
基于SVM算法的股价预测系统的设计与实现(论文+源码)_kaic
目 录
1 研究意义
2 开发工具简介
2.1 Vscode
2.2 Dreaweaver
2.3 Django
2.4 Tushare
2.5 Sklearn
2.6 Matplotlib
2.7 numpy
3 系统分析
3.1 系统可行性分析
3.1.1 技术可行性
3.1.2 运行可行性
3.1.3 经济可行性
3.2 需求分析
3.3 业务流程图
4 总体设计
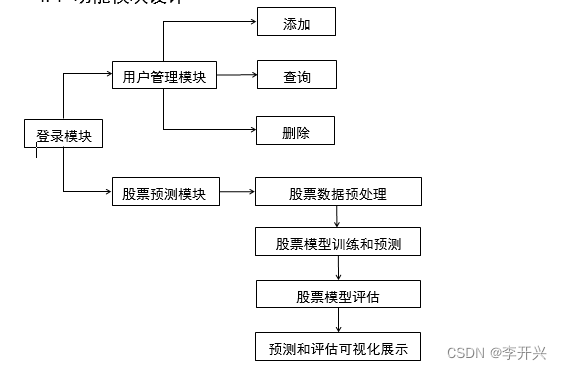
4.1 功能模块设计
4.1.1 登录模块
4.1.2 股票预测模块
4.2 数据库设计
5 系统实现
5.1 登录模块实现
5.2 股票预测模块
5.3 用户管理
6 系统测试
6.1 测试所需的环境
6.2 测试用例
6.2.1 登录测试
6.2.2 股票预测测试
总 结
参考文献
致 谢
1 研究意义
如今,提到股市,很多人都有所了解,我国虽然目前只有量大证券交易市场,但是以为我国人口基数大,所以股民的数量也相应地越来越多,但是有些股民在刚刚进入股票市场时对于股票的风险没有足够的了解,股票市场风险是股票市场上股票价格上升或下降变化所造成损失的概率。它主要产生于股票市场价格的波动,是在证券投资时的主要风险之一。有些人为了炒股票,输了全部家产,导致妻离子散,家破人亡,最后的结果不堪设想,后果严重,网上有许多股民以为不了解风险或者对于风险的预判不够准确导致了非常重大的损失,对其家庭也造成了非常大的影响,这样的案例数不胜数,造成的损失也难以统计。所以一只股票在未来时间内的涨跌就显得非常的重要,很大程度的决定了部分股民风险的大小,使得我也对此产生了兴趣,想通过自己的实践来尝试一下有没有什么方法能够帮助一些股民有效的规避风险,或者降低风险,通过查阅书籍以及在互联网上的浏览发现在机器学习理论日渐火热的现在,网上一部分股民对于股票的走势预测信息也越来越多,于是决定尝试设计一个基于SVM算法的股价预测系统,这个系统通过对一只股票过去的开盘价,最高价,最低价,收盘价,成交量,成交金额等进行分析,分类,整理并训练设计出一个使得我们能够预测出这只股票在未来几天内的涨跌情况的系统,希望能够帮助一部分股民降低部分风险。
该网站应具备以下特点:
1.设计要科学:基于SVM框架来设计。
2.实时效用性:本系统旨在帮助用户降低风险。从用户的角度来看,就是以更高的准确率帮助用户最大化的降低购买股票的风险。
2 开发工具简介
2.1 Vscode
VSCode,是一个运行于 Mac OS X、Windows和 Linux 之上的,针对于编写现代 Web 和云应用的跨平台源代码编辑器。该软件优点有开源,免费,有完整的插件生态,语法高亮和智能提示代码自动补全,由微软开发较为熟悉程序员的需求使用比较方便,查看定义等功能,并且内置了命令行工具和 Git 版本管理工具。
VSCode 有完善的插件生态,插件功能种类繁多,用户可以更改主题和键盘快捷方式实现个性化设置,也可以通过内置的扩展程序商店安装扩展以拓展软件功能。
VScode可以支持c 语言,java , python ,JavaScript等多达37种语言,可以方便的通过安装python插件的方式很好的实现对python代码的编辑运行。
在拥有众多优势的情况下VSCode 在启动时的速度、使用时的流畅度和内存占用等等方面相比较下也都领先于同类型的其他编辑器。
2.2 Dreaweaver
Dreaweaver简称DW是一款由Macromedia公司开发的可视化网页代码编辑器。该款网页代码编辑器有着多年的历史,被大部分使用者给予好评,通过对 HTML、CSS、JavaScript等内容的支持,使得制作网站更加的方便快捷同时还支持ASP,PHP,XML等程序语言的编写以及调试。
