
【论文笔记】Prototypical Contrast Adaptation for Domain Adaptive Semantic Segmentation
论文

论文题目:Prototypical Contrast Adaptation for Domain Adaptive Semantic Segmentation
收录:ECCV 2022
论文地址:https://arxiv.org/abs/2207.06654
项目地址:GitHub - jiangzhengkai/ProCA
参考博客:ECCV2022-ProCA:腾讯优图提出基于原型对比的语义分割无监督域适应算法
语义分语义分割中的无监督域自适应系列-AdaptSegNet (qq.com)语义分
本次带来一篇对于ECCV2022语义分割无监督域适应算法方向上的工作的总结。先介绍下语义分割无监督域自适,再介绍这篇工作。该工作从以往方法只利用特征的类内分布进行特征对齐而忽略了类间关系的建模出发,提出了通过原型对比的方式(Prototypical Contrast Adaptation,ProCA)同时建模类内和类间分布。该方法在GTA5-Cityscapes、SYNTHINA-Cityscapes的域适应设置下取得了当前的语义分割无监督域适应的SOTA结果。
语义分割无监督域自适应(Unsupervised Domain Adaptation,UDA)简介
语义分割中域自适应是一个很有意义的研究,尤其是在遥感图像处理领域。它之所以小众,是因为想要突破现有水平达到实际可应用的程度存在很大的困难。 但是,困难也意味着这个坑还有很大的空间等着我们来填。
1)语义分割为什么需要无监督域自适应
在自然影像中,虽然近年来精度上取得了很大的进步,并且在实际应用中已经能够开始有所应用,但是这主要依赖于高质量的像素级的标注数据。然而这种标注是需要大量的人力和物力的。所以大家开始去探索怎么用更少的人力物力来得到一个与现有正常的语义分割同等的精度。之前的文章中也见过一个常见的想法,那就是弱监督语义分割。即用更容易获取的标签去完成语义分割。那么这里,又是另一个想法,用游戏中的合成数据来训练模型。在游戏中,我们基本不需要任何成本就能用电脑去获取游戏场景中的图片及其像素级标签。但是这种图片在分割上与真实场景的图片有着很大的差异(如图1),他们相当于两个域。如果直接用游戏场景(源域)训练的模型拿到真实场景(目标域)进行分割预测,性能会出现很大的下降。所以,无监督预适应的提出便是如何实现在一个域上训练的模型在另一个域上也能达到与源域的效果一致,从而使得我们可以以零成本训练分割模型。
|
源域(GTA5) |
目标域(Cityscapes) |


