
【Seq2Seq】通过联合学习对齐和翻译的神经机器翻译
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在第三个关于使用PyTorch和TorchText的序列到序列模型的笔记本中,我们将从 Neural Machine Translation by Jointly Learning to Align and Translate这个模型解决了我们迄今为止最大的困惑,大约27个,而以前的模型大约34个。
简介
提醒一下,以下是通用编码器-解码器模型: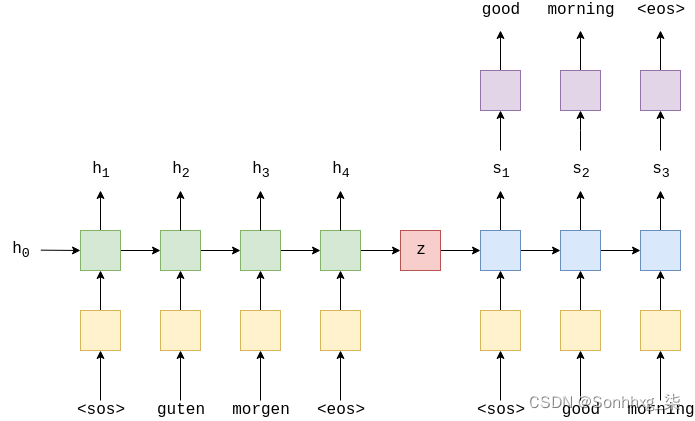
在之前的模型中,我们的架构是通过在每个时间步长将上下文向量显式传递给解码器并通过传递上下文向量和嵌入式输入词d(y(t))来减少“信息压缩”的。,以及隐藏状态,st,到线性层f, 进行预测。
即使我们已经减少了一些压缩,我们的上下文向量仍然需要包含有关源句子的所有信息。本笔记本中实现的模型通过允许解码器在每个解码步骤中查看整个源句子(通过其隐藏状态)来避免这种压缩!它是如何做到这一点的?它使用注意力。
注意力的工作原理是首先计算一个注意力向量a,即源句子的长度。注意向量具有每个元素介于 0 和 1 之间的属性,并且整个向量的总和为 1。然后,我们计算源句子隐藏状态的加权和H,以获得加权源向量w。
解码时,我们每个时间步长都会计算一个新的加权源向量,将其用作解码器RNN的输入以及线性层以进行预测。我们将在本教程中说明如何完成所有这些操作。
准备数据
同样,准备工作与上次类似。
首先,我们导入所有必需的模块。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchtext.legacy.datasets import Multi30k
from torchtext.legacy.data import Field, BucketIterator
import spacy
import numpy as np
import random
import math
import time设置随机种子以提高可重复性。
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True加载德语和英语空间模型。
spacy_de = spacy.load('de_core_news_sm')
spacy_en = spacy.load('en_core_web_sm')我们创建分词器。
def tokenize_de(text):
"""
Tokenizes German text from a string into a list of strings
"""
return [tok.text for tok in spacy_de.tokenizer(text)]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings
"""
return [tok.text for tok in spacy_en.tokenizer(text)]字段与以前相同。
SRC = Field(tokenize = tokenize_de,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)
TRG = Field(tokenize = tokenize_en,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)加载数据
train_data, valid_data, test_data = Multi30k.splits(exts = ('.de', '.en'),
fields = (SRC, TRG))建立词汇量。
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)定义设备。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')创建迭代器。
BATCH_SIZE = 128
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)构建Seq2Seq模型
编码器
首先,我们将构建编码器。与之前的模型类似,我们只使用单层 GRU,但现在使用双向 RNN。使用双向 RNN,我们在每层中有两个 RNN。一个向前的RNN从左到右遍历嵌入的句子(下面以绿色显示),一个向后RNN从右到左遍历嵌入的句子(蓝绿色)。我们在代码中需要做的就是将双向设置为 true,然后像以前一样将嵌入的句子传递给RNN。
我们现在有: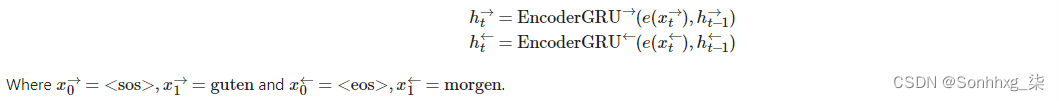
和以前一样,我们只将输入(embedded)传递给RNN,它告诉PyTorch初始化前进和后退的初始隐藏状态(h0 →和h0←,分别) 为所有零的张量。我们还将获得两个上下文向量,一个来自前方RNN,在它看到句子中的最终单词后,z→ = h→T,以及一个来自落后的RNN,在它看到句子中的第一个单词后,z← = h←T
RNN 返回outputs并hidden。
