
论文解读(MCNS)《Understanding Negative Sampling in Graph RepresentationLearning》
论文信息
论文标题:Understanding Negative Sampling in Graph RepresentationLearning
论文作者:Zhen Yang, Ming Ding, Chang Zhou, Hongxia Yang, Jingren Zhou, Jie Tang
论文来源:2020, KDD
论文地址:download
论文代码:download
1 Introduction
创新点:理论上证明了负采样的重要性。
2 Framework
2.1 Unique Embedding Transformation
每个节点既可以作为中心节点(central node)也可以作为上下文节点(contextual node)。
2.2 The SampledNCE Framework
SampleNCE框架如下:

在训练过程中,采样 $m$ 个正节点和 $k·m$ 个负节点。
其中:$\sigma(x)=\frac{1}{1+e^{-x}}$
2.3 Network Embedding and GNNs
图数据中的边可以被假定为从一个潜在的正分布 $p_{d}(u, v)$ 中采样。然而,只有少数边是可观察到的,因此有许多技术可以做出合理的假设来更好地估计 $p_{d}(u, v)$,从而导致不同算法中的各种 $\hat{p_{d}}$ 来近似 $p_{d}$。
NE 算法隐式或显式地采用各种正分布。LINE 直接从相邻节点中抽取正节点。通过随机游动进行抽样,并隐式地将 $\hat{p_{d}}(u \mid v)$ 定义为随机游走的平稳分布。node2vec 认为,节点 $u$ 和 $v$ 的同质性和结构等价性表明有一个更大的 $p_{d}(u, v)$。这些假设主要基于局部平滑性和增强观察到的正节点对进行训练。
图神经网络配备了不同的编码器层,并对正分布进行隐式正则化。先前的工作[20]揭示了GCN是图拉普拉斯平滑的一种变体,它直接限制了相邻节点嵌入的差异。GCN,或其采样版本GraphSAGE[13],并没有显式地增加正对,而是通过局部平滑来正则化输出嵌入,这可以看作是 $p_{d}$ 的隐式正则化。
3 Understading negative sampling
负样本抽样同样重要,但是却长期被忽视。
结论:"the negative sampling distribution should be positively but sub-linearly correlated to their positive sampling distribution"
3.1 How does negative sampling influence the objective of embedding learning?
NE 的一般的形式,分解矩阵是由估计的数据分布 $ \hat{p_{d}}(u \mid v)$ 和负分布 $p_{n}\left(u^{\prime} \mid v\right)$ 决定的。目标函数:
$\begin{aligned}J &=\mathbb{E}_{(u, v) \sim p_{d}} \log \sigma\left(\overrightarrow{\boldsymbol{u}}^{\top} \overrightarrow{\boldsymbol{v}}\right)+\mathbb{E}_{v \sim p_{d}(v)}\left[k \mathbb{E}_{u^{\prime} \sim p_{n}\left(u^{\prime} \mid v\right)} \log \sigma\left(-\overrightarrow{\boldsymbol{u}^{\prime}}^{\top} \overrightarrow{\boldsymbol{v}}\right)\right] \\&=\mathbb{E}_{v \sim p_{d}(v)}\left[\mathbb{E}_{u \sim p_{d}(u \mid v)} \log \sigma\left(\overrightarrow{\boldsymbol{u}}^{\top} \overrightarrow{\boldsymbol{v}}\right)+k \mathbb{E}_{u^{\prime} \sim p_{n}\left(u^{\prime} \mid v\right)} \log \sigma\left(-\overrightarrow{\boldsymbol{u}^{\prime}}^{\top} \overrightarrow{\boldsymbol{v}}\right)\right]\end{aligned}\quad\quad\quad(1)$
Theorem 1. (Optimal Embedding) The optimal embedding satisfies that for each node pair $(u,v)$
