
《深度学习》李宏毅 -- task3误差和梯度下降
1. 误差的来源
如果我们想要更具针对性的优化我们的算法,我们便需要知道我们的误差到底来自于哪里
首先,我们要知道:
e r r o r = b i a s + v a r i a n c e error = bias + varianceerror=bias+variance
1.1 error (误差)
- 反映的是整个模型的准确度
1.2 bias(偏差)
- 反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度
1.3 variance (方差)
- 反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。
1.4 举例说明
- 目标:打靶打到10环
- 事实:打了7环
- 原因:
- 瞄准出问题,假如瞄准时瞄准的是8环,那么此时b i a s = 2 bias = 2bias=2,反映的是模型期望与真实值的差距
- 枪自身稳定性的问题:瞄准的是8环,但打到的是7环,此时v a r i a n c e = 1 variance = 1variance=1,反映的是由于模型自身稳定性的问题造成实际结果与模型期望之间的差距
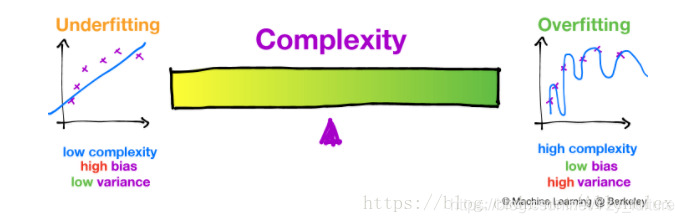
1.5 偏差方差困境
