
论文解读《Embracing Domain Differences in Fake News: Cross-domain Fake News Detection using Multimodal Data》
论文信息
论文标题:Embracing Domain Differences in Fake News: Cross-domain Fake News Detection using Multimodal Data
论文作者:Amila Silva, Ling Luo, Shanika Karunasekera, Christopher Leckie
论文来源:AAAI 2021
论文地址:download
论文代码:download
1 Background
人工虚假新闻检测存在的问题:人工检查费时、费力;
自动虚假新闻检测存在的问题: 如果新闻记录来自不同的领域(如 政治、娱乐),那别是对于在训练中看不到的邻域,那么训练出的模型性能通常会下降;
2 Introduction
问题:
-
- 存在跷跷板问题:模型在某个邻域效果好,但是在其他领域效果不好;新闻数据是海量的,且存在大多没有标签的数据;新闻数据是海量的,且存在大多没有标签的数据;新闻数据是海量的,且存在大多没有标签的数据;新闻数据是海量的,且存在大多没有标签的数据;
- 特定领域的单词使用不同;
- 特定领域的传播结构不同;
- 新闻数据是海量的,且存在大多没有标签的数据;
- 存在跷跷板问题:模型在某个邻域效果好,但是在其他领域效果不好;新闻数据是海量的,且存在大多没有标签的数据;新闻数据是海量的,且存在大多没有标签的数据;新闻数据是海量的,且存在大多没有标签的数据;新闻数据是海量的,且存在大多没有标签的数据;
贡献:
-
- 提出一种新框架,联合保存新闻记录中的特定领域和跨领域知识,以检测来自不同领域的假新闻;
- 引入一种无监督技术,选择一组未标记的信息新闻记录进行人工标签,最终可用于训练一个假新闻检测模型,该模型在许多领域表现良好,同时最小化标签成本;
本研究旨在解决如何在新闻记录中保存特定领域和跨领域的知识,以检测跨领域新闻数据集中的假新闻。
3 Problem Statement
Let $R$ be a set of news records. Each record $r \in R$ is represented as a tuple $\left\langle t^{r}, W^{r}, G^{r}\right\rangle$ , where (1) $t^{r}$ is the timestamp when r is published online; (2) $W^{r}$ is the text content of $r$ ; and (3) $G^{r}$ is the propagation network of $r$ for time bound $\Delta T$ . We keep $\Delta \text{ T low (= five hours)} $ for our experiments to evaluate early detection performance. Each propagation network $G^{r}$ is an attributed directed graph $\left(V^{r}, E^{r}, X^{r}\right)$ , where nodes $V^{r}$ represent the tweets/retweets of r and the edges $E^{r}$ represent the retweet relationships among them. $X^{r}$ is the set of attributes of the nodes (i.e., tweets) in $G^{r}$ . More details about $E^{r}$ and $G^{r}$ are given in (Silva et al. 2021).
