
大数据时代-航空公司该如何转型(三)
还未阅读前两篇的小可爱,链接在这里哦👇
大数据时代-航空公司该如何转型(一)![]() https://blog.csdn.net/tipdm0526/article/details/124985456?spm=1001.2014.3001.5501
https://blog.csdn.net/tipdm0526/article/details/124985456?spm=1001.2014.3001.5501
大数据时代-航空公司该如何转型(二)![]() https://blog.csdn.net/tipdm0526/article/details/125006987?spm=1001.2014.3001.5501
https://blog.csdn.net/tipdm0526/article/details/125006987?spm=1001.2014.3001.5501
下面进入第三篇正文
数据预处理
本案例主要采用数据清洗、属性规约与数据变换的预处理方法。
1. 数据清洗
通过对数据观察发现原始数据中存在票价为空值,票价最小值为0、折扣率最小值为0、总飞行公里数大于0的记录。票价为空值的数据可能是客户不存在乘机记录造成。其他的数据可能是客户乘坐0折机票或者积分兑换造成。由于原始数据量大,这类数据所占比例较小,对于问题影响不大,因此对其进行丢弃处理。同时,数据探索时发现部分年龄大于100记录,也进行丢弃处理,具体处理方法如下。
(1) 丢弃票价为空的记录。
(2) 保留票价不为0的,或者平均折扣率不为0且总飞行公里数大于0的记录。
(3) 丢弃年龄大于100的记录。
使用pandas对满足清洗条件的数据进行丢弃,处理方法为满足清洗条件的一行数据全部丢弃,如代码清单1所示。
代码清单1 清洗空值与异常值
| import numpy as np import pandas as pd
datafile = '../data/air_data.csv' # 原始数据路径 cleanedfile = '../tmp/data_cleaned.csv' # 数据清洗后保存的文件路径
# 读取数据 airline_data = pd.read_csv(datafile,encoding = 'utf-8') print('原始数据的形状为:',airline_data.shape)
# 去除票价为空的记录 airline_notnull = airline_data.loc[airline_data['SUM_YR_1'].notnull() & airline_data['SUM_YR_2'].notnull(),:] print('删除缺失记录后数据的形状为:',airline_notnull.shape)
# 只保留票价非零的,或者平均折扣率不为0且总飞行公里数大于0的记录。 index1 = airline_notnull['SUM_YR_1'] != 0 index2 = airline_notnull['SUM_YR_2'] != 0 index3 = (airline_notnull['SEG_KM_SUM']> 0) & (airline_notnull['avg_discount'] != 0) index4 = airline_notnull['AGE'] > 100 # 去除年龄大于100的记录 airline = airline_notnull[(index1 | index2) & index3 & ~index4] print('数据清洗后数据的形状为:',airline.shape)
airline.to_csv(cleanedfile) # 保存清洗后的数据 |
*代码详见:demo/code/data_clean.py。
2. 属性规约
本案例的目标是客户价值分析,即通过航空公司客户数据识别不同价值的客户,识别客户价值应用最广泛的模型是RFM模型。
(1) RFM模型
①R(Recency)
R(Recency)指的是最近一次消费时间与截止时间的间隔。通常情况下,最近一次消费时间与截止时间的间隔越短,对即时提供的商品或是服务也最有可能感兴趣。这也是为什么,消费时间间隔0至6个月的顾客收到的沟通信息多于1年以上的顾客。