输出的大小为 [src len, batch size, hid dim * num directions],其中第三个轴中的第一个hid_dim元素是来自顶层前向 RNN 的隐藏状态,最后hid_dim元素是来自顶层向后 RNN 的隐藏状态。我们可以将第三轴视为连接在一起的向前和向后隐藏状态,即h1 = [h→1,h←H] , h2 = [h→2,h←H-1], 我们可以将所有编码器隐藏状态(向前和向后连接在一起)表示为H = {h1,h2,...,hT}
.隐藏是大小 [n layers * num directions, batch size, hid dim], 其中 [-2, :, :] 给出顶层前进 RNN 隐藏状态在最后一个时间步长之后(即在它看到句子中的最后一个单词之后),和 [-1, :, :] 给出顶层向后 RNN 隐藏状态在最后一个时间步长之后(即在它看到句子中的第一个单词之后)。
.由于解码器不是双向的,它只需要一个上下文向量z,用作其初始隐藏状态s0,我们目前有两个,一个向前和一个向后(z→ = h→T) 和(z← = h←T) ,分别)。我们通过连接两个上下文向量,将它们传递到线性层并应用激活函数来解决这个问题。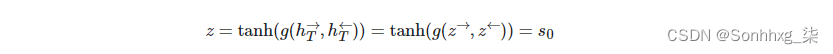
注意:这实际上是与论文的偏差。相反,它们仅通过线性层提供第一个向后RNN隐藏状态,以获得上下文矢量/解码器初始隐藏状态。这对我来说似乎没有意义,所以我们改变了它。
当我们希望模型回顾整个源句子时,我们返回输出,即源句子中每个标记的堆叠向前和向后隐藏状态。我们还返回隐藏状态,它充当解码器中的初始隐藏状态。
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout):
super().__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.GRU(emb_dim, enc_hid_dim, bidirectional = True)
self.fc = nn.Linear(enc_hid_dim * 2, dec_hid_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
#src = [src len, batch size]
embedded = self.dropout(self.embedding(src))
#embedded = [src len, batch size, emb dim]
outputs, hidden = self.rnn(embedded)
#outputs = [src len, batch size, hid dim * num directions]
#hidden = [n layers * num directions, batch size, hid dim]
#hidden is stacked [forward_1, backward_1, forward_2, backward_2, ...]
#outputs are always from the last layer
#hidden [-2, :, : ] is the last of the forwards RNN
#hidden [-1, :, : ] is the last of the backwards RNN
#initial decoder hidden is final hidden state of the forwards and backwards
# encoder RNNs fed through a linear layer
hidden = torch.tanh(self.fc(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1)))
#outputs = [src len, batch size, enc hid dim * 2]
#hidden = [batch size, dec hid dim]
return outputs, hiddenAttention
接下来是注意力层。这将采用解码器的先前隐藏状态st-1,以及编码器H中所有堆叠的向前和向后隐藏状态 。该层将输出一个注意力向量at,即源句子的长度,每个元素介于 0 和 1 之间,整个向量的总和为 1。
.直观地说,这一层采用了我们迄今为止解码的内容st-1,以及我们编码H的所有内容,以生成一个向量at,这表示我们应该最关注源句子中的哪些单词,以便正确预测下一个要解码的单词y^t+1,
首先,我们计算上一个解码器隐藏状态和编码器隐藏状态之间的能量。由于我们的编码器隐藏状态是一系列张量T,而我们之前的解码器隐藏状态是单个张量,我们要做的第一件事就是重复之前的解码器隐藏状态T。然后我们计算能量,Et,通过将它们连接在一起并将它们传递给线性层(attn)和tanh激活函数,在它们之间。![]()
这可以被认为是计算每个编码器隐藏状态与前一个解码器隐藏状态的“匹配”程度。
我们目前为批处理中的每个示例都有一个 [dec hid dim, src len]张量。我们希望对于批处理中的每个示例,这都是 [src len],因为注意力应该在源句子的长度上。这是通过将能量乘以[1, dec hid dim]张量来实现的。
![]()
我们可以将其视v为所有编码器隐藏状态下能量加权和的权重。这些权重告诉我们应该关注源序列中的每个令牌。v的参数是随机初始化的,但通过反向传播与模型的其余部分一起学习。请注意,v如何不依赖于时间,并且对解码的每个时间步长v都使用相同的时间。我们实现v为一个没有偏见的线性层。![]()
这让我们对源句子有了关注!
