
一文看懂推荐系统:召回08:双塔模型——线上服务需要离线存物品向量、模型更新分为全量更新和增量更新
一文看懂推荐系统:召回08:双塔模型——线上服务需要离线存物品向量、模型更新分为全量更新和增量更新
提示:最近系统性地学习推荐系统的课程。我们以小红书的场景为例,讲工业界的推荐系统。
我只讲工业界实际有用的技术。说实话,工业界的技术远远领先学术界,在公开渠道看到的书、论文跟工业界的实践有很大的gap,
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
王树森娓娓道来**《小红书的推荐系统》**
GitHub资料连接:http://wangshusen.github.io/
B站视频合集:https://space.bilibili.com/1369507485/channel/seriesdetail?sid=2249610
基础知识:
【1】一文看懂推荐系统:概要01:推荐系统的基本概念
【2】一文看懂推荐系统:概要02:推荐系统的链路,从召回粗排,到精排,到重排,最终推荐展示给用户
【3】一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
【4】一文看懂推荐系统:召回02:Swing 模型,和itemCF很相似,区别在于计算相似度的方法不一样
【5】一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),要计算用户之间的相似度
【6】一文看懂推荐系统:召回04:离散特征处理,one-hot编码和embedding特征嵌入
【7】一文看懂推荐系统:召回05:矩阵补充、最近邻查找,工业界基本不用了,但是有助于理解双塔模型