- 基本原理:无法同时降低偏差和方差,只能在两者之间取得平衡。
- 解释:如果你想降低偏差,那么你就要增加模型的复杂度,从而能够更好的拟合所给的数据,防止欠拟合的产生。但是,如果此时的模型过于复杂,便会导致过拟合的产生,从而导致模型的泛化性能的下降。所以,需要找到一个两者的平衡点。
- 如下图所示:
2 估测
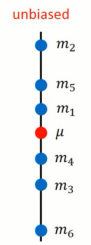
2.1 估测X的偏差
2.1.1 估测平均值
- 拿到N个样本点x 1 , x 2 , . . . x n {x^1, x ^2, ... x^n}x1,x2,...xn
- 计算N个样本的平均值m mm
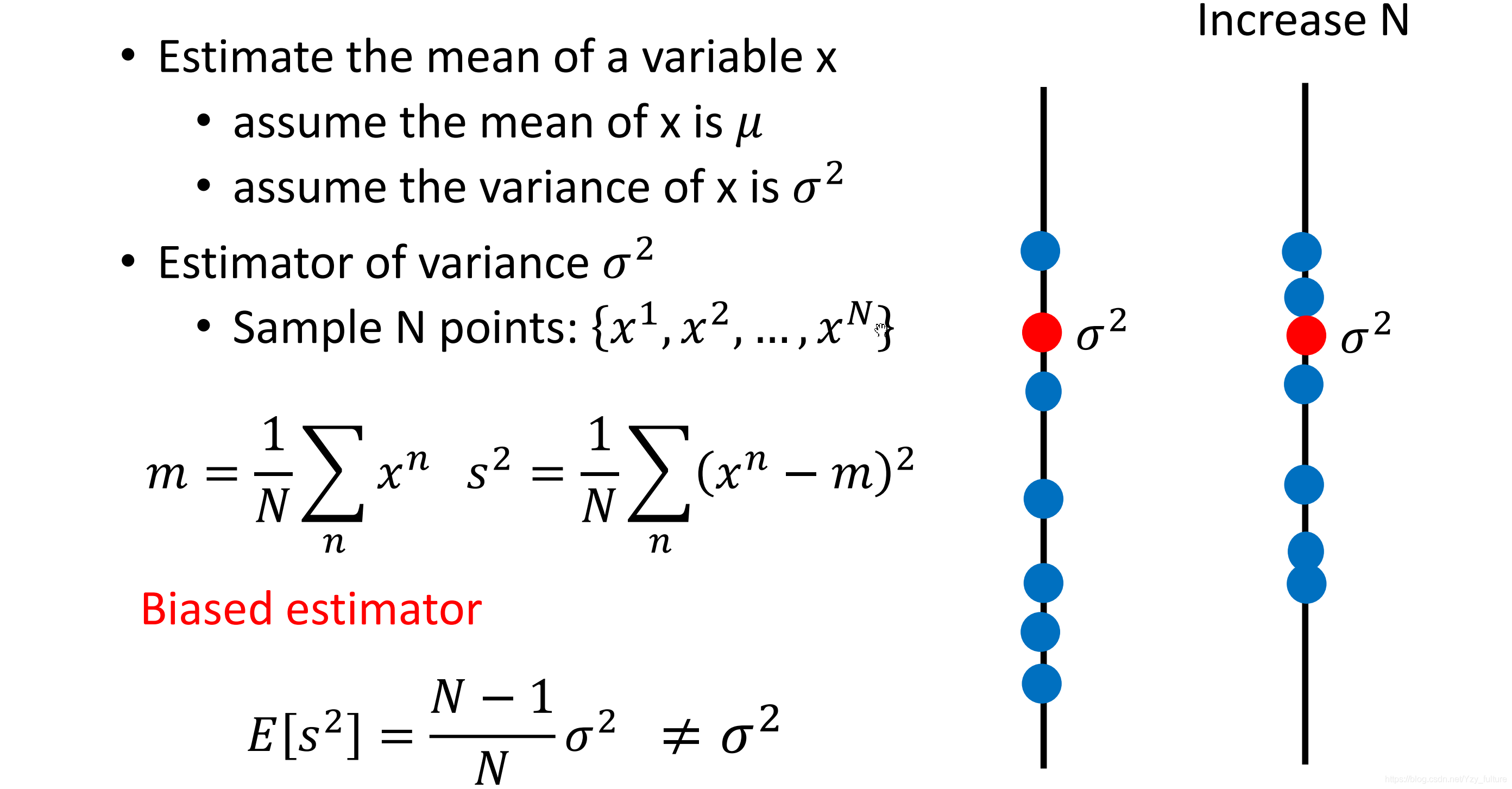
2.1.2 估测方差
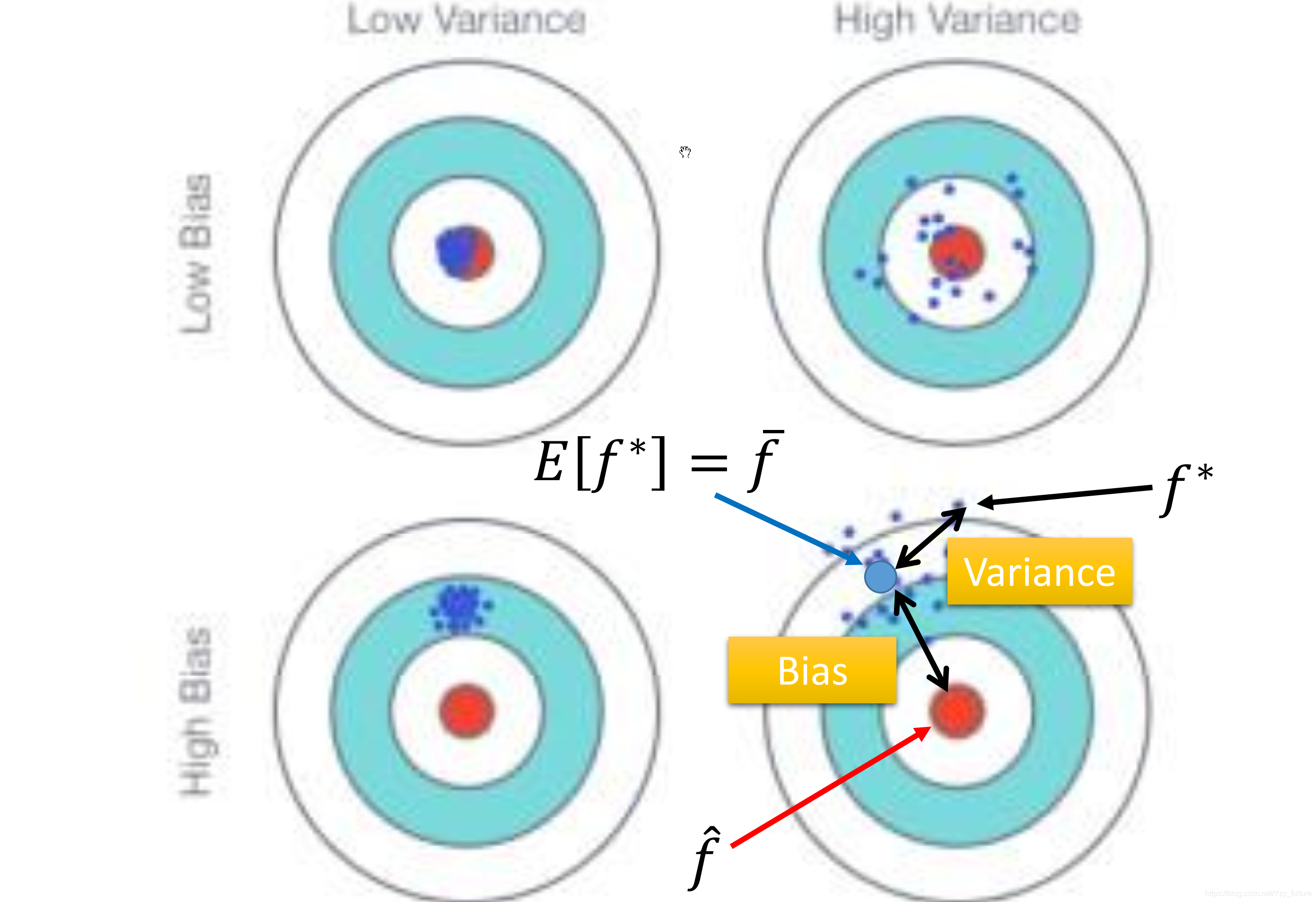
2.2 为什么会有多个模型
由于训练集的不同,会导致使用同一个模型所找到的f ∗ f^*f∗不同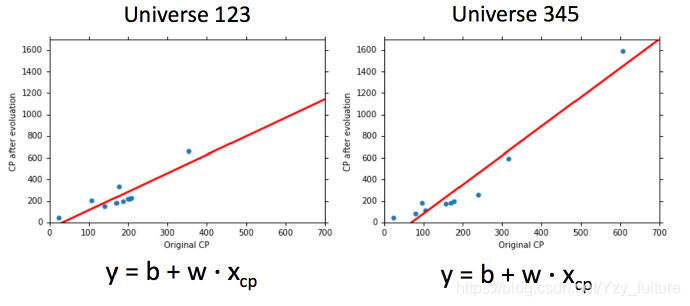
同时,使用不同的模型,使用同一个训练集找到的f ∗ f^*f∗也不同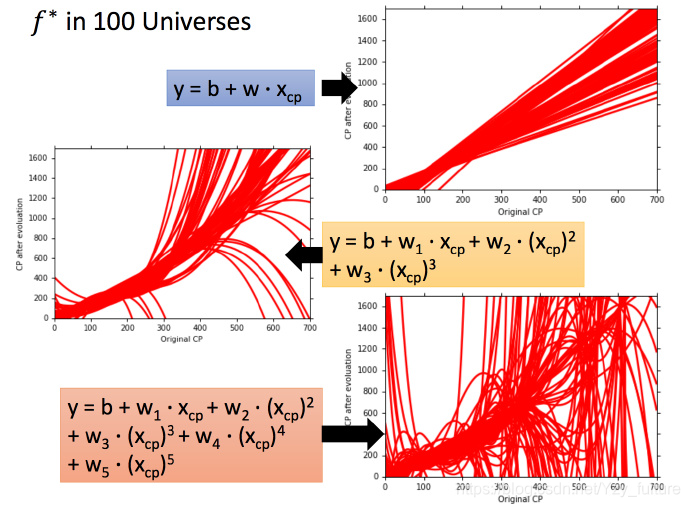
3 判断分析
3.1 欠拟合-偏差大
- 原因:模型的假设空间中并不包含事实