Our problem consists of two sub-tasks: (1) select a set of instances $R^{L}$ from $R$ to label while adhering to the given labelling budget $ B$ , which constrains the number of instances in $ R^{L}$ . The labelling process assigns a binary label $y^{r}$ for each record $r$: $y^{r}$ is $1$ if $r$ is false and $0$ otherwise; (2) learn an effective model using $R^{L}$ to predict the label $ y^{r}$ for unlabelled news records $ r \in R^{U}$ as false or real news records. In this work, $ R\left(R^{L} \cup R^{U}\right)$ is not constrained to a specific domain. To emulate such a domain-agnostic dataset, we combine three publicly available datasets:(1) PolitiFact (2) GossipCop (3) CoAID。
数据集如下:

4 Method
总体框架如下:
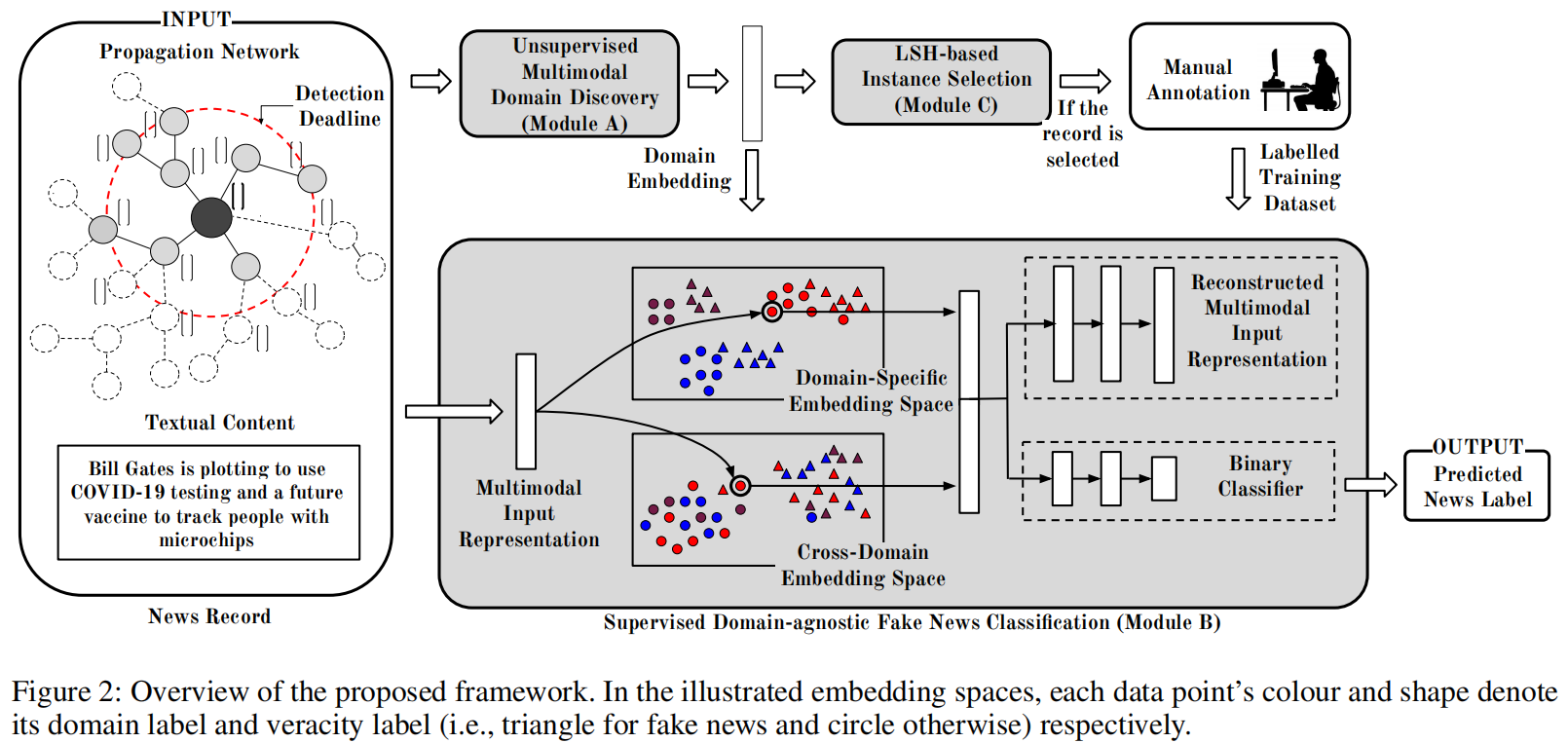
虚假新闻检测包括两个部分:
- unsupervised domain embedding learning (Module A);
- supervised domain-agnostic news classification (Module B);
实列选择方法 (Module C)
4.1 Unsupervised Domain Discovery
用无监督的方法学习新闻的所属领域 $f_{domain}(r)$,用一个低维的向量表示;
算法步骤如下:
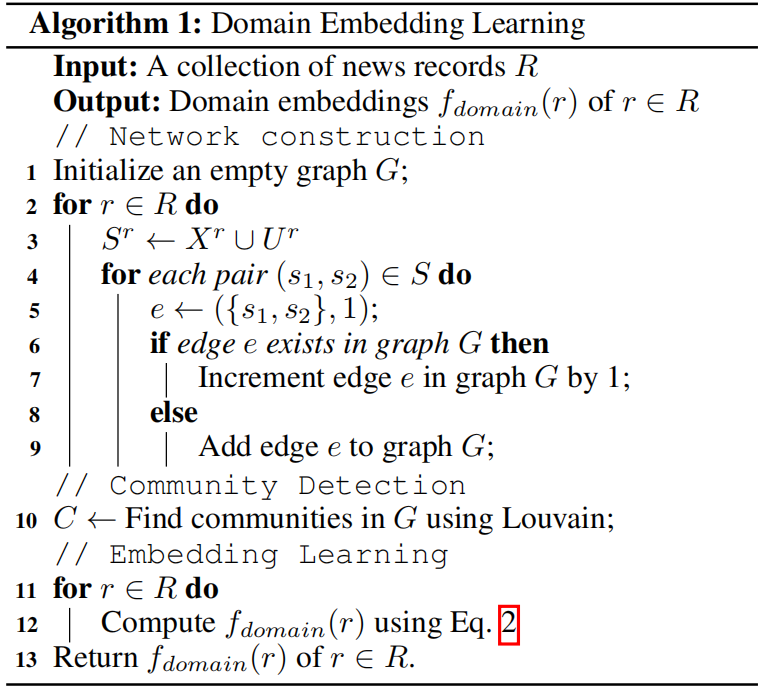
1-9 步概括如下:
-
- 每一个新闻 $r$ 构建一个集合 $S^{r}$ ,包含 $r$ 的传播网络 $G^{r}$ 中的所有用户,以及 $r$ 新闻内容 $W^{r}$ 中的所有单词;
- 针对集合 $S^{r}$ 中的每两个数据,构建一个有权重的边将它们连接起来;
- 重复上述 2 步,直到所有新闻都处理完成,就得到了最终网络 $G$;
