
【Pytorch Lighting】第 8 章:自监督学习
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
自机器学习问世以来,该领域被整齐地划分为两个阵营:监督学习和无监督学习。在监督学习中,应该有一个可用的标记数据集,如果不是这样,那么剩下的唯一选择就是无监督学习。虽然无监督学习听起来很棒,因为它可以在没有标签的情况下工作,但在实践中,无监督方法(如聚类)的应用非常有限。评估无监督方法的准确性或部署它们也没有简单的选择。
最实用的机器学习应用程序往往是监督学习应用程序(例如,识别图像中的对象、预测未来的股票价格或销售量,或者在 Netflix 上向您推荐合适的电影)。监督学习的权衡是精心策划和高质量可信赖标签的必要性。大多数数据集并非天生就有标签,获得这样的标签可能非常昂贵,有时甚至是完全不可能的。ImageNet 是最受欢迎的深度学习数据集之一,由超过 1400 万张图像组成,每个标签标识该图像中的一个对象。正如您可能已经猜到的那样,源图像并没有带有那些漂亮的标签,因此使用亚马逊的 Mechanical Turk 应用程序的 149,000 名工人(主要是研究生)花费了 19 个月以上的时间手动标记每张图像。有很多数据集,
这就引出了一个问题,如果我们能想出一种新方法,不需要太多标签就可以工作,例如无监督学习,但输出与监督学习一样具有高影响力?这正是自我监督学习承诺要做的事情。
自监督学习是机器学习的最新范式,是最前沿的前沿。虽然它已经被理论化了几年,但直到去年它才能够显示出与监督学习相当的结果,并被吹捧为机器学习的未来。图像自监督学习的基础是即使没有标签,我们也可以让机器学习真实的表示。 使用极少数量的标签(低至数据集的 1%),我们可以获得与监督模型一样好的结果。这释放了由于缺乏高质量标签而未使用的数百万个数据集的未开发潜力。
在本章中,我们将介绍自监督学习,然后介绍自监督学习中用于图像识别的最广泛使用的架构之一,称为对比代表性学习。在本章中,我们将介绍以下主题:
- 自监督学习入门
- 什么是对比学习?
- SimCLR 架构
- 用于图像识别的 SimCLR 对比学习模型
技术要求
在本章中,我们将主要使用以下 Python 模块:
- NumPy (version 1.21.5)
- torch (version 1.10)
- torchvision (version 0.11.1)
- PyTorch Lightning (version 1.5.2)
请在运行代码之前检查包的正确版本。
为了确保这些模块一起工作并且不会不同步,我们使用了特定版本的 torch、torchvision、torchtext、torchaudio 和 PyTorch Lightning 1.5.2。您还可以使用相互兼容的最新版 PyTorch Lightning 和手电筒.
!pip install torch==1.10.0 torchvision==0.11.1 torchtext==0.11.0 torchaudio==0.10.0 --quiet
!pip install pytorch-lightning==1.5.2 --quietSTL-10 源数据集可以在STL-10 dataset找到。

图 8.1 – STL-10 数据集的快照
STL-10 数据集是用于开发自我监督学习算法的图像识别数据集。它与 CIFAR-10 类似,但有一个非常重要的区别:每个类的标记训练示例都比 CIFAR-10 少,但提供了非常大的未标记示例集,以便在监督训练之前学习图像表示。
自监督学习入门
鉴于近年来 CNN 和 RNN 等深度学习方法的巨大成功,机器学习的未来备受争议。虽然 CNN 可以做惊人的事情,例如图像识别,RNN 可以生成文本,而其他高级 NLP 方法(例如 Transformer)可以取得惊人的效果,但它们都有严重的问题。与人类智力相比的局限性。在推理、演绎和理解等任务上,它们与人类相比不太好。此外,最值得注意的是,它们需要大量标记良好的训练数据来学习甚至像图像识别这样简单的东西。

图 8.2 – 一个孩子学会用很少的标签对物体进行分类
毫不奇怪,这不是人类学习的方式。孩子在识别物体之前不需要数百万张带标签的图像作为输入。与机器学习相比,人脑基于极少量的初始信息生成自己的新标签的惊人能力是无与伦比的。
为了扩大人工智能的潜力,人们尝试了各种其他方法。对实现接近人类智能性能的追求导致了两种不同的方法,即强化学习和自我监督学习。
在强化学习中,重点是关于构建类似游戏的环境并使机器学习如何在没有明确指示的情况下在环境中导航。每个系统都被配置为最大化奖励功能,并且慢慢地,代理通过在每个游戏事件中犯错来学习,然后在下一个事件中最小化这些错误。这样做需要对模型进行数百万个周期的训练,这有时会转化为数千年的人类时间。虽然这种方法在围棋等非常困难的游戏中击败了人类,并为机器智能树立了新的基准,但显然这不是人类学习的方式。在能够玩游戏之前,我们不会练习游戏数千年。此外,如此多的试验使得学习任何实际工业应用的速度都太慢了。
然而,在自我监督学习中,重点是通过尝试创建自己的标签并继续自适应地学习,让机器学习有点像人类。自我监督学习一词是Yann LeCun 的心血结晶,他是图灵奖获得者之一(相当于诺贝尔计算奖),因为他对深度学习做出了基础性贡献。他还为自我监督学习奠定了基础,并使用能量建模方法进行了大量研究。

图 8.3 – 未来属于“自我监督学习”
最值得注意的是,Yann LeCun 认为,人工智能的未来既不会受到监督也不会得到加强,而是会自我监督!这可以说是最重要的领域,有可能颠覆我们对机器学习的认识。
那么,自我监督意味着什么?
核心概念是我们可以在多个维度的数据中学习。在监督学习中,我们有数据 (x) 和标签 (y),我们可以做很多事情,例如预测、分类和对象检测,而在无监督学习中,我们只有数据 (x),并且我们只能对模型进行聚类。在无监督学习中,我们的优势是不需要昂贵的标签,但我们可以构建的模型种类有限。如果我们以无监督的方式开始(只有 x,然后以某种方式为数据集生成标签(y))然后继续进行有监督学习怎么办?
换句话说,如果我们可以让机器学习生成自己的标签呢?目前,假设我有一个图像数据集,例如 CIFAR-10,它由 10 类图像(鸟类、飞机、狗和猫等类)组成,分布在 65,000 个标签上。这就是机器需要学习识别这 10 个类别的内容。如果不是像我们为这个数据集提供的那样提供 65,000 个标签,而是只提供 10 个标签(每个类别一个),然后机器找到与这些类别相似的图像并为其添加标签,该怎么办?如果我们能做到这一点,那么机器就会自我监督它的学习过程,它将能够扩展以解决以前未解决的问题。
我在这里提供的是一个相当简单的自我监督学习的定义。Yann LeCun 主要在能量建模的背景下将自我监督学习定义为一种不仅可以从后向学习,而且可以在任何方向学习的模型。能量建模是深度学习社区的一个活跃研究领域。诸如概念学习之类的想法,模型借此学习图像和标签的概念在一起,未来可能是革命性的。此外,您可能已经听说过一款自我监督学习应用程序。GPT3 和 Transformers 等 NLP 模型已经过无标签训练,并且仍然可以针对任何任务轻松进行微调或调整。您可以理解语言是一维数据结构,因为数据通常沿一个方向流动(从后到前,因为我们从左到右阅读英语),因此很容易学习结构而无需任何标签。
在其他领域,例如图像或结构化数据,没有标签或标签数量非常有限的学习已被证明具有挑战性。本章我们将重点关注的一个领域,最近几个月取得了非常有趣的成果,那就是对比学习,我们可以从不相似的图像中找到相似的图像,而无需任何标签。
什么是对比学习?