- 解决方法:重新设计模型
- 加入更多的函数
- 考虑更高次的幂、更复杂的模型
- 不建议收集更多数据来解决(事实并不在假设空间中)
3.2 过拟合
- 原因:学习能力过强
- 解决方法:
- 收集更多的数据
- 降低模型的复杂度
4 比较检验
4.1 交叉验证
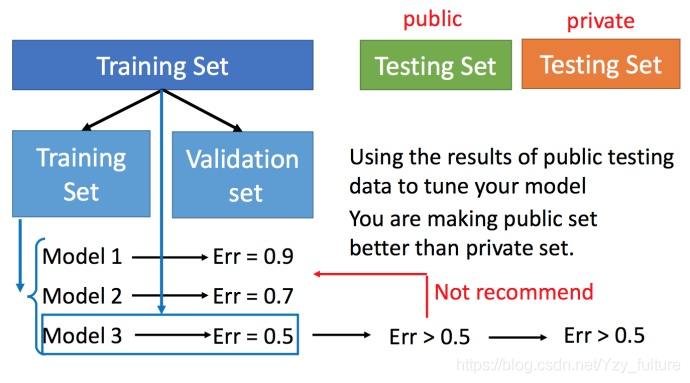
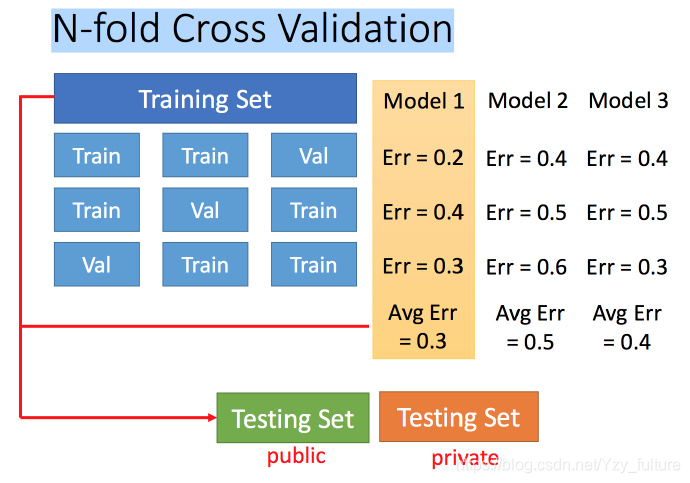
4.2 N折交叉验证
5. 梯度下降
将梯度下降算法进行可视化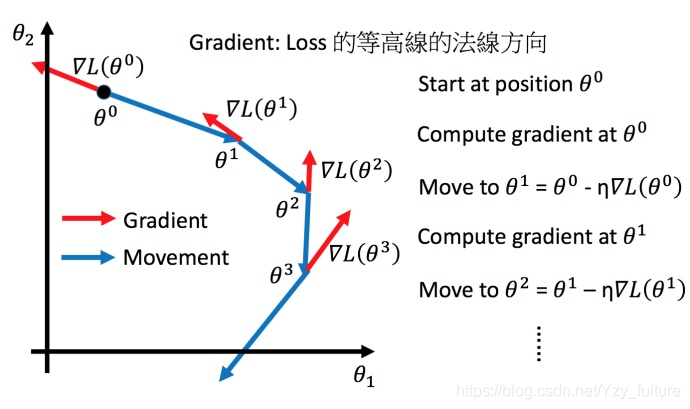
5.1 学习率的调整(η \etaη)
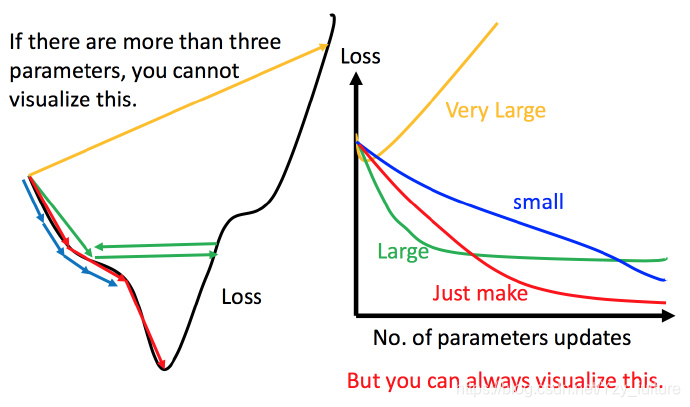
5.1.1 一般学习率的调整
- 学习率调整的刚刚好:红色的线,就能顺利找到最低点。
- 学习率调整的太小:比如蓝色的线,就会走的太慢,虽然这种情况给足够多的时间也可以找到最低点,实际情况可能会等不及出结果。
- 学习率调整的有点大:比如绿色的线,就会在上面震荡,走不下去,永远无法到达最低点。
- 非常大,比如黄色的线,直接就飞出去了,更新参数的时候只会发现损失函数越更新越大。
5.1.2 自适应调整学习率
- 原因:我们想要在开始的时候学习率大一点从而增大步长,随着迭代次数的增加不断地减小步长,从而能够是我们能够更快的收敛到最优解。