第 10 步 使用一个社区发现算法 Louvain算法检测网络 $G$ 中的社区。然后得到 $G$ 的社区划分 $C$,本文简单的认为每一个类别 $C$ 中的所有节点是属于同一个 domain 的,而不同类别 $C$ 下的节点属于不同的 domian。
得到了每一个新闻的所属 domain 的伪标签之后,接下来就计算每一个新闻所属 domain 的低维向量表示了,就是 $f_{domain}(r)$。具体过程如下面公式 1,2 所示:
$p(r \in c)=\sum\limits_{v \in c \cap r} v_{d e g} / \sum\limits _{c \in C} \sum\limits_{v \in r} v_{d e g} \quad\quad\quad(1)$
$f_{\text {domain }}(r)=p\left(r \in c_{1}\right) \oplus p\left(r \in c_{2}\right) \oplus \ldots p\left(r \in c_{|C|}\right) \quad\quad\quad(2)$
以前的方法多用单个的离散值表示新闻所属领域,但是一个新闻可能属于多个不同领域,所以本文这种用概低维概率向量表示 $f_{domain}(r)$ 的方式更好。
可视化结果:

从 Figure 3 中可以看出,与基线相比,所提出的方法在域之间产生了明显的分离。这可能主要是因为我们的方法能够联合利用多种模式,包括用户和新闻记录的文本来发现他们的域。
4.2 Domain-agnostic News Classifification
$\overline{y^{r}}=g_{\text {pred }}\left(f_{\text {specific }}(r) \oplus f_{\text {shared }}(r)\right)$
$\overline{f_{\text {input }}(r)}=g_{\text {recon }}\left(f_{\text {specific }}(r) \oplus f_{\text {shared }}(r)\right)$
$L_{\text {pred }}=B C E\left(y^{r}, \overline{y^{r}}\right) \quad\quad\quad(3)$
$L_{\text {recon }}=\left\|f_{\text {input }}(r)-\overline{f_{\text {input }}(r)}\right\|^{2} \quad\quad\quad(4)$
其中,$\overline{y^{r}}$ 和 $\overline{f_{\text {input }}(r)}$ 是预测的标签和预测的输入表示;
然而,$L_{\text {pred }}$ 和 $L_{\text {recon }}$ 并没有利用新闻记录中的领域差异。因此,我们现在讨论如何进一步学习子空间的映射函数,即 $L_{\text {pred }}$ 和 $L_{\text {recon }}$ 保存新闻记录中特定领域和跨领域的知识。