Dreaweaver与其他相同类型的软件相比不会生成冗余代码,不像别的软件在使用时会生成很多的冗余代码,这些代码会导致以后对网页做出修改带来了非常多的不便,同时也使得这个文件所占的内纯也变得庞大,但是Dw在用户的使用过程中就不会生成多余的代码,同时还可以清除掉该网页原本生成的冗余代码,就避免了其他的麻烦,且大大的提高了效率。Dw在使用时对于代码的编辑也比其他软件方便,可视化编辑和源代码编辑有着各自的优劣,Dw在使用时就不用在两者间做取舍,可以在可视化编辑和源代码编辑两者间切换。Dw在使用的时候也适配安装各种各样的插件,这项功能让Dw的功能变的强大,同时也使得Dw更加符合每个人自己的需求,同时也更加人性化。
2.3 Django
Django是使用Python开发的的一个开放源代码的Web框架,它起源于开源社区,几乎囊括了Web应用的各个方面,用于快速搭建高性能的网站。使用Django架构,程序员能够高效、迅速地创建高品质、易维护的应用程序。
Django在使用时有着以下几点优点:使用Django来对Python网站进行开发会变得更加容易,这是因为Python自身本来缺少内置网站开发功能。但是Django为其提供了这一功能,弥补了这一差距。Django开发因其“包含电池”的理念而受到大部分程序员的好评。它为Web的开发提供了许多通用功能,使程序员不必编写每个功能的代码,有效的节省了时间,提高了效率。Django Web框架同时还支持其他的高级功能,例如ORM,数据库迁移,用户身份验证,管理面板等。Django受大部分使用他的程序员的喜爱是因为它具有简化数据库工作的功能,并且能够加快开发的过程,同时使开发人员能够构建可伸缩的应用程序。开发人员也使用它,因为它允许将Django项目拆分为多个应用程序。
2.4 Tushare
TuShare 是一个免费、开源的 python 财经数据接口包。主要对股票金融类的数据进行采集和分类以及最终到数据储存的过程提供帮助,使得参与金融行业工作的人员对于数据的整理更加的方便,减轻了他们的工作量。同时也提供免费的数据接口,包含沪深股票数据、财务报表数据、指数、基金、期权、期货、港股、美股、宏观经济等数据,甚至上市公司公告、全球新冠疫情数据也包含在内。Tushare 提供http, Python, MATLAB, R 的数据接口,方便获取实时数据。Tushare 社区已经开发开放了主流编程语言的SDK,开箱即用,非常方便。使用者可以基于http获取数据,亦可使用Python、MATLAB的SDK获取数据,还可以在R中获取数据。获取数据的方式在官网都有详细介绍。Tushare 社区的官网给出了各种数据的详细说明。Tushare 官方给出了操作手册,即使小白也能快速上手。除此之外,Tushare 还提供定制服务,以帮助用户完成定制开发。 Tushare从出现一直到现在,已经协助不计其数的用户提高了在数据方面的效率,同时也收到了很多用户的好评,Tushare也同以前一样的以免费和开源的形式分享给他家,希望能够帮助到更多有需求的人。
2.5 Sklearn
Sklearn全称Scikit-Learn,是基于Python语言的机器学习工具,其里面的API的设计很好,所有对象的接口都比较简单,方便新手的使用,使得新手在使用时也能够简单的上手。在 Sklearn 里面有六大任务模块:分别是分类(Classification)、回归(Regression)、非监督分类(Clustering)、降维(Dimensionality reduction)、模型选择(Model Selection )和数据处理(Preprocessing )。使用sklearn可以使得我们对一个复杂的算法的实现变得简单,使得原本很复杂的算法只需要调用几行API就可以实现,能够大大缩短我们实现任务的周期,使我们有更多时间去做其他内容的修改。Scikit-learn项目始于scikits.learn,这是David Cournapeau的Google Summer of Code项目。它的名称源于它是“ SciKit”(SciPy工具包)的概念,它是SciPy的独立开发和分布式第三方扩展。原始代码库后来被其他开发人员重写。2010年费边Pedregosa,盖尔Varoquaux,亚历山大Gramfort和Vincent米歇尔,全部由法国国家信息与自动化研究所的罗屈昂库尔,法国,把该项目的领导和做出的首次公开发行在二月一日2010在各种scikits中,scikit-learn以及scikit-image在2012年11月被描述为“维护良好且受欢迎” 。Scikit-learn是GitHub上最受欢迎的机器学习库之一。