【8】一文看懂推荐系统:召回06:双塔模型——模型结构、训练方法,召回模型是后期融合特征,排序模型是前期融合特征
【9】一文看懂推荐系统:召回07:双塔模型——正负样本的选择,召回的目的是区分感兴趣和不感兴趣的,精排是区分感兴趣和非常感兴趣的
提示:文章目录
线上服务
今儿个我们继续学习双塔模型,主要内容是双塔模型的线上召回和更新,
在训练好双塔模型之后,就可以把模型部署到线上做召回。
比如在用户刷小红书的时候,快速找到这个用户可能感兴趣的一两百篇笔记,
下面的内容就是双塔模型怎样做召回
这是训练好的两个塔,他们分别提取用户特征和物品特征,
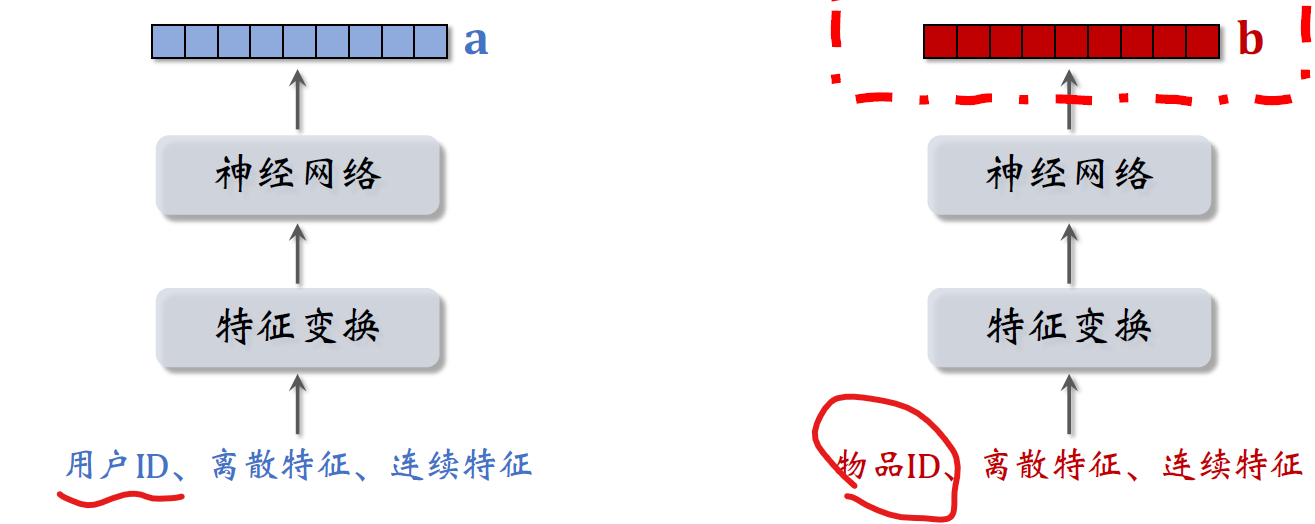
在训练好模型之后,在开始线上服务之前,先用右边的物品塔提取物品的特征,把物品特征向量记作b
小红书有几亿篇笔记,那么就得到几亿个向量b,
把物品特征向量–物品ID这样的二元组保存到Oracle或者MySQL这样的向量数据库。
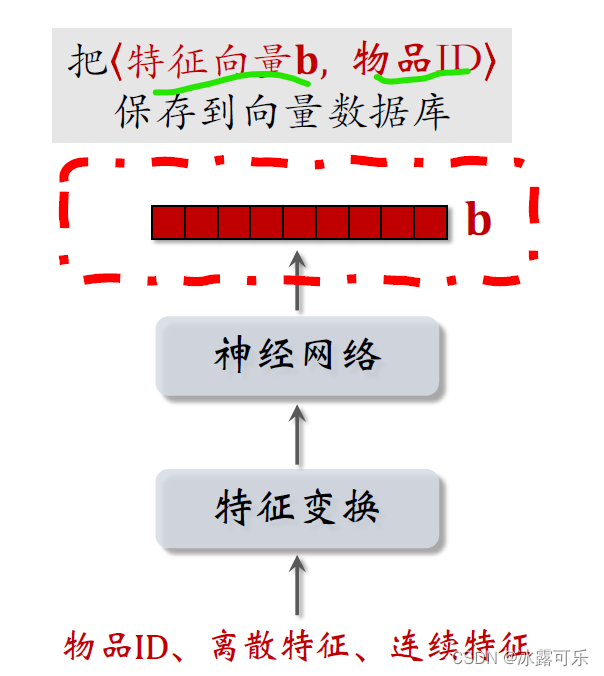
这些是物品的特征向量
和对应的ID有几亿个特征向量
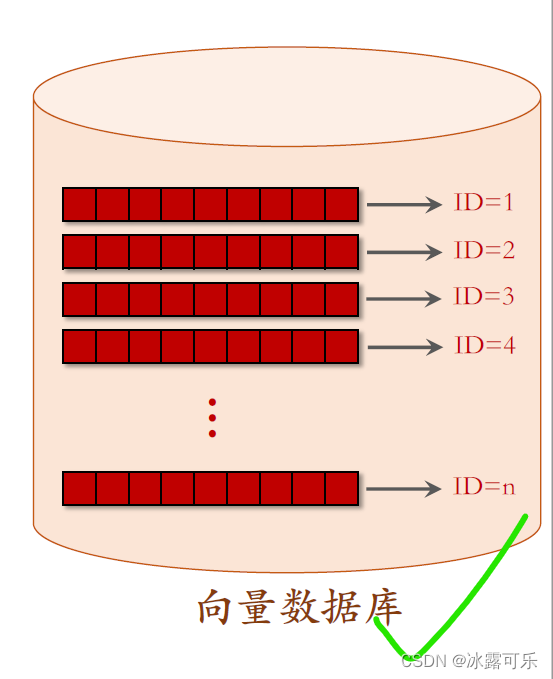
向量数据库存储特征向量和物品ID的二元组。
用作最近邻查找
前面的文章介绍过如何快速做最近邻查找。
【7】一文看懂推荐系统:召回05:矩阵补充、最近邻查找,工业界基本不用了,但是有助于理解双塔模型
至于左边的用户塔,处理方式完全不一样,
不要事先计算和存储用户向量,而是当用户发起推荐请求的时候,调用神经网络在线上线算一个特征向量a,
然后把向量a作为query去数据库中做检索查找最近邻,
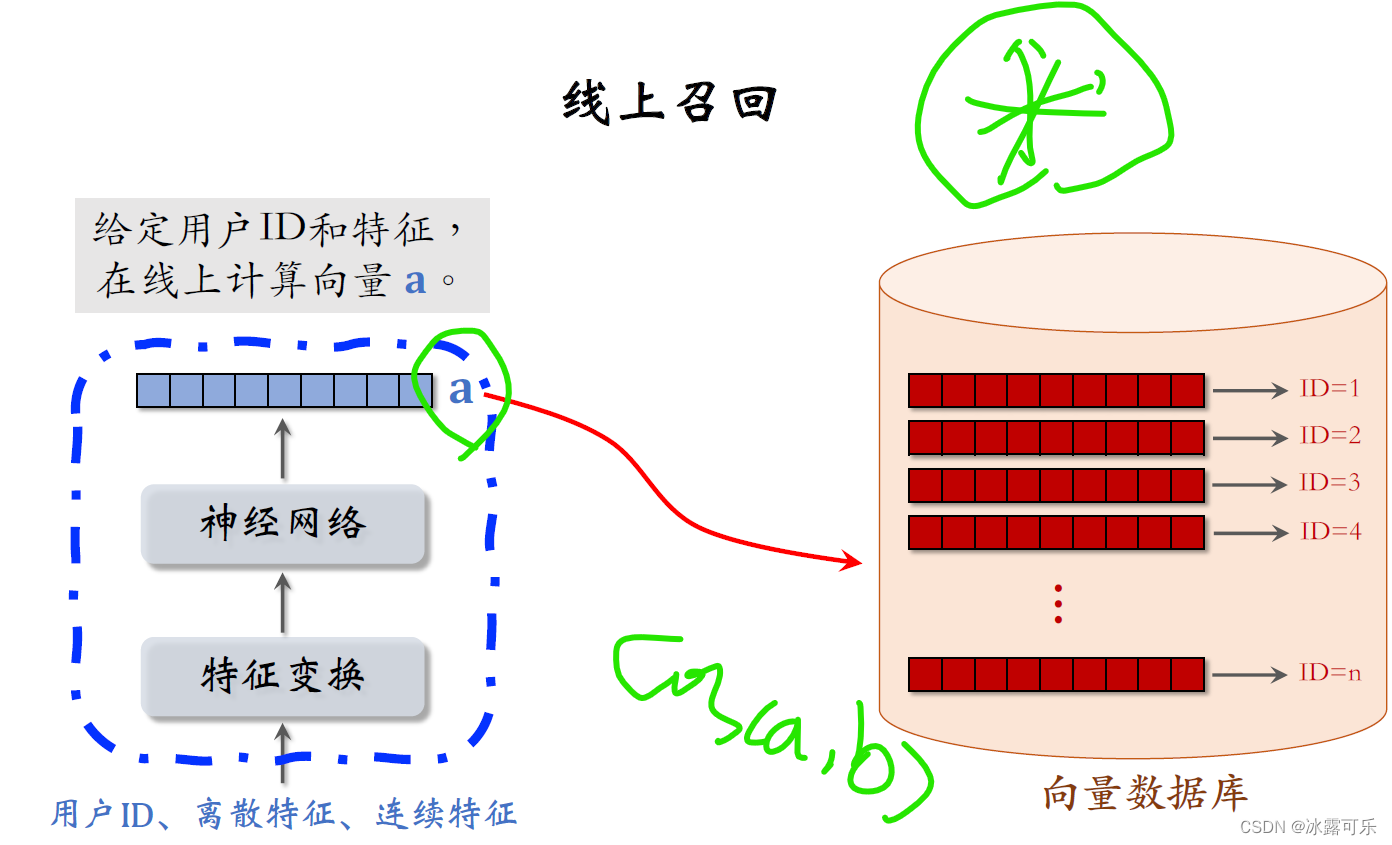
也就是跟向量a相似度(余弦先相似度就是兴趣rate评分)最高的K个红色向量,