4.2.1 Leveraging Domain-specifific Knowledge
$L_{\text {specific }}=\left\|f_{\text {domain }}(r)-g_{\text {specific }}\left(f_{\text {specific }}(r)\right)\right\|^{2}$
$ \left(\hat{g}_{\text {specific }}, \hat{f}_{\text {specific }}\right)=\underset{\left(g_{\text {specific }}, f_{\text {specific }}\right)}{\operatorname{argmin}}\left(L_{\text {specific }}\right) \quad\quad\quad(5)$
4.2.2 Leveraging Cross-domain Knowledge
另一方面,新闻的跨领域表示 $f_{shared}$ 通过 公式6 获取。$g_{shared}$ 是一个解码器函数用于预测新闻的所属领域,同时训练函数 $f_{shared}$ 来欺骗编码器使它无法准确预测出新闻的所属领域。通过这种方式来学习新闻的领域无关特征,也就是跨领域的特征。
$L_{\text {shared }}=\left\|g_{\text {shared }}\left(f_{\text {shared }}(r)\right)-f_{\text {domain }}(r)\right\|^{2}$
$\left(\hat{g}_{\text {shared }}, \hat{f}_{\text {shared }}\right)=\underset{f_{\text {shared }}}{\operatorname{argmin}} \;\; \underset{g_{\text {shared }}}{\operatorname{argmax}}\left(-L_{\text {shared }}\right) \quad\quad\quad(6)$
4.2.3 Integrated Model
为了学习 $L_{sharard}$ 中的极大极小博弈,使用以下两步对最终损失函数 $L_{final}$ 进行顺序优化:
$\left(\widehat{\theta_{1}}\right)=\underset{\theta_{1}}{\operatorname{argmin}} \; L_{\text {final }}\left(\theta_{1}, \theta_{2}\right)\quad\quad\quad(8)$4.3 LSH-based Instance Selection