2.6 Matplotlib
Matplotlib是Python中非常基础也是使用的非常多的可视化工具,能够轻易实现创建2D图表和小部分3D的图表,让简单的事情变得更简单,让无法实现的事情变得可能实现,程序员能够仅凭借少数代码,就能够生成绘图,直方图,功率谱,条形图,错误图,散点图等。也就是Python的一个外部的模块,提供了绘图的功能,最初Matplotlib是模仿MATLAB,所以它有两种接口制作图形,一个是面向对象编程,一个是类似于MATLAB的接口pyplot。为了方便使用者的绘图,pyplot模块提供了与MATLAB相像的界面,方便大家的使用,特别是与IPython结合使用时。对于高级用户,可以通过面向对象的界面或MATLAB用户熟悉的一组函数完全控制线条样式,字体属性,轴属性等。
Matplotlib的具体内容包含如下:
1.Matplotlib中的基本图表包括的元素:x轴和y轴,水平和垂直的轴线,x轴和y轴刻度,刻度标示坐标轴的分隔,包括最小刻度和最大刻度,x轴和y轴刻度标签,表示特定坐标轴的值,绘图区域,实际绘图的区域。
2.hold属性:hold属性默认为True,允许在一幅图中绘制多个曲线;将hold属性修改为False,每一个plot都会覆盖前面的plot。但是不推荐去动hold这个属性,这种做法(会有警告)。因此使用默认设置即可。
3.网格线:grid方法,使用grid方法为图添加网格线,设置grid参数(参数与plot函数相同),.lw代表linewidth,线的粗细,.alpha表示线的明暗程度。
4.axis方法:如果axis方法没有任何参数,则返回当前坐标轴的上下限
Matplotlib与其他软件相比的优点:与MATLAB的比较:pyplot是matplotlib的一个模块,它提供了一个接口,该接口与MATLAB比较相似。 matplotlib被设计得与MATLAB比较相像,但在相像的同时又可以使用Python的功能。同时Matplotlib也是免费的。与 Gnuplot的比较gnuplot和matplotlib都是成熟的开源项目。它们都可以产生多种不同绘图类型。 虽然很难指定一种某人能做而他人不能做的图形类型,但它们仍然具有不同的优点和缺点:优点缺点Matplotlib带有内置代码的默认绘图样式与Python的深度集成Matlab风格的编程接口(对其中一部分使用者来说是优点,但是也有一部分使用者认为这是缺点)。在图形绘制的方面与Gnuplot相比也会显得更加美观但是也高度依赖其他包,如Numpy。并且只适用于Python:基本不可能在Python以外的语言中使用。 (但可以从Julia通过PyPlot软件包使用)Gnuplot跨语言解决方案:可以用作通过管道或文件以不同语言编写的应用程序(例如GNU Octave,Maxima,JavaGnuplotHybrid)中的绘图引擎。独立程序:没有外部依赖。处理大型数据集时非常快。更容易操纵绘图细节旧的默认绘图样式:通常需要小的调整以产生有吸引力的图。在开发中活跃成员的数量较少(与Matplotlib相比)。
2.7 numpy
NumPy是Python中的一款高性能科学计算与数据分析的基础包,Numpy提供了大量的库函数和操作,可以使得程序员面对复杂的数值的计算的时候变的更加的轻松,大多数使用场景是在编写机器学习的算法时,对其中的矩阵进行各种类型的数值计算。同时也经常用于数学类的任务,比如微积分、微分、外推等等。NumPy定义了矩阵和数组,提供存储单一类型的多维数租(ndarray)和矩阵(Matrix)以及相关运算,它的功能和Matlab的矩阵运算有着相似之处。NumPy在使用时通常与稀疏矩阵计算包Scipy结合在一起使用,这样使用也会更加的方便。