图1:自然影像中不同域的图片的分割对比
在遥感影像中,因为不同地区的景观不一致,不同传感器、不同天气导致成像不一致,使得不同地区甚至同一地区不同时间、传感器形成的数据集的风格存在着很大的差异(如图2)从而形成很多个域。而遥感图像是海量的,为每一个域标注像素级标签显然不现实。所以无监督域自适应的提出也可以使得在一个地区上(源域)训练的模型能够在其他地区(目标域)上使用。
|
源域(Vaihingen) |
目标域(Potsdam) |


图2:遥感影像中不同域的图片的分割对比
2)无监督域自适应的定义
定义一系列相似的风格的图像集合Xs为源域。Xs有其对应的像素级标签Ys。存在另一个风格相似的图像集合Xt,定义它为目标域。Xt不存在任何标签。无监督域自适应(UDA)就是通过Xs,Xt,Yt来训练一个模型使得模型可以仅在Ys的监督之下,也能较好的在目标域上达到相近的性能。
3)无监督的自适应的几个研究方向
以下是根据所阅读的文献对无监督自适应的方法的大致分类:
1)基于对抗学习:这一类的方法出发点在于目标域与源域在同一Encoder后编码的特征能够尽量相似。主要在FCAN与ADVENT的基础上寻求突破与创新。
2)风格迁移:这一类的方法出发点在于转换源域图片的风格使得其与目标域相似。代表方法有CycleGAN。
3)自监督学习:在目标域上形成伪标签来训练模型。
一、背景介绍
语义分割无监督域适应算法大体上分为三个方向:风格迁移、自监督、对抗训练。对抗训练的范式本质上就是在特征层面的分布对齐。最开始的时候(如Adapt-seg等论文),只注意到了对其源域与目标域之间的全局特征分布,而忽略了对其特征边缘分布的重要性,从而造成负迁移现象。为了改变这一缺陷,由CLAN等工作为代表,提出在对抗训练中引入类别信息的方案来使得对抗训练不仅能够对齐全局特征分布,还能够对齐边缘分布,最终大大的减少了负迁移现象。
本篇工作(ProCA)则认为CLAN等的范式仍然存在缺陷,那就是只注意类内特征的对齐,而忽略了类间关系的利用。而如图1所示,类间关系对于特征的对齐有着关键性的作用。
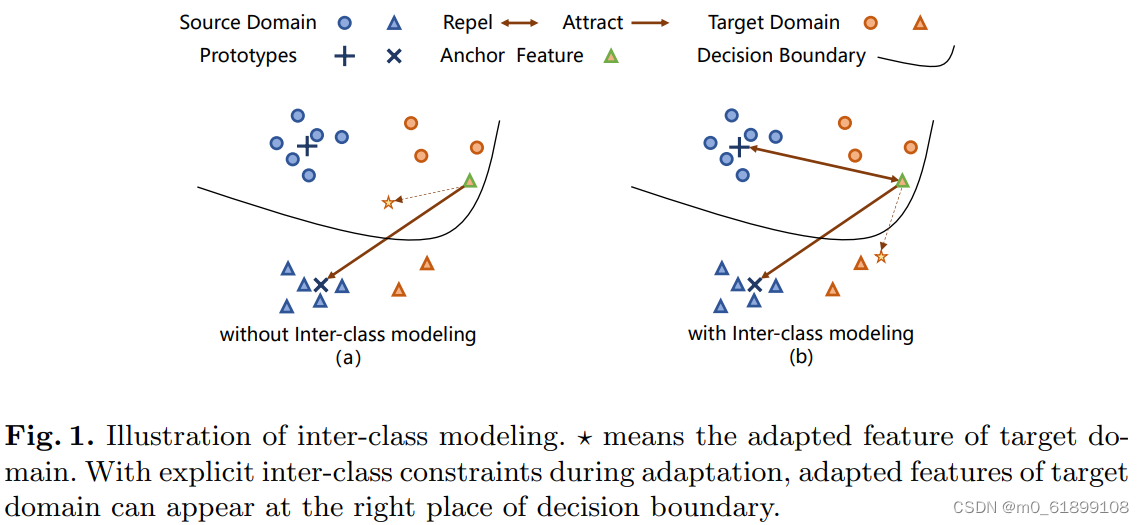
图 1: 从(a)与(b)的对比中可以看出,只有在类间特征需要拉远的推动下,需要对齐的特征才能来到它正确的位置。而仅靠图(a)中的类内关系的拉近是做不到的。
而什么方法即能使得类内特征紧凑,类间距离远离呢?答案呼之欲出是不是?没错,正是对比学习。下面来看一下ProCA是怎么利用对比学习的。
二、方法
整体的方法框架如图2所示:
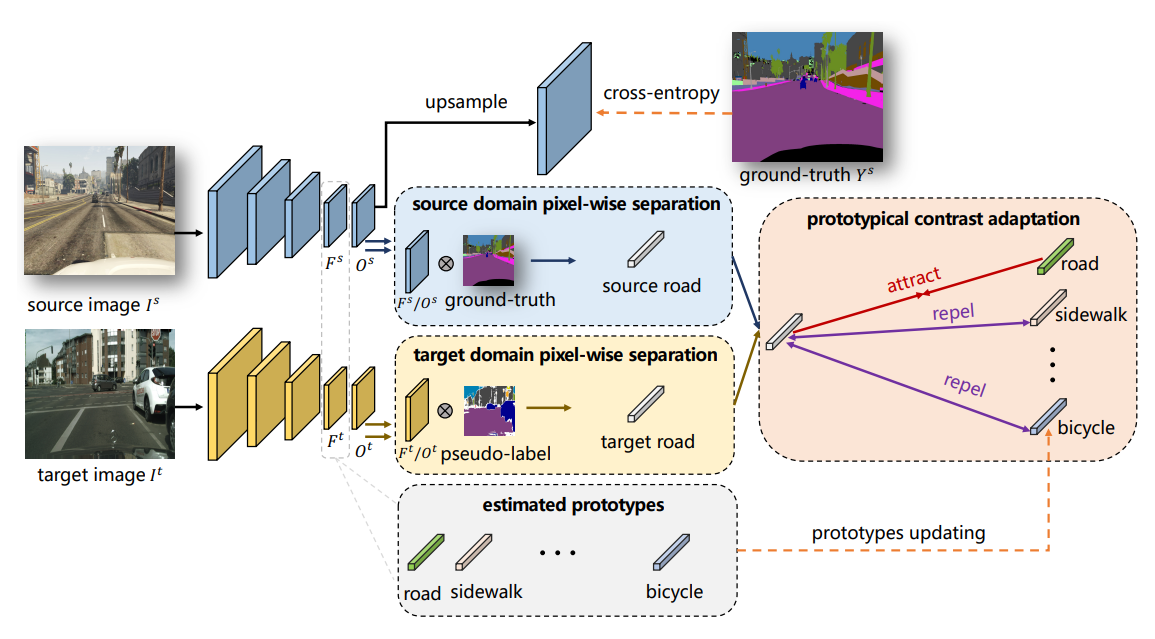

整体上ProCA分为三个阶段:
Prototypes Initialization
毫无疑问我们得先初始化每一个类别的原型。怎么初始化呢?首先用带标签的源域数据训练好一个分割模型,然后利用分割模型特征提取器提取的深度特征 F^t 和类别真值标签 Y^s 来获取每个类别的原型:求数据集图片对应 F^t 中所有属于类别c的特征的平均值作为类别 c 的原型 。
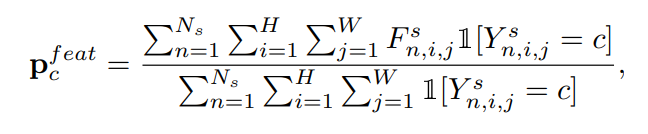
Contrast Adaptation
第二阶段为对比域适应。这一阶段,没有再延续Adapt-seg、ADVENT、CLAN等方法利用对抗学习来进行特征对齐的范式,转而使用了对比学习。可以说是一个范式上的革新,我认为也是本文最大的创新点。但是,本质上对比域适应和对抗学习域适应的思想是一致的,就是将特征放到特种空间中正确的位置。
对比域适应的目的在于使得源域和目标域中相同类别的特征相似,不同类别的特征远离,从而利用类内和类间的关系。具体来说,ProCA首先计算了分割模型提取的目标域特征的与每个类别的原型之间的相似性:
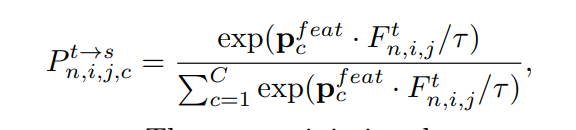
式中,i, j 表示特征在特征图上的空间位置。熟悉对比学习的应该对这个公式是比较熟悉的,含义也比较清楚,就不过多赘述。获取到相似性之后,将其与i, j 位置上分割模型获取的伪标签(伪标签的获取是有一些的技巧的,文中也使用了一些技巧,感兴趣可以自读,这里不做总结)做交叉熵损失函数:
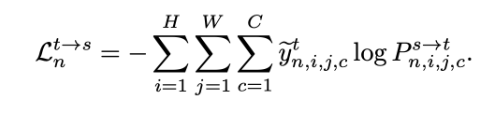
显然,想要优化该交叉熵损失函数, 就得使得i,j 位置的特征与伪标签对应的类别的原型相似,并拉远与其他类别的原型特征的距离,进而完成了特征对齐。当然,与对抗训练的思想一样,在训练的时候还得用到源域数据来完成跨域:
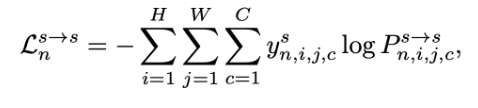
其实本质上由于原型是在不断更新的,因此,源域的特征也得不停的对齐到原型上,这样才使得最后目标域特征与源域特征分布变得一致,最终实现跨域
最终,该阶段的总体优化目标为:
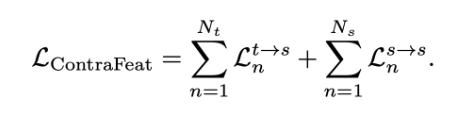
Prototypes Updating
第三阶段为原型的更新,这个阶段也很好理解,就是新的batch的数据不断的进来,然后模型也学的越来越好,所以原型也是需要不停的更新的。这一阶段比较好理解,不再做赘述。
最后,文章提到,以上阶段不仅可以在特征空间进行,还可以在标签空间中同时进行。这应该是借鉴了ADVENT的思想,是一个提升性能的技巧。
三、实验
1)GTA5-Cityscapes
