
5-12《Convolutional Neural Networks for Sentence Classification》论文阅读
1.模型
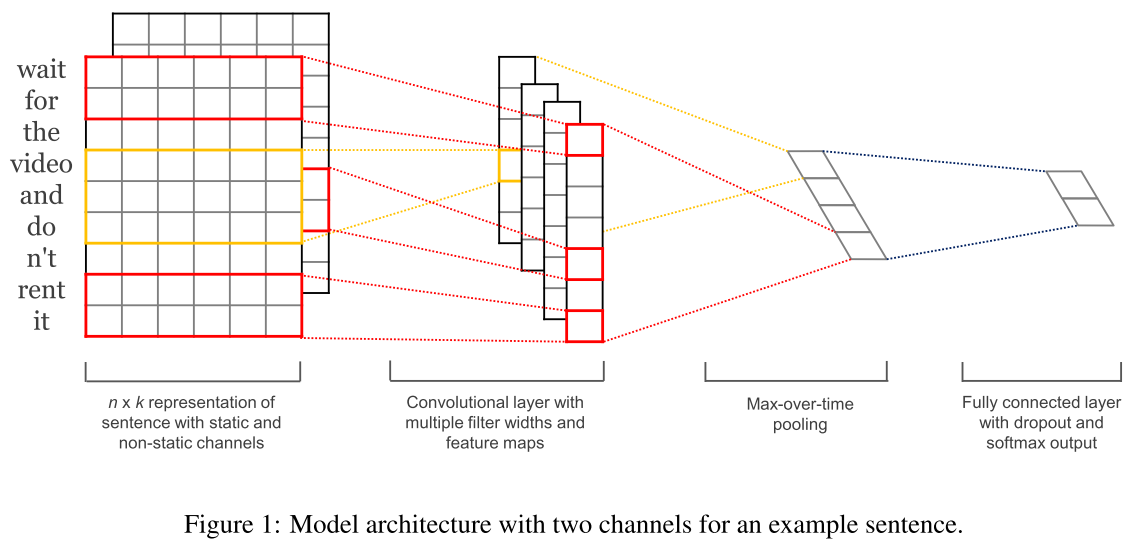
上图中输入部分,两层分别表示两个通道,一层是固定的词向量表示,一层是可以微调的词向量;
输入被表示为,➕表示连接操作:
![]()
对每个h词块都有如下卷积操作,h应该是卷积步长大小,W表示一个卷积核,针对每个卷积核都会进行以下操作,来产生卷积结果(一系列ci组成c)![]()
经过一个卷积核的卷积操作之后,可以得到:
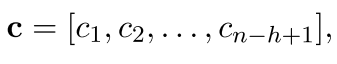
对上面的c做最大池化,选出最大的c,最大的c就对应最重要的特征。
原文中提到:“We have described the process by which one feature is extracted from one filter”。这个one feature是针对倒数第二层来说的,有多少个卷积核这层就有多少个特征,那么最后再经过一层全连接层。当然,使用的卷积核可以有不同的窗口大小。
2.正则化
使用了dropout,它可以防止神经元之间互相产生依赖关系,这个dropout是放在了倒数第二层进行的。对于倒数第二层:
![]()
其中,r就是概率为p的0/1向量:![]()
参数还设置了L2正则化。l2-norms of the weight vectors。
3.实验
3.1超参数
filter windows (h) of 3, 4, 5 with 100 feature maps each,也就是说卷积核一共有300个?每100个的核大小分别为3、4、5?
dropout=0.5. L2正则化参数为3. bsz=50.
预训练的word2vec使用的是300维的。
3.2模型变化
CNN-rand: 所有的词向量都是随机初始化的,在训练过程中训练
CNN-static:词向量由word2vec初始化,并且不可改变
CNN-non-static:词向量由word2vec初始化,并且微调
CNN-multichannel:有两套词向量,应该都是由word2vec初始化,并且一个可以微调,另一个不可改变。
在这里微调:“gradients are back-propagated only through one of the channels.”。微调的意思也就是把其中一个词向量当作可以训练的参数,每次都会计算梯度,然后更新。
4.结论
实验结果我就不截图了。
我认为有意思的:
1.微调之后词向量更有效:
2.dropout能够提高2%-4%。
2020-5-25更新————————————
1.torch版的实现
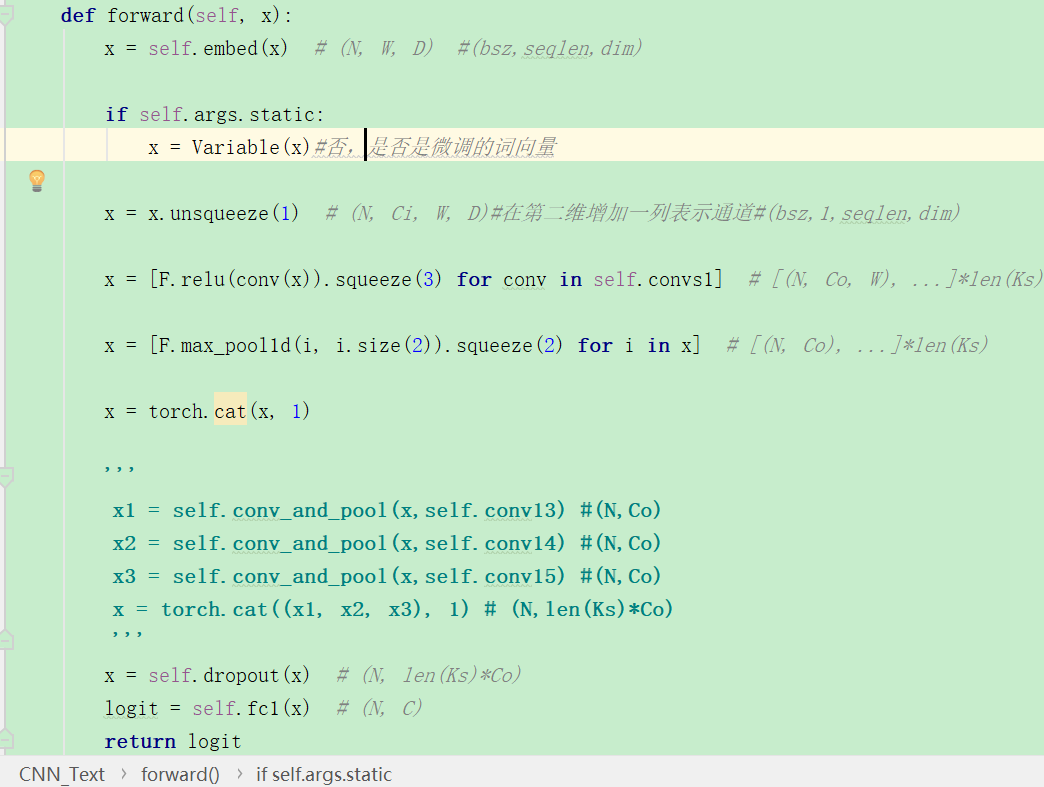
从这个实现中我们可以学习,其中kernel_sizes为[1,2,3],kernel_num为100. 假设如下:
import torch import torch.nn as nn import torch.nn.functional as F m = nn.Conv2d(1, 100, (3,100))#(输入通道、输出通道,kernel_size) m4=nn.Conv2d(1, 100, (4,100)) m5=nn.Conv2d(1, 100, (5,100)) input = torch.randn(32,1, 50, 100)#(bsz,通道数,seqlen,emb_dim) output = m(input) o4=m4(input) o5=m5(input) print(output.size()) print(o4.size()) print(o5.size()) ##mp=nn.MaxPool1d(48) ##print(mp(output).size()) print(F.max_pool1d(output.squeeze(3),48).size())#这里squeeze掉最后一个维度 #输出: torch.Size([32, 100, 48, 1])#输出通道变为了100. torch.Size([32, 100, 47, 1]) torch.Size([32, 100, 46, 1]) torch.Size([32, 100, 1])#最大池化的输出就相当于每个句子都变为了一个100维的向量, #其中每一个元素都来自一个卷积核。
