
论文阅读《The Funny Thing About Incongruity: A Computational Model of Humor in Puns》
LawsonAbs的认知与思考,还请各位读者批判阅读。
总结
- 文章来源:csdn:LawsonAbs
- 这篇文章主要讲的内容就是:
通过数学量化的方法验证在双关语导致的幽默中,ambiguity 和 distinctiveness 是非常重要的两个因素。验证的方式是使用线性回归判断funning ratings;使用对puns,De-punned,Non-pun的分类影响,然后证明确实如此。 - 本文按照原论文的行文流程来解读。
- 论文名:《The Funny Thing About Incongruity: A Computational Model of Humor in Puns》
- 论文地址
- 持续更新~
1 Abstract

Researchers showed the robot ten puns, hoping that one of them would make it laugh. Unfortunately, no pun in ten did.
Humor theorists posit that incongruity—perceiving a situation from different viewpoints and finding the resulting interpretations to be incompatible — contributes to sensations of mirth.
这句话就是全文的核心。语言学家指出“incongruity” 是幽默的真正原因。而incongruity 又是来自两个方面:含义的歧义(ambiguity)【问题是:含义指的是单词的含义还是句子的含义?】; 观点的不同(distinctiveness)
为了形式化描述 incongruity, 就使用一种计算模型(就是后文中说到的a probabilistic model of sentence comprehension),并且测试 incongruity 对双关语幽默的影响。
2 Introduction
略~
3 Model
不一致性是是句子翻译的一种属性。为了描述这种不一致性,先描述一个概率模型(用于表示句子理解的概率模型)。
3.1 模型目标
从已观测到的单词中(其实就是句中的单词)推测句子的主题(a coarse representation of its meaning 也就是其含义的大致猜测)。这种概率模型与之前的模型不同,作者使用了 noisy channel apporach方法,这个方法基于假设:理解者在对哪些词反映了句子主题,哪些词是噪声上不确定。从这个模型中,可以得到两个导致幽默的量:
从这个模型上,我们得出两个可能会导致humor的量:ambiguity and distinctiveness。对于这两个条件都缺一不可:
- many ambiguous sentences are not funny(e.g. I went to the bank)
作者分析,导致这种问题存在的原因是:没有显著的词支持多种topic的翻译,而这两种不同的翻译又会造成某种程度上的不一致性,这就可能会导致humor。
3.2 模型细节
假设句子是由内容词向量
w
⃗
=
{
w
1
,
w
1
,
.
.
.
,
w
i
,
h
,
w
i
+
1
,
.
.
.
,
w
n
}
\vec{w} = {\{w_1,w_1,...,w_i,h,w_{i+1},...,w_n\}}
w={w1,w1,...,wi,h,wi+1,...,wn} 构成,其中这个h 是一个发音模糊的单词。

对于
w
⃗
=
{
w
1
,
w
1
,
.
.
.
,
w
i
,
h
,
w
i
+
1
,
.
.
.
,
w
n
}
\vec{w}={\{w_1,w_1,...,w_i,h,w_{i+1},...,w_n\}}
w={w1,w1,...,wi,h,wi+1,...,wn},我们使用一个生成式模型,模型图如下,下面给出具体的步骤。
 【不懂这里红线标注的内容】
【不懂这里红线标注的内容】
下面这个是上面这个模型的主要思想:
 【不懂】
【不懂】
- 给出一个潜在的句子主题m,每个单词是独立生成,通过决定它是否反应了主题(这个得看标志变量
f
i
f_i
fi)
如果反应了主题,则会根据和m的语义相关性进行采样;如果没有反应主题,则会从之前的单词中找出一个固定的unigram中采样 - 于是可以看到整个句子是一个 topical 和 非topical的单词组成【=> 也就是说,最后的这个 w ⃗ \vec{w} w 是生成得到的向量,而不是原始的句子向量?】
在语言的生成模型中也使用了类似的方法来解释哪些提供非语义信息的单词。
Similar approaches have been used in generative models of language to account for words thad provide non-semantic information
3.2 模型起源
Our model is motivated by the important role that semantic priming plays in lexical disambiguation during sentence processing
感觉就是重在语义,语义!
3.3 假设
the plausible candidate topics m of the sentence correspond to the potential interpretations of the homophone word h, which are constrained by phonetic(adj,语音学的) similarity to two alternatives, m1 and m2.
这句话的意思是说:句子的几个候选主题m 都和 谐音词h潜在的翻译相关联,同时这些候选主题又受(谐音词候选含义m1,m2的)限制。
下面给出一个例子:

在上面这个双关语中,h 就是 谐音双关词hare,同时m1,m2就是hare,hair的候选翻译。那么这句话的两个主题就可以被标志为两个翻译hare 和 hair
这种假设有什么好处呢?
缩小了句子含义的不明确的空间
由联合分布
p
(
m
,
f
⃗
∣
w
⃗
)
p(m,\vec{f}|\vec{w})
p(m,f∣w) (其中m是句子主题,
f
⃗
\vec{f}
f是标志变量),那么这个联合分布就可以被分解成
P
(
m
,
f
⃗
∣
w
⃗
)
=
P
(
m
∣
w
⃗
)
P
(
f
⃗
∣
m
,
w
⃗
)
P(m,\vec{f}|\vec{w}) = P(m|\vec{w}) P(\vec{f}|m,\vec{w})
P(m,f∣w)=P(m∣w)P(f∣m,w)
右侧两式是推导ambiguity 和 distinctiveness的基础。
-
ambiguity意味着两种相似可能解释的存在,ambiguity可以被 p ( m ∣ w ⃗ ) p(m|\vec{w}) p(m∣w) 量化 。
如果 p ( m ∣ w ⃗ ) p(m|\vec{w}) p(m∣w) 值大,那么就有ambiguity吗? -
distinctiveness衡量的是度:这句话的不同观点支持两种解释的程度。 (Distinctiveness measures the degree to which two interpretations are supported by “distinct” viewpoints of the sentence)。这里的distinctiveness 被视作是分歧:两套聚焦在不同主题的words的分歧。它可以被 P ( f ⃗ ∣ m , w ⃗ ) P(\vec{f}|m,\vec{w}) P(f∣m,w)所量化。(it can be quantified as a summary of the distribution P ( f ⃗ ∣ m , w ⃗ ) P(\vec{f}|m,\vec{w}) P(f∣m,w) 根据这句话,可以指出是根据这个表达式的和来量化。)
最后,这两种方式就构成了我们对不一致性的定义。(Together, these two measures constitute our formalization of incongruity)
3.4 Ambiguity
用M 表示分布
p
(
m
∣
w
⃗
)
p(m|\vec{w})
p(m∣w),是一个二项分布,在两种含义值m1 和 m2。(Let M denote the distribution
P
(
m
∣
w
⃗
)
P(m|\vec{w})
P(m∣w),a binomial distribution over the two meaning values m1 and m2 given the observed words.) 如果这个分布的熵值较低,那么意味着probability mass 集中在仅仅一个含义上,
If the entropy of this distribution is low, this means that the probability mass is concentrated on only one meaning, and the alternative meaning is unlikely given the observed words.
If entropy is high, this means that the probability mass is more evenly distributed among m1 and m1, and the two interpretations are similarly likely given the contexts.
因此,
P
(
m
∣
w
⃗
)
P(m|\vec{w})
P(m∣w) 的熵就是一个自然指标去衡量歧义度。下面给出计算
P
(
m
∣
w
⃗
)
P(m|\vec{w})
P(m∣w) 的方法:
 公式(2)很好理解;
公式(2)很好理解;
公式(3)怎么理解?
公式(4)怎么理解?
单独计算每个因子的值。
用单词m的词频来估计P(m);
对于每个单词被作为focus,假设成是一个均匀分布,那么有
P
(
f
⃗
)
P(\vec{f})
P(f) 就是一个常数;
对于
P
(
m
∣
w
⃗
)
P(m|\vec{w})
P(m∣w),需要注意到它既由 m 和
w
⃗
\vec{w}
w之间的semanftic relationship 决定,同时也由 m的先验概率决定,这个先验概率也就是我们上面说的使用 单词m1和m2的 ==unigram probability ==
对于生成式模型:
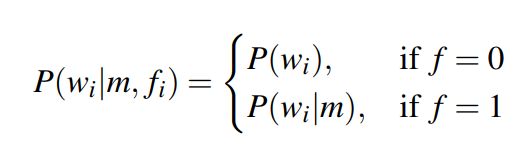
然后就可以使用上式(4)得到最后的计算结果。
3.5 Distictiveness
接着来看下面这个式子:
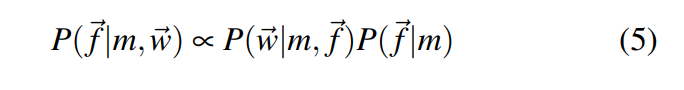
因为
f
⃗
\vec{f}
f 和
m
m
m是独立的,所以
P
(
f
⃗
∣
m
)
=
P
(
f
⃗
)
P(\vec{f}|m)=P(\vec{f})
P(f∣m)=P(f)。
4 Evaluation
需要事先计算数个值:
5 Result
根据上述的模型部分和使用 relatedness measures ,就可以计算出每条句子的ambiguity 和 distinctiveness的值。
本模型有两个超参数:
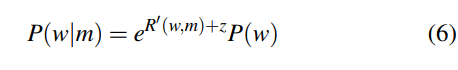
这里的z 以及常数 r——用于表明一个单词和它自身的相关度。我们在线性回归中使用
R
2
R^2
R2的方法来对其优化,总结的结果如下表:

上面这个表想说明的问题就是: A linear regression showed that both ambiguity and distinctiveness are significant predictors of funniness.
6 总结
6.1 这个模型能干什么?
读论文总会把自己搞迷糊,所以要常问,这个模型最终带来了什么?看看作者的话:

下面他说可以怎样得到一个关键的是什么词导致了incongruity 和 humor。但是我对这句话理解不透彻:

通过下面的表可以更细致的理解上面说到的这个问题:
 给出m1的情况下,被聚焦的单词用红色表示;
给出m1的情况下,被聚焦的单词用红色表示;
给出m2的情况下,最可能被聚焦的单词用绿色表示。

看上面的蓝色框:
- 当在Non-pun 的时候,hare做m1的时候,仅仅只有红色的标记;
- 当在Non-pun 的时候,tears做m2的时候,仅仅只有绿色的标记;
上面这个现象就说明Non-pun句子的focus 是固定的。
6.2 a nosiy channel model of language comprehension 指的是什么?


这里的nosiy channel model 模型应该是指 (Levy,2008;Levy et al.,2009)中的模型:这个模型指出:语言理解
相关文章
- Paper之ICASSP&IEEEAUDIOSPE:2018~2019年ICASSP国际声学、语音和信号处理会议&IEEE-ACM T AUDIO SPE音频、语音和语言处理期刊最佳论文简介及其解读
- Unexpected XML declaration. The XML declaration must be the first node in the document and no white
- Algorithm之PGM之BNet:贝叶斯网络BNet的相关论文、过程原理、关键步骤等相关配图
- DL之AlexNet:AlexNet算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略
- DL之ShuffleNetV2:ShuffleNetV2算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略
- 论文解读二十七:文本行识别模型的再思考
- Sqlachemy的警告SAWarning: The IN-predicate on "sns_object.BIZ_ID" was invoked with an empty sequence. This results in a contradiction, which nonetheless can be expensive to evaluate.
- 计算机毕设 SSM Vue的停车位租赁管理系统(含源码+论文)
- Spark SQL 源代码分析之 In-Memory Columnar Storage 之 in-memory query
- Caused by: org.xml.sax.SAXParseException; systemId: file:/home/hadoop/hive-0.12.0/conf/hive-site.xml; lineNumber: 5; columnNumber: 2; The markup in the document following the root element must be well
- 论文解读(AutoSSL)《Automated Self-Supervised Learning for Graphs》
- 解决办法:The name 'Response' does not exist in the current context
- 论文投稿指南——中文核心期刊推荐(电子、通信技术2)
- 论文投稿指南——中文核心期刊推荐(电子、通信技术)
- 论文投稿指南——收藏|SCI写作投稿发表全流程
- 行人检测0-02:LFFD-白话给你讲论文-翻译无死角(1)
- 《论文阅读》Supervised Prototypical Contrastive Learning for Emotion Recognition in Conversation
- 《论文阅读》Improving Multi-turn Emotional Support Dialogue Generation with Lookahead Strategy Planning
- 《论文阅读》EmoBERTa: Speaker-Aware Emotion Recognition in Conversation with RoBERTa
- 《论文阅读》Towards Building an Open-Domain Dialogue System Incorporated with Internet Memes
- 《论文阅读》Generating Responses with a Specific Emotion in Dialog
- 《论文阅读》Knowledge-Enriched Transformer for Emotion Detection in Textual Conversations
- 论文阅读《Exploring Task Difficult for Few-Shot Relation Extraction》
- 学习经验分享【26】论文写作画图方法(持续更新)