
《Imbalance Problems in Object Detection:A Review》论文笔记
1. 概述
导读:这篇文章系统性研究了目标检测任务中的不平衡问题,并且文章针对不同的不平衡问题做了深入研究(文章中将其分为了4个大类,8个小类的不平衡问题),并给出了一些统一化且关键的解决方案。并且作者使用上面的代码地址建立了一个公开的讨论组(在该仓库中包含了对应的问题以及其对应的文献,对应查找起来相当方便),一起讨论检测任务中不平衡的情况与对应的解决方案。
文章将所要探讨的不平衡问题划分为如下的4个大类,这4个大类之中又可以细分为8个子类,不平衡的分类关系见下表所示:

针对上面的这些问题,对应的解决方法主要从4个角度解决,每个角度对应的解决方法见下图所示:
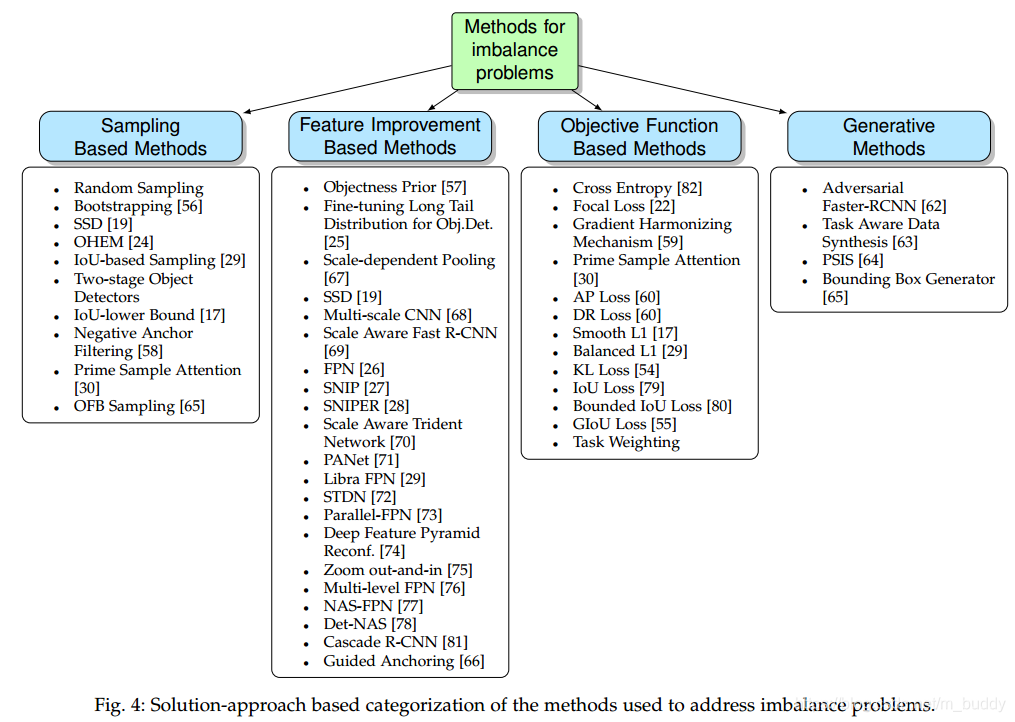
2. 类间不平衡问题
类间不平衡是出现于任务中某一类或是一些类的数量明显多于其它类的情况,这样的情况存在两种具体情形:前景背景不平衡(foreground-background imbalance)与 前景前景不平衡(foreground-foreground imbalance),下图是两种类间不平衡的统计说明:

2.1 前景背景的不平衡问题
解决类间不平衡问题的方法主要有三种:硬采样、软采样与生成方法,前面的两种方法是改变样本选择的权值
w
i
w_i
wi,其表达式为(
C
E
CE
CE为交叉熵损失):
w
i
C
E
(
p
s
)
w_iCE(p_s)
wiCE(ps)
硬采样中期权值是二值的,也就是代表这个区域是选中还是丢弃;而软采样是给每个框给出一个
w
i
∈
[
0
,
1
]
w_i\in [0,1]
wi∈[0,1]的权值。而生成方法旨在生成样本。
2.1.1 硬采样与软采样方法
硬采样与软采样方法是比较常见的对类间样本不平衡的处理方式,在现有的一些检测算法中已经成为了标配,下面是使用这两种类型方法改善类间不平衡问题的具体方法列表:

2.1.2 生成方法
生成方法与硬采样方法与软采样方法不同的是它直接产生并添加人工样本到训练数据集中。
其中一种方法就是使用GAN网络,使用依赖于生成样本分类准确度的损失来调整网络并在训练过程中生成困难样本,其中典型的方法是Adversarial-Fast-RCNN。
另一种方法是添加人工处理的图像到训练集中,作为数据集的扩展。这里使用的代表方法是Progressive and Selective Instance-Switching(PSIS)。
在人工增广数据的基础上另外一种数据增广的方式是直接使用GAN网络去生成数据,而不是通过复试粘贴样本数据,其代表方法是Task Aware Data Synthesis。
此外,还有一种方法是Bounding Box Generator,它通过给定的Bounding Box的IoU生成一系列的正样本区域。

2.2 前景类间的不平衡问题
前景类中的类间不平衡源自于训练的数据与采样的mini-batch。训练集中类别的不平衡是由于数据集自身的属性导致的,而batch上的不平衡是由于训练时采样造成的。
2.2.1 数据集中类别的不平衡问题
下图(图6.a)展示了三个数据集中每个类别的数量分布

对应的解决办法:通常情况会去添加额外的训练样本了,这个方法可以参考前景背景中不平衡的生成方法。另外一种方式是 finetuning long-tail distribution for object detection 的方法通过特征聚类的方式组合一些类别从而改善训练数据集的类间分布。
2.2.2 训练batch中的类间不平衡
训练batch中的类别不平衡会导致网络学习变得具偏向性,图6的b、c图展示了每张图的目标与类别数是存在较大区别的。

对应的有学者使用 Oline Foreground Balance (OFB) Sampling 方法来改变训练时每个gt框的采样比例,从而改变batch中的类别分布。确实这个方法针对不平衡问题较为有效,但是对于最后实际效果的提升并不明显。
3. 尺度不平衡问题
尺度上的不平衡包含两个方面:目标级别的尺度不平衡,表现出来就是不同大小的目标区域了。还有一种是特征的不平衡这是由解决目标级别不平衡引入特征金字塔进而导致的。
3.1 目标级别的不平衡问题
在下图7中展示了在COCO数据集中目标的长度宽度与面积的分布,可以可看出,其分布并不均匀,较小的目标占据了大多数。

不平衡目标的检测问题是被广泛研究的课题,一般来讲是引入诸如FPN之类的机制在不同尺度的特征图上进行预测,这里将目标级别的不平衡问题总结为如下的方法:

- 1)上图(a)是传统但尺度预测网络,如Faster RCNN;
- 2)上图(b)是在backbone的不同stage上做预测,如SSD;
- 3)上图(c)是构建FPN网络,在FPN网络的每个层上做预测,现在基本是检测网络标配了;
- 4)上图(d)是使用图像金字塔做预测,这样会消耗大量显存,可以参考SNIPer论文;
- 5)上图(e)是在预测的时候使用不同膨胀系数的卷积进行特征优化,如TridentNet;
3.2 FPN网络中的特征层不平衡问题
在FPN网络中不同的层代表了不同表达能力的特征,这些特征层之间(底层级与高层级)并没有很强的关系关联起来,这就导致了特征层之间特征表达的不同以及不平衡。其对应的解决方案包含了top-down的路径连接方法到全新的网络结构。按照网络中金字塔特征或backbone特征做为basis可以将FPN改进的方法分为两类。
3.2.1 使用金字塔特征作为基准
在这类方法中通过一些操作及步骤增强FPN的特征,这类方法见下图所示(图10的a,b):
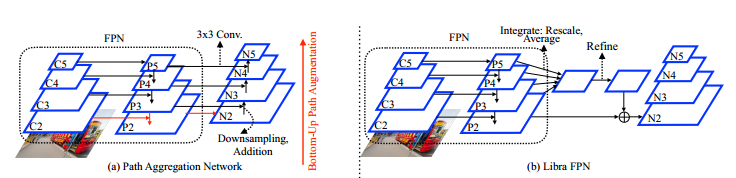
图a是PANet的网络结构,这个结构表明FPN的特征可以被进一步增强并且检测的目标可以被分配到金字塔结构的每一个层级而不是某一个固定的层级。因而这个网络对于传统FPN网络的改进体现在如下两点:
- 1)使用自下而上的方式增强了网络表达的特征,特别是显著将低层次特征中诸如轮廓的信息引入到高层次特征中;
- 2)传统FPN中会根据目标属性划分到不同的特征层级上做回归,而PANNet中是在所有的特征层级上做处理。
不同于PANet,Libra FPN采用类似残差网络的结构实现特征增强,其结构见图b所示,其中对于特征的处理主要分为两步:
- 1)Integrate:,FPN中的特征层经过缩放与平均操作得到新的特征,在这个过程中不会引入其它任何参数;
- 2)Refine:,上一步的特征经过诸如卷积的层进行增强。
3.2.2 将backbone特征作为偏置的改进方法
这一系列的FPN改进方法见下图的c到h所示:

4. 空间维度上的不平衡问题
这一部分讨论的问题主要存在于检测网络中的检测框回归函数、IoU分布不均衡以及目标位置不均衡方面上。
4.1 损失函数方面
对于检测框的位置文章首先比较了L1与L2范数的损失函数,如下图11所示:

L1范数相比L2范数对回归误差较小的时候不稳定但是对于较远的时候友好,L2范数就正好相反。那么将2者结合起来就是被广泛采用的Smooth L1损失函数了。
从梯度的角度分析离得较远的检测结果仍然会带来一些负面的影响,在Smooth L1范数的基础上有学者对其进行改进(也就是加入平衡的思想),得到下面的损失函数形式:
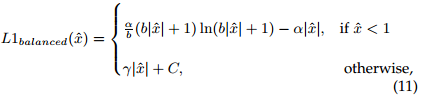
除此之外有学者从GT与检测结果分布的角度建立损失函数(将KL Loss引入)以及使用IoU(最好的损失函数既是性能评估标注本身)作为损失函数的IoU Loss与其改进GIoU Loss。
将坐标点的回归损失函数总结为如下表所示:

4.2 IoU分布的不均衡
IoU分布的不均衡既是小IoU的检测结果占了大多数,就如下图所示:

一种解决IoU分布不均衡的方法是Cascade RCNN,它是通过级联的方式不断优化IoU的分布,从而提升最后检测的结果。
4.3 目标位置的不均衡
现有基于anchor机制的检测器都是假设输入图的全图目标的权重分布时一样的,这样在全图上均衡分布anchor进行目标检测。但是在实际情况下这样的均匀采样方法是不适应的,下图是在COCO数据集中目标位置的统计分布图(目标在存在于图片中的位置并不是均匀的):

5. 分类与回归损失的不平衡
检测任务需要定位目标的位置并且需要对其分类,这就为一个网络引入了两个损失分支,而这两个损失分支并不是均衡的,见下图所示

可以看到分类的损失是高于回归的损失的,也有将两个损失相结合的方法叫作:Classification-Aware Regression Loss(CARL)
相关文章
- Apache Spark源码走读之1 -- Spark论文阅读笔记
- 论文阅读:Robots, Pancakes, and Computer Games: Designing Serious Games for Robot Imitation Learning
- [顶会论文]IROS2019机器人学习相关论文汇总
- 浏览器打开有些pdf内容不全、打开有些论文页很多红色绿色的框
- 【毕业设计_课程设计】面向高考招生咨询的问答系统设计与实现(源码+论文)
- 计算机类论文审稿意见的模板
- 【转载】 arXiv论文提交流程
- BEVDistill:Cross-Modal BEV Distillation for Multi-View 3D Object Detection——论文笔记
- STS:Surround-view Temporal Stereo for Multi-view 3D Detection——论文笔记
- 《PersFormer:3D Lane Detection via Perspective Transformer and the OpenLane Benchmark》论文笔记
- 《CREStereo:Practical Stereo Matching via Cascaded Recurrent Network with Adaptive Correlation》论文笔记
- 《PWC-Net:CNNs for Optical Flow Using Pyramid,Warping,and Cost Volume》论文笔记
- 《AdaptSegNet:Learning to Adapt Structured Output Space for Semantic Segmentation》论文笔记
- 《ENAS:Efficient Neural Architecture Search via Parameter Sharing》论文笔记
- 《DB:Real-time Scene Text Detection with Differentiable Binarization》论文笔记
- 《Grid R-CNN Plus: Faster and Better》论文笔记
- 《CRAFT:Character Region Awareness for Text Detection》论文笔记
- 《Strip Pooling:Rethinking Spatial Pooling for Scene Parsing》论文笔记
- 《Robust Multiple Object Mask Propagation with Efficient Object Tracking》论文笔记
- 《OSVOS:One-Shot Video Object Segmentation》论文笔记
- 《DeepLab v1:semantic image segmentation with deep convolutional nets and fully connected CRFs》论文笔记
- 《Distilling the Knowledge in a Neural Network》论文笔记
- 《Dynamic Network Surgery for Efficient DNNs》论文笔记
- 论文理解Deep Photo Style Transfer