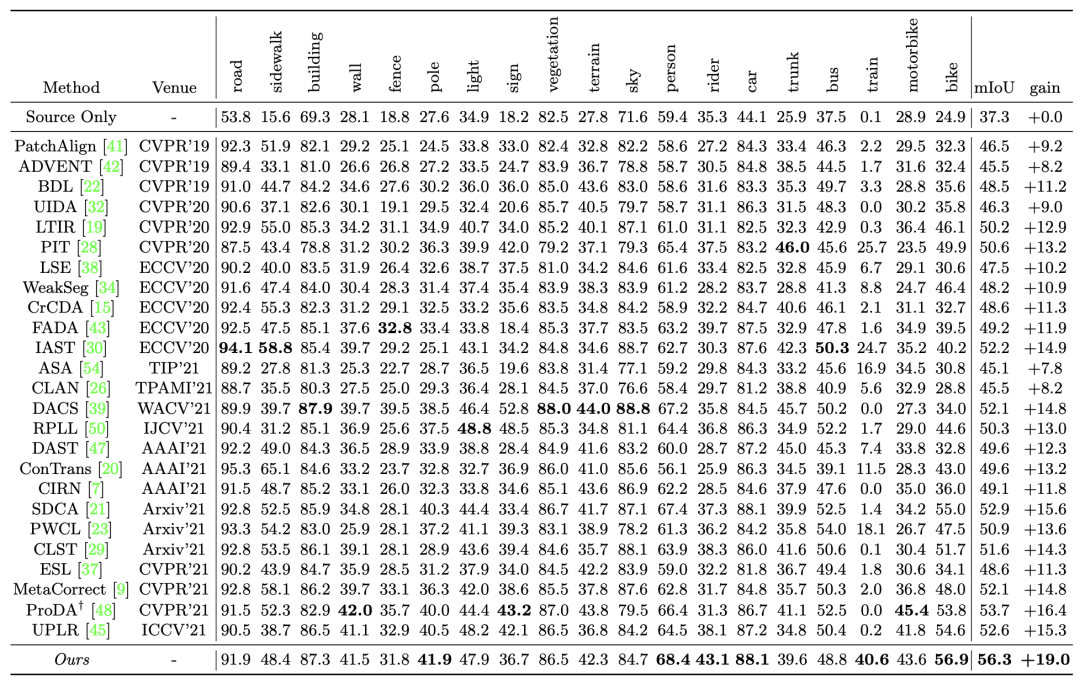
2)SYNTHINA-Cityscapes
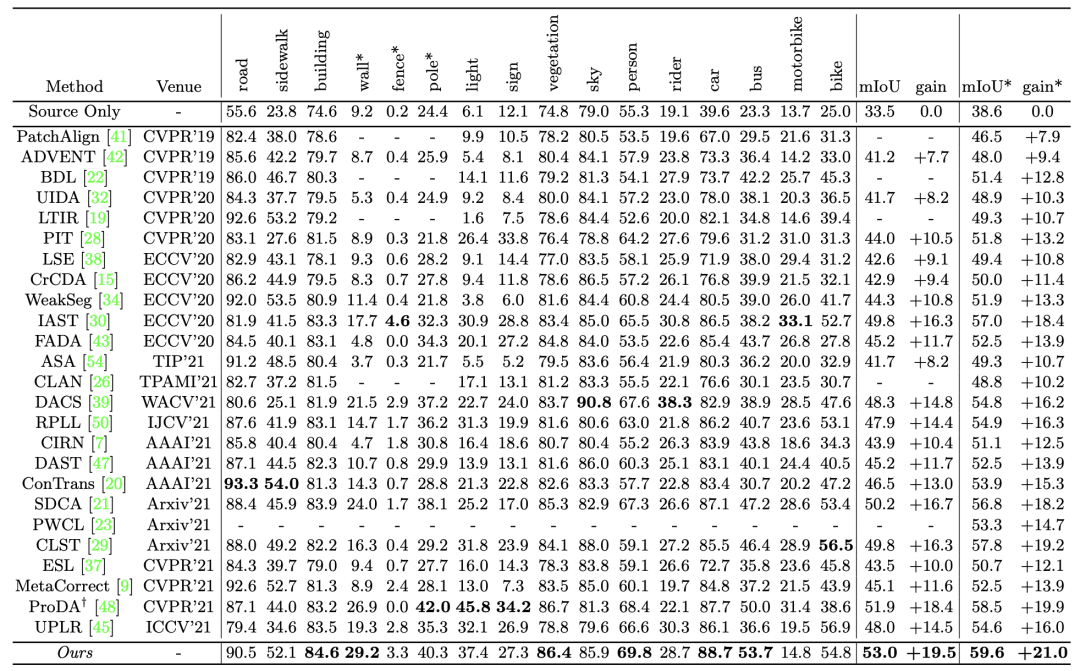
3)可视化对比
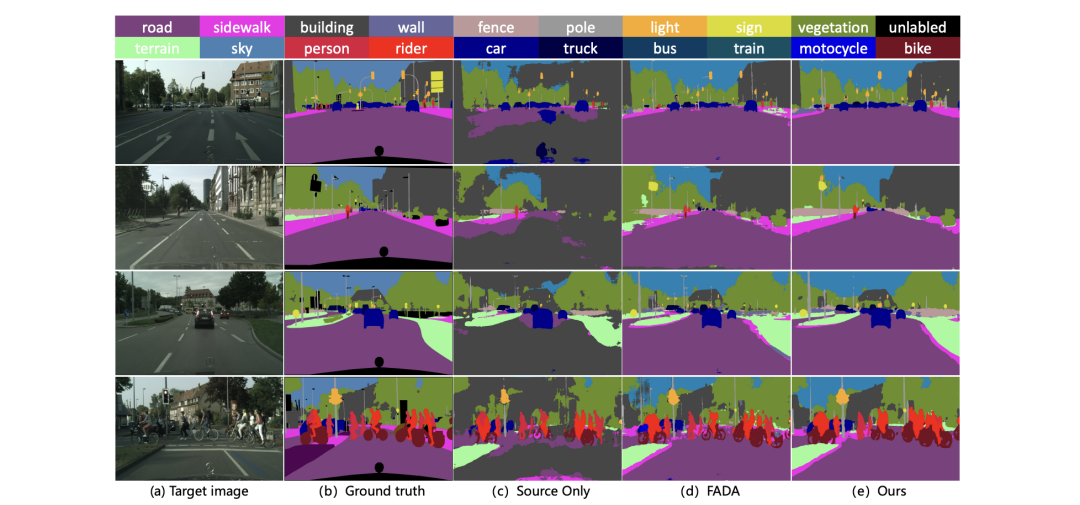
语义分割总结与展望
从语义分割的几个桎梏说起
1.1、CNN的局限性
基于CNN的结构大多都遵循编码器-解码器的框架。编码器中CNN用于特征提取,它在逐渐降低特征图分辨率的同时使得特征图富含语义信息。随后解码器中的CNN利用编码器编码特征作为输入,解码出最后的分割预测结果。
当然,这种最为基础的框架,存在很多的问题。比如语义分割任务除了语义信息还需要细节信息,因此UNet等论文给出了解决方案。比如语义分割任务需要上下文信息,因此PSPNet、Deeplab系列、基于自注意力机制的一系列方法(Non-Local、DANet、CCNet等)等被提出来获取局部、多尺度乃至全局上下文。又比如语义分割框架对于物体边缘处的分割效果不理想,因此Gated-SCNN等一些方法也在着力解决这些问题。
这些问题在以上这些方法的支撑下得到了极大的缓解。当然不是说这些点不值得研究了,学界和业界总是能有些有才之人再往前突破一点的。只不过我私以为它们都已经开始出现边际效应了。投入其中,无论对于学界还是业界可能投入与产出不一定能够达到预期的效果。
然而,除了上述的点之外,CNN的方法本质上存在着一个巨大的桎梏,就是图像初始阶段输入到网络之时,由于CNN的卷积核不会太大,所以模型只能利用局部信息理解输入图像,这难免有些一叶障目,从而影响编码器最后提取的特征的可区分性。这是只要使用CNN就逃脱不了的缺陷。当然,有人会说基于自注意力机制的一些即插即用的模块插入到编码器和解码器之间,就能获取到全局上下文,使得模型从全局的角度理解图像进而改善特征。但是,模型如果一开始因为一叶障目获取了错误的特征,在后续利用全局上下文是否能够纠正的过来是存在一个很大的疑问的。
1.2、标注数据的局限性
我们知道,语义分割任务是像素级别的分类。因此,一张512*512的图像在进行分割任务标注时,所需的标注次数理论上是图像分类任务的512*512倍。正因为如此,分割的输入获取是需要很大的资源投入的,简言之就是要烧很多的钱的。
1.3、模型的泛化能力
这不仅是分割任务上存在的问题,只要基于深度学习的任务就难免面临这么样一个窘境。我辛辛苦苦训练好了一个模型,在换了一个场景的图像输入到模型之后,模型的性能往往出现一个很大的下降。这个问题在实际中太常见了。以遥感图像语义分割为例,我在上海采集的城市数据集上训练好模型,在对来自成都的影像进行分割时,往往效果与随机预测的无异。这太尴尬了,要按传统方式解决这一问题的话,各个地区的测绘局都得采集一遍数据,然后标注好,才能无缝对国内所有城市的进行语义分割。这工作量,想想就很难。
