward(loss)
opt.step().clear_grad()
objs_train.update(loss.item())
top1_train.update(100 * acc1.item())
top5_train.update(100 * acc5.item())
clck_train.update(time.time() - t)
3.模型验证
for _, (image, label) in enumerate(self.valid_dataloader):
image = megengine.tensor(image, dtype="float32")
label = megengine.tensor(label, dtype="int32")
n = image.shape[0]
logits = self.model(image)
loss = F.nn.cross_entropy(logits, label, label_smooth=0.1)
acc1, acc5 = F.topk_accuracy(logits, label, topk=(1, 5))
if dist.get_world_size() > 1:
loss = F.distributed.all_reduce_sum(loss) / dist.get_world_size()
acc1 = F.distributed.all_reduce_sum(acc1) / dist.get_world_size()
acc5 = F.distributed.all_reduce_sum(acc5) / dist.get_world_size()
objs_valid.update(loss.item(), n)
top1_valid.update(100 * acc1.item(), n)
top5_valid.update(100 * acc5.item(), n)
clck_valid.update(time.time() - t, n)
t = time.time()
4.模型保存
模型保存结构必须保持结构一致,如图:
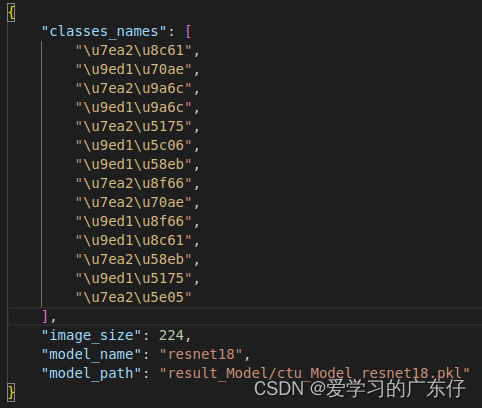
主要包含类别,图像大小,模型选择,模型保存路径
megengine.save(
{
"epoch": (step + 1) // math.ceil(self.num_train/self.batch_size),
"state_dict": self.model.state_dict(),
},
ClassDict['model_path'],
)
10.模型预测
def predict(self,img_cv):
processed_img = self.transform.apply(img_cv)[np.newaxis, :]
processed_img = megengine.tensor(processed_img, dtype="float32")
logits = self.model(processed_img)
probs = F.softmax(logits)
top_probs, classes = F.topk(probs, k=5, descending=True)
return_dict = {}
for rank, (prob, classid) in enumerate(zip(top_probs.numpy().reshape(-1), classes.numpy().reshape(-1))):
return_dict[rank]={
"class":self.classes_names[classid],
"score":100 * prob
}
return return_dict
三、基于MegEngine的模型构建
先看下模型字典及nets文件夹目录,代表会有此类模型:
self.model_dict={
'resnet18':resnet18,
'resnet34':resnet34,
'resnet50':resnet50,
'resnet101':resnet101,
'resnet152':resnet152,
'mobilenet_v2':mobilenet_v2,
'shufflenet_v1_x0_5_g3':shufflenet_v1_x0_5_g3,
'shufflenet_v1_x1_0_g3':shufflenet_v1_x1_0_g3,
'shufflenet_v1_x1_5_g3':shufflenet_v1_x1_5_g3,
'shufflenet_v1_x2_0_g3':shufflenet_v1_x2_0_g3,
'resnext50_32x4d':resnext50_32x4d,
'resnext101_32x8d':resnext101_32x8d,
'shufflenet_v2_x0_5':shufflenet_v2_x0_5,