理解的想法图像是获取特定类型的图像(例如狗),然后我们可以通过推理它们共享相同的表示或结构来识别所有其他狗。例如,如果你给一个还不能说话或理解语言的孩子(比如,不到 2 岁)展示一张狗的照片(或真狗),然后给他们一包卡片,上面写着一组动物,包括狗、猫、大象和鸟,然后问孩子哪张图片与第一张相似,孩子很可能很容易挑选出上面有狗的卡片。即使您不解释这张图片等于“狗”,孩子也可以这样做(换句话说,无需提供任何新标签)。
你可以说一个孩子学会了在一个实例和一个标签上识别所有的狗!如果机器也能做到这一点,那不是很棒吗?这正是对比学习的意义所在!
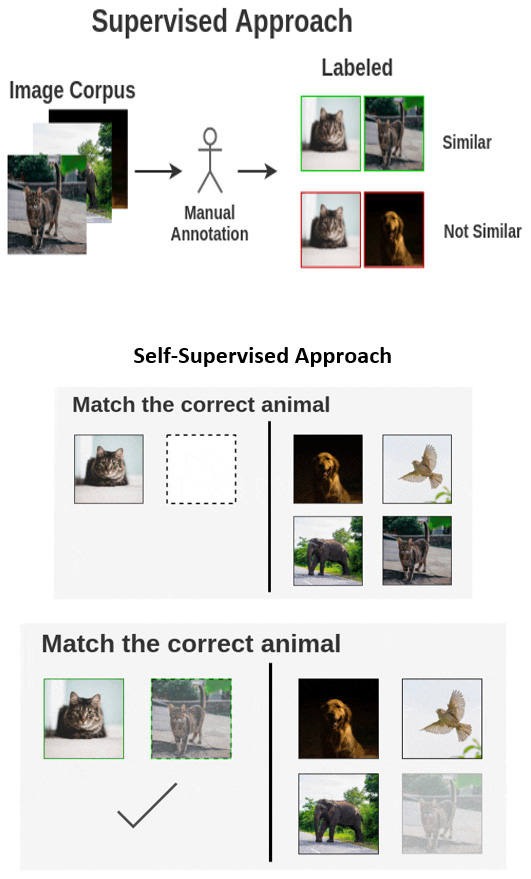
图 8.4 – 对比学习与监督学习有何不同(来源:https ://amitness.com/2020/03/illustrated-simclr/ )
怎么了这是表示学习的一种形式。其实这个方法的全称是对比表示学习. 孩子已经了解狗具有某种类型的表征(一条尾巴、四条腿、眼睛等),然后能够找到类似的表征。令人惊讶的是,人脑用非常少的数据来做到这一点(即使是一张图像也足以教给某人一个新对象)。事实上,儿童发展专家提出的理论是,当孩子不到几个月大时,它就开始纯粹通过创建松散的表示(如剪影)来识别其父母和其他熟悉的物体。这是它开始接受新的视觉数据并开始识别和分类过程的关键发展阶段之一。这种视觉能力使我们能够看到而不是仅仅看物体,这对我们的智力发展非常重要。相似地,
已经提出了各种用于对比学习的架构,并取得了惊人的成果。一些流行的有 SimCLR、CPC、YADIM 和 NOLO。在本章中,我们将看到正在迅速成为对比学习事实上的标准的架构——SimCLR。
SimCLR 架构
SimCLR代表简单对比学习架构。该架构基于Geoffrey Hinton 和 Google 团队发表的论文“A Simple Framework for Contrastive Learning of Visual Representations” 。Geoffrey Hinton(就像 Yann LeCun 一样)是共同收件人因其在深度学习方面的工作而获得图灵奖。有 SimCLR 和 SimCLR2 版本。SimCLR2 是一个比 SimCLR 更大、更密集的网络。在撰写本文时,SimCLR2 是可用的最佳架构更新,但如果即将推出比前一个更密集和更好的 SimCLR3,请不要感到惊讶。
该架构已经表明,与 ImageNet 数据集相关,我们只需 1% 的标签就可以达到 93% 的准确率。考虑到 Mechanical Turk 上超过 140,000 名标注员(主要是研究生)花费了 2 年多的时间和大量的努力来手工标注 ImageNet,这是一个真正了不起的结果。这是在全球范围内开展的一项艰巨的任务。除了标记该数据集所花费的大量时间之外,很明显,如果没有像谷歌这样的大公司的支持,这样的努力是很困难的。许多数据集只是因为没有正确标记而未被使用,这对您来说可能并不奇怪。如果我们仅用 1% 的标签就能获得可比的结果,那将打开深度学习可以做的以前未打开的大门!
SimCLR 是如何工作的?