每个红色向量对应一篇笔记。
K近邻查找一共召回了K篇笔记,作为这条召回通道的结果返回。
我已经讲完了双塔模型的召回,
我再总结一遍,训练好双塔模型之后,在开始线上服务之前,先要做离线存储,
用神经网络计算每个物品的特征向量B,把这几亿个物品向量存入向量数据库,比如⽐如Milvus、Faiss、HnswLib这样的开源系统。

向量数据库会建立索引,
前面的文章我就讲过建索引就是把向量空间划分成很多区域,
每个区域用一个向量表示,这样可以加速最近邻查找。
在向量数据库建好索引之后,可以开始做线上召回。
比如一个用户刷小红书的时候,
双塔模型召回通道可以返回用户可能感兴趣的K个物品

【图中的topK问题,是互联网大厂经常面试考的题目】
用户发起推荐请求,我们知道用户ID和用户画像,把这些信息输入用户塔神经网络算出用户向量a,
然后在向量数据库中做最近邻查找,把用户的特征向量a作为query,
调用Milvus、Faiss、HnswLib这种向量数据库做近似最近邻查找
数据库返回与用户向量a余弦相似度最大的K物品作为召回的结果。
接下来,这些物品会跟其他的等召回通道的结果融合,然后经过排序最终展示给用户。
我已经讲完了召回的内容,请大家思考一个问题,
在开始线上召回之前,我们先要把物品向量B存储到向量数据库,
但是我们不存储用户向量a,而是在线上用神经网络现算用户向量a。
为什么要区别对待物品向量和用户向量?

道理是这样的,每做一次召回,只用到一个用户向量a,
而要用到几亿个物品向量B,拿神经网络现算一个用户向量,计算量不大,算的起。
但是几亿个物品向量显然是算不起的,
所以我们不得不离线算好物品向量。
那么,能不能把几亿个用户向量也事先算好,把几亿个向量存储起来,进一步减少线上的计算负担?
这样做当然可以,