'shufflenet_v2_x1_0':shufflenet_v2_x1_0,
'shufflenet_v2_x1_5':shufflenet_v2_x1_5,
'shufflenet_v2_x2_0':shufflenet_v2_x2_0,
'alexnet':alexnet,
'espnetv2_s_0_5':espnetv2_s_0_5,
'espnetv2_s_1_0':espnetv2_s_1_0,
'espnetv2_s_1_25':espnetv2_s_1_25,
'espnetv2_s_1_5':espnetv2_s_1_5,
'espnetv2_s_2_0':espnetv2_s_2_0,
'vgg11':vgg11,
'vgg11_bn':vgg11_bn,
'vgg13':vgg13,
'vgg13_bn':vgg13_bn,
'vgg16':vgg16,
'vgg16_bn':vgg16_bn,
'vgg19':vgg19,
'vgg19_bn':vgg19_bn,
'swin_tiny_patch4_window7_224':swin_tiny_patch4_window7_224,
'swin_small_patch4_window7_224': swin_small_patch4_window7_224,
'swin_base_patch4_window7_224': swin_base_patch4_window7_224,
'swin_base_patch4_window12_384': swin_base_patch4_window12_384,
'swin_large_patch4_window7_224': swin_large_patch4_window7_224,
'swin_large_patch4_window12_384': swin_large_patch4_window12_384
}
引入库:
from nets.mobilenet_v2 import mobilenet_v2
from nets.shufflenetv1 import shufflenet_v1_x0_5_g3,shufflenet_v1_x1_0_g3,shufflenet_v1_x1_5_g3,shufflenet_v1_x2_0_g3
from nets.shufflenetv2 import shufflenet_v2_x0_5,shufflenet_v2_x1_0,shufflenet_v2_x1_5,shufflenet_v2_x2_0
from nets.resnet import resnet18,resnet34,resnet50,resnet101,resnet152,resnext50_32x4d,resnext101_32x8d
from nets.alexnet import alexnet
from nets.espnets import espnetv2_s_0_5,espnetv2_s_1_0,espnetv2_s_1_25,espnetv2_s_1_5,espnetv2_s_2_0
from nets.vgg import vgg11,vgg11_bn,vgg13,vgg13_bn,vgg16,vgg16_bn,vgg19,vgg19_bn
from nets.swin_transformer import swin_tiny_patch4_window7_224, swin_small_patch4_window7_224, swin_base_patch4_window7_224, swin_base_patch4_window12_384, swin_large_patch4_window7_224, swin_large_patch4_window12_384
1.AlexNet实现
class AlexNet(M.Module):
def __init__(self, in_ch=3, num_classes=1000):
super(AlexNet, self).__init__()
self.features = M.Sequential(
M.Conv2d(in_ch, 64, kernel_size=11, stride=4, padding=11//4),
M.ReLU(),
M.MaxPool2d(kernel_size=3, stride=2),
M.Conv2d(64, 192, kernel_size=5, padding=2),
M.ReLU(),
M.MaxPool2d(kernel_size=3, stride=2),
M.Conv2d(192, 384, kernel_size=3, stride=1, padding=1),
M.ReLU(),
M.Conv2d(384, 256, kernel_size=3, stride=1, padding=1),
M.ReLU(),
M.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