让我们有一个SimCLR 工作原理的快速概览。我们敦促您阅读上一节中提到的完整论文以了解更多详细信息。
对比学习背后的想法是,我们希望对相似的图像进行分组,同时将它们与不同的图像区分开来。这个过程发生在一组未标记的图像上。
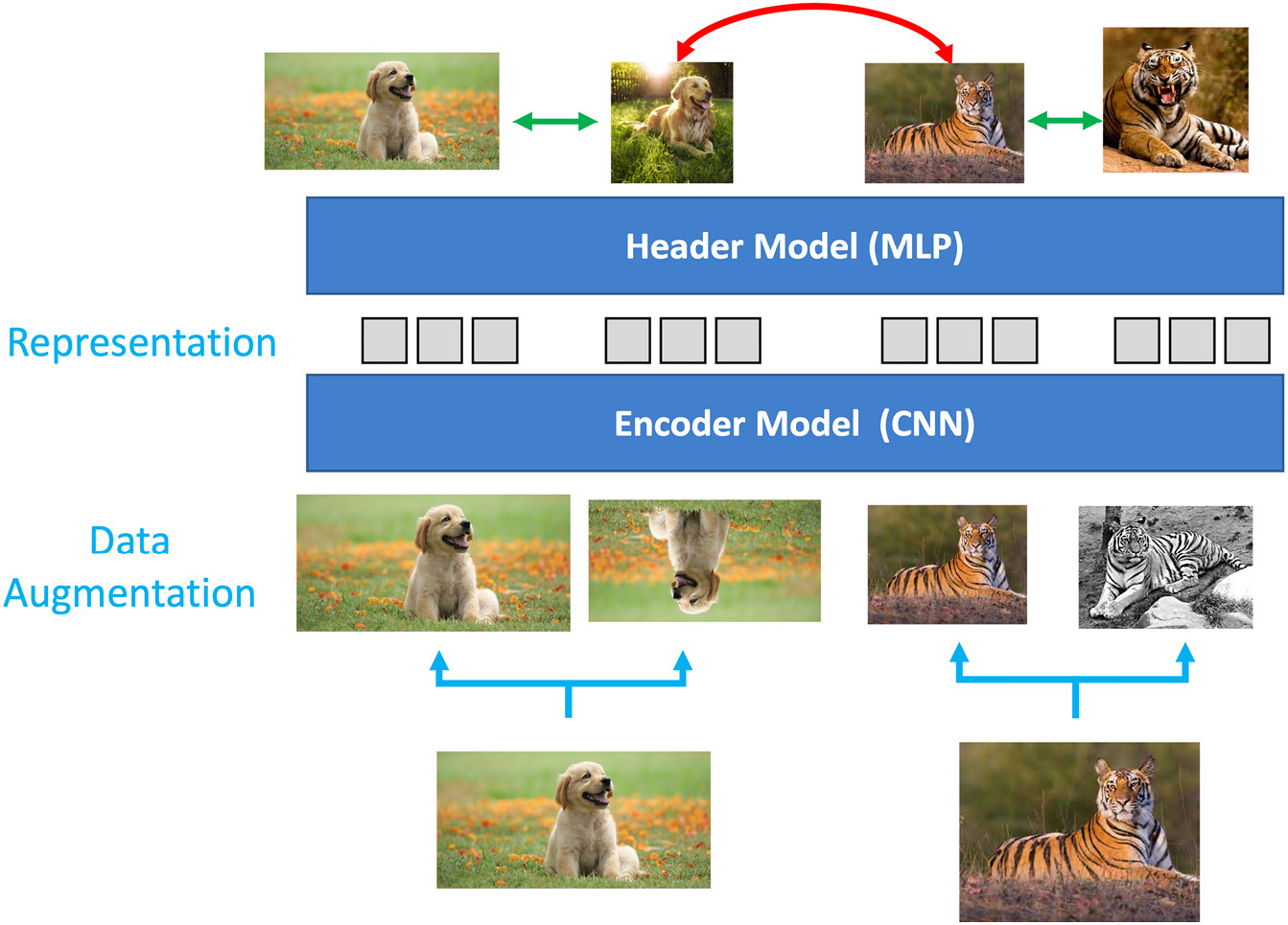
图 8.5 – SimCLR 的工作原理(注意:架构自下而上执行)
- 作为第一步,对随机图像组执行数据增强。执行各种数据增强任务。其中一些是标准的,例如旋转图像、裁剪图像以及通过使它们成为灰度来更改颜色。还执行其他更复杂的数据增强任务,例如高斯模糊。您会发现,增强变换越复杂,它对模型就越有用。
这个数据增强步骤非常重要,因为我们想让模型可靠且一致地学习真实的表示。另一个相当重要的原因是我们在数据集中没有标签。因此,我们无法知道哪些图像实际上彼此相似,哪些不同。因此,从单个图像中获得各种增强图像会为我们可以先验确定的模型创建一组“真实”的相似图像。
- 下一个然后是创建一批包含相似和不同图像的图像。作为一个类比,这可以被认为是具有一些正离子和一些负离子的批次,我们希望通过在它们上方移动一个神奇的磁铁(SimCLR)来隔离它们。
- 这个过程之后是一个编码器,它只不过是一个 CNN 架构。ResNet架构(例如 ResNet-18 或 ResNet-50)最常用于此操作。但是,我们剥离最后一层并使用最后一个平均池层之后的输出。这个编码器帮助我们学习图像表示。
- 紧随其后的是头模块(也称为投影头),它是一个多层感知器( MLP ) 模型。这用于将对比损失映射到应用上一步表示的空间。我们的 MLP 可以是单隐藏层神经网络(如在 SimCLR 中)或 3 层网络(如在 SimCLR2 中)。你甚至可以试验更大的神经网络。此步骤用于平衡对齐(将相似的图像保持在一起)和均匀性(保留最大量的信息)。
- 这一步的关键是用于对比预测的对比损失函数。它的工作是识别数据集中的其他正面图像。使用的专门损失函数因为这是NT-Xent(归一化的温标交叉熵损失)。这个损失函数帮助我们衡量系统在随后的时期是如何学习的。
这些步骤描述了 SimCLR 架构,并且您可能已经注意到,它完全适用于未标记的图像。当您针对图像分类等下游任务对其进行微调时,就会实现 SimCLR 的魔力。这个架构可以学习功能,然后您可以将这些功能用于任何任务。
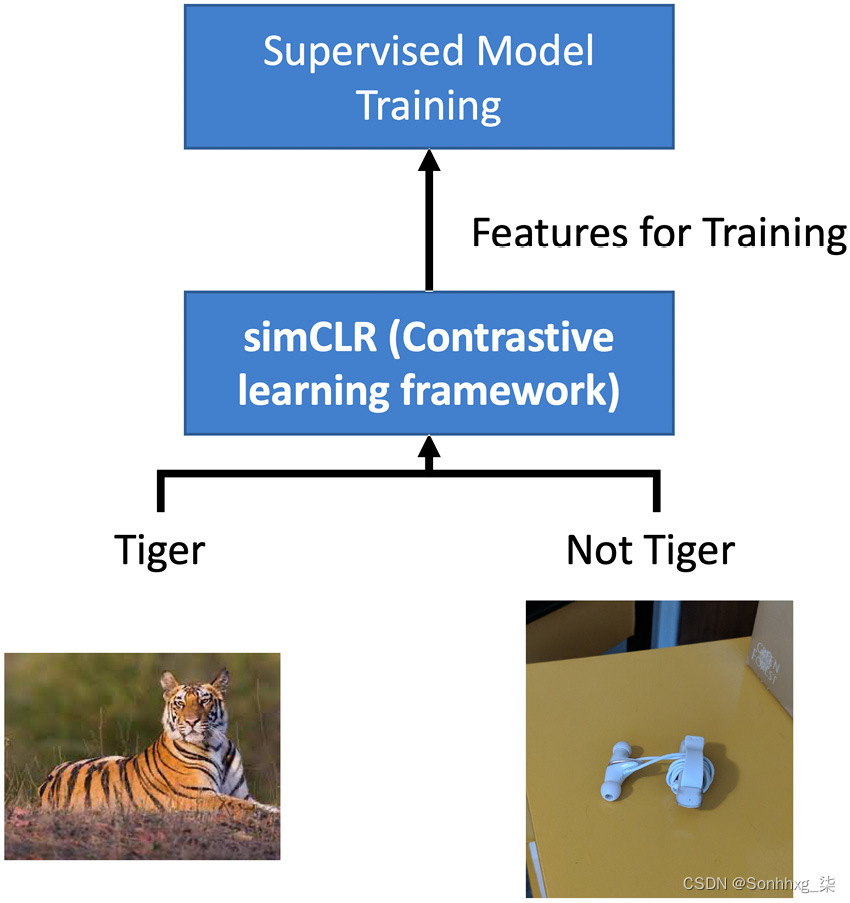
图 8.6 – 寻找相关图像的半监督方法
任务可能是找出数据集中的图像是否与您的目标相关。想象一下,您想通过为老虎创建图像识别模型来拯救老虎,而您只想要老虎图像。任何相机陷阱都可能包括其他动物(甚至是不相关的物体)。但并非所有图像都会被标记。您可以使用 SimCLR 架构构建半监督学习模型,然后为您拥有的任何少量标签使用监督分类器并清理数据。也可以将其视为迁移学习,将通过 SimCLR 模型的表示学习学习到的权重转移到后续的分类任务中。
另一个更基本的任务可能是通过提供来自 SimCLR 架构的极少标签和特征来对图像进行分类。您可能会想到的问题是“到底有多少?” 实验表明,对于只有 10% 甚至 1% 标记的下游任务,我们可以获得接近 95% 的准确率。
用于图像识别的 SimCLR 模型
- 通过将相似的图像组合在一起并将不同的图像分开来学习特征表示(单位超球面)。
- 平衡对齐(将相似的图像保持在一起)和均匀性(保留最大信息)。
- 学习未标记的训练数据。
主要挑战是使用未标记数据(来自与标记数据相似但不同的分布)来构建有用的先验,然后用于为未标记集生成标签。让我们看看我们将在本节中实现的架构。
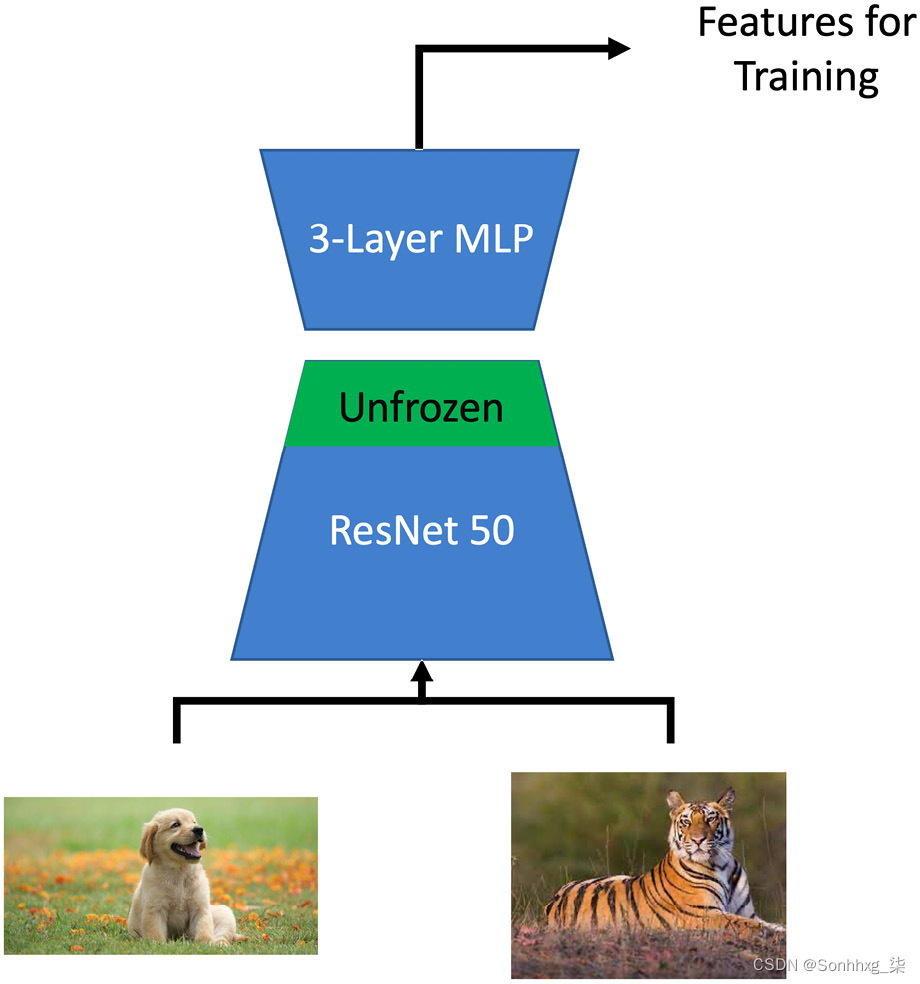
图 8.7 – SimCLR 架构实现
我们将使用 ResNet-50 作为Encoder,然后使用三层 MLP 作为投影头。然后,我们将使用逻辑回归或 MLP 作为监督分类器来测量准确性。
- 收集数据集
- 设置数据增强
- 加载数据集
- 配置培训
- 训练 SimCLR 模型
- 评估性能
收集数据集
我们将使用STL-10 数据集来自STL-10 dataset。
如数据集网页所述,STL-10 数据集是用于开发自监督学习算法的图像识别数据集。它由以下部分组成:
- 10类:飞机、鸟、车、猫、鹿、狗、马、猴、船、卡车。
- 图像为 96x96 像素和彩色。
- 每类 500 个训练图像(10 个预定义折叠)和 800 个测试图像。
- 用于无监督学习的 100,000 张未标记图像。这些示例是从类似但更广泛的图像分布中提取的。例如,除了标记集中的动物之外,它还包含其他类型的动物(熊、兔子等)和车辆(火车、公共汽车等)。
二进制文件分为后缀为 train_X.bin、train_y.bin、test_X.bin和test_y.bin的数据和标签文件。
您可以直接从http://ai.stanford.edu/~acoates/stl10/stl10_binary.tar.gz下载二进制文件并将它们放在您的数据文件夹中。或者,要在云实例上工作,请执行 https://github.com/mttk/STL10 上提供的完整 Python 代码。STL-10 数据集也可以在https://pytorch.org/vision/stable/datasets.html#stl10下的torchvision模块中找到,也可以直接导入到 notebook 中。
由于 STL-10 数据集是从 ImageNet 中抓取的,因此 ImageNet 上的任何预训练模型都可以通过使用预训练的权重来加速训练。
SimCLR 模型依赖于三个包:pytorch、torchvision和pytorch_lightning。作为第一步,请安装这些包并将其导入您的笔记本中。安装包后,我们将开始导入它们:
import os
import urllib.request
from copy import deepcopy
from urllib.error import HTTPError
import matplotlib
import matplotlib.pyplot as plt
import pytorch_lightning as pl
import seaborn as sns
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data as DataLoader
from IPython.display import set_matplotlib_formats
from pytorch_lightning.callbacks import LearningRateMonitor, ModelCheckpoint
from pytorch_lightning.callbacks import ModelCheckpoint
from pytorch_lightning.callbacks import Callback
import torchvision
from torchvision import transforms
import torchvision.models as models
from torchvision import datasets
from torchvision.datasets import STL10
from tqdm.notebook import tqdm
from torch.optim import Adam
import numpy as np
from torch.optim.lr_scheduler import OneCycleLR
import zipfile
from PIL import Image
import cv2之后导入必要的包,我们必须收集 STL-10 格式的图像。我们可以将斯坦福存储库中的数据下载到我们的本地数据路径中,以用于进一步处理。您应该添加下载 STL-10 文件的文件夹的路径。
设置数据增强
首先我们需要做的步骤是创建一个数据增强模块。这是 SimCLR 架构中极其重要的一步,最终结果很大程度上受此步骤中所进行转换的丰富程度的影响。
重要的提示