$\overrightarrow{\boldsymbol{u}}^{\top} \overrightarrow{\boldsymbol{v}}=-\log {\large \frac{k \cdot p_{n}(u \mid v)}{p_{d}(u \mid v)}} \quad\quad\quad(2)$
证明:为了最大化 $J$,等价于为每个 $v$ 最小化以下目标函数:
$\begin{aligned}J^{(v)} &=\mathbb{E}_{u \sim p_{d}(u \mid v)} \log \sigma\left(\overrightarrow{\boldsymbol{u}}^{\top} \overrightarrow{\boldsymbol{v}}\right)+k \mathbb{E}_{u^{\prime} \sim p_{n}\left(u^{\prime} \mid v\right)} \log \sigma\left(-\overrightarrow{\boldsymbol{u^{\prime}}} \overrightarrow{\boldsymbol{v}}^{\top}\right) \\&=\sum\limits_{u} p_{d}(u \mid v) \log \sigma\left(\overrightarrow{\boldsymbol{u}}^{\top} \overrightarrow{\boldsymbol{v}}\right)+k \sum\limits_{u^{\prime}} p_{n}\left(u^{\prime} \mid v\right) \log \sigma\left(-\overrightarrow{\boldsymbol{u^{\prime}}}^{\top} \overrightarrow{\boldsymbol{v}}\right) \\&=\sum\limits_{u}\left[p_{d}(u \mid v) \log \sigma\left(\overrightarrow{\boldsymbol{u}}^{\top} \overrightarrow{\boldsymbol{v}}\right)+k p_{n}(u \mid v) \log \sigma\left(-\overrightarrow{\boldsymbol{u}}^{\top} \overrightarrow{\boldsymbol{v}}\right)\right] \\&=\sum\limits_{u}\left[p_{d}(u \mid v) \log \sigma\left(\overrightarrow{\boldsymbol{u}}^{\top} \overrightarrow{\boldsymbol{v}}\right)+k p_{n}(u \mid v) \log \left(1-\sigma\left(\overrightarrow{\boldsymbol{u}}^{\top} \overrightarrow{\boldsymbol{v}}\right)\right)\right]\end{aligned}$
对于每一个 $(u, v)$,我们定义两个伯努利分布 $P_{u, v}(x)$、$Q_{u, v}(x)$,其中 $P_{u, v}(x=1)={\large \frac{p_{d}(u \mid v)}{p_{d}(u \mid v)+k p_{n}(u \mid v)}} $ 、 $Q_{u, v}(x= 1) =\sigma\left(\overrightarrow{\boldsymbol{u}}^{\top} \overrightarrow{\boldsymbol{v}}\right) $,上述等式简化如下:
$J^{(v)}=-\sum\limits _{u}\left(p_{d}(u \mid v)+k p_{n}(u \mid v)\right) H\left(P_{u, v}, Q_{u, v}\right)$
其中,$H(p, q)=-\sum_{x \in X} p(x) \log q(x) $ 是两个分布之间的交叉熵。根据 吉布斯不等式,$L^{(v)}$ 的极大值满足每个 $(u, v)$ 对的 $P=Q$ ,从而给出
$\begin{aligned}\frac{1}{1+e^{-\overrightarrow{\boldsymbol{u}}^{T} \overrightarrow{\boldsymbol{v}}}} &=\frac{p_{d}(u \mid v)}{p_{d}(u \mid v)+k p_{n}(u \mid v)} \\\overrightarrow{\boldsymbol{u}}^{\top} \overrightarrow{\boldsymbol{v}} &=-\log \frac{k \cdot p_{n}(u \mid v)}{p_{d}(u \mid v)}\end{aligned}\quad\quad\quad(3)$
以上定理清楚地表明,正负分布 $p_{d}$ 和 $p_{n}$ 对优化具有相同程度的影响。与大量关于寻找更好的 $\hat{p_{d}}$ 来近似 $p_{d}$ 的研究相比,负分布的 $p_{n}$ 显然没有得到充分的探索。