M.ReLU(),
M.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = M.AdaptiveAvgPool2d((6,6))
self.classifier = M.Sequential(
M.Dropout(),
M.Linear(256*6*6, 4096),
M.ReLU(),
M.Dropout(),
M.Linear(4096, 4096),
M.ReLU(),
M.Linear(4096, num_classes)
)
def get_classifier(self):
return self.classifier
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = mge.functional.flatten(x, 1)
x = self.classifier(x)
return x
2.ResNet实现
class BasicBlock(M.Module):
expansion = 1
def __init__(
self,
in_channels,
channels,
stride=1,
groups=1,
base_width=64,
dilation=1,
norm=M.BatchNorm2d,
):
super().__init__()
if groups != 1 or base_width != 64:
raise ValueError("BasicBlock only supports groups=1 and base_width=64")
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
self.conv1 = M.Conv2d(
in_channels, channels, 3, stride, padding=dilation, bias=False
)
self.bn1 = norm(channels)
self.conv2 = M.Conv2d(channels, channels, 3, 1, padding=1, bias=False)
self.bn2 = norm(channels)
self.downsample = (
M.Identity()
if in_channels == channels and stride == 1
else M.Sequential(
M.Conv2d(in_channels, channels, 1, stride, bias=False), norm(channels),
)
)
def forward(self, x):
identity = x
x = self.conv1(x)
x = self.bn1(x)
x = F.relu(x)
x = self.conv2(x)
x = self.bn2(x)
identity = self.downsample(identity)
x += identity
x = F.relu(x)
return x
class Bottleneck(M.Module):
expansion = 4
def __init__(
self,
in_channels,
channels,
stride=1,
groups=1,
base_width=64,
dilation=1,
norm=M.BatchNorm2d,
):
super().__init__()
width = int(channels * (base_width / 64.0)) * groups
self.conv1 = M.Conv2d(in_channels, width, 1, 1, bias=False)
self.bn1 = norm(width)
self.conv2 = M.Conv2d(
width,
width,
3,
stride,
padding=dilation,
groups=groups,
dilation=dilation,
bias=False,
)
self.bn2 = norm(width)
self.conv3 = M.Conv2d(width, channels * self.expansion, 1, 1, bias=False)
self.bn3 = norm(channels * self.expansion)
self.downsample = (
M.Identity()
if in_channels == channels * self.expansion and stride == 1
else M.Sequential(
M.Conv2d(in_channels, channels * self.expansion, 1, stride, bias=False),
norm(channels * self.expansion),
)
)