PyTorch Lightning 还包括使用 Bolts 开箱即用的各种 SimCLR 变换。但是,我们在这里手动定义它。您还可以在此处参考开箱即用的转换以了解各种方法:https ://pytorch-lightning-bolts.readthedocs.io/en/latest/transforms.html#simclr-transforms 。请注意您的 PyTorch Lightning 版本和使用它们的Torch版本。
我们的目标是创建一个可以通过创建给定图像的多个副本并对其应用各种增强转换轻松实现的正集。作为第一步,我们可以创建任意数量的图像副本:
class DataAugTransform:
def __init__(self, base_transforms, n_views=4):
self.base_transforms = base_transforms
self.n_views = n_views
def __call__(self, x):
return [self.base_transforms(x) for i in range(self.n_views)]在前面的代码片段中,我们创建了同一图像的四个副本。
我们现在将继续对图像应用四个关键变换。根据原始论文和进一步的研究,图像的裁剪和调整大小是至关重要的转换和帮助学习更好的模型:
augmentation_transforms = transforms.Compose(
[
transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop(size=96),
transforms.RandomApply([transforms.ColorJitter(brightness=0.8, contrast=0.8, saturation=0.8, hue=0.1)], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),
]
)在前面的代码片段中,我们扩充了图像并执行了以下转换:
- 随机调整大小和裁剪
- 随机水平翻转
- 随机颜色抖动
- 随机灰度
请请注意,对于相当大的数据集,数据扩充步骤可能需要相当长的时间才能完成。
重要的提示
SimCLR 论文中提到但未在此处执行的较重的变换之一是高斯模糊。它通过使用高斯函数通过赋予图像的中心部分比其他部分更大的权重来添加噪声来模糊图像。最终的平均效果是减少图像的细节。您也可以选择在 STL-10 图像上执行高斯模糊变换。在新版本的torchvision中,您可以使用以下选项来执行它:#transforms.GaussianBlur(kernel_size=9)。
加载数据集
DATASET_PATH = os.environ.get("PATH_DATASETS", "bookdata/")
CHECKPOINT_PATH = os.environ.get("PATH_CHECKPOINT", "booksaved_models/")在前面的代码片段中,我们定义了数据集和检查点路径。
我们现在将转换应用到 STL-10 数据集并创建它的两个视图:
unlabeled_data = STL10(
root=DATASET_PATH,
split="unlabeled",
download=True,
transform=DataAugTransform(augmentation_transforms, n_views=2),
)
train_data_contrast = STL10(
root=DATASET_PATH,
split="train",
download=True,
transform=DataAugTransform(augmentation_transforms, n_views=2),
)那么它通过应用数据增强过程转换为模型训练的火炬张量。我们可以通过可视化一些图像来验证上述过程的输出:
pl.seed_everything(96)
NUM_IMAGES = 20
imgs = torch.stack([img for idx in range(NUM_IMAGES) for img in unlabeled_data[idx][0]], dim=0)
img_grid = torchvision.utils.make_grid(imgs, nrow=8, normalize=True, pad_value=0.9)
img_grid = img_grid.permute(1, 2, 0)
plt.figure(figsize=(20, 10))
plt.imshow(img_grid)
plt.axis("off")
plt.show()在前面的代码片段中,我们打印了原始图像和增强图像。这应该显示以下结果:

图 8.8 – STL-10 增强图像
正如你可以看到,各种图像变换都已成功应用。同一图像的多个副本将作为模型学习的正对集合。
训练配置
现在我们将设置模型训练的配置,包括超参数、损失函数和编码器。
设置超参数
我们将使用YAML 文件将各种超参数传递给我们的模型训练。拥有 YAML 文件可以轻松创建各种实验:
weight_decay: 10e-6
out_dim: 256
dataset:
s: 1
input_shape: (96,96,3)
num_workers: 4
optimizer:
lr: 0.0001
loss:
temperature: 0.05
use_cosine_similarity: True
lr_schedule:
max_lr: .1
total_steps: 1500
model:
out_dim: 128
base_model: "resnet50"
'''
config = yaml.full_load(config)前面的代码片段将加载 YAML 文件并设置以下超参数:
- batch_size:用于训练的批量大小。
- 时期:运行训练的时期数。
- out_dim:嵌入层的输出维度。
- s:颜色抖动变换的亮度、对比度、饱和度和色调级别。
- 输入形状:最终图像转换后的模型输入形状。所有原始图像都将调整为此形状(H、W、颜色通道)。
- num_workers:用于数据加载器的工人数量。它可以通过预取和处理数据来提高训练速度。
- lr:用于训练的初始学习率。
- temperature:用于平滑损失函数概率的温度调整参数。
- use_cosine_similarity:是否在损失函数中使用余弦相似度的布尔指标。
- max_lr:1cycle 学习率调度程序的最大学习率。
- total_steps:1cycle 学习率调度程序的训练步骤总数。
关于批量大小的重要说明
批量大小在对比学习模型中起着非常重要的作用。在 SimCLR 中,已经观察到具有大批量大小与更好的结果相关联。但是,大批量也需要 GPU 形式的更多计算。
定义损失函数
目的损失函数的目的是帮助区分正负对。原始论文描述了NTXent损失函数。
我们现在将继续在代码中实现这个损失函数:
import yaml # 处理配置文件加载
# 加载配置文件
config = '''
batch_size: 128
epochs: 100
class NTXentLoss(torch.nn.Module):
def __init__(self, device, batch_size, temperature, use_cosine_similarity):
super(NTXentLoss, self).__init__()
self.batch_size = batch_size
self.temperature = temperature
self.device = device
self.softmax = torch.nn.Softmax(dim=-1)
self.mask_samples_from_same_repr = self._get_correlated_mask().type(torch.bool)
self.similarity_function = self._get_similarity_function(use_cosine_similarity)
self.criterion = torch.nn.CrossEntropyLoss(reduction="sum").cuda()