最近一次消费时间与截止时间的间隔不仅能够为确定促销客户群体提供依据,还能够从中得出企业发展的趋势。如果分析报告显示最近一次消费时间很近的客户在增加,则表示该公司是个稳步上升的公司。反之,最近一次消费时间很近的客户越来越少,则说明该公司需要找到问题所在,及时调整营销策略。
②F(Frequency)
F(Frequency)指顾客在某段时间内所消费的次数。可以说消费频率越高的顾客,也是满意度越高的顾客,其忠诚度也就越高,顾客价值也就越大。增加顾客购买的次数意味着从竞争对手处偷取市场占有率,赚取营业额。商家需要做的,是通过各种营销方式,去不断的刺激顾客消费,提高他们的消费频率,提升店铺的复购率。
③M(Monetary)
M(Monetary)指顾客在某段时间内所消费的金额。消费金额越大的顾客,他们的消费能力自然也就越大,这就是所谓“20%的顾客贡献了80%的销售额”的二八法则。而这批顾客也必然是商家在进行营销活动时需要特别照顾的群体,尤其是在商家前期资源不足的时候。不过需要注意一点,不论采用哪种营销方式,以不对顾客造成骚扰为大前提,否则营销只会产生负面效果。
在RFM模型理论中,最近一次消费时间与截止时间的间隔,消费频率,消费金额是测算客户价值最重要的特征,这三个特征对营销活动的具有十分重要的意义。其中,近一次消费时间与截止时间的间隔是最有力的特征。
(2) RFM模型结果解读
RFM模型包括3个特征,无法用平面坐标系来展示,所以这里使用三维坐标系进行展示,如图1所示,x轴表示R特征(Recency),y轴表示F特征(Frequency),z轴表示M指标(Monetary)。每个轴一般会用5级表示程度,1为最小,5为最大。需要特别说明的是R特征。在x轴上,R值越大,代表该类客户最近一次消费与截止时间的消费间隔越短,客户R维度上的质量越好。在每个轴上划分5等级,等同于将客户划分成5´5´5=125种类型。这里划分为5级并不是严格的要求,一般是根据实际研究需求和顾客的总量进行划分的,对于是否等分的问题取决于该维度上客户的分布规律。
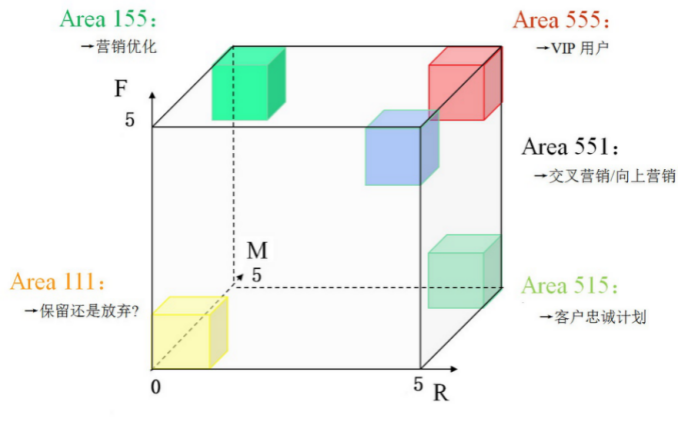
图1 RFM客户价值模型
图 1中,左上角方框的客户RFM特征取值为155。R值是比较小的,说明该类客户最近都没有来店消费,原因可能是最近比较忙,或者对现有的产品或服务不满意,或者是找到了更好的商家。R特征数值变小需要企业管理人员引起重视,说明该类客户可能流失,对企业造成损失。消费频率F很高,说明客户很活跃,经常到商家店里消费。消费金额M值很高,说明该类客户具备一定的消费能力,为店里贡献了很多的营业额。这类客户总体分析比较优质,但是R特征时间近度值较小,其往往是需要营销优化的客户群体。
同理,若客户RFM特征取值为555。则可以判定该客户为最优质客户,即该类客户最近到商家消费过,消费频率很高,消费金额很大。该类客户往往是企业利益的主要贡献者,需要重点关注与维护。
(3) 航空客户价值分析的LRFMC模型
在RFM模型中,消费金额表示在一段时间内,客户购买该企业产品金额的总和。由于航空票价受到运输距离,舱位等级等多种因素影响,同样消费金额的不同旅客对航空公司的价值是不同的,比如一位购买长航线,低等级舱位票的旅客与一位购买短航线,高等级舱位票的旅客相比,后者对于航空公司而言价值可能更高。因此这个特征并不适合用于航空公司的客户价值分析⑮。本案例选择客户在一定时间内累积的飞行里程M和客户在一定时间内乘坐舱位所对应的折扣系数的平均值C两个特征代替消费金额。此外,航空公司会员入会时间的长短在一定程度上能够影响客户价值,所以在模型中增加客户关系长度L,作为区分客户的另一特征。
本案例将客户关系长度L,消费时间间隔R,消费频率F,飞行里程M和折扣系数的平均值C五个特征作为航空公司识别客户价值特征(如表1所示),记为LRFMC模型。
表1 特征含义
| 模型 | L | R | F | M | C |
| 航空公司LRFMC模型 | 会员入会时间距观测窗口结束的月数 | 客户最近一次乘坐公司飞机距观测窗口结束的月数 | 客户在观测窗口内乘坐公司飞机的次数 | 客户在观测窗口内累计的飞行里程 | 客户在观测窗口内乘坐舱位所对应的折扣系数的平均值 |
