
Uformer: A General U-Shaped Transformerfor Image Restoration
目录
(2)Bottleneck stage(图一,最下面的两个LeWin Transformer blocks)
1.Window-based Multi-head Self-Attention (W-MSA).
Locally-enhanced Feed-Forward Network (LeFF).
3.3 Variants of Skip-Connection
1.Concatenation-based Skip-connection (Concat-Skip).
2.Cross-attention as Skip-connection (Cross-Skip)
3.Concatenation-based Cross-attention as Skip-connection (ConcatCross-Skip).
Limitation and Broader Impacts.
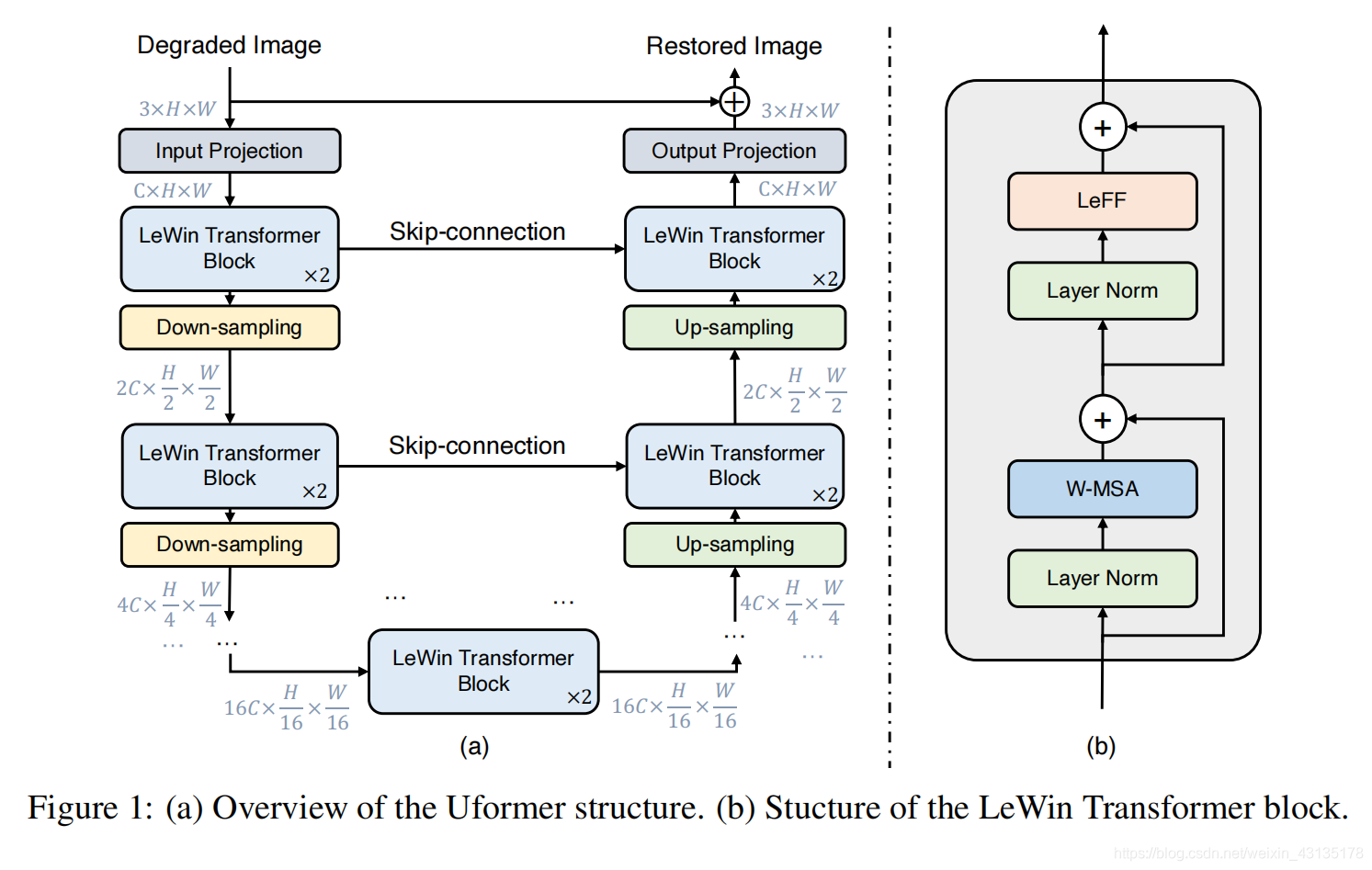
(1)Encoder
For example,given the input feature maps X0 ∈ RC×H×W , the l-th stage of the encoder produces the feature maps ![]()