def _get_similarity_function(self, use_cosine_similarity):
if use_cosine_similarity:
self._cosine_similarity = torch.nn.CosineSimilarity(dim=-1)
return self._cosine_simililarity
else:
return self._dot_simililarity
def _get_correlated_mask(self):
diag = np.eye(2 * self.batch_size)
l1 = np.eye((2 * self.batch_size), 2 * self.batch_size, k=-self.batch_size)
l2 = np.eye((2 * self.batch_size), 2 * self.batch_size, k=self.batch_size)
mask = torch.from_numpy((diag + l1 + l2))
mask = (1 - mask).type(torch.bool)
return mask.to(self.device)
@staticmethod
def _dot_simililarity(x, y):
v = torch.tensordot(x.unsqueeze(1), y.T.unsqueeze(0), dims=2)
return v
def _cosine_simililarity(self, x, y):
v = self._cosine_similarity(x.unsqueeze(1), y.unsqueeze(0))
return v
def forward(self, zis, zjs):
representations = torch.cat([zjs, zis], dim=0)
similarity_matrix = self.similarity_function(representations, representations)
# 从正样本中过滤掉分数
l_pos = torch.diag(similarity_matrix, self.batch_size)
r_pos = torch.diag(similarity_matrix, -self.batch_size)
positives = torch.cat([l_pos, r_pos]).view(2 * self.batch_size, 1)
negatives = similarity_matrix[self.mask_samples_from_same_repr].view(2 * self.batch_size, -1)
logits = torch.cat((positives, negatives), dim=1)
logits /= self.temperature
labels = torch.zeros(2 * self.batch_size).to(self.device).long()
loss = self.criterion(logits, labels)
return loss / (2 * self.batch_size)在里面在前面的代码片段中,我们实现了 NTXtent 损失函数,它将测量正对的损失。请记住,模型的任务是最小化正对之间的损失,从而最小化这个损失函数。
定义编码器
我们可以使用任何编码器架构(例如 VGGNet、或 AlexNet、或 ResNet 等)。由于原论文有 ResNet,我们也将使用 ResNet 作为我们的编码器:
class ResNetSimCLR(nn.Module):
def __init__(self, base_model, out_dim, freeze=True):
super(ResNetSimCLR, self).__init__()
# 最后一个线性层的输入特征数
num_ftrs = base_model.fc.in_features
# 移除最后一层resnet
self.features = nn.Sequential(*list(base_model.children())[:-1])
if freeze:
self._freeze()在前面的代码块中,我们移除了 ResNet 的最后一个 softmax 层,并将特征传递给下一个模块。我们可以通过使用 MLP 模型的标头投影代码块来跟进这一点。SimCLR1 有一个单层 MLP,而 SimCLR2 有一个 3 层 MLP,这就是我们将在这里使用的。其他人也取得了不错的成绩2 层 MLP 模型。(请注意,此代码与上述同一类的一部分:)
# 标头投影 MLP - 用于 SimCLR
self.l1 = nn.Linear(num_ftrs, 2*num_ftrs)
self.l2_bn = nn.BatchNorm1d(2*num_ftrs)
self.l2 = nn.Linear(2*num_ftrs, num_ftrs)
self.l3_bn = nn.BatchNorm1d(num_ftrs)
self.l3 = nn.Linear(num_ftrs, out_dim)
def _freeze(self):
num_layers = len(list(self.features.children())) # 9 层,冻结除最后 2 层之外的所有层
current_layer = 1
for child in list(self.features.children()):
if current_layer > num_layers-2:
for param in child.parameters():
param.requires_grad = True
else:
for param in child.parameters():
param.requires_grad = False
current_layer += 1
def forward(self, x):
h = self.features(x)
h = h.squeeze()
if len(h.shape) == 1:
h = h.unsqueeze(0)
x_l1 = self.l1(h)
x = self.l2_bn(x_l1)
x = F.selu(x)
x = self.l2(x)
x = self.l3_bn(x)
x = F.selu(x)
x = self.l3(x)
return h, x_l1, x在里面在前面的代码片段中,我们已经为 ResNet 定义了卷积层,然后冻结了最后一层并将该特征用作投影头模型的输入,这是一个 3 层 MLP。
现在,我们可以从 ResNet 的最后一层或 3 层 MLP 模型的最后一层提取特征,并将其用作模型学习图像的真实表示。
重要的提示
虽然带有 SimCLR 的 ResNet 将作为 STL-10 的预训练模型提供,但如果您正在为另一个数据集尝试 SimCLR 架构,则此代码对于从头开始训练很有用。
SimCLR 管道
现在我们已经为 SimCLR 架构准备好所有构建块,我们终于可以构建 SimCLR 管道了:
class simCLR(pl.LightningModule):
def __init__(self, model, config, optimizer=Adam, loss=NTXentLoss):
super(simCLR, self).__init__()
self.config = config
# Optimizer
self.optimizer = optimizer
# Model
self.model = model
# Loss
self.loss = loss(self.config['batch_size'], **self.config['loss'])
# Prediction/inference
def forward(self, x):
return self.model(x)
# Sets up optimizer
def configure_optimizers(self):
optimizer = self.optimizer(self.parameters(), **self.config['optimizer'])
