
《CREStereo:Practical Stereo Matching via Cascaded Recurrent Network with Adaptive Correlation》论文笔记
参考代码:CREStereo
1. 概述
介绍:双目立体匹配在像Middlebury数据上已经取得了不错的效果,但是将训练得到的匹配模型应用到实际场景下时输出效果会出现较大退化。这是因为实际运用场景情况会更加复杂,比如纤细物体的视差估计、图像矫正不够理想、双目相机的模型一致性存在问题以及多样的困难场景。这篇文章对于实际场景中存在的问题提出了一种合成数据、真实数据联合训练的多层次迭代优化双目视差估计算法加以解决,文章的主要贡献点可以总结为如下几点:
- 网络结构上:提出AGCL(Adaptive Group Correlation Layer),首先使用channel-group局部窗口计算local feature attention,之后在视差图解码预测的不同阶段上交替使用2D和1D的kernel实现局部搜索,此外通过学习的形式感知kernel的偏移offset实现更精准地搜索匹配;
- 参考RAFT中迭代优化的策略,这里文章也采用这种coarse-to-fine的迭代优化形式。除此,还可以通过在infer阶段建立图像金字塔实现级联优化,从而得到更准确的视差估计;
- 在现有合成数据集的基础上使用Blender针对复杂场景(如纤细物体、新的视差分布、图像光照变化等)进行仿真数据合成(数据量为20w),作为现有公开数据集数据的补充;
将文章代码中的eth3d上训练得到的模型实际进行测试也展示了其较好的泛化能力。下面是文章给出的该方法的一些效果图:

2. 方法设计
2.1 网络结构
文章设计的网络在训练和测试阶段其pipeline如下图所示:
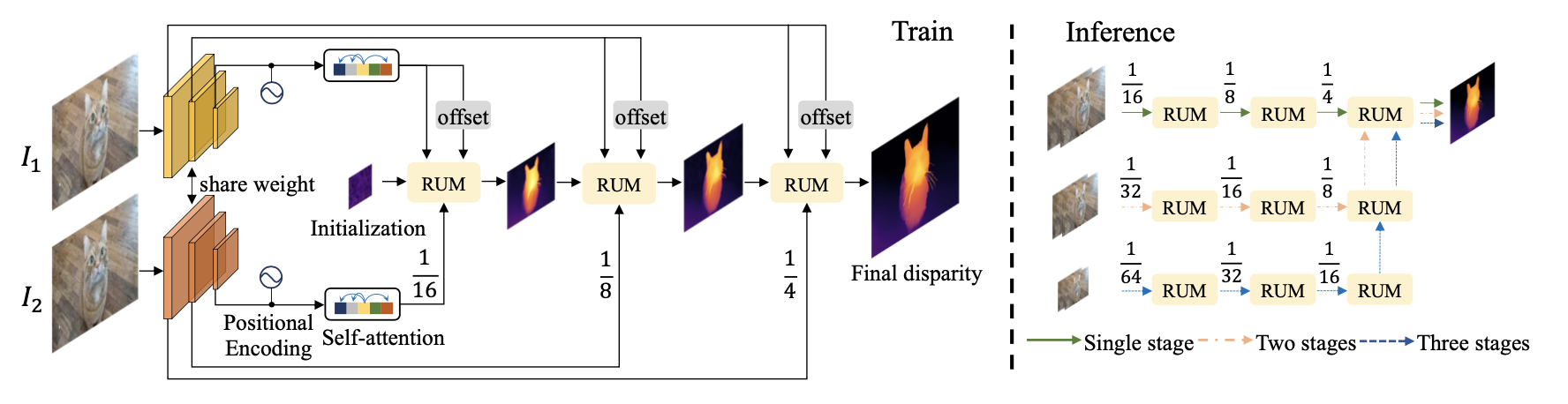