2020-2022对于这三点给出的答案
2.1、CNN的模型不能在一开始就从全局理解输入图像的问题
对于这一点,所给出的答案最好的当然还是基于Transformer的方案,它将输入的图像Token化,然后利用自注意力机制就能在模型的一开始使得模型能够以全局的角度去理解图片。这里顺着发展脉络,给出语义分割任务上使用Transformer必须要了解的几篇文章:
1)用Transformer就不能不看VIT,他是将Transformer用于视觉任务的开山之作,主要思想可以看如下解读:
ICLR2021-谷歌大脑团队Vision Transformer:AN IMAGE IS WORTH 16X16 WORDS
2)在VIT的基础上尝试使用Transformer解决分割任务的几个方法值得一看,有针对Transformer解码器改进的、有针对Transformer编码器改进的,也有结合CNN与Transformer的。这些方法本质上仍然还是属于编码器解码器的基础框架,但是已经打破了CNN的桎梏:
语义分割中的Transformer(第一篇):SETR与TransUNet — 使用Transformer时解码器的设计
语义分割中的Transformer(第二篇):SegFormer — 简单有效的语义分割新思路
语义分割中的Transformer(第三篇):PVT — 用于密集预测任务的金字塔 Vision Transformer
3)经典之作Swin Transformer系列不可不看,就像基于编码器-解码器结构要为任务选择一个合适的编码器backnbone一样,基于Transformer结构的编码器也是需要精益求精的,而Swin Transformer显然是一个比较优秀的选项:
Swin v1https://arxiv.org/abs/2103.14030v1?ref=hackernoon.com
Swin v1中利用滑动窗口和分层结构的设计使得Swin Transformer成为了CV领域新的SOTA Backbone,在图像分类、目标检测、语义分割等多种机器视觉任务中达到了SOTA水平。
Swin v2 https://arxiv.org/abs/2111.09883
Swin v2中提出了post-norm and cosine similarity、Continuous relative position bias 和 Log-spaced coordinates来分别解决模型不够大和不能适配不同分辨率的图片和不同尺寸的窗口的问题。