scheduler = OneCycleLR(optimizer, **self.config["lr_schedule"])
return [optimizer], [scheduler]在前面的代码片段中,我们使用配置文件(字典)将参数传递给每个模块:优化器、损失和lr_schedule。我们正在使用 Adam 优化器并调用我们之前构建的 NTXtent 损失函数。
现在我们可以将训练和验证循环添加到同一个类中:
# Training loops
def training_step(self, batch, batch_idx):
x, y = batch
xis, xjs = x
ris, _, zis = self(xis)
rjs, _, zjs = self(xjs)
zis = F.normalize(zis, dim=1)
zjs = F.normalize(zjs, dim=1)
loss = self.loss(zis, zjs)
return loss
# Validation step
def validation_step(self, batch, batch_idx):
x, y = batch
xis, xjs = x
ris, _, zis = self(xis)
rjs, _, zjs = self(xjs)
zis = F.normalize(zis, dim=1)
zjs = F.normalize(zjs, dim=1)
loss = self.loss(zis, zjs)
self.log('val_loss', loss)
return loss
def test_step(self, batch, batch_idx):
loss = None
return loss
def _get_model_checkpoint():
return ModelCheckpoint(
filepath=os.path.join(os.getcwd(),"checkpoints","best_val_models"),
save_top_k = 3,
monitor="val_loss"
)- 配置文件中的超参数
- NTXtent 作为损失函数
- Adam 作为优化器
- 编码器作为模型(如果需要,可以更改为 ResNet 以外的任何模型)
我们进一步定义了训练和验证循环来计算损失并最终保存模型检查点。
重要的提示
建议您构建一个回调类,它将保存模型检查点并从保存的检查点恢复模型训练。它对于传递编码器的预配置权重也很有用。请参阅 GitHub 或第 10 章了解更多详细信息。
模型训练
我们将首先使用数据加载器来加载数据:
train_loader = DataLoader.DataLoader(
unlabeled_data,
batch_size=128,
shuffle=True,
drop_last=True,
pin_memory=True,
num_workers=NUM_WORKERS,
)
val_loader = DataLoader.DataLoader(
train_data_contrast,
batch_size=128,
shuffle=False,
drop_last=True,
pin_memory=True,
num_workers=NUM_WORKERS,
)我们将使用 ResNet-50 架构作为编码器。您可以使用其他 ResNet 架构,例如 ResNet-18 或 ResNet-152,并比较结果:
resnet = models.resnet50(pretrained=True)
simclr_resnet = ResNetSimCLR(base_model=resnet, out_dim=config['out_dim'])在前面的代码片段中,我们导入了 ResNet CNN 模型架构,并使用pretrained=True来使用模型的预训练权重来加快训练速度。由于 PyTorch ResNet 模型是在 ImageNet 数据集上训练的,而我们的 STL-10 数据集也是从 ImageNet 中抓取的,因此使用预训练的权重是一个合理的选择。
我们现在将启动训练过程:
模型= simCLR(配置=配置,模型=simclr_resnet)
教练 = pl.Trainer()
您应该看到以下信息,具体取决于您使用的硬件:

图 8.9 – 可用于模型训练的 GPU
在前面的代码片段中,我们根据上述架构创建 SimCLR 模型,并使用训练器通过从数据加载器传递数据集来拟合模型:
trainer.fit(model, train_loader, val_loader)这应该向您显示培训过程的以下启动:

图 8.10 – SimCLR 训练过程
这眼尖的你们可能已经注意到它正在使用 NTXent 损失函数。
重要的提示
根据您可以访问的硬件,您可以使用 PyTorch Lightning 框架中的各种选项来加快训练过程。如第 7 章,半监督学习所示,如果您使用的是 GPU,那么您可以使用gpu=-1选项并启用 16 位精度以进行混合模式精度训练。有关扩大培训过程的选项的更多详细信息,请参阅第 10 章。
训练模型后,您可以保存模型权重
torch.save(model.state_dict(), 'weights_only.pth')
torch.save(model.state_dict(), 'weights_only.pth')
torch.save(model, 'entire_model.pth')这会将模型权重保存为“weights_only.pth”,将整个模型保存为“entire_model.pth”
模型评估
虽然SimCLR 模型架构将学习未标记图像的表示,我们仍然需要一种方法来衡量它对这些表示的学习程度。为了做到这一点,我们使用具有一些标记图像(来自原始 STL-10 数据集)的监督分类器,然后我们使用在 SimCLR 模型中学习到的特征将特征图应用于通过表示学习学习到的图像,然后比较结果。
因此,模型评估包括三个步骤:
- 从 SimCLR 模型中提取特征
- 定义分类器
- 预测准确性
我们可以尝试通过传递非常有限数量的标签来比较结果,例如 500 或 5,000(或 1 到 10%),然后也可以将结果与已用 100% 的标签训练的监督分类器进行比较. 这将帮助我们比较我们的自我监督模型从未标记图像中学习表示的能力。
从 SimCLR 模型中提取特征
def _load_resnet_model(checkpoints_folder):
model = torch.load('entire_model.pth')
model.eval()
state_dict = torch.load(os.path.join(checkpoints_folder, 'weights_only.pth'), map_location=torch.device(device))
model.load_state_dict(state_dict)
model = model.to(device)
return model此代码片段将从 weights_only.pth 加载预训练的 SimCLR 模型权重,从 whole_model.pth 加载整个模型。
def get_stl10_data_loaders(download, shuffle=False, batch_size=128):
train_dataset = datasets.STL10('./data', split='train',
download=download,
transform=transforms.
ToTensor())
train_loader = DataLoader.DataLoader(train_dataset, batch_size=batch_size,num_workers=4, drop_last=False,
shuffle=shuffle)
test_dataset = datasets.STL10('./data', split='test',
download=download,
transform=transforms.
ToTensor())