原始数据中属性太多,根据航空公司客户价值LRFMC模型,选择与LRFMC指标相关的六个属性:FFP_DATE、LOAD_TIME、FLIGHT_COUNT、AVG_DISCOUNT、SEG_KM_SUM、LAST_TO_END。删除与其不相关、弱相关或冗余的属性,例如:会员卡号、性别、工作地城市、工作地所在省份、工作地所在国家、年龄等属性。属性选择的代码如代码清单2所示。
代码清单2 属性选择
| import pandas as pd import numpy as np
# 读取数据清洗后的数据 cleanedfile = '../tmp/data_cleaned.csv' # 数据清洗后保存的文件路径 airline = pd.read_csv(cleanedfile, encoding='utf-8') # 选取需求属性 airline_selection = airline[['FFP_DATE','LOAD_TIME','LAST_TO_END', 'FLIGHT_COUNT','SEG_KM_SUM','avg_discount']] print('筛选的属性前5行为:\n',airline_selection.head()) |
*代码详见:demo/code/zscore_data.py。
通过代码清单2得到的数据集,如表2所示。
表2 属性选择后的数据集
| FFP_DATE | LOAD_TIME | LAST_ TO_END | FLIGHT_ COUNT | SEG_ KM_SUM | avg_discount |
| 2006/11/2 | 2014/3/31 | 1 | 210 | 580717 | 0.961639 |
| 2007/2/19 | 2014/3/31 | 7 | 140 | 293678 | 1.252314 |
| 2007/2/1 | 2014/3/31 | 11 | 135 | 283712 | 1.254676 |
| 2008/8/22 | 2014/3/31 | 97 | 23 | 281336 | 1.090870 |
| 2009/4/10 | 2014/3/31 | 5 | 152 | 309928 | 0.970658 |
| … | … | … | … | … | … |
3. 数据变换
数据变换是将数据转换成“适当的”格式,以适应挖掘任务及算法的需要。本案例中主要采用的数据变换方式有属性构造和数据标准化。
由于原始数据中并没有直接给出LRFMC五个指标,需要通过原始数据提取这五个指标。
1) 会员入会时间距观测窗口结束的月数L=会员入会时长,如式(1)所示。

(1)
2) 客户最近一次乘坐公司飞机距观测窗口结束的月数R=最后一次乘机时间至观察窗口末端时长(单位:月),如式(2)所示。

(2)
3) 客户在观测窗口内乘坐公司飞机的次数F=观测窗口的飞行次数(单位:次),如式(3)所示。
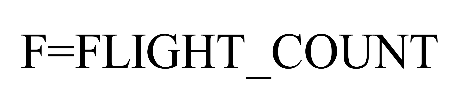
(3)
4) 客户在观测时间内在公司累计的飞行里程M=观测窗口总飞行公里数(单位:公里),如(4)所示。
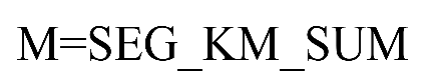
(4)
5) 客户在观测时间内乘坐舱位所对应的折扣系数的平均值C=平均折扣率(单位:无),如式(5)所示。
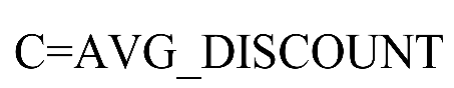
(5)
在完成五个指标的数据提取后,对每个指标数据分布情况进行分析,其数据的取值范围如表3所示。从表中数据可以发现,五个指标的取值范围数据差异较大,为了消除数量级数据带来的影响,需要对数据进行标准化处理。
表3 LRFMC指标取值范围
| 属性名称 | L | R | F | M | C |
| 最小值 | 12.23 | 0.03 | 2 | 368 | 0.14 |
| 最大值 | 114.63 | 24.37 | 213 | 580717 | 1.5 |
属性构造与数据标准化的代码如代码清单3所示。
代码 3属性构造与数据标准化
| # 构造属性L L = pd.to_datetime(airline_selection['LOAD_TIME']) - \ pd.to_datetime(airline_selection['FFP_DATE']) L = L.astype('str').str.split().str[0] L = L.astype('int')/30