(2)Bottleneck stage(图一,最下面的两个LeWin Transformer blocks)
4.Then, a bottleneck stage with a stack of LeWin Transformer blocks is added at the end of the encoder. In this stage, thanks to the hierarchical structure, the Transformer blocks capture longer (even global when the window size equals the feature map size) dependencies.
(3)Decoder
2.After that, the features inputted to the LeWin Transformer blocks are the up-sampled features and the corresponding features from the encoder through skip-connection.Next, the LeWin Transformer blocks are utilized to learn to restore the image.
3.After the K decoder stages, we reshape the flattened features to 2D feature maps and apply a 3 × 3 convolution layer to obtain a residual image R ∈ R3×H×W.
4.Finally, the restored image is obtained by I' = I + R.
remark:In our experiments, we empirically set K = 4 and each stage contains two LeWin Transformer blocks. We train Uformer using the Charbonnier loss.
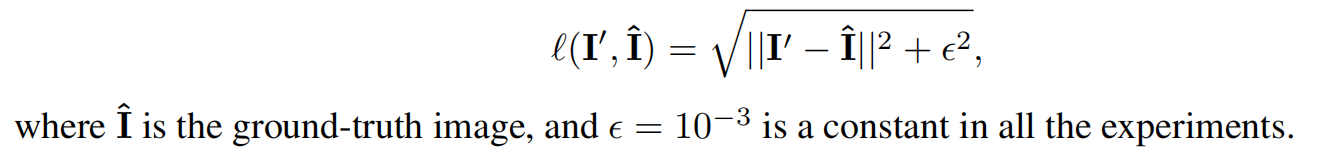

LeWin Transformer Block
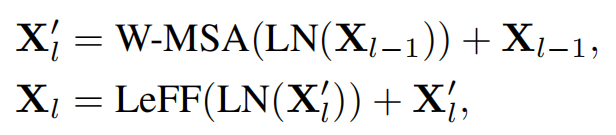
- where X'l and Xl are the outputs of the W-MSA module and LeFF module respectively.
- LN represents the layer normalization.
解释:
接下来介绍下这个 LeWin Transformer Block 的机制。传统的 Transformer在计算 self-attention 时会计算全部 tokens 之间的attention,假设序列长度是 N,即有 N 个 tokens,Embedding dimension为 d ,则计算复杂度是O(N*N*d) 。因为分类任务的图片大小一般是224×224,当我们把图片分块成16×16大小的块时,可以分成196(224*224/16*16 = 196)个patches,token数就是196。
但是对于 Image Restoration 的任务一般都是高分辨率的图片,比如1048×1048的图片,此时得到的patches数量会很多,如果还计算全部 tokens 之间的attention的话,计算量开销会变得很大,显然不合适。所以第1个结论是:计算全部 tokens 之间的 attention 是不合适的。
另外,对于 Image Restoration 的任务local的上下文信息很重要。那么什么是local的上下文信息呢?就是一个patch的上下左右patch的信息。那么为什么local的上下文信息信息很重要呢?因为一个 degraded pixel 的邻近 pixel 可以帮助这个 pixel 完成重建。所以第2个结论是:每个 patch 的 local 的上下文信息很重要。
为了解决第1个问题,作者提出了一种 locally-enhanced window (LeWin) 的 Transformer Block,如上图2(b)所示。它既得益于 Self-attention 的建模长距离信息的能力,也得益于卷积网络的捕获局部信息的本领
1.Window-based Multi-head Self-Attention (W-MSA).

4.Then the outputs for all heads {1, 2, . . . , k} are concatenated and then linearly projected to get the final result.
这个模块是LeWin Transformer Block 的第1步。具体而言,它不使用全部的 tokens 来做 Self-attention,而是在不重叠的局部窗口 (non-overlapping local windows) 里面去做attention,以减少计算量。
问:Window-based Multi-head Self-Attention (W-MSA)能够节约多少计算量?


作用:
- significantly reduce the computational cost compared with global self-attention
- at low resolution feature maps works on larger receptive fields and is sufficient to learn long-range dependencies.