test_loader = DataLoader.DataLoader(test_dataset, batch_size=batch_size,
num_workers=4, drop_last=False,
shuffle=shuffle)
return train_loader, test_loader我们现在可以定义特征提取器类:
class ResNetFeatureExtractor(object):
def __init__(self, checkpoints_folder):
self.checkpoints_folder = checkpoints_folder
self.model = _load_resnet_model(checkpoints_folder)
def _inference(self, loader):
feature_vector = []
labels_vector = []
for batch_x, batch_y in loader:
batch_x = batch_x.to(device)
labels_vector.extend(batch_y)
features, _ = self.model(batch_x)
feature_vector.extend(features.cpu().detach().numpy())
feature_vector = np.array(feature_vector)
labels_vector = np.array(labels_vector)
print("Features shape {}".format(feature_vector.shape))
return feature_vector, labels_vector
def get_resnet_features(self):
train_loader, test_loader = get_stl10_data_loaders(download=True)
X_train_feature, y_train = self._inference(train_loader)
X_test_feature, y_test = self._inference(test_loader)
return X_train_feature, y_train, X_test_feature, y_test在里面前面的代码片段,我们得到了从我们训练的 ResNet 模型中提取的特征。我们可以通过打印文件的形状来验证这一点:
checkpoints_folder = ''
resnet_feature_extractor = ResNetFeatureExtractor(checkpoints_folder)
X_train_feature, y_train, X_test_feature, y_test = resnet_feature_extractor.get_resnet_features()您应该看到以下输出,其中显示了训练和测试文件的形状:
Files already downloaded and verified
Files already downloaded and verified
Features shape (5000, 2048)
Features shape (8000, 2048)现在我们准备好了,我们可以定义监督分类器,在自监督特征之上训练监督模型。
有监督的分类器
我们可以为此任务使用任何监督分类器,例如 MLP 或逻辑回归。在本模块中,我们将选择逻辑回归。在本节中,我们使用 scikit-learn 模块来实现逻辑回归。
我们首先定义LogisticRegression类:
import torch.nn as nn
class LogisticRegression(nn.Module):
def __init__(self, n_features, n_classes):
super(LogisticRegression, self).__init__()
self.model = nn.Linear(n_features, n_classes)
def forward(self, x):
return self.model(x)class LogiticRegressionEvaluator(object):
def __init__(self, n_features, n_classes):
self.log_regression = LogisticRegression(n_features, n_classes).to(device)
self.scaler = preprocessing.StandardScaler()
def _normalize_dataset(self, X_train, X_test):
print("Standard Scaling Normalizer")
self.scaler.fit(X_train)
X_train = self.scaler.transform(X_train)
X_test = self.scaler.transform(X_test)
return X_train, X_test
def _sample_weight_decay():
weight_decay = np.logspace(-7, 7, num=75, base=10.0)
weight_decay = np.random.choice(weight_decay)
print("Sampled weight decay:", weight_decay)
return weight_decay
def eval(self, test_loader):
correct = 0
total = 0
with torch.no_grad():
self.log_regression.eval()
for batch_x, batch_y in test_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
logits = self.log_regression(batch_x)
predicted = torch.argmax(logits, dim=1)
total += batch_y.size(0)
correct += (predicted == batch_y).sum().item()
final_acc = 100 * correct / total
self.log_regression.train()
return final_acc- 我们首先对数据集进行规范化。
- 然后我们从 10−7 到 107 之间的 75 个对数间隔值定义 L2 正则化参数。这是一个可以调整的设置。
- 我们还定义了如何在final_acc参数中测量准确性。
我们现在可以为分类器提供数据加载器并要求它拾取模型:
def create_data_loaders_from_arrays(self, X_train, y_train, X_test, y_test):
X_train, X_test = self._normalize_dataset(X_train, X_test)
train = torch.utils.data.TensorDataset(torch.from_numpy(X_train), torch.from_numpy(y_train).type(torch.long))
train_loader = torch.utils.data.DataLoader(train, batch_size=128, shuffle=False)
test = torch.utils.data.TensorDataset(torch.from_numpy(X_test), torch.from_numpy(y_test).type(torch.long))
test_loader = torch.utils.data.DataLoader(test, batch_size=128, shuffle=False)
return train_loader, test_loader您也可以定义test_loader,就像我们在此处定义的train_loader一样。我们现在将为优化器定义超参数:
def train(self, X_train, y_train, X_test, y_test):
train_loader, test_loader = self.create_data_loaders_from_arrays(X_train, y_train, X_test, y_test)
weight_decay = self._sample_weight_decay()
optimizer = torch.optim.Adam(self.log_regression.parameters(), 3e-4, weight_decay=weight_decay)
criterion = torch.nn.CrossEntropyLoss()
best_accuracy = 0
for e in range(200):
for batch_x, batch_y in train_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
optimizer.zero_grad()
logits = self.log_regression(batch_x)
loss = criterion(logits, batch_y)
loss.backward()
optimizer.step()
epoch_acc = self.eval(test_loader)
if epoch_acc > best_accuracy:
#print("Saving new model with accuracy {}".format(epoch_acc))
best_accuracy = epoch_acc
torch.save(self.log_regression.state_dict(), 'log_regression.pth')在里面在前面的代码片段中,我们使用逻辑回归模型来训练分类器,使用 Adam 作为优化器,交叉熵损失作为损失函数,只保存精度最高的模型。我们现在准备执行模型评估。
预测准确性
log_regressor_evaluator = LogiticRegressionEvaluator(n_features=X_train_feature.shape[1], n_classes=10)
log_regressor_evaluator.train(X_train_feature, y_train, X_test_feature, y_test)逻辑回归模型应该告诉您模型对从自监督架构中学习到的特征执行的准确度:

图 8.11 – 准确度结果
如您所见,我们在逻辑回归模型上获得了 73% 的准确率。
准确率反映了以完全无监督的方式学习的特征,没有任何标签。我们将这些学习到的特征与传统分类器进行了比较,就好像存在标签一样。然后,通过传递一小部分标签,我们可以获得与标记数据集相当的准确度。如前所述,通过更好的训练能力,你可以达到原论文中提到的结果,即 95% 的准确率,只需 1% 的标签。
强烈建议您通过改变标记训练集的数量并将其与所有标签的完整训练进行比较来重复评估步骤。这将有助于展示自我监督学习的巨大力量。
下一步
虽然我们只构建了一个监督分类器来使用从 SimCLR 模型中学习到的特征,但 SimCLR 模型实用程序并不限于此。您可以以各种其他方式使用从未标记图像中学习的表示:
除此之外,您还可以尝试调整 SimCLR 架构代码并构建新模型。以下是一些调整架构的方法:
- 您可以尝试使用其他监督分类器进行微调,例如 MLP,并比较结果。
- 尝试使用其他编码器架构(例如 ResNet-18、ResNet-152 或 VGG)进行模型训练,看看是否能更好地表示特征。
- 您也可以尝试从头开始训练,尤其是当您将其用于另一个数据集时。找到一组未标记的图像不应该是一个挑战。您始终可以将一些相似类的 ImageNet 标签用作微调评估分类器的验证标签,或者手动标记少量并查看结果。
- 目前,SimCLR 架构使用 NTXent 损失函数。如果你有信心,你可以使用不同的损失函数。
- 尝试使用生成对抗网络( GAN ) 中的一些损失函数来混合和匹配 GAN自我监督表示可以是一个令人兴奋的研究项目。
最后,不要忘记 SimCLR 只是对比学习的众多架构之一。PyTorch Lightning 还内置了对其他架构的支持,例如 CPC、SWAV 和 BYOL。您也应该尝试一下,并将结果与 SimCLR 进行比较。
概括
自然界或工业中存在的大多数图像数据集都是未标记的图像数据集。想想诊断实验室生成的 X 射线图像,或者 MRI 或牙科扫描等等。亚马逊评论中生成的图片或来自谷歌街景或 eBay 等电子商务网站的图片也大多没有标签;还有很大一部分 Facebook、Instagram 或 WhatsApp 图像从未标记,因此也没有标记。由于当前的建模技术需要大量手动标记集,因此许多这些图像数据集仍未使用且具有未开发的潜力。消除对大型标记数据集的需求并扩展可能的领域是自我监督学习。
我们在本章中看到了如何使用 PyTorch Lightning 快速创建自我监督学习模型,例如对比学习。事实上,PyTorch Lightning 是第一个为许多自监督学习提供开箱即用支持的框架楷模。我们使用 PyTorch Lightning 实现了 SimCLR 架构,并使用内置功能轻松创建了一个在 TensorFlow 或 PyTorch 上花费大量精力的模型。我们还看到,该模型在标签数量有限的情况下表现得非常好。只需标记 1% 的数据集,我们就获得了与使用 100% 标记集相当的结果。我们可以纯粹通过学习它们的表示来区分未标记的图像。这种表示学习方法使其他方法能够识别集合中的异常图像或自动将图像聚类在一起。自我监督学习方法,如 SimCLR,目前被认为是深度学习中最先进的方法之一。
到目前为止,我们已经看到了深度学习中所有流行的架构,从 CNN 开始,到 GAN,然后是半监督学习,最后是自监督学习。我们现在将把重点从训练模型转移到部署它们。在下一章中,我们将了解如何将模型投入生产,并熟悉部署和评分模型的技术。
相关文章
- spring学习笔记(2)文件资源访问接口Resource
- V-rep学习笔记:Reflexxes Motion Library 1
- alipay 的基础知识学习
- LARK BOARD开发板入门学习-第2篇
- pytorch的学习资源
- Coursera台大机器学习课程笔记11 -- Nonlinear Transformation
- Knockout.Js官网学习(options绑定)
- redis源码学习
- JavaScript学习(一)
- SAP Spartacus SSR学习笔记 - 如何启用SAP Spartacus服务器端渲染模式
- es6学习笔记(四)箭头函数
- 【Pytorch深度学习实战】(7)深度残差网络(DRN)
- Python学习49:使用枚举类
- Android学习-应用程序管理
- Docker镜像原理学习理解
- Android开发最佳学习路线图
- 3-16日学习记录
- PyTorch学习笔记(六):PyTorch进阶训练技巧
- PyTorch学习笔记(二):PyTorch简介与基础知识
- 【深度学习】Pytorch面试题:什么是 PyTorch?PyTorch 的基本要素是什么?Conv1d、Conv2d 和 Conv3d 有什么区别?
- 【深度学习】TensorFlow面试题:什么是TensorFlow?你对张量了解多少?TensorFlow有什么优势?TensorFlow比PyTorch有什么不同?该如何选择?
- 【飞桨PaddlePaddle】迁移学习快速入门,完整源码+讲解演示
- PyTorch 深度学习:60分钟快速入门
- pytorch 21 各种学习率调度器的使用
- pytorch 15 模型性能分析,从loss出发到具体数据(以语义分割为例,实现深度学习中的手工TomeLinks方法)
- GIT 命令学习总结导航
- Pytorch模型训练实用教程学习笔记:一、数据加载和transforms方法总结
- pytorch学习笔记(九):卷积神经网络CNN(基础篇)
- pytorch学习笔记(一):线性模型
- 高性能异步爬虫概述_学习总结