# 合并属性 airline_features = pd.concat([L,airline_selection.iloc[:,2:]],axis=1) print('构建的LRFMC属性前5行为:\n',airline_features.head())
# 数据标准化 from sklearn.preprocessing import StandardScaler data = StandardScaler().fit_transform(airline_features) np.savez('../tmp/airline_scale.npz',data) print('标准化后LRFMC五个属性为:\n',data[:5,:]) |
*代码详见:demo/code/zscore_data.py。
标准差标准化处理后,形成ZL、ZR、ZF、ZM、ZC五个属性的数据,如表4所示。
表4 标准化处理后的数据集
| ZL | ZR | ZF | ZM | ZC |
| 1.43571897 | -0.94495516 | 14.03412875 | 26.76136996 | 1.29555058 |
| 1.30716214 | -0.9119018 | 9.07328567 | 13.1269701 | 2.86819902 |
| 1.32839171 | -0.88986623 | 8.71893974 | 12.65358345 | 2.88097321 |
| 0.65848092 | -0.41610151 | 0.78159082 | 12.54072306 | 1.99472974 |
| 0.38603481 | -0.92291959 | 9.92371591 | 13.89884778 | 1.3443455 |
| … | … | … | … | … |
预告:
大数据时代-航空公司该如何转型(四)-模型构建
相关文章
- 1000亿数据、30W级qps如何架构?来一个天花板案例
- 1张图学会如何正确选择图表(数据可视化)
- 【wpf】 当用了数据模板之后如何获取控件的Item?
- Google Earth Engine ——MODIS表面反射率产品提供了在没有大气散射或吸收的情况下在地面测量的表面光谱反射率的估计,250米的分辨率提供波段1和2数据集
- Redis开发运维实践数据迁移之将key从当前数据库移动到指定数据库
- 车品觉:大数据如何帮助企业决策
- DataHub: 现代数据栈的元数据平台--如何删除元数据?
- DataHub: 现代数据栈的元数据平台--如何搭建本地开发环境
- DataHub: 现代数据栈的元数据平台--如何将自定义的元数据事件发送到DataHub
- Hive数据倾斜解决办法总结
- Wireshark数据抓包教程之Wireshark的基础知识
- 项目实战分享:大数据时代-航空公司该如何转型(一)
- 【可视化】地震数据体Segy文件inline、xline道数据计算获取
- Flutter 高级教程之如何开发iOS Widget小组件展示SQLite本地数据库数据(教程含完整源码)
- 如何毫不费力地探索您的 IDX 数据集,使用 idx2numpy 库在 Python 中探索原始 MNIST 文件
- (数据科学学习手札70)面向数据科学的Python多进程简介及应用
- 无处不数据的时代 三大运营商如何变现大数据价值?
- 大数据时代,如何让学习更高效
- 浅析如何让 (a === 1 && a === 2 && a === 3) 返回 true - 数据描述符与存取描述符的利用
- 大数据时代,如何构建国家地质基础数据更新体系
- 【AGC】如何解决事件分析数据本地和AGC面板中显示不一致的问题?
- 如何做到ERP基础数据的整理?
- 3分钟如何向MySQL数据库中插入100万条数据
- 大数据时代:如何节省存储成本
- 数据显示:Debian是最重要的Linux发行版
- 大数据时代隐私该如何保护
- CYQ.Data 轻量数据层之路 抢先体验版本功能说明演示 (二十九)
- 如何使用 apache的POI读取日期格式数据
- 如何解析android访问webservice返回的SoapObject数据(可用)