
自适应变异麻雀搜索优化算法-附代码
基于Logistic回归麻雀算法
文章目录
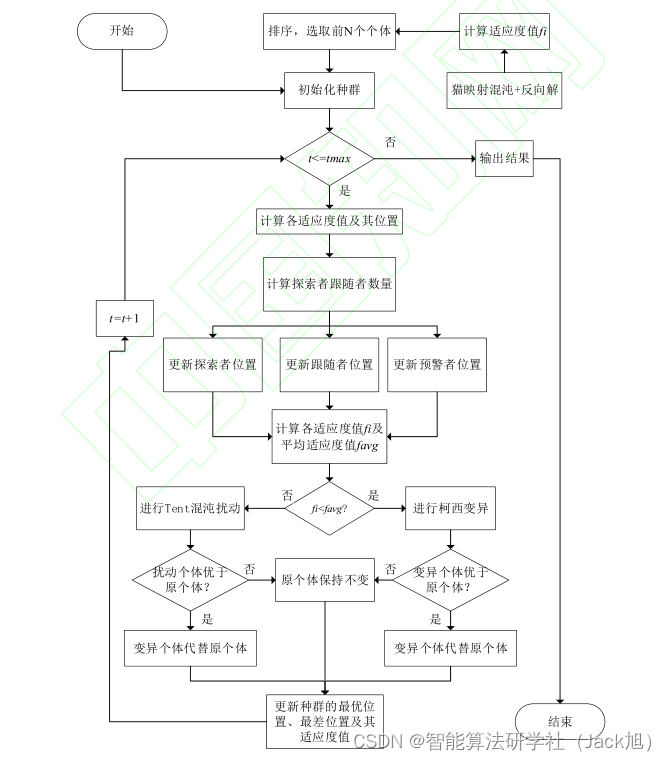
摘要:针对麻雀搜索算法前期易陷入局部极值点、后期寻优精度不高等问题,提出一种自适应变异麻雀搜索算法(AMSSA)。首先,通过猫映射混沌序列初始化种群,增强初始种群的随机性、遍历性,提高算法的全局搜索能力;其次,引入柯西变异和Tent混沌扰动,拓展局部搜索能力,使陷入局部极值点的个体跳出限制继续搜索;最后,提出探索者-跟随者数量自适应调整策略,利用各阶段探索者和跟随者数量的改变增强算法前期的全局搜索能力和后期的局部深度挖掘能力,提高算法的寻优精度。
1.麻雀搜索算法
基础麻雀算法的具体原理参考,我的博客:https://blog.csdn.net/u011835903/article/details/108830958
2.改进麻雀算法
2.1 猫映射混沌初始化种群
点, 本文通过猫映射来生成 SSA2 算法的初始种群。猫映射表达式为:
[
y
i
+
1
w
i
+
1
]
=
[
1
a
1
b
1
a
1
b
1
+
1
]
[
y
i
w
i
]
m
o
d
1
\left[\begin{array}{l} y_{i+1} \\ w_{i+1} \end{array}\right]=\left[\begin{array}{cc} 1 & a_1 \\ b_1 & a_1 b_1+1 \end{array}\right]\left[\begin{array}{c} y_i \\ w_i \end{array}\right] \bmod 1
[yi+1wi+1]=[1b1a1a1b1+1][yiwi]mod1
式中:
a
1
、
b
1
a_1 、 b_1
a1、b1 为任意实数;
m
o
d
1
\bmod 1
mod1 表示求
a
1
a_1
a1 小数部分。由于猫映射结构简单, 不易陷入小循环周 期和不动点, 通过该映射产生初始种群具有更好的遍历均匀性。
根据猫映射的特点, 在可行域中产生混沌序列并结合反向解初始化的方法步骤为:随机产生当前 种群的一个可行解, 记为:
{
Y
i
=
[
y
i
1
,
y
i
2
,
…
,
y
i
d
,
…
,
y
i
D
]
;
y
i
d
∈
[
l
b
i
d
,
u
b
i
s
]
}
\left\{\boldsymbol{Y}_i=\left[y_{i 1}, y_{i 2}, \ldots, y_{i d}, \ldots, y_{i D}\right] ; y_{i d} \in\left[l b_{i d}, u b_{i s}\right]\right\}
{Yi=[yi1,yi2,…,yid,…,yiD];yid∈[lbid,ubis]}
则反向解为:
Y
′
=
[
Y
1
′
,
Y
2
′
,
…
,
Y
d
′
,
…
,
Y
D
′
]
y
i
d
=
q
(
l
b
i
d
−
u
b
d
d
)
−
y
i
d
\begin{aligned} &\boldsymbol{Y}^{\prime}=\left[\boldsymbol{Y}_1^{\prime}, \boldsymbol{Y}_2^{\prime}, \ldots, \boldsymbol{Y}_d^{\prime}, \ldots, \boldsymbol{Y}_D^{\prime}\right] \\ &y_{i d}=q\left(l b_{i d}-u b_{d d}\right)-y_{i d} \end{aligned}
Y′=[Y1′,Y2′,…,Yd′,…,YD′]yid=q(lbid−ubdd)−yid
式中:
q
q
q 为区间
[
0
,
1
]
[0,1]
[0,1] 上的均匀分布,
l
b
i
d
l b_{i d}
lbid 和
u
b
i
d
u b_{i d}
ubid 表示可行解的上下界。
2.2 Tent 混沌和柯西变异扰动策略
在
2.1
2.1
2.1 节中提到, Tent 混沌映射存在小周期和不稳定周期点, 为避免落入小周期点和不稳定周期 点, 文献[22]在原有的 Tent 映射表达式上引入随机变量
