
《DeepLab v3:Rethinking Atrous Convolution for Semantic Image Segmentation》论文笔记
1. 概述
导读:在之前v1与v2版本中已经展示了膨胀卷积在DCNN中具有调整filter感受野与控制特征分辨率的能力。在之前的工作中使用膨胀卷积去适应不同尺度的目标,按照顺序排列或是并行排列。在这篇文章中在之前ASPP的基础上使用图像级别的特征编码全局上下文信息与特征,从而进一步提升分割网络的性能,由此得到DeePLab v3网络。该网络在没有DenseCRF后处理的前提下依然保持了与当前最好方法接近的分割性能。
2. 方法设计
2.1 Atrous Convolution for Dense Feature Extraction
在传统的DCNN网络中由于pooling和带有stride大于1的卷积使得特征的分辨率不断减小,在之前的一些研究中引入了反积来解决分辨率的问题。在这篇文章中呢,在DCNN中stride为16的地方将其后面的卷积换成了膨胀卷积,使得其可以在更大分辨率的特征图上进行特征提取。膨胀卷积的示意图见下图:

2.2 Going Deeper with Atrous Convolution
文章指出太大的网络stride对于分割是并不适合的,文章中将ResNet中从block4开始到block7的卷积全部替换为了膨胀卷积,并且使用不同的膨胀ratio来提取不同尺度的特征(文中采用的
r
a
t
i
o
=
{
2
,
4
,
8
,
16
}
ratio=\{2,4,8,16\}
ratio={2,4,8,16}),其采用的网络结构见下图所示:

2.3 Atrous Spatial Pyramid Pooling
在之前的v2版本中提出了ASPP,其在最后的卷积图上使用不同ratio的膨胀卷积来适应分割目标的不同尺寸,而在这篇文章的v3方法中引入了BN操作。
首先文章分析了随着膨胀卷积的变大其中的有效参数的变化情况,分析得到的变化曲线如下图所示:

就是说,当atrous rate在极限的情况下(等于特征图的大小),3×3的卷积退化成为了1×1的卷积(只有一个权重(中心)是有效的)
为了解决这个问题,并且将全局的上下文信息合并到模型中,在模型最后得到的特征图中采用全局平均池化,再给256个1×1的卷积(BN),然后双线性地将特征图 上采样 到所需的空间维度。最后,改善的ASPP由一个1×1的卷积,三个3×3的卷积,且rate=(6,12,18)当output_stride=16时,如下图所示:

当output_stride=8时,rate=2×(6,12,18).并行处理后的特征图在集中通过256个1×1卷积(BN),最后就是输出了,依旧是1×1卷积。
3. 实验结果
3.1 网络性能分析
首先,这里将文章提出的方法与当前主流的方法进行对比:

下面是使用搞不通stage的特征图进行分割得到的分割性能:

结论:stage越靠前其包含的信息更有利于分割。
使用不同的主干网络对分割性能的影响:
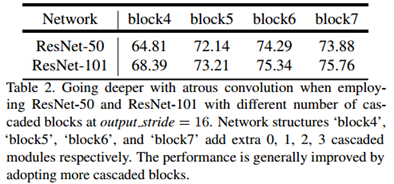
结论:更深的主干网络更好。
block4到block7之间使用的膨胀ratio对分割性能的影响:
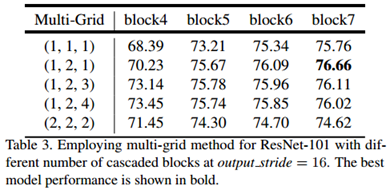
文中所谈到的模块对分割性能的影响:
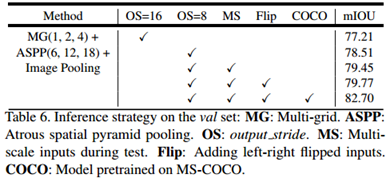
有时在复现作者的结果的时候,发现自己的结果与论文或是Git上相差比较大,就需要看看是不是按照上面的方法进行测试的:多尺度输入、图像翻转、COCO预训练模型等
3.2 训练参数分析
剪裁的尺寸、测试性能时(结果上采样还是GT下采样)、BN对分割性能的影响:
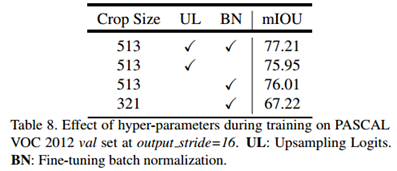
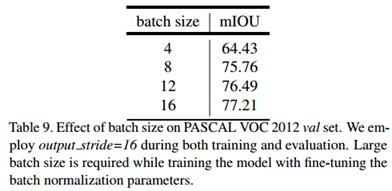
在包含BN的网络中通常BatchSize对最后的分割性能是存在影响的,显卡多显存大才是硬道理:
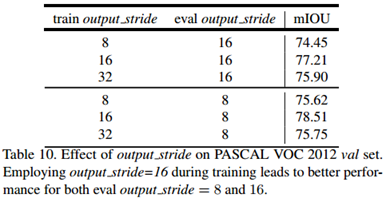
训练与测试的时候使用不同的output_stride对于分割性能的影响(训练用16测试用8能提升1个多点-_-||):
相关文章
- 论文笔记(9):Multiscale Combinatorial Grouping
- 论文笔记(7):Constrained Convolutional Neural Networks for Weakly Supervised Segmentation
- 论文笔记(5):Fully Convolutional Multi-Class Multiple Instance Learning
- 论文笔记(4):Fully Convolutional Networks for Semantic Segmentation
- 论文笔记(1):From Image-level to Pixel-level Labeling with Convolutional Networks
- 论文笔记(1):From Image-level to Pixel-level Labeling with Convolutional Networks
- 论文笔记:Support Vector Method For Novelty Detection(Schölkopf)
- 机器学习笔记 - U-Net论文解读
- 机器学习笔记 - EfficientNet论文解读
- Atitit.如何文章写好 论文 文章 如何写好论文 技术博客
- CV之IC:Image Caption图像描述算法的相关论文、设计思路、关键步骤相关配图之详细攻略
- WPS:WPS的论文使用技巧之如何自动生成参考文献(图文教程)
- 论文解读《Cross-Domain Few-Shot Graph Classification》
- 论文解读(DMVCJ)《Deep Embedded Multi-View Clustering via Jointly Learning Latent Representations and Graphs》
- 论文解读(GCC)《Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering》
- 论文解读(LG2AR)《Learning Graph Augmentations to Learn Graph Representations》
- NLP模型笔记2022-16:词向量、中文词向量的训练与中文词向量论文综述
- NLP模型笔记2022-15:深度机器学习模型原理与源码复现(lstm模型+论文+源码)
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现
- 论文投稿指南——中文核心期刊推荐(国家财政)
- 深度残差收缩网络再次理解(论文地址+代码地址+代码理解)
- 论文笔记:Adaptive event detection for Representative Load Signature Extraction
- 论文笔记:基于复合滑动窗的CUSUM暂态事件检测算法
- 论文阅读笔记2:Eyeriss