
《Robust Multiple Object Mask Propagation with Efficient Object Tracking》论文笔记
参考代码:暂无
1. 概述
导读:交互的视频目标分割拥有两个比较核心的操作:交互式的图像目标分割(将用户给的交互信息【方框、点击等,与文中tracker对应】与RGB图像、前一帧分割结果【可选】送入CNN模型)与视频目标mask的传导(与DeepLab v3+分割网络对应)。这篇文章将这两个步骤看成是相互独立的部分,主要的工作重点在后一个步骤中,文章引入目标跟踪为目标提供一个RoI区域,这样可以极大提升mask传导的稳定性,之后所有目标区域mask传导的结果会进行整合以解决分割过程中的重叠问题。这篇文章的方法不需要任何预先计算好的特征,其在Davis 2017验证集上取得了AUC 0.766与J&F@60s 0.78的性能。
2. 方法设计
在这篇文章的分割方法中存在两个不同的交互式图像目标分割模块:初始帧的目标分割与后序帧的交互分割。这两个模块都是基于DeepLab v3+的,在前一个模块中将用户输入的交互信息作为引导图,因而输入的数据就是:RGB图+引导图;后一个模块的输入还额外增加了前一帧的分割结果。这篇文章主要着力于视频目标的分割,其结构见下图所示:

这篇文章中mask传导步骤可以划分为3步:单目标跟踪、但目标mask传导(分割)、多目标分割。
2.1 单目标跟踪
文章中选用的是ATOM的跟踪器,它为每个目标提供当前帧中的目标区域,从而在此基础上计算ROI。
ATOM跟踪网络由两个子任务组成:目标预估与分类,目标预估是离线进行训练的,他会预估检测框与目标的Jaccard Index(IoU overlap)。目标分类是在线学习的,去预测对于类别的置信度。这里使用的Backbone是ResNet-18,运算速度是30FPS。
2.2 单目标mask分割
这里对于mask的提取是通过backbone为xception_65的DeepLab v3+实现的,这一步就是在上一步tracking的基础上使用其得到的边界框结果,经过扩大之后得到ROI再将RGB对应的区域与前一帧对应区域抠出,组合成为4通道的分割输入数据,之后resize到 513 ∗ 513 513*513 513∗513进行分割。因而跟踪给分割带来鲁棒性的同时,分割也是很依赖于tracking性能的。
2.3 多目标分割
在前面的内容里面已经将每个单独的目标分割出来了,那么这一步就是将这些单独的分割目标进行整合,解决目标重叠的问题。
对于前面两步网络产生的分割结果为
P
i
P_i
Pi(为第
i
i
i个目标的前景与背景类的概率),则这里就是对于这个概率矩阵进行归一化得到
P
i
′
(
x
,
k
)
,
k
∈
{
0
,
1
}
P_i^{'}(x,k),k\in\{0,1\}
Pi′(x,k),k∈{0,1}:
P
i
′
(
x
,
k
)
=
e
p
i
(
x
,
k
)
e
p
i
(
x
,
0
)
P_i^{'}(x,k)=\frac{e^{p_i^{(x,k)}}}{e^{p_i^{(x,0)}}}
Pi′(x,k)=epi(x,0)epi(x,k)
经过上式背景类的都被归一化为1,之后就是将归一化之后的概率矩阵进行整合了,下面是其运算公式:
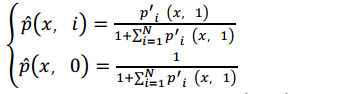
其中,
N
N
N是目标的数目,经过上面的计算之后,对于最后的结果就是在对应位置上对不同类别取argmax了。
2.4 数据增广
文章为了提升分割网络的鲁棒性还提出了两种数据增广的方式:
- 1)使用affine变换得到边形之后的mask;
- 2)为mask添加随机的噪声;
3. 实验结果
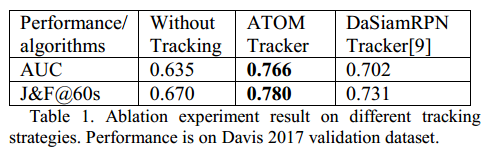
相关文章
- Online Object Tracking: A Benchmark 论文笔记(转)
- Google大数据三篇著名论文中文版
- 论文笔记(2):Deep Crisp Boundaries: From Boundaries to Higher-level Tasks
- 论文笔记(9):Multiscale Combinatorial Grouping
- 论文笔记(4):Fully Convolutional Networks for Semantic Segmentation
- 投稿指南【NO.7】目标检测论文写作模板(初稿)
- 谷歌Borg论文阅读笔记(一)——分布式架构
- 谷歌Borg论文阅读笔记(二)——任务混部的解决
- DL之DenseNet:DenseNet算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略
- 跟我读论文丨ACL2021 NER 模块化交互网络用于命名实体识别
- 论文阅读丨神经清洁: 神经网络中的后门攻击识别与缓解
- AI论文解读:基于Transformer的多目标跟踪方法TrackFormer
- 计算机毕设 SSM Vue的驾校预约管理系统(含源码+论文)
- 论文解读(JKnet)《Representation Learning on Graphs with Jumping Knowledge Networks》
- 论文解读《Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning》
- 论文解读(Cluster-GCN)《Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks》
- NLP模型笔记2022-18:GCN/GNN模型在nlp中的使用【论文+源码】
- NLP模型笔记2022-07:一种联合中文分词和依存分析的统一模型训练CTB5数据集【论文复现+源码+数据集下载】
- 论文投稿指南——中国(中文EI)期刊推荐(第5期)
- 论文笔记系列:经典主干网络(二)-- ResNet
- 《论文阅读》开放域对话系统——外部信息融入对话的方法
- 【第十届“泰迪杯”数据挖掘挑战赛】C题:疫情背景下的周边游需求图谱分析 赛后总结、46页论文及代码
- 美团外卖——物流论文小笔记(Python实现)
- 论文笔记:A Low-Complexity I/Q Imbalance compensation Algorithm
- 论文阅读:Faster AutoAugment: Learning Augmentation Strategies using Backpropagation
- 论文阅读笔记5-An Asynchronous Energy-Efficient CNN Accelerator with Reconfigurable Architecture