- 1)在训练中:首先通过一系列的attention和2D、1Dcorrelation操作refine特征,并级联优化输出视差估计结果,对应上图左边分别在 s t r i d e = { 1 16 , 1 8 , 1 4 } stride=\{\frac{1}{16},\frac{1}{8},\frac{1}{4}\} stride={161,81,41}处得到视差估计残差 Δ d i s p a r i t y \Delta_{disparity} Δdisparity;
- 2)在测试中:按照需求的不同会通过采样操作得到图像金字塔,然后将低分辨率的预测输出结果作为高分辨率的初始输入,从而达到级联优化的目的;
2.2 AGCL
实际场景下使用的双目系统可能会存在如极线未对齐、双目相机参数存在偏差等因素,从而导致与双目立体匹配的先验假设不符,自然导致实际运用存在限制。对此文章提出了AGCL(Adaptive Group Correlation Layer)模块去实现双目图像的特征关联。对于这个模块其结构为:
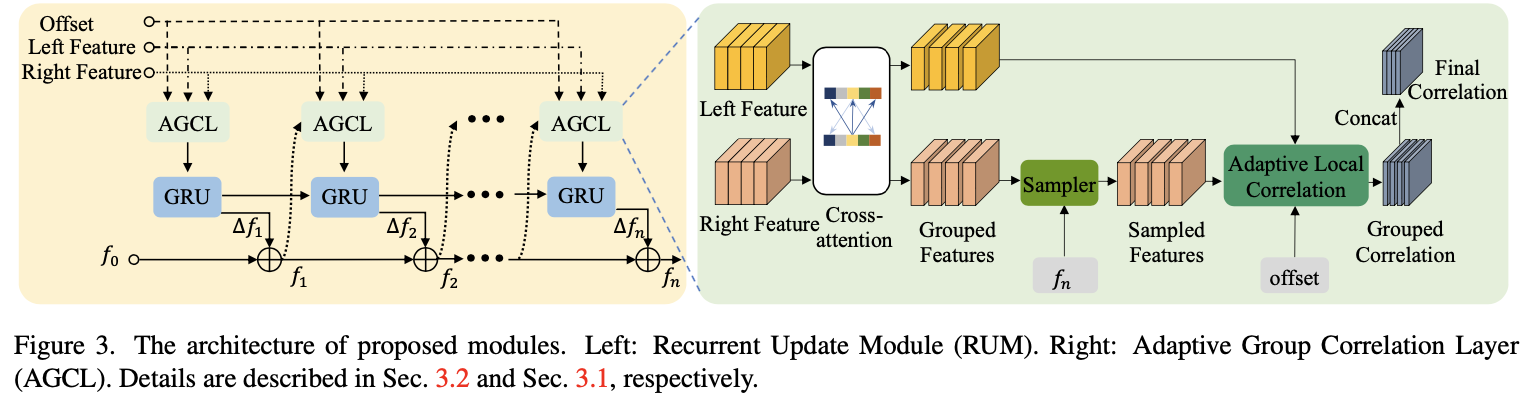
结合文章内容解码器部分主要包含这几个部分:基于channel-group局部特征attention模块(也就是文中的Local Feature Attention)、2D和1D维度的局部交替搜索模块。这里涉及到的模块多是采用分组的形式进行的,这样做的好处便是能够减少部分运算量。
channel-group局部特征attention:
这部分实现参考的是LoFTR论文中对与特征相关性的计算,并采用channel分组和位置编码的形式加速运算和优化特征表达。对于位置编码部分使用的是sin和cos进行编码,对于这部分可以参考:
# nets/attention/position_encoding.py#L6
class PositionEncodingSine(M.Module):
...