- 通常刚开始,初始点会距离最低点比较远,所以使用大一点的学习率
- update好几次参数之后呢,比较靠近最低点了,此时减少学习率
-
Adagrad 算法
- 是什么:每个参数的学习率都把它除上之前微分的均方根
- 解释:
- 普通的梯度下降为:
w t + 1 = w t − η t g t w^{t+1} = w^t - \eta^tg^twt+1=wt−ηtgt
η t = η t t + 1 \eta^t = \frac{\eta^t }{\sqrt{t+1}}ηt=t+1ηt - 而adagrad算法可以做的更好
w t + 1 = w t − η t σ t g t w^{t+1} = w^t - \frac{\eta^t }{\sigma^t}g^twt+1=wt−σtηtgt
g t = ∂ L ( θ t ) ∂ w g^t = \frac{\partial{L(\theta^t)}}{\partial w}gt=∂w∂L(θt)
- 普通的梯度下降为:
- 矛盾:
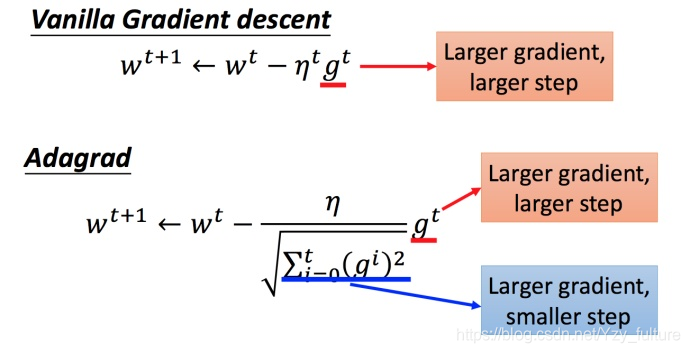
梯度越大的时候,步伐应该越大,但下面分母又导致当梯度越大的时候,步伐会越小
解释: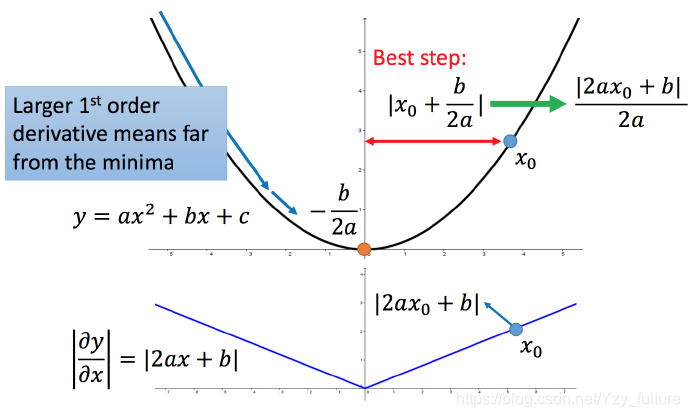
