
pytorch中的MultiheadAttention类解析
PyTorch 解析
2023-09-14 09:13:19 时间
总结
- 文章来源:CSDN_LawsonAbs
- 暂无亮点,持续更新~
- LawsonAbs的认知与思考,望各位读者审慎阅读。
forward()函数的输入参数:
query(L,N,E) L 指的是输出目标序列的长度,N 就是batch_size, E 就是每个单词的embedding 维度大小
key(S,N,E) S 指的是输入目标序列的长度(也就是max_seq_length),N 就是batch_size, E 就是每个单词的embedding 维度大小
value(S,N,E) ,S 指的是输入目标序列的长度,N 是 batch_size, E 是embedding的维度
输出参数:
attn_output(L,N,E)。
为什么源序列输入长度和目标序列输出长度不一致?
这个是完全可能的。结合下张图来看:
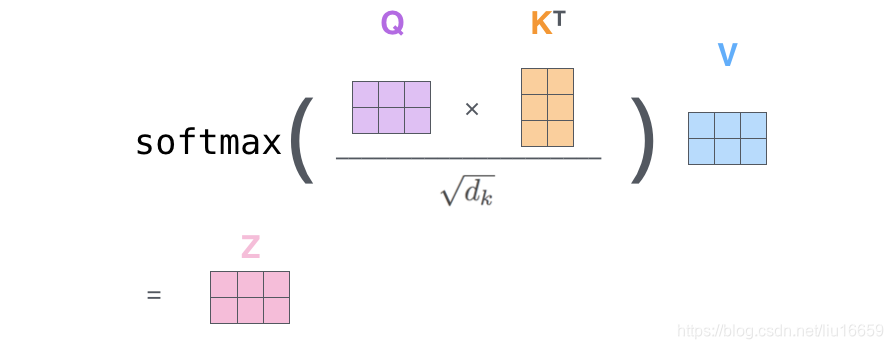
输入长度取决于 Q 的列维度,输出长度取决于V的列维度,而两者完全没有关联。
源码分析
class MultiheadAttention(Module):
r"""Allows the model to jointly attend to information
from different representation subspaces.
See reference: Attention Is All You Need
Args:
embed_dim: total dimension of the model.
num_heads: parallel attention heads.
dropout: a Dropout layer on attn_output_weights. Default: 0.0.
bias: add bias as module parameter. Default: True.
add_bias_kv: add bias to the key and value sequences at dim=0.
add_zero_attn: add a new batch of zeros to the key and
value sequences at dim=1.
kdim: total number of features in key. Default: None.
vdim: total number of features in value. Default: None.
Note: if kdim and vdim are None, they will be set to embed_dim such that
query, key, and value have the same number of features.
Examples::
>>> multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
>>> attn_output, attn_output_weights = multihead_attn(query, key, value)
"""
bias_k: Optional[torch.Tensor]
bias_v: Optional[torch.Tensor]
def __init__(self, embed_dim, num_heads, dropout=0., bias=True, add_bias_kv=False, add_zero_attn=False, kdim=None, vdim=None):
super(MultiheadAttention, self).__init__()
# embed_dim 应该是输入的维度
self.embed_dim = embed_dim
# 如果没有单独为kdim,vdim设置维度,则设置成和 embed_dim 同样的值
self.kdim = kdim if kdim is not None else embed_dim
self.vdim = vdim if vdim is not None else embed_dim
# 判断最后的值是否相同,设置一个标签
self._qkv_same_embed_dim = self.kdim == embed_dim and self.vdim == embed_dim
self.num_heads = num_heads
self.dropout = dropout
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
if self._qkv_same_embed_dim is False:
# 这里默认Wq 矩阵的第二维度是 embed_dim
self.q_proj_weight = Parameter(torch.Tensor(embed_dim, embed_dim))
self.k_proj_weight = Parameter(torch.Tensor(embed_dim, self.kdim))
self.v_proj_weight = Parameter(torch.Tensor(embed_dim, self.vdim))
self.register_parameter('in_proj_weight', None)
else: # 这么做是为了方便一次性初始化
self.in_proj_weight = Parameter(torch.empty(3 * embed_dim, embed_dim))
self.register_parameter('q_proj_weight', None)
self.register_parameter('k_proj_weight', None)
self.register_parameter('v_proj_weight', None)
if bias:
self.in_proj_bias = Parameter(torch.empty(3 * embed_dim))
else:
self.register_parameter('in_proj_bias', None)
self.out_proj = _LinearWithBias(embed_dim, embed_dim)
if add_bias_kv:
self.bias_k = Parameter(torch.empty(1, 1, embed_dim))
self.bias_v = Parameter(torch.empty(1, 1, embed_dim))
else:
self.bias_k = self.bias_v = None
self.add_zero_attn = add_zero_attn
self._reset_parameters()
# 这是pytorch 中专用的初始化参数的方法
def _reset_parameters(self):
if self._qkv_same_embed_dim:
xavier_uniform_(self.in_proj_weight)
else:
xavier_uniform_(self.q_proj_weight)
xavier_uniform_(self.k_proj_weight)
xavier_uniform_(self.v_proj_weight)
if self.in_proj_bias is not None:
constant_(self.in_proj_bias, 0.)