这样的话我就明白了这个过程了!基本没有问题了。
相关文章
- 2018年3月14日论文阅读
- 【论文复现】——Patchwork++:基于点云的快速稳健地面分割方法
- 投稿指南【NO.7】目标检测论文写作模板(初稿)
- CV之FR之FAN:FAN人脸对齐网络(Face Alignment depth Network)的论文简介、案例应用之详细攻略
- DL之InceptionV2/V3:InceptionV2 & InceptionV3算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略
- 带你读AI论文:NDSS2020 UNICORN: Runtime Provenance-Based Detector
- 论文解读丨LayoutLM: 面向文档理解的文本与版面预训练
- 带你读论文丨基于视觉匹配的自适应文本识别
- 解读顶会CIKM‘21 Historical Inertia论文
- AI论文解读:基于Transformer的多目标跟踪方法TrackFormer
- 论文解读(VAT)《Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning》
- 论文解读(MSN)《Masked Siamese Networks for Label-Effificient Learning》
- 论文解读(Graph Barlow Twins)《Graph Barlow Twins: A self-supervised representation learning framework for graphs》
- 论文解读(LA-GNN)《Local Augmentation for Graph Neural Networks》
- 论文解读(GraphDA)《Data Augmentation for Deep Graph Learning: A Survey》
- 论文解读(Cluster-GCN)《Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks》
- 论文解读(CSSL)《Contrastive Self-supervised Learning for Graph Classification》
- 论文解读(SimCLR)《A Simple Framework for Contrastive Learning of Visual Representations》
- 论文投稿指南——中文核心期刊推荐(海洋学)
- 论文阅读【ACM_2020】SimSwap: An Efficient Framework For High Fidelity Face Swapping
- 论文笔记:An Experimental Comparison of Performance Metrics for Event Detection Algorithms in NILM(1)
- 论文阅读:Path Aggregation Network for Instance Segmentation
- 论文解读:STANet | A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image
- Mask RCNN网络源码解读(Ⅴ) --- Mask R-CNN论文解读环境配置以及训练脚本解析