def forward(self, x):
identity = x
x = self.conv1(x)
x = self.bn1(x)
x = F.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = F.relu(x)
x = self.conv3(x)
x = self.bn3(x)
identity = self.downsample(identity)
x += identity
x = F.relu(x)
return x
class ResNet(M.Module):
def __init__(
self,
block,
layers,
num_classes=1000,
zero_init_residual=False,
groups=1,
width_per_group=64,
replace_stride_with_dilation=None,
norm=M.BatchNorm2d,
):
super().__init__()
self.in_channels = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError(
"replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation)
)
self.groups = groups
self.base_width = width_per_group
self.conv1 = M.Conv2d(
3, self.in_channels, kernel_size=7, stride=2, padding=3, bias=False
)
self.bn1 = norm(self.in_channels)
self.maxpool = M.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], norm=norm)
self.layer2 = self._make_layer(
block,
128,
layers[1],
stride=2,
dilate=replace_stride_with_dilation[0],
norm=norm,
)
self.layer3 = self._make_layer(
block,
256,
layers[2],
stride=2,
dilate=replace_stride_with_dilation[1],
norm=norm,
)
self.layer4 = self._make_layer(
block,
512,
layers[3],
stride=2,
dilate=replace_stride_with_dilation[2],
norm=norm,
)
self.fc = M.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, M.Conv2d):
M.init.msra_normal_(m.weight, mode="fan_out", nonlinearity="relu")
if m.bias is not None:
fan_in, _ = M.init.calculate_fan_in_and_fan_out(m.weight)
bound = 1 / math.sqrt(fan_in)
M.init.uniform_(m.bias, -bound, bound)
elif isinstance(m, M.BatchNorm2d):
M.init.ones_(m.weight)
M.init.zeros_(m.bias)
elif isinstance(m, M.Linear):
M.init.msra_uniform_(m.weight, a=math.sqrt(5))
if m.bias is not None:
fan_in, _ = M.init.calculate_fan_in_and_fan_out(m.weight)
bound = 1 / math.sqrt(fan_in)
M.init.uniform_(m.bias, -bound, bound)
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
M.init.zeros_(m.bn3.weight)
elif isinstance(m, BasicBlock):
M.init.zeros_(m.bn2.weight)
def _make_layer(
self, block, channels, blocks, stride=1, dilate=False, norm=M.BatchNorm2d
):
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
layers = []
layers.append(
block(
self.in_channels,