rand
(
0
,
1
)
×
1
N
\operatorname{rand}(0,1) \times \frac{1}{N}
rand(0,1)×N1, 改进后的 Tent 混沌映射表达式 如下:
z
i
+
1
=
{
2
z
i
+
rand
(
0
,
1
)
×
1
N
,
0
≤
z
≤
1
2
2
(
1
−
z
i
)
+
rand
(
0
,
1
)
×
1
N
,
1
2
<
z
≤
1
z_{i+1}= \begin{cases}2 z_i+\operatorname{rand}(0,1) \times \frac{1}{N}, & 0 \leq z \leq \frac{1}{2} \\ 2\left(1-z_i\right)+\operatorname{rand}(0,1) \times \frac{1}{N}, \frac{1}{2}<z \leq 1\end{cases}
zi+1={2zi+rand(0,1)×N1,2(1−zi)+rand(0,1)×N1,21<z≤10≤z≤21
贝努利移位变换后的表达式为:
z
i
+
1
=
(
2
z
i
)
m
o
d
1
+
rand
(
0
,
1
)
×
1
N
z_{i+1}=\left(2 z_i\right) \bmod 1+\operatorname{rand}(0,1) \times \frac{1}{N}
zi+1=(2zi)mod1+rand(0,1)×N1
式中:
N
N
N 为序列内粒子个数。
柯西变异来源于连续型概率分布的柯西分布[23], 主要特点为零处峰值较小, 从峰值到零值下降缓 慢, 使变异范围更均匀。变异公式为:
mutation
(
x
)
=
x
(
1
+
tan
(
π
(
u
−
0.5
)
)
)
(x)=x(1+\tan (\pi(u-0.5)))
(x)=x(1+tan(π(u−0.5)))
式中:
x
x
x 为原来个体位置, mutation
(
x
)
(x)
(x) 为经过柯西变异后的个体位置,
u
u
u 为
(
0
,
1
)
(0,1)
(0,1) 区间内的随机数。
2.3 改进探索者位置更新公式
在 SSA2 算法中, 麻雀探索者只受上一代探索者位置的影响,
exp
(
−
i
α
⋅
iter
max
)
\exp \left(\frac{-i}{\alpha \cdot \text { iter }_{\max }}\right)
exp(α⋅ iter max−i) 的值在不断迭代过程 中自适应降低, 其值较大时, 探索者进入广泛搜索模式, 随着其值降低, 探索者主要进行窄搜索模 式, 即在最优解附件深度挖掘, 提高算法的收玫精度。因此,
exp
(
−
i
α
⋅
i
t
e
r
max
)
\exp \left(\frac{-i}{\alpha \cdot i t e r_{\max }}\right)
exp(α⋅itermax−i) 的值尤为重要。由于
exp
(
−
i
α
⋅
i
t
e
max
)
\exp \left(\frac{-i}{\alpha \cdot i t e_{\max }}\right)
exp(α⋅itemax−i) 值的微小改变对探索者的影响较大, 因此本文在式 (2) 的基础上, 将探索者更新公式 改为:
x
i
,
d
′
+
1
=
{
x
i
,
d
′
⋅
2
exp
(
4
i
α
⋅
i
t
e
r
)
′
′
,
R
2
<
S
T
x
i
,
d
′
+
Q
×
L
,
R
2
≥
S
T
x_{i, d}^{\prime+1}=\left\{\begin{array}{l} x_{i, d}^{\prime} \cdot \frac{2}{\exp \left(\frac{4 i}{\alpha \cdot i_{t e r}}\right)^{\prime \prime}}, R_2<S T \\ x_{i, d}^{\prime}+Q \times L \quad, R_2 \geq S T \end{array}\right.