constant_(self.out_proj.bias, 0.)
if self.bias_k is not None:
xavier_normal_(self.bias_k)
if self.bias_v is not None:
xavier_normal_(self.bias_v)
def __setstate__(self, state):
# Support loading old MultiheadAttention checkpoints generated by v1.1.0
if '_qkv_same_embed_dim' not in state:
state['_qkv_same_embed_dim'] = True
super(MultiheadAttention, self).__setstate__(state)
def forward(self, query, key, value, key_padding_mask=None,
need_weights=True, attn_mask=None):
# type: (Tensor, Tensor, Tensor, Optional[Tensor], bool, Optional[Tensor]) -> Tuple[Tensor, Optional[Tensor]]
r"""
Args:
query, key, value: map a query and a set of key-value pairs to an output.
See "Attention Is All You Need" for more details.
key_padding_mask: if provided, specified padding elements in the key will
be ignored by the attention. When given a binary mask and a value is True,
the corresponding value on the attention layer will be ignored. When given
a byte mask and a value is non-zero, the corresponding value on the attention
layer will be ignored
need_weights: output attn_output_weights.
attn_mask: 2D or 3D mask that prevents attention to certain positions. A 2D mask will be broadcasted for all
the batches while a 3D mask allows to specify a different mask for the entries of each batch.
Shape:
- Inputs:
- query: :math:`(L, N, E)` where L is the target sequence length, N is the batch size, E is
the embedding dimension.
- key: :math:`(S, N, E)`, where S is the source sequence length, N is the batch size, E is
the embedding dimension.
- value: :math:`(S, N, E)` where S is the source sequence length, N is the batch size, E is
the embedding dimension.
- key_padding_mask: :math:`(N, S)` where N is the batch size, S is the source sequence length.
If a ByteTensor is provided, the non-zero positions will be ignored while the position
with the zero positions will be unchanged. If a BoolTensor is provided, the positions with the
value of ``True`` will be ignored while the position with the value of ``False`` will be unchanged.
- attn_mask: 2D mask :math:`(L, S)` where L is the target sequence length, S is the source sequence length.
3D mask :math:`(N*num_heads, L, S)` where N is the batch size, L is the target sequence length,
S is the source sequence length. attn_mask ensure that position i is allowed to attend the unmasked
positions. If a ByteTensor is provided, the non-zero positions are not allowed to attend
while the zero positions will be unchanged. If a BoolTensor is provided, positions with ``True``
is not allowed to attend while ``False`` values will be unchanged. If a FloatTensor
is provided, it will be added to the attention weight.
- Outputs:
- attn_output: :math:`(L, N, E)` where L is the target sequence length, N is the batch size,
E is the embedding dimension.
- attn_output_weights: :math:`(N, L, S)` where N is the batch size,
L is the target sequence length, S is the source sequence length.
"""
if not self._qkv_same_embed_dim:
return F.multi_head_attention_forward(
query, key, value, self.embed_dim, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.bias_k, self.bias_v, self.add_zero_attn,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask, use_separate_proj_weight=True,
q_proj_weight=self.q_proj_weight, k_proj_weight=self.k_proj_weight,
v_proj_weight=self.v_proj_weight)
else:
return F.multi_head_attention_forward(
query, key, value, self.embed_dim, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.bias_k, self.bias_v, self.add_zero_attn,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask)
相关文章
- 从零开始安装pytorch,并在pycharm中使用
- YOLOAir,一个基于 PyTorch 的 YOLO 工具箱...
- batchnorm pytorch_Pytorch中的BatchNorm
- Pytorch中的可视化——tensorboardX(一)
- Pytorch模型训练实用教程学习笔记:三、损失函数汇总
- 非常详细 | 用 Pytorch 理解卷积网络
- pytorch lstm训练例子_半对数模型参数的解释
- pytorch Tensor转numpy并解决RuntimeError: Can‘t call numpy() on Tensor that requires grad.报错
- pytorch tensor转int_numpy和pytorch
- 深入理解Pytorch中的分布式训练
- PyTorch GPU 与虚拟内存
- 改变几行代码,PyTorch炼丹速度狂飙、模型优化时间大减
- PyTorch + NumPy这么做会降低模型准确率,这是bug还是预期功能?
- PyTorch 可视化工具:TensorBoard、Visdom