推荐团队早期基础很弱的时候通常会这样做,这样工程实现很简单,
但这样不利于推荐的效果。
因为用户的兴趣点是动态变化的,所以应该在线上实时计算用户向量
而不是事先计算好存起来。
事先存储用户向量效果不好,
但事先存储物品向量是OK的,这是因为物品的特征相对比较稳定,
短期内不会发生变化。
模型更新:全量更新和增量更新
刚才介绍的线上召回
在实践中还会更复杂一些,会涉及到模型的全量更新和增量更新。
全量更新,意思是在每天凌晨用前一天的数据训练模型,
比方说在今天凌晨就用昨天的数据训练模型。
注意,是在昨天模型参数的基础上做训练,而不是重新随机初始化。

把昨天一天的数据打包成tf record的文件,在昨天模型参数的基础上做训练,把昨天的数据过一遍,
每条数据只用一次,也就是训练只做one episode,
训练完成之后发布新的用户塔神经网络
用户塔的作用是在线上实时计算用户向量。
作为召回的query还要发布新的物品向量,这几个向量存入向量数据库,
向量数据库会重新建索引,然后可以在线上做最近邻查找。
全量更新的实现相对比较容易,对数据流和整个系统的要求不高。
全量更新不需要实时的数据流,对生成训练数据的速度没有要求,延迟一两个小时也没有关系,
只需要把每天的数据落表在凌晨做个批处理,把数据打包成tf record格式的文件就可以了。
全量更新对系统的要求也很低,每天做一次全量更新,
所以只需要把神经网络和物品向量,每天发布一次就够了。
与全量更新相对的是增量更新,也就是做online learning,更新模型参数,
每隔几十分钟就把新的模型参数给发布出去。
为什么要做增量更新?这是因为用户的兴趣随时会发生变化
举个例子我,早上刷小红书的时候看到几篇有意思的笔记,也就是说我产生了新的兴趣点。
我在中午刷新小红书,小红书能不能根据我新的兴趣点做推荐?