比如初始点在x 0 x_0x0,最低点为 − b 2 a −\frac{b}{2a}−2ab,最佳的步伐就是 x0x0 到最低点之间的距离∣ x 0 + b 2 a ∣ |x_0 + \frac{b}{2a}|∣x0+2ab∣。而∣ 2 a x 0 + b ∣ |2ax_0 +b|∣2ax0+b∣就是方程绝对值在x 0 x_0x0这一点的微分。
这样可以认为如果算出来的微分越大,则距离最低点越远。而且最好的步伐和微分的大小成正比。所以如果踏出去的步伐和微分成正比,它可能是比较好的。
从而得出结论:梯度越大,就跟最低点的距离越远。
但结论在多个参数的时候就不一定成立
5.2 随机梯度下降法
特点:损失函数不需要处理训练集所有的数据,选取一个例子x n x^nxn即可。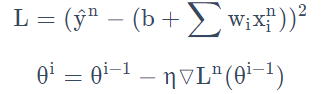
不需要像之前那样对所有的数据进行处理,只需要计算某一个例子的损失函数L n L_nLn,就可以赶紧更新梯度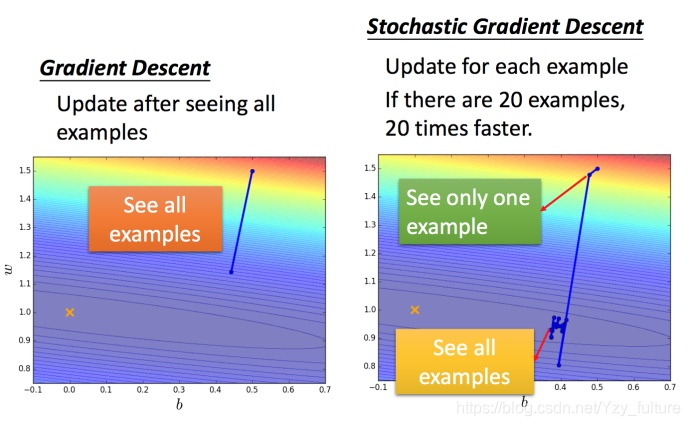
5.3 特征缩放
将具有不同输入范围的输入范围进行缩放,使得不同输入的范围一样
5.3.1 缩放的原因
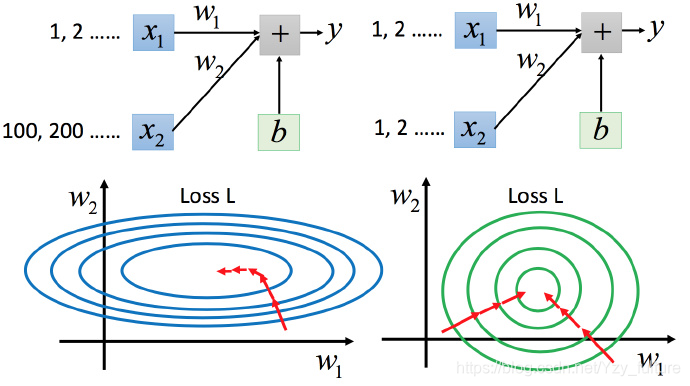
- 为了使不同的特征值对输出的影响相近
- 为了使梯度下降时参数的更新更加容易、有效。
5.3.2 特征缩放的方法