当然,最近也有新的backbone在论文中report的精度超过了SWIN,感兴趣也可多看看,比如:
CVPR2022 Oral - Shunted Transformer:全新多尺度视觉 Transformer 主干网络
4)最近新出的一些用于分割的Transformer也值得一看,他们的思想源于NLP预训练中会使用CLS这个Token去表征语义,在这些方法中也用到了随机初始化去构建的Token,在学习过程中逐渐富有了想表征的语义:
Segmenter https://arxiv.org/abs/2105.05633
Segmenter 在解码阶段使用一系列与语义类别对应的可学习token,与图像自身解码的特征进行交互,从而实现最终分割预测。
还有一系列与Segmeter相同思想的文章,他们都用到了可学习token去表征他们想要表征的语义。
MaskFormer https://arxiv.org/abs/2107.06278
语义分割新范式:上海 AI Lab 联合北邮、商汤提出 StructToken
然而,诚然打破CNN桎梏的Transformer使得模型可以在一开始就从全局的角度去理解图像。但是这样是否获取到了真正的全局信息呢?答案是多数情况下是不行的。为什么?我们知道真实的图片往往是分辨率比较大的,直接输入到模型中,显卡是扛不动的,因此一张图像我们需要裁剪成多个小图才能使得送到模型中。这一裁剪,先天就使得模型只能看到完整大图中的一部分内容。因此,此时的全局角度并不是完整的全局,而只是裁剪后对于小图的全局。显然这是会影响模型的性能的。那么怎么解决呢?可以看看以下文章的解决方案:
CVPR2021-MagNet与ICCV2021-FCtl:如何提高超高分辨率图像的语义分割准确性
2.2、对于标注数据获取困难的解决方案
对于标注数据不好获取,显然结合弱监督、无监督的思想来做语义分割是比较好的解决方案。我对无监督语义分割了解的甚少,因为我认为暂时CV领域还做不到像NLP领域那样巧妙设计无监督任务的程度,因此无监督语义分割暂时应该是达不到一个能看的精度(如果这个判断有误的话,欢迎指正)。所以这里主要介绍弱监督语义分割。
首先可以先了解一下弱监督分割的简要概念与做法:
弱监督语义分割综述
弱监督语义分割系列-2、处理pascal voc2012及其增强数据集以用于弱监督语义分割
总的来说,弱监督语义分割就是使用比像素级标签更容易获取的标签,比如图像分类标签来训练分割模型。目前而言,使用图像分类标签训练的分割模型已经开始可以逐渐全监督语义分割的精度,比如:
CVPR2022-Class Re-Activation Maps:用于弱监督语义分割的类重新激活图