xi,d′+1={xi,d′⋅exp(α⋅iter4i)′′2,R2<STxi,d′+Q×L,R2≥ST
2.4 探索者-跟随者自适应调整策略
在 SSA2 算法中,探索者和跟随者的数目比例保持不变,这会导致在迭代前期,探索者的数目相对较少,无法对全局进行充分的搜索,在迭代后期,探索者的数目又相对较多,此时已不需要更多的探索者进行全局搜索, 而需要增加跟随者的数量进行精确的局部搜索。为解决这个问题, 本文提出探 索者-跟随者自适应调整策略, 该策略在迭代前期, 探索者可以占种群数目的多数, 随着迭代次数的 增加, 探索者的数目自适应减少, 跟随者的数目自适应增加, 逐步从全局搜索转为局部精确搜索, 从 整体上提高算法的收敛精度。探索者和跟随者数目调整公式为:
r
=
b
(
tan
(
−
π
t
4
⋅
iter
max
+
π
4
)
−
k
⋅
rand
(
0
,
1
)
)
p
N
u
m
=
r
⋅
N
s
N
u
m
=
(
1
−
r
)
⋅
N
\begin{gathered} r=b\left(\tan \left(-\frac{\pi t}{4 \cdot \text { iter }_{\max }}+\frac{\pi}{4}\right)-k \cdot \operatorname{rand}(0,1)\right) \\ p N u m=r \cdot N \\ s N u m=(1-r) \cdot N \end{gathered}
r=b(tan(−4⋅ iter maxπt+4π)−k⋅rand(0,1))pNum=r⋅NsNum=(1−r)⋅N
式中:
p
N
u
m
p N u m
pNum 为探索者数目,
s
N
u
m
s N u m
sNum 为跟随者数目;
b
b
b 为比例系数, 用于控制探索者和跟随者之间 的数目;
k
k
k 为扰动偏离因子, 对非线性递减的
r
r
r 值进行扰动。
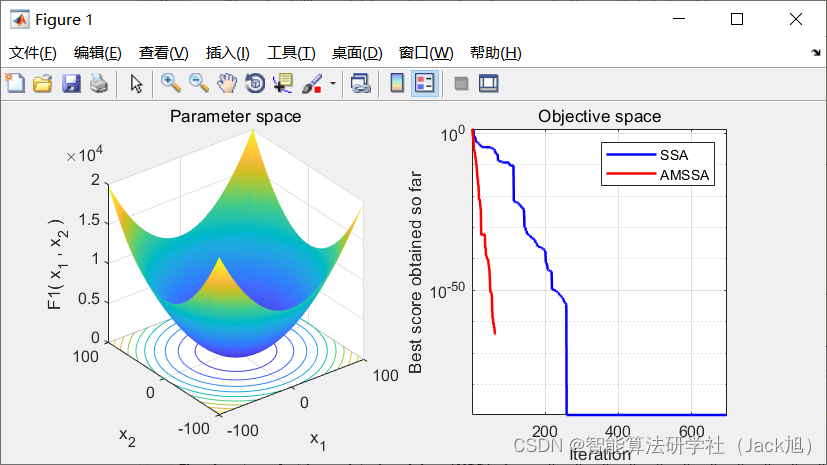
3.实验结果
4.参考文献
[1]唐延强,李成海,宋亚飞,陈晨,曹波.自适应变异麻雀搜索优化算法[J/OL].北京航空航天大学学报:1-14[2021-09-27].https://doi.org/10.13700/j.bh.1001-5965.2021.0282.
5.Matlab代码
6.python代码
相关文章
- 下一代搜索技术:软件管家堪比真人管家
- 理解Lucene索引与搜索过程中的核心类
- Java实现 LeetCode 173 二叉搜索树迭代器
- (算法)二分查找的搜索区间
- python code practice(二):KMP算法、二分搜索的实现、哈希表
- 数据结构与算法之美-11 图 深度和广度优先搜索 [MD]
- NET 查找程序集路径(CLR关于Assembly的搜索路径的过程)
- C语言/C++常见习题问答集锦(六十八) 之二叉搜索树揭秘
- Atitit 知识搜索 信息检索的方法总结 目录 1. 目录搜索1 1.1. 向下同级搜索1 1.2. 向上目录抽象搜索1 2. hash搜索模式1 2.1. 关键词搜索 主题搜索1 2
- Atitit 数据挖掘之道 attilax总结 艾龙著 1. 数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。1 2. 数据(Data)-信息(information)-知识(K
- 给Angular应用增添搜索Search功能
- ML之SVM:利用SVM算法(超参数组合进行多线程网格搜索+3fCrVa)对20类新闻文本数据集进行分类预测、评估
- 混合灰狼和布谷鸟搜索优化算法(Matlab完整代码实现)
- 基于形态学处理算法的迷宫路线搜索matlab仿真
- 基于自适应调整权重和搜索策略的鲸鱼优化算法-附代码
- 一种全局搜索策略的鲸鱼优化算法-附代码
- 具有自适应搜索策略的灰狼优化算法-附代码
- 扇区搜索机制的果蝇优化算法-附代码
- 混沌麻雀搜索优化算法-附代码
- 算法7-4:宽度优先搜索
- 利用ZoomEye探索互联网hikvision摄像头——直接http://www.zoomeye.org/search?q=DVRDVS-Webs即可搜索暴露在公网的摄像头
- 【车间调度】基于黏菌算法算法和变邻域搜索的柔性作业车间调度研究(Matlab代码实现)
- 基于变邻域搜索平衡优化算法与粘菌算法的柔性车间调度(Matlab代码实现)
- 基于Astar算法的智能避障最短路径搜索matlab仿真,可以任意选择起点和终点
- 数据结构和算法 十一、二叉搜索树/AVL树
- 数据结构和算法 十八、图的结构、最短路径、广度优先搜索、深度优先搜索