PS:这里的实现在其实是存在一些问题的,具体可以参考仓库的issue。
对于特征添加了位置编码之后便是计算特征之间相关性用于增强特征表达了,其核心代码为:
# nets/attention/linear_attention.py#L25
# [B, L, 8, 32, 1]*[B, L, 8, 1, 32]->[B,L,8,32,32]->[B,8,32,32]
KV = F.sum(F.expand_dims(K, -1) * F.expand_dims(values, 3), axis=1)
# [B, L, 8, 32]*[B, 1, 8, 32]->[B, L, 8, 32]->[B, L, 8]
Z = 1 / (F.sum(Q * F.sum(K, axis=1, keepdims=True), axis=-1) + self.eps)
queried_values = (
F.sum(
# [B,L,8,32,1]*[B, 1, 8, 32, 32]*[B, L, 8, 1, 1]->[B,L,8,32]
F.expand_dims(Q, -1) * F.expand_dims(KV, 1) * F.expand_dims(Z, (3, 4)),
axis=3,
)
* v_length
)
注意上面的维度数 8 , 32 8,32 8,32其实是输入特征被划分为了8个head,也就是在channel上8等分, L = H ∗ W L=H*W L=H∗W是特征图的spatial维度上的元素数量。
2D和1D维度的局部交替搜索:
这部分是使用预先定义好的kernel和dilation参数交替(按照迭代优化的奇偶次数)进行局部搜索,其参数被设置为:
# nets/corr.py#L58
if small_patch:
psize_list = [(3, 3), (3, 3), (3, 3), (3, 3)]
dilate_list = [(1, 1), (1, 1), (1, 1), (1, 1)]
else:
psize_list = [(1, 9), (1, 9), (1, 9), (1, 9)]
dilate_list = [(1, 1), (1, 1), (1, 1), (1, 1)]
注意到上面的kernel size和dilate size是4对,其实就是与文章中说到的channel分组。
通过上述kernel size和dilate size便在特征图上进行局部特征匹配(2D和1D均可用下面的表达式进行描述,区别在于kernel的形状不一样):
C
o
r
r
(
x
,
y
,
d
)
=
1
C
∑
i
=
1
C
F
1
(
i
,
x
,
y
)
F
2
(
i
,
x
′
,
y
′
)
Corr(x,y,d)=\frac{1}{C}\sum_{i=1}^CF_1(i,x,y)F_2(i,x^{'},y^{'})
Corr(x,y,d)=C1i=1∑CF1(i,x,y)F2(i,x′,y′)