CVPR2022-Pixel-to-Prototype Contrast:将对比学习应用于弱监督语义分割
它们能够在PASCAL VOC2012的数据集上达到72以上的miou,可以说十分惊艳。当然除了图像分类的标签,还可以使用其他的容易获取的标签,他们的精度能够达到更高,不过相应的能够标签获取难度会上升一点,比如:
CVPR2022-Tree Energy Loss:能够扩展弱监督语义分割中稀疏真值标签的新方法
2.3、如何增强模型的泛化能力
增强模型的泛化能力其实有很多基础的方法,比如数据增强、正则化等等。但是它们起到的效果是有限的。这里我们分为两种情况来讨论如何增加模型的泛化能力:
1)测试集数据不可获取:
那此事就只能从模型本身出发,迫使模型能够学习到更为鲁棒的特征,具体这一篇文章值得一看:
CVPR2022 Oral-即插即用!感知语义的域泛化语义分割模型 (SAN & SAW)
2)测试集数据可获取(没有标签):
这显然就是无监督域适应的范围了。无监督域适应语义分割主要分为三个研究方向:
1)基于对抗学习:这一类的方法出发点在于目标域与源域在同一Encoder后编码的特征能够尽量相似。主要在FCAN与ADVENT的基础上寻求突破与创新。以下链接深入的讲了基于对抗学习的无监督域自适应语义分割的原理:
2)风格迁移:这一类的方法出发点在于转换源域图片的风格使得其与目标域相似。代表方法有CycleGAN。
3)自监督学习:在目标域上形成伪标签来训练模型。
这些方向上方向上值得一看的论文有:
ICCV2021-语义分割无监督域适应:Dual Path Learning(DPL)
CVPR2021语义分割无监督域适应:Self-supervised Augmentation Consistency(SAC)
我自己也试过一些方法效果还不错,也总结过:
相关文章
- 知网上的论文怎么下载成word格式
- 论文写作与学术规范课堂笔记01——4.30
- BEVDistill:Cross-Modal BEV Distillation for Multi-View 3D Object Detection——论文笔记
- 《NeW CRFs:Neural Window Fully-connected CRFs for Monocular Depth Estimation》论文笔记
- 《HR-Depth:High Resolution Self-Supervised Monocular Depth Estimation》论文笔记
- 《PackNet:3D Packing for Self-Supervised Monocular Depth Estimation》论文笔记