channels,
stride,
groups=self.groups,
base_width=self.base_width,
dilation=previous_dilation,
norm=norm,
)
)
self.in_channels = channels * block.expansion
for _ in range(1, blocks):
layers.append(
block(
self.in_channels,
channels,
groups=self.groups,
base_width=self.base_width,
dilation=self.dilation,
norm=norm,
)
)
return M.Sequential(*layers)
def extract_features(self, x):
outputs = {}
x = self.conv1(x)
x = self.bn1(x)
x = F.relu(x)
x = self.maxpool(x)
outputs["stem"] = x
x = self.layer1(x)
outputs["res2"] = x
x = self.layer2(x)
outputs["res3"] = x
x = self.layer3(x)
outputs["res4"] = x
x = self.layer4(x)
outputs["res5"] = x
return outputs
def forward(self, x):
x = self.extract_features(x)["res5"]
x = F.avg_pool2d(x, 7)
x = F.flatten(x, 1)
x = self.fc(x)
return x
3.VGG实现
class VGG(M.Module):
def __init__(self, cfg, num_classes=1000, in_channels=3, init_weights=True, batch_norm=False):
super(VGG, self).__init__()
self.features = self._make_layers(in_channels, cfg, batch_norm)
self.avgpool = M.AdaptiveAvgPool2d((7,7))
self.classifier = M.Sequential(
M.Linear(512*7*7, 4096),
M.ReLU(),
M.Dropout(),
M.Linear(4096, 4096),
M.ReLU(),
M.Dropout(),
M.Linear(4096, num_classes)
)
if init_weights:
self._init_weights()
def _make_layers(self, in_channels, cfg, batch_norm=False):
layers = []
in_ch = in_channels
for v in cfg:
if v == "M":
layers.append(M.MaxPool2d(kernel_size=2, stride=2))
else:
conv2d = M.Conv2d(in_ch, v, kernel_size=3, stride=1, padding=1)
if batch_norm:
layers += [conv2d, M.BatchNorm2d(v), M.ReLU()]
else:
layers += [conv2d, M.ReLU()]
in_ch = v
return M.Sequential(*layers)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = F.flatten(x, 1)
x = self.classifier(x)
return x
def get_classifier(self):
return self.classifier
def _init_weights(self):
for m in self.modules():
if isinstance(m, M.Conv2d):
M.init.msra_normal_(m.weight)
if m.bias is not None:
M.init.zeros_(m.bias)
elif isinstance(m, M.BatchNorm2d):
M.init.fill_(m.weight, 1)
M.init.zeros_(m.bias)
elif isinstance(m, M.Linear):
M.init.normal_(m.weight, 0, 0.01)
M.init.zeros_(m.bias)
四、模型主入口
本人主要习惯简洁方式,因此主入口的实现过程也是很简单的
if __name__ == "__main__":