从图形上看,这看起来像下面这样。这是为了计算第一个注意力向量,其中st-1 = s0 = z
.绿色/蓝绿色块表示来自正向和后向 RNN 的隐藏状态,注意力计算全部在粉红色块内完成。

class Attention(nn.Module):
def __init__(self, enc_hid_dim, dec_hid_dim):
super().__init__()
self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim)
self.v = nn.Linear(dec_hid_dim, 1, bias = False)
def forward(self, hidden, encoder_outputs):
#hidden = [batch size, dec hid dim]
#encoder_outputs = [src len, batch size, enc hid dim * 2]
batch_size = encoder_outputs.shape[1]
src_len = encoder_outputs.shape[0]
#repeat decoder hidden state src_len times
hidden = hidden.unsqueeze(1).repeat(1, src_len, 1)
encoder_outputs = encoder_outputs.permute(1, 0, 2)
#hidden = [batch size, src len, dec hid dim]
#encoder_outputs = [batch size, src len, enc hid dim * 2]
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim = 2)))
#energy = [batch size, src len, dec hid dim]
attention = self.v(energy).squeeze(2)
#attention= [batch size, src len]
return F.softmax(attention, dim=1)解码器
接下来是解码器。
解码器包含注意力层,attention,它采取先前的隐藏状态,st-1,则所有编码器隐藏状态 H,并返回注意向量at,然后,我们使用此注意向量来创建加权源向量wt,,则用加权表示,它是编码器隐藏状态H的加权和,使用at 作为权重。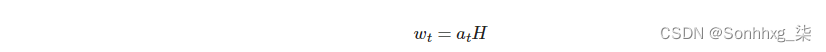
嵌入的输入词d(y(t)),加权源向量wt,以及之前的解码器隐藏状态st-1,然后全部传递到解码器 RNN 中,使用d(y(t)) 和wt 连接在一起。![]()
然后我们通过d(y(t)),wt和st 通过线性层f,对目标句子中的下一个单词进行预测y^t+1,这是通过将它们全部连接在一起来完成的。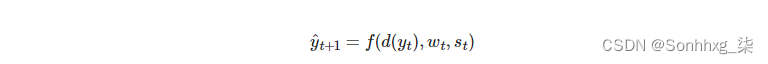
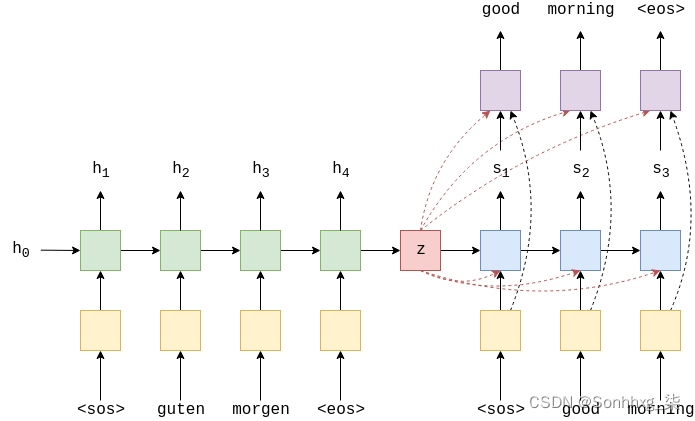
下图显示了对示例翻译中第一个单词的解码。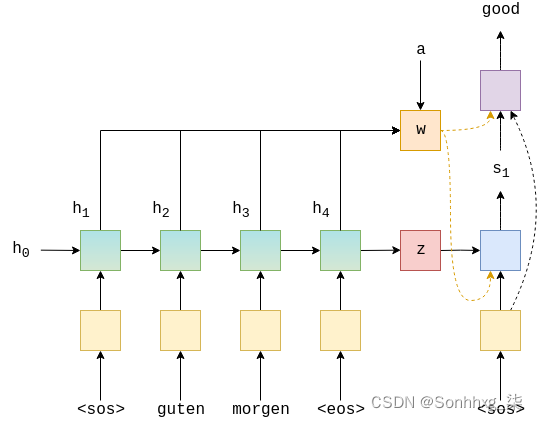
绿色/蓝绿色块显示输出的前向/后退H编码器 RNNs,红色块显示上下文向量,![]() ,蓝色块显示输出st的解码器 RNN
,蓝色块显示输出st的解码器 RNN
,紫色块显示线性层f,输出y^t+1 橙色块显示加权总和的计算H ,at和输出wt.未显示的是计算at
.