- 《CTDNet:Complementary Trilateral Decoder for Fast and Accurate Salient Object Detection》论文笔记
- 《HRNet:Deep High-Resolution Representation Learning for Human Pose Estimation》论文笔记
- 《Generalized Focal Loss V2》论文笔记
- 《Distance-IoU Loss:Faster and Better Learning for Bounding Box Regression》论文笔记
- 《FSAF:Feature Selective Anchor-Free Module for Single-Shot Object Detection》论文笔记
- 《GIoU: A Metric and A Loss for Bounding Box Regression》论文笔记
- 《IoU-Net: Acquisition of Localization Confidence for Accurate Object Detection》论文笔记
- 《SSD: Single Shot MultiBox Detector》论文笔记
- Light-Head R-CNN论文笔记
- 《Reviving Iterative Training with Mask Guidance for Interactive Segmentation》论文笔记
- 《HOP-Matting:Hierarchical Opacity Propagation for Image Matting》论文笔记
- 《Indices Matter(IndexNet):Learning to Index for Deep Image Matting》论文笔记
- 《Context Prior for Scene Segmentation》论文笔记
- 《RVOS:End-to-End Recurrent Network for Video Object Segmentation》论文笔记
- 《DeepLab v3:Rethinking Atrous Convolution for Semantic Image Segmentation》论文笔记
- 《To prune, or not to prune:exploring the efficacy of pruning for model compression》论文笔记
- 论文阅读笔记from image to imuge:immunized image generation