NumPy同时也是是Python中的数学库中运算速度非常快的一个库,它非常重视数组。NumPy在使用也支持你在Python中进行向量和矩阵计算,并且由于许多底层函数实际上是用C编写的,因此你可以体验在原生Python中本来无法体会到的速度。同时NumPy还支持许多高级的数值编程工具,例如:矩阵数据类型、矢量处理,以及精密的运算库。NumPy专为进行严格的数字处理而产生。使用它的公司大多数为大型金融公司以及核心的科学计算组织如:Lawrence Livermore,NASA用其处理一些本来使用C++,Fortran或Matlab等所做的任务。NumPy 的前身为 Numeric ,最早由 Jim Hugunin 与其它协作者共同开发,2005 年,Travis Oliphant 在 Numeric 中结合了另一个同性质的程序库 Numarray 的特色,并加入了其它扩展而开发了 NumPy。NumPy 为开放源代码并且由许多协作者共同维护开发。
3 系统分析
3.1 系统可行性分析
支持向量机(support vector machine, SVM)是监督学习中占比较大的方法之一,它能够根据不同任务的数据来确定使用的分类器,这些数据就是支持向量,分类器就是机。支持向量机在解决小样本、回归预测和非线性等的问题上都有着很大的优势。本系统采用支持向量分类机,通过对每日股票的基本信息的处理和学习,对第二日股票的涨跌进行预测。
支持向量的基本思路
1、支持向量分类建模目的:基于训练集在p维空间中找到能将两类样本有效分开的分类超平面
2、分类超平面:b+ X1W1 +X2W2 + ⋯ + XnWn = 0,即: 如果参数b 和w 的估计值是合理的: 对实际属于某一类的样本观测点Xi,代入计算绝大部分的计算结果应大于0 ,对实际属于另一类的样本观测点代入计算绝大部分的计算结果应小于0 •。支持向量机规定:计算> 0的样本观测(位于超平面的一侧),输出变量 = 1;计算< 0的样本观测(位于超平面的另一侧),输出变量= −1
股票的涨跌由多种因素决定,但股票本身的历史基本数据,如果以较长的周期来总结分析,和股票未来的涨跌存在着一定的相关性,可以尝试分析股票历史数据与涨跌的关系,来对未来的股票走势做出一定程度的预测。
股票涨跌(收盘价)是典型的二分类问题,且股票的数据样本不会特别大,一般是几年的数据(几百条数据),基于支持向量机对于小样本分类的优势,因此可以使用支持向量机来对股票的涨跌进行预测。
3.1.1 技术可行性
(1)、模型训练、评估与预测。支持向量机的分类算法实现通过调用sklearn库的svm模型来实现,股票信息通过tushare库获取。具体实现为通过tushare获取10支股票的历史成交基本数据,包括当日的开盘价、最高价、最低价、成交量、成交金额、收盘价、价格变动、价格变动百分比等基本信息,以及第二天的收盘价,来进行训练并建立模型,并通过模型实现根据当日的股票基本信息,预测第二天股票收盘价涨跌的目的。
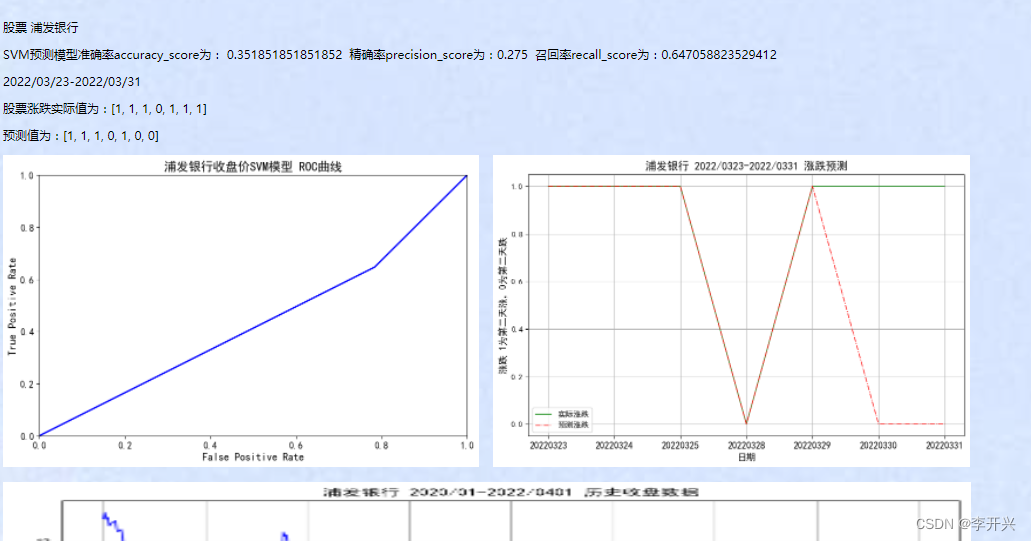
股票的基本信息包含了多个参数,需要把多个参数进行处理形成一个特征变量以导入模型进行训练。具体处理为首先进行归一化处理,即将每日每项数据减去平均值,然后除以对应的标准差,然后将归一化处理后的数据放入一个新的list即获得对应的多变量的特征变量;然后再取第二天的收盘价和第一天的收盘价之比作为目标变量,如果第二天收盘价大于等于第一天,则目标变量为1;否则为0;然后将经过处理的特征变量和目标变量传入svm的SVC分类器,模型选择线性模型,惩罚参数选择0.1(在数据量较小时,惩罚参数应取较小值)进行训练,获得训练好的模型并利用sklearn.metrics的accuracy_score,precision_score,recall_score,roc_curve对模型进行指标评估,同时根据roc_curve数据,利用matplotlib库绘制对应的roc曲线(roc曲线通过TPR(True Positive Rate),FPR(False Positive Rate)来对模型的指标进行评价)。并利用模型预测最后7天的股票涨跌,最后通过django在页面对上述输出进行展示。