如果模型是做天级别的全量更新肯定是不行的,
想要让模型在用户行为发生几小时之内就做出反应,
模型需要做到小时级别的增量更新。

增量更新对数据流的要求很高,需要实时收集线上的数据,并且对数据做流式处理,
实时生成训练模型用的tf record文件。
然后对模型做online learning做梯度下降,更新ID embedding的参数,
也就是说从早到晚训练数据文件不断生成,
不断做梯度下降更新模型的embedding层
注意,Online learning 不更新神经网络其他部分的参数,
全连接层的参数都是锁住的,不做增量更新,
只更新embedding的参数,
只有做全量更新的时候才会更新全连接层。
至于为什么只更新embedding层参数,不更新全链接层参数,
主要是出于工程实现的考量,道理一两句话也解释不清楚。
对模型更新之后,再把算出的用户ID embedding给发布出去
用户的ID embedding是一个哈希表的形式,
给定用户ID可以查出ID embedding向量
发布用户ID embedding的目的是为了线上计算用户的特征向量,
最新的用户ID embedding可以捕捉到用户的最新的兴趣点,对推荐很有帮助。
发布用户ID embedding,这个过程会有延迟,
在我们小红书刚上线online learning的时候,这个过程会有小时级的延迟,
通过对系统做优化,延迟可以降低到几十分钟甚至更短。
也就是说,用户在小红书上产生行为,几十分钟之后,他的用户向量就会被更新。