3.2 How does negative sampling influence the expected loss (risk) of embedding learning?
以上分析表明,有足够(可能是无限)的 $p_{d}$ 边样本,嵌入 $\overrightarrow{\boldsymbol{u}}^{\top} \overrightarrow{\boldsymbol{v}}$ 的内积有一个最优值。在真实世界的数据中,我们只有有限的 $p_{d}$ 样本,这导致了不可忽视的预期损失(风险)。然后,将节点 $v$ 的经验风险最小化的损失函数变为:
$J_{T}^{(v)}=\frac{1}{T} \sum\limits_{i=1}^{T} \log \sigma\left(\overrightarrow{\boldsymbol{u}}_{i}^{\top} \overrightarrow{\boldsymbol{v}}\right)+\frac{1}{T} \sum\limits_{i=1}^{k T} \log \sigma\left(-\overrightarrow{\boldsymbol{u}}_{i}^{\top} \overrightarrow{\boldsymbol{v}}\right)\quad\quad\quad(4)$
其中,$\left\{u_{1}, \ldots, u_{T}\right\}$ 从 $p_{d}(u \mid v)$ 采样,$\left\{u_{1}^{\prime}, \ldots, u_{k}^{\prime \top}\right\}$ 从 $p_{n}(u \mid v)$ 采样。
在本节中,我们只考虑节点 $v$ 的优化,它可以直接推广到整个嵌入学习。更准确地说,我们等价地考虑 $ \theta=\left[\vec{u}_{0}^{\top} \vec{v}, \ldots, \vec{u}_{N-1}^{\top} \vec{v}\right]$ 作为需要优化的参数,其中 $\left\{u_{0}, \ldots u_{N-1}\right\}$ 是图中的 $N$ 个节点
假设 $J_{T}^{(v)}$ 和 $J^{(v)}$ 的最优参数分别为 $\boldsymbol{\theta}_{T} $ 和 $\boldsymbol{\theta}^{*}$。$\boldsymbol{\theta}_{T} $ 和 $\boldsymbol{\theta}^{*}$ 之间的差距描述如下:
Theorem 2. The random variable $\sqrt{T}\left(\boldsymbol{\theta}_{T}-\boldsymbol{\theta}^{*}\right)$ asymptotically converges to a distribution with zero mean vector and covariance matrix:
$\operatorname{Cov}\left(\sqrt{T}\left(\boldsymbol{\theta}_{T}-\boldsymbol{\theta}^{*}\right)\right)=\operatorname{diag}(\boldsymbol{m})^{-1}-(1+1 / k) \mathbf{1}^{\top} \mathbf{1}$
其中,${\large \boldsymbol{m}=\left[\frac{k p_{d}\left(u_{0} \mid v\right) p_{n}\left(u_{0} \mid v\right)}{p_{d}\left(u_{0} \mid v\right)+k p_{n}\left(u_{0} \mid v\right)}, \ldots, \frac{k p_{d}\left(u_{N-1} \mid v\right) p_{n}\left(u_{N-1} \mid v\right)}{p_{d}\left(u_{N-1} \mid v\right)+k p_{n}\left(u_{N-1} \mid v\right)}\right]^{\top}} $
证明:分析基于 $\nabla_{\theta} J_{T}^{(v)}(\boldsymbol{\theta})$ 在 $\boldsymbol{\theta}^{*}$ 周围的泰勒展开式。由于 $ \boldsymbol{\theta}_{T}$ 是 $J_{T}^{(v)}(\boldsymbol{\theta})$ 的最小值,必须有 $\nabla_{\theta} J_{T}^{(v)}\left(\boldsymbol{\theta}_{T}\right)= \mathbf{0}$,并给出:
$\nabla_{\theta} J_{T}^{(v)}\left(\boldsymbol{\theta}_{T}\right)=\nabla J_{T}^{(v)}\left(\boldsymbol{\theta}^{*}\right)+\nabla_{\theta}^{2} J_{T}^{(v)}\left(\boldsymbol{\theta}^{*}\right)\left(\boldsymbol{\theta}_{T}-\boldsymbol{\theta}^{*}\right)+O\left(\left\|\boldsymbol{\theta}_{T}-\boldsymbol{\theta}^{*}\right\|^{2}\right)=\mathbf{0}\quad\quad\quad(6)$