# ctu = Ctu_Classification(USEGPU="-1",image_size=224,log_file=None)
# ctu.InitModel(r'./DataSet/DataImage',train_split=1,batch_size=1,model_name='resnet18',Pre_Model=None)
# ctu.train(TrainNum=150,learning_rate=0.001, ModelPath='result_Model')
ctu = Ctu_Classification(USEGPU="-1",image_size=224,log_file=None)
ctu.LoadModel('./result_Model/ctu_params_resnet18.json')
for root, dirs, files in os.walk(r'./DataSet/test'):
for f in files:
img_cv = ctu.read_image(os.path.join(root, f))
if img_cv is None:
continue
res = ctu.predict(img_cv)
print(res)
cv2.imshow("result", img_cv)
cv2.waitKey()
五、效果展示
1.自定义数据集效果展示
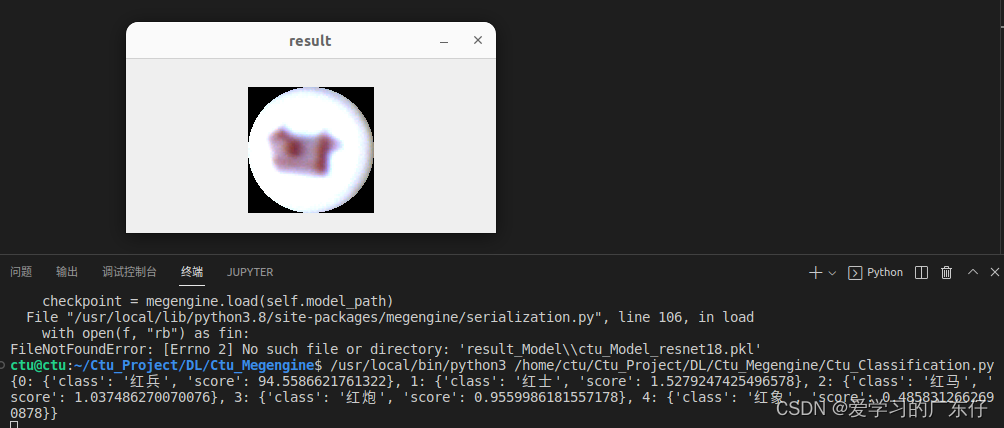
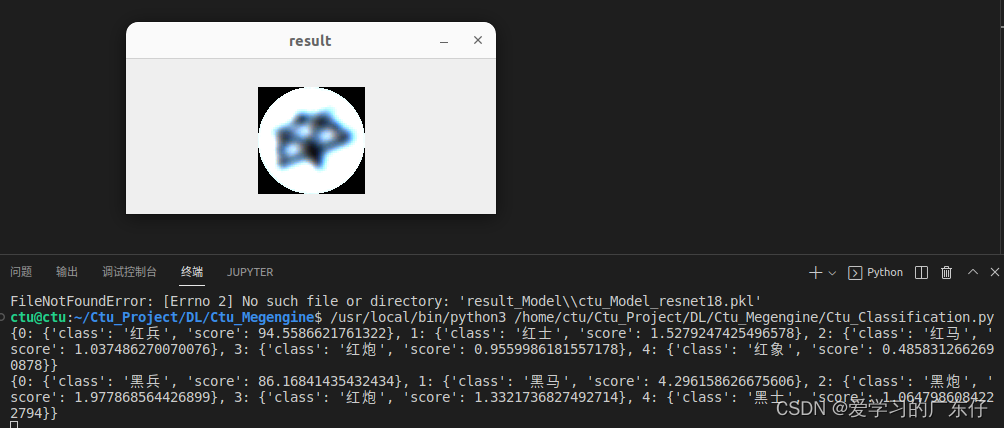
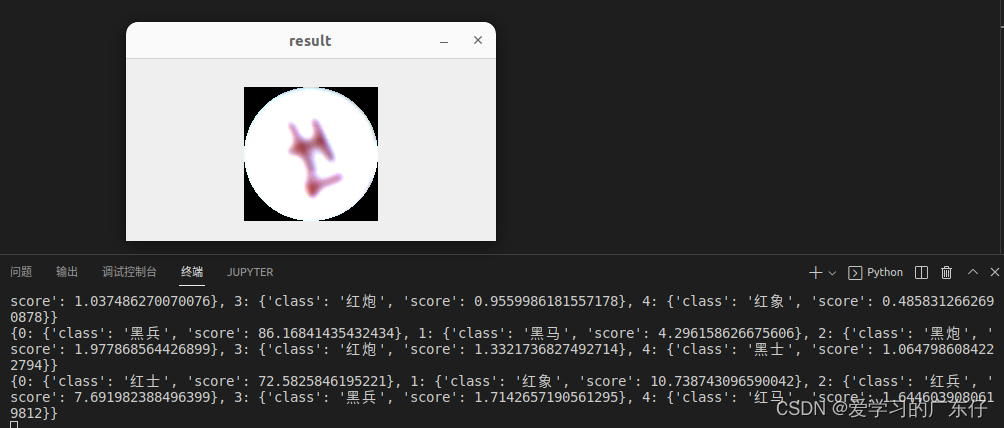
2.ImageNet数据集效果展示
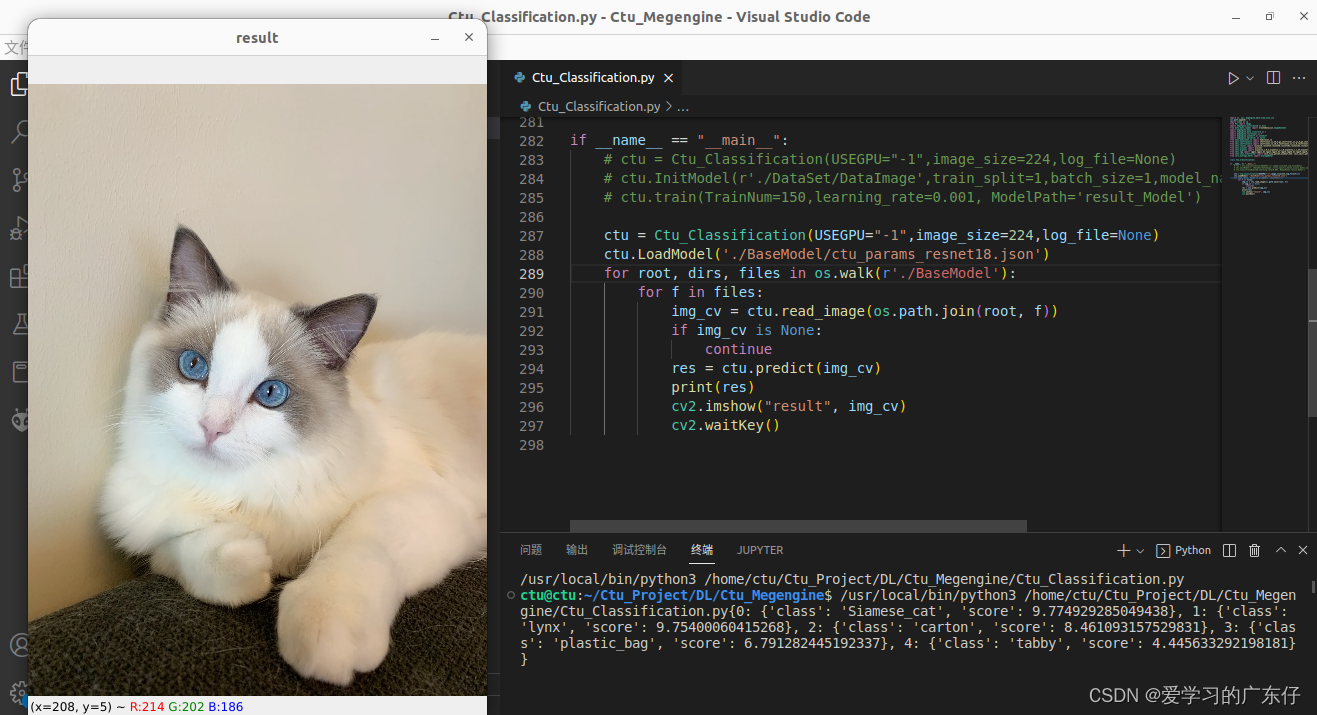
六、ImageNet各模型免费下载
AlexNet
VGG11
VGG13
VGG16
VGG19
ResNet18
ResNet34
ResNet50
ResNet101
ResNet152
SeNetV2_0.5
SeNetV2_1.0
SeNetV2_1.5
SeNetV2_2.0
ESPNet_2.0
ESPNetV2_1.0
ESPNetV2_1.25
ESPNetV2_1.5
ESPNetV2_2.0
总结
本文调用方式简单,模型结构丰富,博客只是展示了几个模型结构的实现,对模型感兴趣的或者其他问题的可以私聊
相关文章
- 医院预约挂号系统设计与实现(论文+源码)_kaic
- 基于线上考研资讯数据抓取的推荐系统的设计与实现(论文+源码)_kaic
- 基于JAVA的学生管理系统的设计与实现(论文+源码)_kaic
- 基于JSP的网上购物系统的设计与实现(论文+源码)_kaic
- 基于微信小程序的英语单词记忆系统的设计与实现(源码+程序)_kaic
- 社区便利店销售微信APP的设计与实现(源码+论文)_kaic
- 基于智能推荐的健身场所的设计与实现(论文+源码)_kaic
- 毕业论文提交系统的设计与实现(论文+源码)_kiac
- 小区疫情防控系统的设计与实现(论文+源码)_kaic
- 基于SVM算法的股价预测系统的设计与实现(论文+源码)_kaic
- Java字节码修改库ASM#ClassReader实现原理及源码分析
- 基于python结合dlib实现人脸识别【附源码】
- 基于C#结合dlib实现人脸识别及眼部识别【附源码】
- 基于Mxnet实现GAN-CycleGAN【附部分源码】
- 基于Android的运动记录APP设计与实现(论文+源码)_kaic
- 基于JAVA的学生管理系统的设计与实现(论文+源码)_kaic
- 基于SpringBoot的分销商城的设计与实现(论文+源码)_kaic
- 基于web网上订餐系统的设计与实现(论文+源码)_kaic
- 医院预约挂号系统设计与实现(论文+源码)_kaic
- 基于智能推荐的健身场所的设计与实现(论文+源码)_kaic
- 基于Vue的在线购物系统的设计与实现(论文+源码)_kaic
- [含论文+源码等]ssm实现的酒店管理系统
- 【源码】学生疫情期间信息管理系统(python实现)
- 【基于Java+Swing的飞机大战游戏的设计与实现(效果+源码+论文 获取~~)】
- 【项目精选】基于Java的愤怒的小鸟游戏的设计与实现(视频+论文+源码)
- 【项目精选】基于Vue + ECharts的数据可视化系统的设计与实现(论文+源码+视频)
- 使用 CSS3 实现 3D 图片滑块效果【附源码下载】
- Windows虚拟地址转物理地址(原理+源码实现,附简单小工具)
- Unity3d 基于xlua热更新实现系列三:生成AB包导出并实现AB包动态加载(资源半热更改)(含源码)
- 修改 Chromium 源码,实现 HEVC/H.265 4K 视频播放
- Android例子源码仿支付宝手势密码的功能实现
- 前端路由实现与 react-router 源码分析