本文首先用新闻所属领域 $f_{domain}(r)$ 来表示每一个新闻,然后采用局部敏感的哈希(Locality-Sensitive Hashing ,LSH)算法来选择 $R$ 中尽可能远的新闻。最终得到满足条件 B 个数目的有标记的新闻集合。
如下图 a 所示,分别是采用随机方式从数据集中选择样本(Rand-Fake/Real)和采用本文的 LSH 方式选择样本(LSH-Fake/Real)的结果。可以看出随机的方式对于数据集中少有的领域新闻(politiFact 和 CoAID)也采样了很少。而本文的方法对这类少见的领域新闻采样出了一个较为均衡的数目。因此本文能够较好处理训练集中 unseen 和 rarely seen 领域新闻的问题。 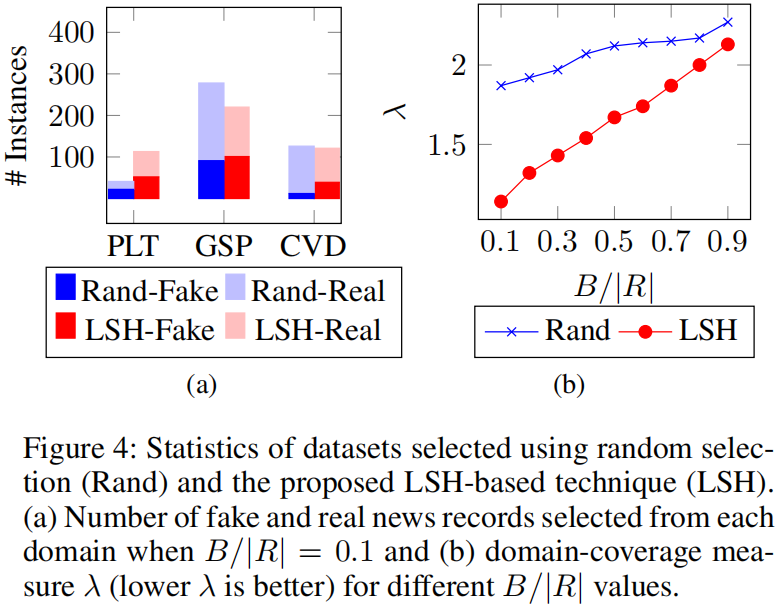
5 Experiment
本文模型中每一个新闻的输入表示是通过它的文本内容和传播网络得到的。作者使用 RoBERTa-base 来学习新闻的文本表示 $f_text$,然后用一个无监督的网络表征学习技术来学习新闻的传播表示 $f_network$,最后将这两者拼接得到新闻的输入表示 $f_input$.
本文所有的编码和解码网络($f_{specific}$, $f_{shared}$, $g_{specific}$, $g_{shared}, $g_{pred}$, $g_{recon}$)都是 $2$ 层的前馈神经网络,激活函数是 sigmoid 函数。
其他超参数设置见论文原文,这里不再赘述。
Dataset
本文将三个不同领域的数据集:(1) PolitiFact; (2) GossipCop; and (3) CoAID,组合成一个跨领域的数据集。然后随机选择 75% 的数据作为训练集,25% 作为测试集。
针对本文的 LSH 选择算法,从 75% 的训练集中依据限制 $B$ 来选择有标注的新闻的数目来训练模型。
Result
如下表所示,本文对比了 4 个纯文本方法(T),两个基于社交信息的方法 (S),三个多模态方法(M)。从中可以看出本文模型的虚假新闻检测能力最好。EANN-Multimoda取得了次好的结果,说明探索领域相关的特征是有效的。EANN 也本文的差距在于,前者只用了 corss-domain 的特征,没有用 domain-specific 的特征;同时 EANN 用一种 hard 的方式表示新闻的 domian,而本文使用低维的概率向量表示的,因此本文模型更好。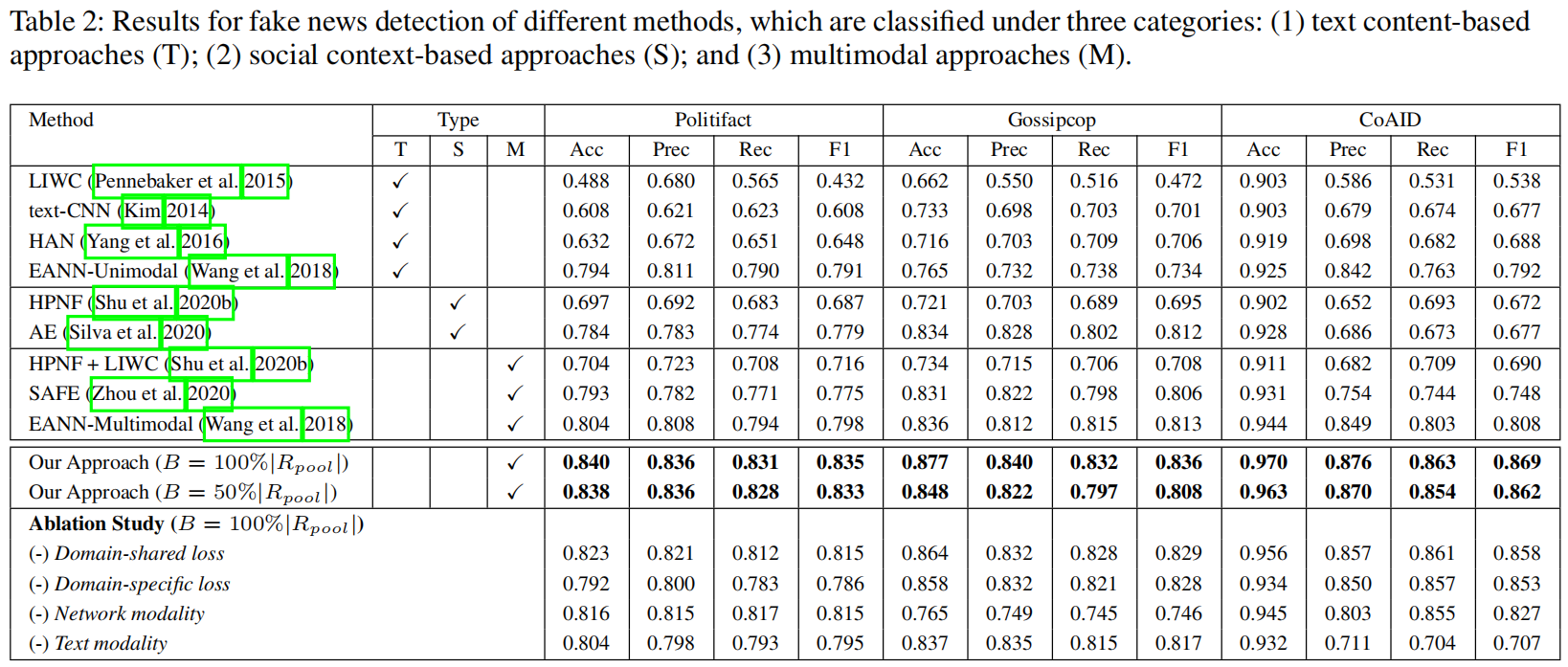
结果如上表最后一行所示,可以看出领域特定的特征,以及跨领域的特征都对检测虚假新闻有帮助。而且每一个模态的数据(network modality以及text modality)也都有用。