根据 $O\left(\left\|\boldsymbol{\theta}^{*}-\boldsymbol{\theta}_{T}\right\|^{2}\right)$ ,有
$\sqrt{T}\left(\boldsymbol{\theta}_{T}-\boldsymbol{\theta}^{*}\right)=-\left(\nabla_{\theta}^{2} J_{T}^{(v)}\left(\boldsymbol{\theta}^{*}\right)\right)^{-1} \sqrt{T} \nabla_{\theta} J_{T}^{(v)}\left(\boldsymbol{\theta}^{*}\right) \quad \quad\quad (7)$
接下来,将通过下面 lemmas 分析 $-\left(\nabla_{\theta}^{2} J_{T}^{(v)}\left(\theta^{*}\right)\right)^{-1} $ 和 $\sqrt{T} \nabla_{\theta} J_{T}^{(v)}\left(\theta^{*}\right)$ :
Lemma 1. The negative Hessian matrix $-\nabla_{\theta}^{2} J_{T}^{(v)}\left(\boldsymbol{\theta}^{*}\right)$ converges in probability to $ \operatorname{diag}(\boldsymbol{m}) $.
证明:首先,我们计算了 $J_{T}^{(v)}(\theta)$ 和Hessian矩阵 $\nabla_{\theta}^{2} J_{T}^{(v)}(\boldsymbol{\theta})$ 的梯度。设 $\boldsymbol{\theta}_{u}$ 是 $\boldsymbol{\theta}$ 中用于建模 $\overrightarrow{\boldsymbol{u}}^{\top} \overrightarrow{\boldsymbol{v}}$ 的参数,而 $\boldsymbol{e}_{(u)} $ 是在这个维度上只有一个 $1$ 的一独热向量。
$\begin{aligned}J_{T}^{(v)}(\boldsymbol{\theta})=& \frac{1}{T} \sum\limits_{i=1}^{T} \log \sigma\left(\boldsymbol{\theta}_{u_{i}}\right)+\frac{1}{T} \sum\limits_{i=1}^{k T} \log \sigma\left(-\boldsymbol{\theta}_{u_{i}^{\prime}}\right) \\\nabla_{\theta} J_{T}^{(v)}(\boldsymbol{\theta})=& \frac{1}{T} \sum\limits_{i=1}^{T}\left(1-\sigma\left(\boldsymbol{\theta}_{u_{i}}\right)\right) \boldsymbol{e}_{\left(u_{i}\right)}-\frac{1}{T} \sum\limits_{i=1}^{k T} \sigma\left(\boldsymbol{\theta}_{u_{i}^{\prime}}\right) \boldsymbol{e}_{\left(u_{i}^{\prime}\right)} \\\nabla_{\theta}^{2} J_{T}^{(v)}(\boldsymbol{\theta})=& \frac{1}{T} \sum\limits_{i=1}^{T}\left\{-\sigma\left(\boldsymbol{\theta}_{u_{i}}\right)\left(1-\sigma\left(\boldsymbol{\theta}_{u_{i}}\right)\right) \boldsymbol{e}_{\left(u_{i}\right)} \boldsymbol{e}_{\left(u_{i}\right)}^{\top}+\mathbf{0}^{\top} \mathbf{0}\right\} \\&-\frac{1}{T} \sum\limits_{i=1}^{k T}\left\{\sigma\left(\boldsymbol{\theta}_{u_{i}^{\prime}}\right)\left(1-\sigma\left(\boldsymbol{\theta}_{u_{i}^{\prime}}\right)\right) \boldsymbol{e}_{\left(u_{i}^{\prime}\right)} \boldsymbol{e}_{\left(u_{i}^{\prime}\right)}^{\top}+\mathbf{0}^{\top} \mathbf{0}\right\}\end{aligned}\quad\quad\quad(8)$
根据 $\text{Eq.3}$ ,$\sigma\left(\boldsymbol{\theta}_{u_{i}}\right)={\large \frac{p_{d}(u \mid v)}{p_{d}(u \mid v)+k p_{n}(u \mid v)} } $ 在 $\boldsymbol{\theta}=\boldsymbol{\theta}^{*}$ ,因此:
$\begin{aligned}\lim _{T \rightarrow+\infty}-\nabla_{\theta}^{2} J_{T}^{(v)}\left(\boldsymbol{\theta}^{*}\right) \stackrel{P}{\rightarrow} & \sum_{u} \sigma\left(\boldsymbol{\theta}_{u}\right)\left(1-\sigma\left(\boldsymbol{\theta}_{u}\right)\right) \boldsymbol{e}_{(u)} \boldsymbol{e}_{(u)}^{\top} \cdot\left(p_{d}(u)+k p_{n}(u)\right) \\ =& \sum_{u} \frac{k p_{d}(u \mid v) p_{n}(u \mid v)}{p_{d}(u \mid v)+k p_{n}(u \mid v)} \boldsymbol{e}_{(u)} \boldsymbol{e}_{(u)}^{\top} \\ &=\operatorname{diag}(\boldsymbol{m}) .\end{aligned}\quad\quad\quad(9)$
Lemma 2. The expectation and variance of $\nabla_{\theta} J_{T}^{(v)}\left(\boldsymbol{\theta}^{*}\right)$ satisfy
$\mathbb{E}\left[\nabla_{\theta} J_{T}^{(v)}\left(\boldsymbol{\theta}^{*}\right)\right]=\mathbf{0}\quad\quad\quad(10)$
$\operatorname{Var}\left[\nabla_{\theta} J_{T}^{(v)}\left(\boldsymbol{\theta}^{*}\right)\right]=\frac{1}{T}\left(\boldsymbol{d i a g}(\boldsymbol{m})-(1+1 / k) \boldsymbol{m m}^{\top}\right)\quad\quad\quad(11)$
证明:根据 $\text{Eq.3}、\text{Eq.8}$
$\begin{array}{l}\mathbb{E}\left[\nabla_{\theta} J_{T}^{(v)}\left(\boldsymbol{\theta}^{*}\right)\right]=\sum\left[p_{d}(u)\left(1-\sigma\left(\theta_{u}^{*}\right)\right) \boldsymbol{e}_{(u)}-k p_{n}(u) \sigma\left(\boldsymbol{\theta}_{u}^{*}\right) \boldsymbol{e}_{(u)}\right]=0 \\\operatorname{Cov}\left[\nabla_{\theta} J_{T}^{(v)}\left(\boldsymbol{\theta}^{*}\right)\right] \\=\mathbb{E}\left[\nabla_{\theta} J_{T}^{(v)}\left(\boldsymbol{\theta}^{*}\right) \nabla_{\theta} J_{T}^{(v)}\left(\boldsymbol{\theta}^{*}\right)^{\top}\right] \\=\frac{1}{T} \mathbb{E}_{u \sim p_{d}(u \mid v)}\left(1-\sigma\left(\boldsymbol{\theta}_{u}^{*}\right)\right)^{2} \boldsymbol{e}_{(u)} \boldsymbol{e}_{(u)}^{\top}+\frac{k}{T} \mathbb{E}_{u \sim p_{n}(u \mid v)} \sigma\left(\boldsymbol{\theta}_{u}^{*}\right)^{2} \boldsymbol{e}_{(u)} \boldsymbol{e}_{(u)}^{\top}+\left(\frac{T-1}{T}-2+1-\frac{1}{k T}\right) \boldsymbol{m}^{\top} \\=\frac{1}{T}\left(\operatorname{diag}(\boldsymbol{m})-\left(1+\frac{1}{k}\right) \mathbf{m} \boldsymbol{m}^{\top}\right)\end{array}\quad\quad\quad(12)$
让我们继续用 $\text{Eq.9}、\text{Eq.12}$ 代入 $\text{Eq.7}$ 来证明 Theorem 2,并推导出 $\sqrt{T}\left(\boldsymbol{\theta}_{T}-\boldsymbol{\theta}^{*}\right)$ 的协方差:
$\begin{aligned}\operatorname{Cov}\left(\sqrt{T}\left(\boldsymbol{\theta}_{T}-\boldsymbol{\theta}^{*}\right)\right) &=\mathbb{E}\left[\sqrt{T}\left(\boldsymbol{\theta}_{T}-\boldsymbol{\theta}^{*}\right) \sqrt{T}\left(\boldsymbol{\theta}_{T}-\boldsymbol{\theta}^{*}\right)^{\top}\right] \\& \approx T \operatorname{diag}(\boldsymbol{m})^{-1} \operatorname{Var}\left[\nabla_{\theta} J_{T}^{(v)}\left(\boldsymbol{\theta}^{*}\right)\right]\left(\operatorname{diag}(\boldsymbol{m})^{-1}\right)^{\top} \\&=\operatorname{diag}(\boldsymbol{m})^{-1}-(1+1 / k) \mathbf{1}^{\top} \mathbf{1}\end{aligned}$
根据 Theorem 2,$\overrightarrow{\boldsymbol{u}}^{\top} \overrightarrow{\boldsymbol{v}}$ 的均方误差,又称风险,为
$\mathbb{E}\left[\left\|\left(\theta_{T}-\theta^{*}\right)_{u}\right\|^{2}\right]=\frac{1}{T}\left(\frac{1}{p_{d}(u \mid v)}-1+\frac{1}{k p_{n}(u \mid v)}-\frac{1}{k}\right)\quad\quad\quad(13)$
3.3 The Principle of Negative Sampling
对于特定 $p_d$ 为确定合适的 $p_n$,可能需要权衡来平衡目标的合理性和预期损失,也称为风险。
一个简单的解决方案是对负节点进行正抽样,但与它们的正抽样分布呈亚线性相关。
$p_{n}(u \mid v) \propto p_{d}(u \mid v)^{\alpha}, 0<\alpha<1$
(Monotonicity) From the perspective of objective, if we have $p_{d}\left(u_{i} \mid v\right)>p_{d}\left(u_{j} \mid v\right)$
$\begin{aligned}\overrightarrow{\boldsymbol{u}}_{i}^{\top} \overrightarrow{\boldsymbol{v}} &=\log p_{d}\left(u_{i} \mid v\right)-\alpha \log p_{d}\left(u_{i} \mid v\right)+c \\&>(1-\alpha) \log p_{d}\left(u_{j} \mid v\right)+c=\overrightarrow{\boldsymbol{u}}_{j}^{\top} \overrightarrow{\boldsymbol{v}}\end{aligned}$
其中 $c$ 是一个常数。内积的大小与正分布 $p_d$ 一致,促进了不同我们依赖于 $\overrightarrow{\boldsymbol{u}}^{\top} \overrightarrow{\boldsymbol{v}}$ 的相对大小的任务,如推荐或链接预测。
(Accuracy) From the perspective of risk, we mainly care about the scale of the expected loss. According to $\text{Eq.13}$ , the expected squared deviation is dominated by the smallest one in $p_{d}(u \mid v)$ and $p_{n}(u \mid v)$ . If an intermediate node with large $p_{d}(u \mid v)$ is negatively sampled insufficiently (with small $p_{n}(u \mid v) )$, the accurate optimization will be corrupted. But if $p_{n}(u \mid v) \propto p_{d}(u \mid v)^{\alpha}$ , then
$\mathbb{E}\left[\left\|\left(\theta_{T}-\theta^{*}\right)_{u}\right\|^{2}\right]=\frac{1}{T}\left(\frac{1}{p_{d}(u \mid v)}\left(1+\frac{p_{d}(u \mid v)^{1-\alpha}}{c}\right)-1-\frac{1}{k}\right)$
偏差的数量级仅与 $p_d(u|v)$ 呈负相关,这意味着在有限的正样本下,高概率节点对的内积估计更准确。这是比均匀负抽样的一个明显优势。
4 Method
4.1 The Self-contrast Approximation
虽然我们推断出 $p_{n}(u \mid v) \propto p_{d}(u \mid v)^{\alpha}$,但真实的 $p_{d}$ 是未知的,它的近似 $\hat{p_{d}}$ 通常是隐式定义的。该原则如何帮助负抽样?