Locally-enhanced Feed-Forward Network (LeFF).
3.Then we flatten the features to tokens and shrink the channels via another linear layer to match the dimension of the input channels.
4. We use GELU [ 52 ] as the activation function after each linear/convolution layer.
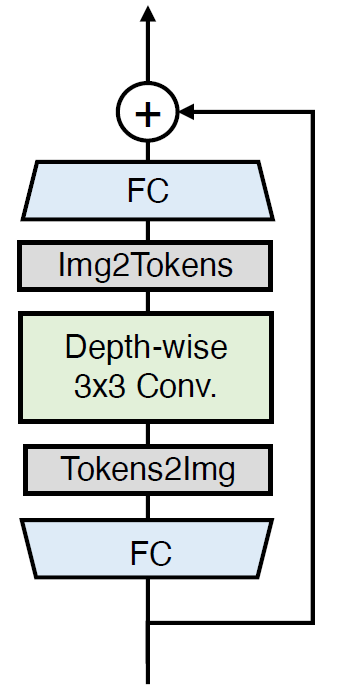
Feed-Forward Network (FFN) 利用局部上下文信息的能力有限。但是相邻像素的信息却对图像复原的任务来讲很重要,因此作者仿照之前的做法在FFN中添加了 Depth-wise Convolution,如图所示。
- 1.首先特征通过一个 FC 层来增大特征的维度 (feature dimension),
- 2.再把序列化的1D特征 reshape 成 2D的特征,
- 3.并通过 3×3 的 Depth-wise Convolution来建模 local 的信息。
- 4.再把2D的特征 reshape 成序列化的1D特征,
- 5.并通过一个 FC 层来减少特征的维度到原来的值,每一个 FC 层或 Depth-wise 卷积层后使用 GeLU 激活函数。
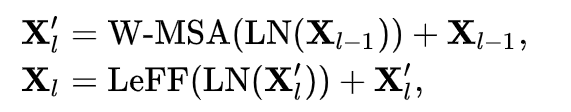
综上,locally-enhanced window (LeWin) 的过程可以用上式表达
3.3 Variants of Skip-Connection
To investigate how to deliver the learned low-level features from the encoder to the decoder
1.Concatenation-based Skip-connection (Concat-Skip).
2.Then, we feed the concatenated features to the W-MSA component of the first LeWin Transformer block in the decoder stage, as shown in Figure 2(c.1).

2.Cross-attention as Skip-connection (Cross-Skip)
2.The first self-attention module in this block (the shaded one) is used to seek the self-similarity pixel-wisely from the decoder features D l − 1, and the second attention module in this block takes the features E l from the encoder as the keys and values, and uses the features from the first module as the queries .
3.Concatenation-based Cross-attention as Skip-connection (ConcatCross-Skip).
Combining above two variants, we also design another skip-connection.As illustrated in Figure 2(c.3),
we concatenate the features El from the encoder and Dl−1 from the decoder as the keys and values, while the queries are only from the decoder.
为了研究如何把 Encoder 里面的 low-level 的特征更好地传递给 Decoder,作者探索了3种Skip-Connection的方式,分别是:
- Concatenation-based Skip-connection (Concat-Skip).
- Cross-attention as Skip-connection (Cross-Skip)
- Concatenation-based Cross-attention as Skip-connection (Concat Cross-Skip)
名字听上去非常花里胡哨,但其实很直觉,如下图5所示。


5 Conclusions
Limitation and Broader Impacts.
Thanks to the proposed structure, Uformer achieves the state-of-the-art performance on a variety of image restoration tasks (image denoising, deraining, deblurring, and demoireing). We have not tested Uformer for more vision tasks such as image-to-image translation, image super-resolution, and so on. We look forward to investigating Uformer for more applications. Meanwhile we notice that there are several negative impacts caused by abusing image restoration techniques. For example, it may cause human privacy issue with the restored images in surveillance. Meanwhile, the techniques may destroy the original patterns for camera identification and multi-media copyright [65], which hurts the authenticity for image forensics.
小结
Uformer 是 2 个针对图像复原任务 (Image Restoration) 的 Transformer 模型,它的特点是长得很像 U-Net (医学图像分割的经典模型),有Encoder,有Decoder,且 Encoder 和 Decoder 之间还有 Skip-Connections。另外,在 Transformer 的 LeWin Transformer Block 中包含2个结构,一个是W-MSA,就是基于windows的attention模块,另一个是LeFF,就是融入了卷积的FFN。
相关文章
- 系统重装 Ghost系统的disk to image等等是什么意思
- Deep Residual Learning for Image Recognition(MSRA-深度残差学习)
- [Docker] Handcrafting a Container Image
- [CSS] Control Image Aspect Ratio Using CSS (object-fit)
- [CSS3] Apply Image Filter Effects With CSS
- [CSS] Control Image Aspect Ratio Using CSS (object-fit)
- 【译】UNIVERSAL IMAGE LOADER. PART 3---ImageLoader详解
- cs231n-2022-assignment1#Q5:Higher Level Representations: Image Features
- 配置.dockerignore文件以排除路径,避免打包进image镜像文件
- Atitit 图像资料文档分类器 netpic image 网络图片与人像图片分类 微信图片分类 D:0workspaceatiplat_imgsrccomattilaximgut
- Unity技术手册-UGUI零基础详细教程-Image图片
- 不编译只打包system或者vendor image命令
- PyQt之Eric:成功解决No module named 'my_image_rc'
- CV之IG:图像生成(Image Generation)的简介、使用方法、案例应用之详细攻略
- Py之scikit-image:Python库之skimage的简介、安装、使用方法之详细攻略
- Hlacon 之Image ,Region,XLD
- 【FastGAN】★Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis
- Accurate prediction of molecular targets using a self-supervised image rep...(论文解读)
- 【Paper】StyTr2: Image Style Transfer with Transformers
- (SRNTT)Image Super-Resolution by Neural Texture Transfer