(2)、可视化展示。Django是基于python开发的网络框架,能很好的承接使用python语言开发的程序的输出,并实现展示网页展示。Django的template机制,可以方便的将后台生成的数据、图片通过字典context的方式打包输送给前端,前端收到打包的数据后,根据template语法进行解析,获取对应的数据,并在网页上进行数据的输出和图片的可视化。
3.1.2 运行可行性
系统主要使用python并结合了HTML,CSS,Javascript等编程语言进行编写,以django作为框架进行网页展示,数据获取采用tushare库,svm算法实现采用sklearn svm SVC分类器,模型评估采用sklearn.metrics的accuracy_score、precision_score,,recall_score以及roc_curve。以上工作对电脑配置没有特殊要求(没有GPU要求),可在一般有cpu的电脑上进行运行和展示。
3.1.3 经济可行性
开发工具使用的Vscdoe,Dreamweaver,系统技术框架使用基于Python的Django,股票数据通过tushare库获取,SVM模型的训练和评估通过skearn库实现,以上关键工具和技术能力都可以免费获取,因此在经济上完全具有可行性。
3.2 需求分析
一些刚进入股票市场或者想进入股票市场的股民在刚进入时候没有那些老股民的经验,所以总是伴随着极大的风险。于是本系统针对那些想进入股票市场或者刚进入股票市场,对股票市场不同股票收益与风险不是很了解的股民做一个参考,使得其在购买股票时能够对其自己想买的那只股票有一个短期的预测,一定程度上降低其在股票市场的风险,起一个参考的作用。

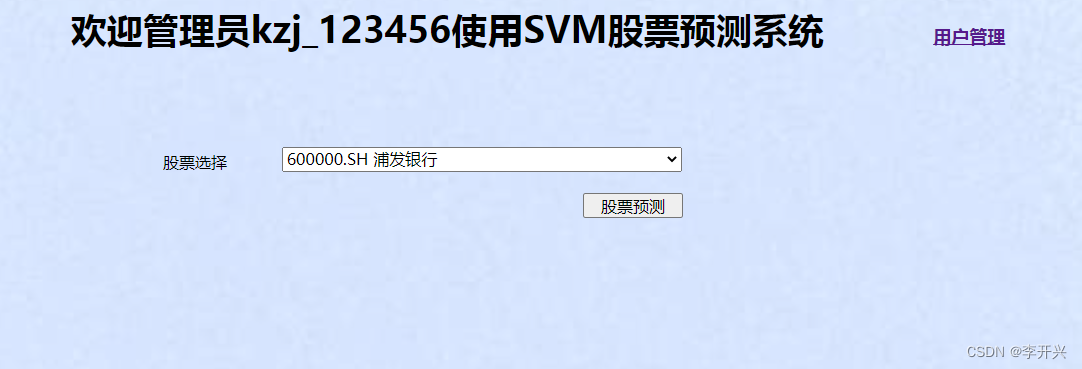
如果是管理员登录,则会看到‘用户管理’模块,如果是一般用户登录则无法看到。
进入股票预测模块后,可以在‘股票选择’下拉框,选择一支股票,点击预测,则会将选择的股票信息提交后台处理。股票的选择信息也是通过表单的post方式进行提交,(2)、后台处理。后台在收到前台提交的股票信息后,先从提交的数据中获取选择的股票信息,读取对应的股票历史数据,绘制历史数据图,同时调用对应的提前训练好的svm预测模型进行预测,然后将模型评估数据、预测结果,历史数据图等通过template机制输出到前台,通过context字典存取和传递参数,前端页面收到后台传送的数据后,进行相应的解析并展示。具体代码如下:
def stock_predict(request):
request.encoding='utf-8'
accuracy_score=0
precision_score=0
recall_score=0
context_data={}
user= request.POST['user']
context_data.setdefault('user',user)
stock_select=request.POST['select']
df=pd.read_excel('svm_stock/stock_model_train/模型评估.xlsx',header=0)
for row in range(df.shape[0]):
if str(df.loc[row,'symbol']) in stock_select:
accuracy_score=df.loc[row,'准确率']
precision_score=df.loc[row,'精确率']
recall_score=df.loc[row,'召回率']
context_data.setdefault('accuracy_score',accuracy_score)
context_data.setdefault('precision_score',precision_score)
context_data.setdefault('recall_score',recall_score)