他再次刷新小红书的时候,双塔模型会考虑到他最新的兴趣。
图示全量更新和增量更新
在我们小红书模型既要做全量更新,也要做增量更新,
我画个图演示一下,
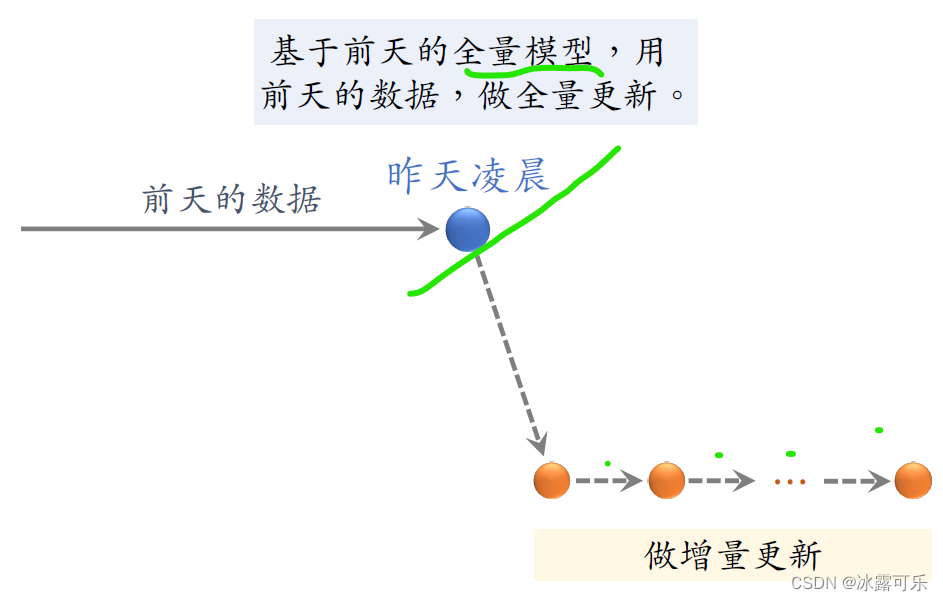
这些是前天一天积累的数据,到了昨天凌晨的时候,我们把前天的数据打包成tf ricker的文件,
要基于前天凌晨全量训练出来的模型做训练,
也就是说昨天凌晨模型初始化的时候,参数用的是前天凌晨全量训练出的模型,而不是随机初始化。
然后我们拿前天积累的数据来训练模型,要把前天的数据做random shuffle打乱。
然后做随机梯度下降
只训练1 epoch,也就是说每条数据只过一遍。
接下来需要基于这个全量训练出来的模型做分钟级别的增量更新。
从昨天凌晨到今天凌晨,不停做online learning,
每隔几十分钟发布一次模型,刷新线上的用户塔100顶层参数,
在昨天我们又就积累了一天的数据,到了今天凌晨又该做一次全量更新。
今天凌晨的全量更新是基于昨天凌晨全量训练出来的模型,而不是用下面增量训练出的模型。
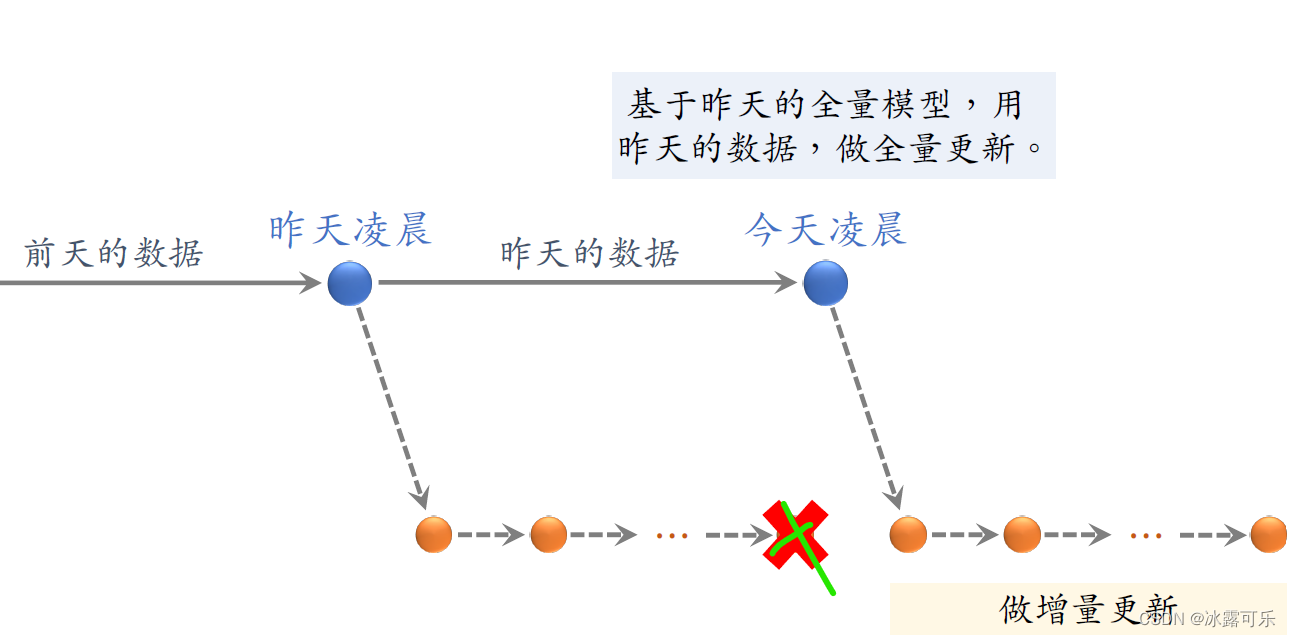
在完成这次全量训练之后,下面增量训练出的模型就可以扔掉了,
然后再基于今天凌晨全量训练出的模型,做分钟级别的增量更新,
从今天凌晨到明天凌晨,不停做online learning,每隔几十分钟发布一次模型。
大家思考一个问题,能不能只做增量更新,不做全量更新?