下图 a 是新闻的 domian-specific 特征,可以看出该特征反应了新闻的 domain 信息。而 b 图 是 corss-domain 特征,就与 domian 无关了。 
相关文章
- 【目标检测】目标检测遇上知识图谱:Object detection meets knowledge graphs论文解读与复现
- Algorithm:数学建模大赛(CUMCM/NPMCM)之数学建模(经验/技巧)、流程(模型准备/模型假设/建模/求解/分析/优化/预测/评价)、论文写作(意义/摘要/关键词/问题重述和模型假设/建
- ML之LS&OLS:LS&OLS算法的简介、论文、算法的改进(最佳子集选择OFSS法、前向逐步回归FSR法)、代码实现等详细攻略
- DL之FastR-CNN:Fast R-CNN算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略
- WPS:WPS的论文使用技巧之如何自动生成参考文献(图文教程)
- 【论文解读】RepLKNet,基于Swin架构的超大核网络
- 带你读AI论文丨ACGAN-动漫头像生成
- 论文解读(PGD)《Towards deep learning models resistant to adversarial attacks》
- 论文解读(DMVCJ)《Deep Embedded Multi-View Clustering via Jointly Learning Latent Representations and Graphs》
- 论文解读(MCNS)《Understanding Negative Sampling in Graph RepresentationLearning》
- 论文解读(GCA)《Graph Contrastive Learning with Adaptive Augmentation》
- 如何在线翻译整篇PDF论文?
- 5-12《Convolutional Neural Networks for Sentence Classification》论文阅读
- 《论文阅读》Cluster-Level Contrastive Learning for Emotion Recognition in Conversations
- 论文阅读《Extracting Multiple-Relations in One-Pass with Pre-Trained Transformers》
- 论文笔记:An Experimental Comparison of Performance Metrics for Event Detection Algorithms in NILM(2)
- 论文解读:ChangeStar | Change is Everywhere: Single-Temporal Supervised Object Change Detection in Remote