下面为较为常见的一种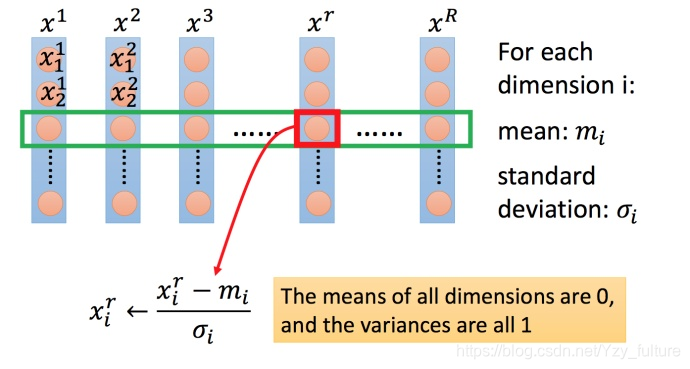
- 对每一个维度i ii(绿色框)都计算平均数,记做m i m_imi;计算标准差,记做σ i \sigma_iσi.
- 然后用第r rr个例子中的第i ii个输入,减掉平均数m i m_imi ,然后除以标准差σ i \sigma_iσi,得到的结果是所有的维数都是 0,所有的方差都是.
补充:
偏差和方差
方差:方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
偏差: 期望输出与真实标记的差别称为偏差(bias),即: 偏差的含义:偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力
偏差、方差与bagging、boosting的关系?
Bagging算法是对训练样本进行采样,产生出若干不同的子集,再从每个数据子集中训练出一个分类器,取这些分类器的平均,所以是降低模型的方差(variance)。Bagging算法和Random Forest这种并行算法都有这个效果。
Boosting则是迭代算法,每一次迭代都根据上一次迭代的预测结果对样本进行权重调整,所以随着迭代不断进行,误差会越来越小,所以模型的偏差(bias)会不断降低。
如何解决偏差、方差问题?