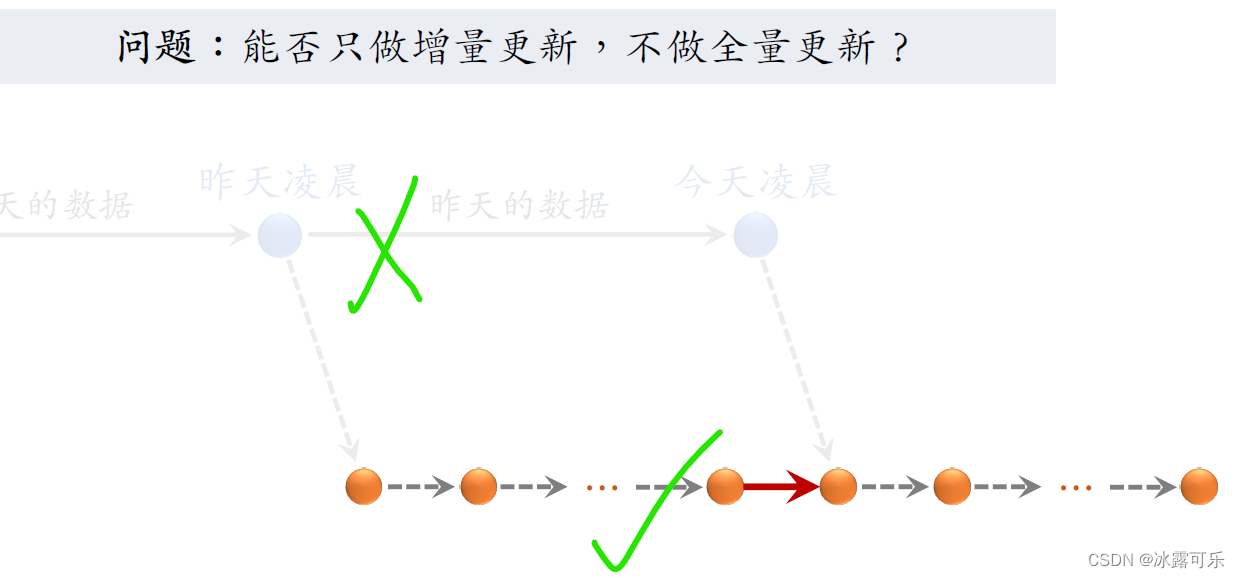
什么意思?就是去掉上面的全量更新,接着昨天的增量更新训练,继续把增量更新给做下去。
这样只做增量更新,当然比既要做增量也要做全量简单工程实现会更容易,训练消耗的机器资源也更少。
我们同时把两种都试过,发现只做增量的话效果不好,
最好还是既要做全量,也要做增量。
为什么只做增量更新效果不好?
如果你只看一个小时的数据,它是有偏的,
它的统计值跟全天的数据差别很大
为什么有偏?在不同的时间段,用户的行为是不一样的,
比如中午和傍晚的数据明显会不一致,如果你只看五分钟的数据,那么偏差就更大了,
它跟全天数据的统计值差别巨大,
我们做全量训练的时候要随机排列数据,也就是randen shuffle,这样就是为了消除偏差。
全量更新是在random shuffle过的数据上做,
而增量更新删掉数据,从早到晚的顺序做训练,同样使用一天的数据。

这两种排列数据的方式会导致训练的效果有差别,
把数据按照从早到晚的时间顺序排列,效果不如把数据随机打乱。
所以全量训练的效果比增量训练更好。
这就是为什么我们既要做增量训练,也要做全量训练,
全量训练的模型更好,而增量训练可以实时捕捉用户的兴趣。
懂?