其中,
x
′
=
x
+
f
(
d
)
,
y
′
=
y
+
g
(
d
)
x^{'}=x+f(d),y^{'}=y+g(d)
x′=x+f(d),y′=y+g(d)代表的是在
(
x
,
y
)
(x,y)
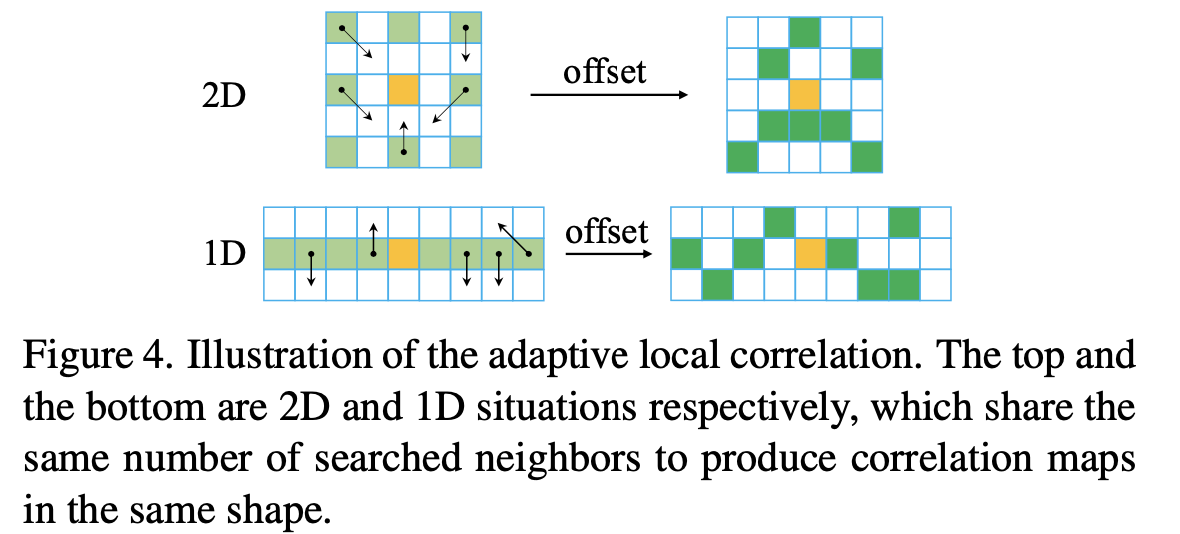
(x,y)处的局部搜索偏移量,其与kernel的设置相关。除了上述中使用预先设定好的kernel和dilate参数进行局部搜索之外,文章还提供了网络自学习局部偏移能力,也就是在上述局部搜索的前提下对每个像素设定一个偏移量,使得能够更好完成局部匹配,而不仅仅使用预先设定好的参数进行计算,具有一定的自主感知能力。其实现是通过卷积的形式(之后会经过sigmoid激活),可以参考:
# nets/crestereo.py#L40
# adaptive search
self.search_num = 9
self.conv_offset_16 = M.Conv2d(
256, self.search_num * 2, kernel_size=3, stride=1, padding=1
)
self.conv_offset_8 = M.Conv2d(
256, self.search_num * 2, kernel_size=3, stride=1, padding=1
)
因而计算局部相关性的时候原来的偏移量就变为了:
x
′
′
=
x
+
f
(
d
)
+
d
x
,
y
′
′
=
y
+
g
(
d
)
+
d
y
x^{''}=x+f(d)+d_x,y^{''}=y+g(d)+d_y
x′′=x+f(d)+dx,y′′=y+g(d)+dy。也就是下图展示的情况:
2.3 损失函数
这里损失函数的设计与RAFT的形式一致,如下:
L
=
∑
s
∑
i
=
1
n
γ
n
−
i
∣
∣
d
g
t
−
μ
s
(
f
i
s
)
∣
∣
1
L=\sum_s\sum_{i=1}^n\gamma^{n-i}||d_{gt}-\mu_s(f_i^s)||_1
L=s∑i=1∑nγn−i∣∣dgt−μs(fis)∣∣1
2.4 合成数据集
文章对现有的视差公开数据集进行分析之后,使用Blender在场景中物体形状、光照变化、视差分布等维度进行重新设计与采样,用以对现有公开数据的补充。其效果见下图 :

3. 实验结果
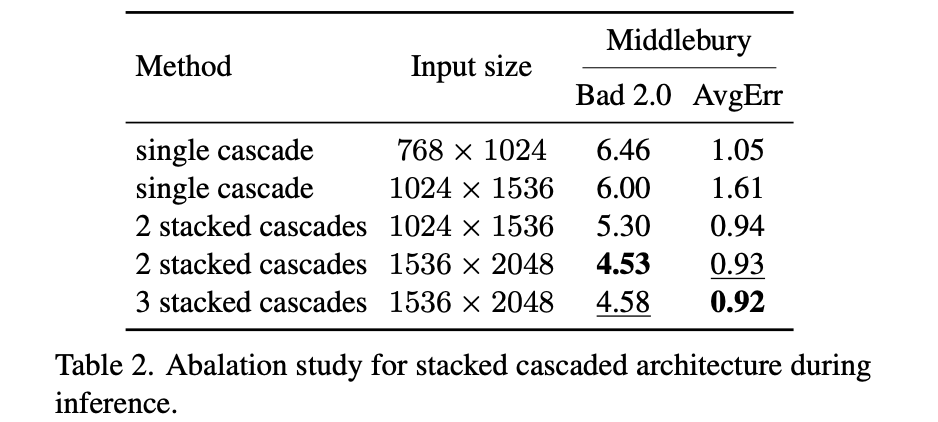
文章提出的多阶段(图像金字塔)推理对性能的影响:
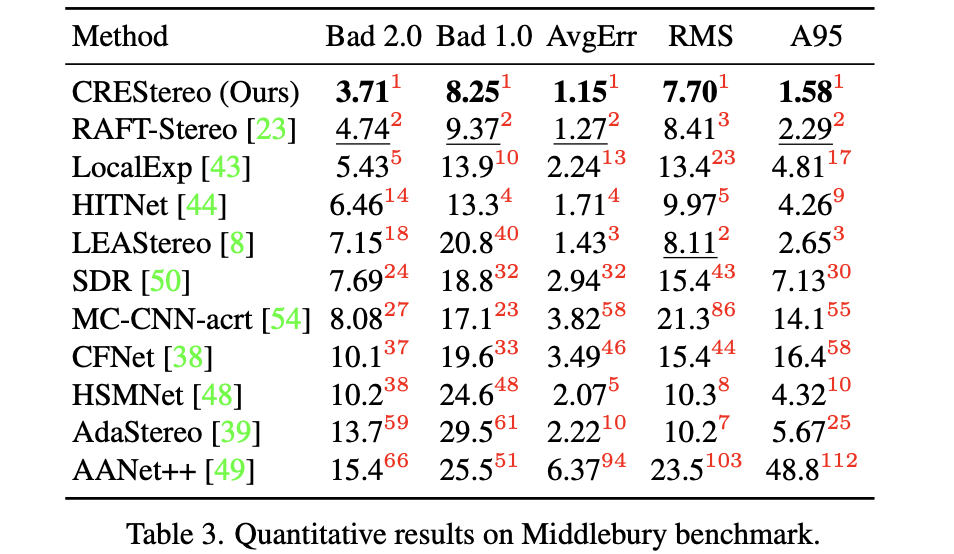
Middlebury上的性能比较:
相关文章
- Online Object Tracking: A Benchmark 论文笔记(转)
- 论文笔记(8):BING: Binarized Normed Gradients for Objectness Estimation at 300fps