break
df=pd.read_excel('svm_stock/stock_model_train/上交所前序号10股票列表.xlsx',header=0)
for row in range(df.shape[0]):
if str(df.loc[row,'symbol']) in stock_select:
filename=df.loc[row,'name']
context_data.setdefault('stock_name',filename)
break
df=pd.read_excel('svm_stock/stock_model_train/'+filename+'.xlsx',header=0)
df_close=df['close']
date=df['trade_date'].astype(str)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10,6),dpi=96)
x_ticks=[]
x_label=[]
for index in range(9):
x_ticks.append(int(((df.shape[0]-1)/8)*index))
x_label.append(df.loc[int(((df.shape[0]-1)/8)*index),'trade_date'])
plt.xticks(x_ticks,x_label)
plt.title(f'{filename} 2020/01-2022/0401 历史收盘数据')
plt.xlabel('日期')
plt.ylabel('单位(元)')
plt.grid()
plt.plot(date,df_close,linewidth=1,linestyle='-',color='b')
buffer = BytesIO()
plt.savefig(buffer,dpi=96,bbox_inches='tight')
plot_data = buffer.getvalue()
imb = base64.b64encode(plot_data) # 对plot_data进行编码
ims = imb.decode()
img_history = "data:image/png;base64," + ims
context_data.setdefault('img_history',img_history)
X_raw=df.iloc[-8:]#最后8天
X_raw.reset_index(inplace=True)
X_raw.drop(['index','ts_code','trade_date'],inplace=True,axis=1)#去掉 index ,ts_code,trade_date列
print(X_raw.columns)
X_raw=X_raw.astype(float)
y=[]
for row_data in range(1,X_raw.shape[0]):#保留最后8天用来进行预测
if (X_raw.loc[row_data,'close']/X_raw.loc[row_data-1,'close'])>= 1.0:#如果第二天的收盘价大于等于第一天的收盘价,则认为股票是涨的
y.append(1)
else:#否则认为股票是跌的
y.append(0)
data_mean=X_raw.mean(axis=0,skipna = True)
print(data_mean,data_mean.shape)
X_raw-=data_mean
print(X_raw)
data_std=X_raw.std(axis=0,skipna = True)
X_raw/=data_std
print(X_raw)
X_predict=[]
for row_data in range(1,X_raw.shape[0]):#保留最后8天用来进行预测
x_row=[]
for item in X_raw.columns:
x_row.append(X_raw.loc[row_data-1,item])
X_predict.append(x_row)
model_name='svm_stock/stock_model_train/'+stock_select.split('.')[0]+'.pkl'
model=joblib.load(model_name)
predict_result=model.predict(X_predict)
x_ticks=[]
x_label=[]
plt.clf()
plt.title(f'{filename} 2022/0323-2022/0331 涨跌预测',fontsize=14)
plt.xlabel('日期',fontsize=12)
plt.ylabel('涨跌 1为第二天涨,0为第二天跌',fontsize=12)
plt.grid()
for index in range(len(predict_result)):
x_ticks.append(index)#流出最后7天的数据,用于预测
x_label.append(df.loc[df.shape[0]-8+index,'trade_date'])
plt.xticks(x_ticks,x_label,fontsize=12)
plt.plot(y,linewidth=1,linestyle='-',color='g',label='实际涨跌')
plt.plot(predict_result,linewidth=1,linestyle='-.',color='r',label='预测涨跌')
plt.legend()
buffer = BytesIO()
plt.savefig(buffer,dpi=96,bbox_inches='tight')
plot_data = buffer.getvalue()
imb = base64.b64encode(plot_data) # 对plot_data进行编码
ims = imb.decode()
img_predict = "data:image/png;base64," + ims
context_data.setdefault('img_predict',img_predict)
context_data.setdefault('y',y)
context_data.setdefault('predict_result',list(predict_result))
context_data.setdefault('roc_img','svm_stock\\'+stock_select.split('.')[0]+'.png')#roc 曲线
return render(request, 'svm_stock_template/stock_predict.html',context_data)
相关文章
- Chord算法实现具体
- 【BZOJ3168】[Heoi2013]钙铁锌硒维生素 高斯消元求矩阵的逆+匈牙利算法
- 32 MAPREDUCE的map端join算法实现
- 超级实习生Ian Goodfellow留给谷歌地图的算法被完善,识别800亿街景图文字(附论文)
- 2022 年阿里高频 Java 面试题:分布式 + 中间件 + 高并发 + 算法 + 数据库............学会拿捏面试官!!!!
- 读《Simple statistical gradient-following algorithms for connectionist reinforcement learning》论文 提出Reinforce算法的论文
- 21天经典算法之冒泡排序
- 华为OD机试 -数组二叉树(Java) | 机试题+算法思路+考点+代码解析 【2023】
- 【历史上的今天】10 月 8 日:Netflix 创始人诞生;反向传播算法经典论文发表;Android 4.0 发布
- PageRank算法
- 收集到的--关于算法很好的网址
- leetcode算法28.实现strStr()