刚刚我们详细讲解了双塔模型,
最后总结一下,双塔模型,顾名思义有两个塔,一个用户塔,一个物品塔,
两个塔各输出一个向量,两个向量的余弦值就是对兴趣的预估,
这个值越大,用户就越有可能对物品感兴趣。

前面的课介绍了三种训练双卡模型的方式,分别是point wise,pair wise, list wise。
做训练的时候要用到正负样本,
正样本是用户点击过的物品,
负样本稍微复杂一些,简单负样本是全体物品,是从全体物品中做随机抽样,
困难负样本是被排序淘汰的物品。
做完训练,把物品塔输出的物品向量存储到向量数据库里面,
供线上做最近邻查找

用做线上召回的时候拿到用户ID和用户画像,调用训练好的用户塔神经网络现算用户的向量a,
然后把用户向量a作为query,查询物品的向量数据库,
找到余弦相似度最大的K物品向量
返回这K物品ID作为召回结果
模型需要定期做全量更新和实时做增量更新,

全量更新,意思是在今天凌晨用昨天的数据训练整个神经网络做1epoch随机梯度下降,也就是每条数据只用一遍。
增量更新,意思是用最近产生的数据训练神经网络,训练的时候只更新embedding层
锁住全连接层不更新
现在先进的推荐系统都会结合全量更新和增量更新。
每天做全量更新,实时做增量更新,每隔几十分钟要发布最近的用户embedding,
供用户他在线上计算用户向量用。
这样的好处是可以捕捉到用户最新的兴趣点
懂了吧?
从双塔模型的原理,到线上召回的过程,我已经讲得很清楚很明了。
最近这几篇文章我想你应该都熟悉了。
总结
提示:如何系统地学习推荐系统,本系列文章可以帮到你
(1)找工作投简历的话,你要将招聘单位的岗位需求和你的研究方向和工作内容对应起来,这样才能契合公司招聘需求,否则它直接把简历给你挂了
(2)你到底是要进公司做推荐系统方向?还是纯cv方向?还是NLP方向?还是语音方向?还是深度学习机器学习技术中台?还是硬件?还是前端开发?后端开发?测试开发?产品?人力?行政?这些你不可能啥都会,你需要找准一个方向,自己有积累,才能去投递,否则面试官跟你聊什么呢?
(3)今日推荐系统学习经验:现在先进的推荐系统都会结合全量更新和增量更新。
相关文章
- 近40年银行核心系统变迁历程及新建设模式
- [XMove-自主设计的体感解决方案] 系统综述
- 合阔智云核心生产系统切换到服务网格 ASM 的落地实践
- loadrunner12.55:订票系统脚本录制---手动关联
- EasyNVR无插件H5/HLS/m3u8直播解决方案中Windows系统服务启动错误问题的修复:EasyNVR_Service 服务因 函数不正确。 服务特定错误而停止。
- adb shell dumpsys 系统服务 [MD]
- 各种官网系统镜像文件(Windows 7 ,Windows 10,Ubuntu 18.6,Centos 6.8 ,Centos 7.6 )
- [ASP.NET Core 3框架揭秘] 服务承载系统[1]: 承载长时间运行的服务[上篇]
- paip.注册java程序为LINUX系统服务的总结。
- Android 8.1 系统应用如何拉起第三方应用的服务
- Android WMS服务的窗口系统
- Android 系统服务 io多路复用
- 成功解决Windows无法启动服务NVIDIA Dispaly Container LS服务(位于本地计算机上),错误2:系统找不到指定的文件
- 【大数据 OLAP ClickHouse 引擎】ClickHouse 系统架构和存储引擎实现原理 : 为什么 ClickHouse 这么快? Why is ClickHouse so fast?
- 内网渗透(三十五)之横向移动篇-IPC配合系统服务横向移动
- 数据分析----数据分析环境搭建即在Windows10系统安装Anaconda集成环境
- 【Deepin 20系统】Linux系统安装gcc报错no acceptable C compiler found in $PATH
- 基于Java+SpringBoot+Vue在线培训考试系统设计与实现
- 真实推荐系统
- 操作系统权限提升(六)之系统错误配置-不安全的服务提权