因此,我们提出了一种自对比近似方法,用基于当前编码器的内积来代替 $p_{d}$
$p_{n}(u \mid v) \propto p_{d}(u \mid v)^{\alpha} \approx \frac{\left(E_{\theta}(u) \cdot E_{\theta}(v)\right)^{\alpha}}{\sum_{u^{\prime} \in U}\left(E_{\theta}\left(u^{\prime}\right) \cdot E_{\theta}(v)\right)^{\alpha}}$
所得到的形式类似于 RotatE 中的一种技术,而且非常耗时。每次采样都需要 $O(n)$ 个时间,因此无法使用中型或大规模图。我们的 $MCNS$ 通过我们的适应版本的Metropolis-Hastings 算法来解决了这个问题。
4.2 The Metropolis-Hastings Algorithm
作为最杰出的马尔可夫链蒙特卡罗(MCMC)方法之一,Metropolis-Hastings 算法 被设计用于从非归一化分布中获得随机样本序列。假设我们想从分布 $\pi(x)$ 中采样,但只知道 $\tilde{\pi}(x) \propto \pi(x)$。同时,归一化器 $Z=\sum_{x} \tilde{\pi}(x)$ 的计算也是不可承受的。Metropolis-Hastings 算法构造了一个马尔可夫链 $\{X(t)\}$,这意味着,$X(t) \sim \pi(x), t \rightarrow \infty$。
马尔可夫链中的跃迁有两个步骤:
(1) Generate $y \sim q(y \mid X(t))$ where the proposal distribution q is arbitrary chosen as long as positive everywhere.
(2) Pick $y$ as $X(t+1)$ at the probability $\min \left\{\frac{\tilde{\pi}(y)}{\tilde{\pi}(X(t))} \frac{q(X(t) \mid y)}{q(y \mid X(t))}, 1\right\}$ , or $X(t+1) \leftarrow X(t) $. See tutorial [6] for more details.
