
【深度强化学习】Actor-Critic算法
Actor-Critic算法
回顾策略梯度算法:

Actor-Critic算法的区别就是对
R
(
τ
n
)
R(\tau^n)
R(τn)进行了修改。

当
R
(
τ
n
)
R(\tau^n)
R(τn)具有上述三种形式时,便是经典的AC算法,在AC算法,我们通过另一个叫做Critic的神经网络来估计
V
π
(
s
t
)
V^{\pi}(s_{t})
Vπ(st)(或其他,视具体情况而定)。
本博客实现的便是基于TD残差的AC算法,其策略网络的梯度如下图所示
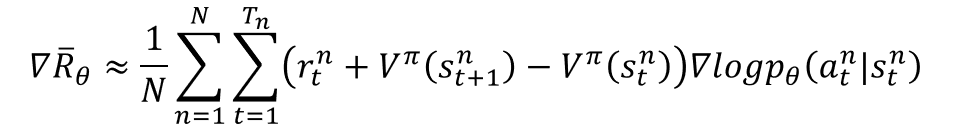
相应的Actor和Critic损失函数为:
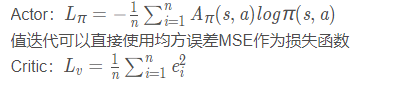
这里
e
i
=
r
t
n
+
V
π
(
s
t
+
1
n
)
−
V
π
(
s
t
n
)
e_i=r^n_t+V^{\pi}(s_{t+1}^n)-V^{\pi}(s^n_{t})
ei=rtn+Vπ(st+1n)−Vπ(stn),称为TD残差,而
A
π
(
s
,
a
)
=
e
i
A_{\pi}(s,a)=e_i
Aπ(s,a)=ei。
代码
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
# Hyperparameters
learning_rate = 0.0002
gamma = 0.98
n_rollout = 10
class ActorCritic(nn.Module):
def __init__(self):
super(ActorCritic, self).__init__()
self.data = []
self.fc1 = nn.Linear(4, 256)
self.fc_pi = nn.Linear(256, 2) #策略网络actor,根据状态输出每个动作的概率
self.fc_v = nn.Linear(256, 1) #值网络critic,根据状态输出价值V(s)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, softmax_dim=0):
x = F.relu(self.fc1(x))
x = self.fc_pi(x)
prob = F.softmax(x, dim=softmax_dim) #softmax输出概率值
return prob
def v(self, x):
x = F.relu(self.fc1(x))
v = self.fc_v(x) #输出Critic对状态s的评价
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
s_lst, a_lst, r_lst, s_prime_lst, done_lst = [], [], [], [], [] #s,a,r,s_,done
for transition in self.data:
s, a, r, s_prime, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r / 100.0]) #为什么除以100?
s_prime_lst.append(s_prime)
done_mask = 0.0 if done else 1.0
done_lst.append([done_mask]) #s_是否是terminal
s_batch, a_batch, r_batch, s_prime_batch, done_batch = torch.tensor(s_lst, dtype=torch.float), torch.tensor(
a_lst), \
torch.tensor(r_lst, dtype=torch.float), torch.tensor(
s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float)
self.data = []
return s_batch, a_batch, r_batch, s_prime_batch, done_batch
def train_net(self):
s, a, r, s_prime, done = self.make_batch()
td_target = r + gamma * self.v(s_prime) * done #计算r+gamma*V(s_),若s_为terminal状态,则td_target=r
delta = td_target - self.v(s) #计算TD残差,r+gamma*V(s_)-V(s)
pi = self.pi(s, softmax_dim=1)
pi_a = pi.gather(1, a)
loss = -torch.log(pi_a) * delta.detach() + F.smooth_l1_loss(self.v(s), td_target.detach()) #前半部分为actor网络的损失函数,后半部分为critic网络的损失函数
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()
def main():
env = gym.make('CartPole-v1')
model = ActorCritic()
print_interval = 20
score = 0.0
for n_epi in range(10000):
done = False
s = env.reset()
while not done:
for t in range(n_rollout):
prob = model.pi(torch.from_numpy(s).float())
m = Categorical(prob)
a = m.sample().item() #根据actor选择动作a
s_prime, r, done, info = env.step(a)
model.put_data((s, a, r, s_prime, done))
s = s_prime
score += r
if done:
break
model.train_net() #每回合训练一次网络
if n_epi % print_interval == 0 and n_epi != 0:
print("# of episode :{}, avg score : {:.1f}".format(n_epi, score / print_interval))
score = 0.0
env.close()
if __name__ == '__main__':
main()
结果展示

相关文章
- 【NLP基础】英文关键词抽取RAKE算法
- 机器学习十大经典算法之PCA主成分分析
- 机器学习十大经典算法之随机森林
- 机器学习算法——线性回归(超级详细且通俗)
- 机器学习算法——k-近邻(KNN)案例讲解
- 算法学习<2>---选择排序
- Paxos算法学习疑问记录
- 一文帮你搞懂 | 串的模式匹配-朴素匹配和KMP算法及优化
- 算法学习–整型转字符串
- 《算法竞赛进阶指南》0x12 队列
- PQ实战案例拆解 | 汇总多股票交易数据,计算最近60天的5日移动平均的操作与算法优化
- 《异常检测——从经典算法到深度学习》6 基于重构概率的 VAE 异常检测
- 如何提升深度学习算法效率,谷歌有这些绝招
- 算法 | byte值的按位不定长存储算法 [C/C++]
- 你想要的字符串展开算法在这
- 多智能体强化学习算法【二】【MADDPG、QMIX、MAPPO】
- 深度学习算法原理——RCNN
- 基于深度学习的基准目标检测及其衍生算法
- AI通用安防深度学习算法如何赋能场景应用?
- Python用逻辑回归、决策树、SVM、XGBoost 算法机器学习预测用户信贷行为数据分析报告
- 【深度学习】深度图像检测算法总结与对比
- 《机器学习十大经典算法》报告邀请
- AAAI 2023杰出论文一作分享:新算法加持的大批量学习加速推荐系统训练
- 机器学习算法(八):基于BP神经网络的乳腺癌的分类预测
- A.机器学习入门算法(八):基于BP神经网络的乳腺癌的分类预测
- 深度学习基础入门篇[三]:优化策略梯度下降算法:SGD、MBGD、Momentum、Adam、AdamW
- Python用机器学习算法进行因果推断与增量、增益模型Uplift Modeling智能营销模型|附代码数据
- Java实现的快速排序算法详解编程语言
- Java数据结构学习笔记之二Java数据结构与算法之栈(Stack)实现详解编程语言
- LRU算法详解编程语言
- Pedro Domingos深度解析机器学习五大流派中主算法精髓
- Redis集群中的选举算法与机制研究(redis选举算法和机制)