整体思路:首先,要知道偏差和方差是无法完全避免的,只能尽量减少其影响。
(1)在避免偏差时,需尽量选择正确的模型,一个非线性问题而我们一直用线性模型去解决,那无论如何,高偏差是无法避免的。
(2)有了正确的模型,我们还要慎重选择数据集的大小,通常数据集越大越好,但大到数据集已经对整体所有数据有了一定的代表性后,再多的数据已经不能提升模型了,反而会带来计算量的增加。而训练数据太小一定是不好的,这会带来过拟合,模型复杂度太高,方差很大,不同数据集训练出来的模型变化非常大。
(3)最后,要选择合适的模型复杂度,复杂度高的模型通常对训练数据有很好的拟合能力。
针对偏差和方差的思路:
偏差:实际上也可以称为避免欠拟合。
1、寻找更好的特征 – 具有代表性。
2、用更多的特征 – 增大输入向量的维度。(增加模型复杂度)
方差:避免过拟合
1、增大数据集合 – 使用更多的数据,减少数据扰动所造成的影响
2、减少数据特征 – 减少数据维度,减少模型复杂度
3、正则化方法
4、交叉验证法
随机梯度下降法
在梯度下降法中,批量指的是用于在单次迭代中计算梯度的样本总数。到目前为止,我们一直假定批量是指整个数据集。就 Google 的规模而言,数据集通常包含数十亿甚至数千亿个样本。此外,Google 数据集通常包含海量特征。因此,一个批量可能相当巨大。如果是超大批量,则单次迭代就可能要花费很长时间进行计算。
包含随机抽样样本的大型数据集可能包含冗余数据。实际上,批量大小越大,出现冗余的可能性就越高。一些冗余可能有助于消除杂乱的梯度,但超大批量所具备的预测价值往往并不比大型批量高。
如果我们可以通过更少的计算量得出正确的平均梯度,会怎么样?通过从我们的数据集中随机选择样本,我们可以通过小得多的数据集估算(尽管过程非常杂乱)出较大的平均值。 随机梯度下降法 (SGD) 将这种想法运用到极致,它每次迭代只使用一个样本(批量大小为 1)。如果进行足够的迭代,SGD 也可以发挥作用,但过程会非常杂乱。“随机”这一术语表示构成各个批量的一个样本都是随机选择的。
小批量随机梯度下降法(小批量 SGD)是介于全批量迭代与 SGD 之间的折衷方案。小批量通常包含 10-1000 个随机选择的样本。小批量 SGD 可以减少 SGD 中的杂乱样本数量,但仍然比全批量更高效。
梯度下降学习理论参考:
参考资料:
李宏毅机器学习笔记 3.误差和梯度下降_Simone Zeng的博客-CSDN博客
误差和梯度下降(李宏毅深度学习task 3)_Yzy_fulture的博客-CSDN博客
相关文章
- [转载] 机器学习面试之算法思想简单梳理
- Linux学习之文件属性chattr权限与sudo权限(十二)
- Python学习--21 电子邮件
- Python学习--11 面向对象高级编程
- java学习笔记13--反射机制与动态代理
- 学习8个简单步骤让你成为数据科学家
- linux shell 脚本攻略学习13--file命令详解,diff命令详解
- 前端学习 -- Html&Css -- 表单
- 转-[Python 学习]2.5版yield之学习心得
- jsp学习--JavaBean定义和在Jsp中使用JavaBean
- jsp学习--如何定位错误和JSP和Servlet的比较
- jsp学习--基本语法和基础知识
- Java -- JDBC 学习--通过Statement进行数据库更新操作
- 前端学习 -- 超链接
- 机器学习--详解人脸对齐算法SDM-LBF
- Hadoop参考学习
- c++模板学习12之通用数组类模板案例封装
- Python编程语言学习:python中与数字相关的函数(取整等)、案例应用之详细攻略
- Python:Python语言学习总结之常见变量与七大运算符
- 美赛数据网站和学习资料
- 【读一本书】《昇腾AI处理器架构与编程》--神经网络基本知识学习(1)
- 学习算法笔记(9)
- C++ Primer 学习笔记_44_STL实践与分析(18)--再谈迭代器【下】
- Django学习12 -- 数据表格展示
- WPF学习笔记一 依赖属性及其数据绑定
- 《深度学习》李宏毅 -- task7总结
- 《深度学习》李宏毅 -- task2 回归
- 《深度学习》 --李宏毅学习导图总结
- 深度学习笔记:卷积神经网络的可视化--卷积核本征模式
- 深度学习笔记:卷积神经网络的可视化--特征图
- 学习区块链的基础知识--工作量证明