4.3 Markov chain Negative Sampling
基于提出的负采样分布形式,作者提出了如下 self-contrast approximation:
$\mathcal{L}=\max \left(0, E_{\theta}(v) \cdot E_{\theta}(x)-E_{\theta}(u) \cdot E_{\theta}(v)+\gamma\right)\quad\quad\quad(14)$
在 Algorithm 2 中总结了MCNS。

5 Experiments
数据集及任务

推荐任务
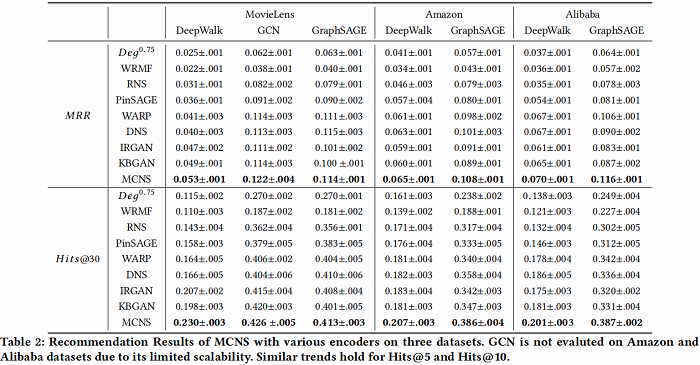
链接预测
用学到的 embedding 用于链接预测任务,结果如下:

节点分类
用学到的 embedding 加上简单的 logistic 分类器用于节点分类任务,结果如下:
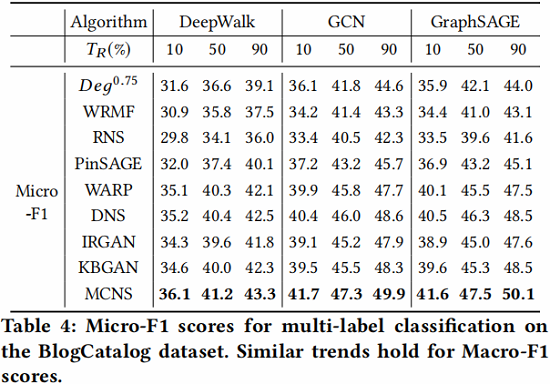
相关工作


对于正样本的工作:
随机游走:[27]
二阶接近:[32]
社区结构:[37]
对于编码器的工作:
以注意力为基础:[34]
基于GAN:[8]
抽样聚合器:[13]
基于 WL :[39]
负样本首先是作为噪声对比估计的简化版本 [24]、[12, 25]
相关文章
- 论文笔记(5):Fully Convolutional Multi-Class Multiple Instance Learning
- 投稿指南【NO.7】目标检测论文写作模板(初稿)
- 谷歌Borg论文阅读笔记(二)——任务混部的解决
- DL之CycleGAN:CycleGAN算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略
- DL之NIN:Network in Network算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略
- Paper之ACL&EMNLP:2009年~2019年ACL计算语言学协会年会&EMNLP自然语言处理的经验方法会议历年最佳论文简介及其解读
- Paper:2020.02.09钟南山团队首篇新冠病毒论文《Clinical characteristics of 2019 novel coronavirus infection in China》
- 跟我读论文丨ACL2021 NER 模块化交互网络用于命名实体识别
- 答读者问(16):一个研二学生有关论文和学习的相关疑问
- 计算机毕设项目 40个高质量SSM+VUE毕设项目分享【源码+论文】(八)
- 论文解读(SelfGNN)《Self-supervised Graph Neural Networks without explicit negative sampling》
- 论文投稿指南——收藏|SCI论文怎么投?(Accepted)
- 3D点云重建0-03:MVSNet-白话给你讲论文-翻译无死角(1)
- 《论文阅读》DialogueCRN: Contextual Reasoning Networks for Emotion Recognition in Conversations
- 《论文阅读》Generating Responses with a Specific Emotion in Dialog
- 论文阅读《The Funny Thing About Incongruity: A Computational Model of Humor in Puns》
- 论文阅读《Extracting Multiple-Relations in One-Pass with Pre-Trained Transformers》
- 【PGGAN】1、Progressive Growing of GANs for Improved Quality, Stability, and Variation 论文阅读
- 改进YOLOv5系列:3.YOLOv5结合Swin Transformer结构,ICCV 2021最佳论文 使用 Shifted Windows 的分层视觉转换器
- 论文阅读:UNET 3+: A FULL-SCALE CONNECTED UNET FOR MEDICAL IMAGE SEGMENTATION
- Mask RCNN网络源码解读(Ⅴ) --- Mask R-CNN论文解读环境配置以及训练脚本解析
- 【目标检测论文解读复现NO.32】基于改进YOLO的飞机起降阶段跟踪方法