- 论文笔记(5):Fully Convolutional Multi-Class Multiple Instance Learning
- 论文笔记(4):Fully Convolutional Networks for Semantic Segmentation
- 论文笔记(5):Fully Convolutional Multi-Class Multiple Instance Learning
- 机器学习笔记 - CRAFT(文本检测的字符区域感知)论文解读
- Paper之ICML:2009年~2019年ICML历年最佳论文简介及其解读—(International Conference on Machine Learning,国际机器学习大会)
- DL之InceptionV4/ResNet:InceptionV4/Inception-ResNet算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略
- DL之DenseNet:DenseNet算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略
- 论文阅读丨神经清洁: 神经网络中的后门攻击识别与缓解
- AI论文解读丨融合视觉、语义、关系多模态信息的文档版面分析架构VSR
- NLP模型笔记2022-16:词向量、中文词向量的训练与中文词向量论文综述
- NLP模型笔记2022-12:Deep Biaffine Attention for Neural Dependency Parsing【论文+源码】
- NASNet学习笔记—— 核心一:延续NAS论文的核心机制使得能够自动产生网络结构; 核心二:采用resnet和Inception重复使用block结构思想; 核心三:利用迁移学习将生成的网络迁移到大数据集上提出一个new search space。
- 【讲座笔记】科研论文的构思、规划和写作--中南大帅词俊
- 论文投稿指南——中文核心期刊推荐(会计、审计)
- 论文投稿指南——中文核心期刊推荐(园艺)
- 论文笔记系列:轻量级网络(一)-- RepVGG
- 2021计算机视觉-包揽所有前沿论文源码 -上半年
- 《论文阅读》Autoregressive Entity Generation for End-to-End Task-Oriented Dialog
- 论文笔记:基于复合滑动窗的CUSUM暂态事件检测算法
- 论文笔记:Bayesian Online Changepoint Detection
- NILM论文笔记:R.Reddy, et al: A feature fusion technique for improved NILM
- 论文阅读笔记5-An Asynchronous Energy-Efficient CNN Accelerator with Reconfigurable Architecture