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout, attention):
super().__init__()
self.output_dim = output_dim
self.attention = attention
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU((enc_hid_dim * 2) + emb_dim, dec_hid_dim)
self.fc_out = nn.Linear((enc_hid_dim * 2) + dec_hid_dim + emb_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, encoder_outputs):
#input = [batch size]
#hidden = [batch size, dec hid dim]
#encoder_outputs = [src len, batch size, enc hid dim * 2]
input = input.unsqueeze(0)
#input = [1, batch size]
embedded = self.dropout(self.embedding(input))
#embedded = [1, batch size, emb dim]
a = self.attention(hidden, encoder_outputs)
#a = [batch size, src len]
a = a.unsqueeze(1)
#a = [batch size, 1, src len]
encoder_outputs = encoder_outputs.permute(1, 0, 2)
#encoder_outputs = [batch size, src len, enc hid dim * 2]
weighted = torch.bmm(a, encoder_outputs)
#weighted = [batch size, 1, enc hid dim * 2]
weighted = weighted.permute(1, 0, 2)
#weighted = [1, batch size, enc hid dim * 2]
rnn_input = torch.cat((embedded, weighted), dim = 2)
#rnn_input = [1, batch size, (enc hid dim * 2) + emb dim]
output, hidden = self.rnn(rnn_input, hidden.unsqueeze(0))
#output = [seq len, batch size, dec hid dim * n directions]
#hidden = [n layers * n directions, batch size, dec hid dim]
#seq len, n layers and n directions will always be 1 in this decoder, therefore:
#output = [1, batch size, dec hid dim]
#hidden = [1, batch size, dec hid dim]
#this also means that output == hidden
assert (output == hidden).all()
embedded = embedded.squeeze(0)
output = output.squeeze(0)
weighted = weighted.squeeze(0)
prediction = self.fc_out(torch.cat((output, weighted, embedded), dim = 1))
#prediction = [batch size, output dim]
return prediction, hidden.squeeze(0)Seq2Seq
这是我们不必让编码器RNN和解码器RNN具有相同的隐藏尺寸的第一个模型,但是编码器必须是双向的。如果encoder_is_bidirectional enc_dim,则可以通过将enc_dim * 2 的所有出现次数更改为enc_dim * 2 来消除此要求。
这个 seq2seq 封装器与前两个封装器类似。唯一的区别是,编码器返回最终隐藏状态(这是通过线性层传递的正向和后向编码器 RNN 的最终隐藏状态)以用作解码器的初始隐藏状态,以及每个隐藏状态(即彼此堆叠在一起的前进和后向隐藏状态)。我们还需要确保将隐藏和encoder_outputs传递给解码器。
简要介绍所有步骤:
- 创建输出张量来保存所有预测Y^,
- 源序列 X被馈送到编码器中以接收z和H
- 初始解码器隐藏状态设置为上下文向量,s0 = z = hT
- 我们使用一批<sos>代币作为第一个输入y1,
- 然后,我们在一个循环中解码:
插入输入令牌yt,以前的隐藏状态st-1,,并将所有编码器输出 H,输入解码器
接收预测y^t+1,以及一个新的隐藏状态st,
然后,我们决定是否要强制教师,并根据需要设置下一个输入
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio = 0.5):
#src = [src len, batch size]
#trg = [trg len, batch size]
#teacher_forcing_ratio is probability to use teacher forcing
#e.g. if teacher_forcing_ratio is 0.75 we use teacher forcing 75% of the time
batch_size = src.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
#tensor to store decoder outputs
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
#encoder_outputs is all hidden states of the input sequence, back and forwards
#hidden is the final forward and backward hidden states, passed through a linear layer
encoder_outputs, hidden = self.encoder(src)
#first input to the decoder is the <sos> tokens
input = trg[0,:]
for t in range(1, trg_len):
#insert input token embedding, previous hidden state and all encoder hidden states
#receive output tensor (predictions) and new hidden state
output, hidden = self.decoder(input, hidden, encoder_outputs)
#place predictions in a tensor holding predictions for each token
outputs[t] = output
#decide if we are going to use teacher forcing or not
teacher_force = random.random() < teacher_forcing_ratio
#get the highest predicted token from our predictions
top1 = output.argmax(1)
#if teacher forcing, use actual next token as next input
#if not, use predicted token
input = trg[t] if teacher_force else top1
return outputsTraining the Seq2Seq Model
本教程的其余部分与上一个非常相似。
我们初始化我们的参数,编码器,解码器和seq2seq模型(如果有的话,将其放在GPU上)。
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
ENC_HID_DIM = 512
DEC_HID_DIM = 512
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
attn = Attention(ENC_HID_DIM, DEC_HID_DIM)
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, DEC_DROPOUT, attn)
model = Seq2Seq(enc, dec, device).to(device)我们使用本文中使用的权重初始化方案的简化版本。在这里,我们将初始化所有偏差为零,并将所有权重从N(0,0.01) .
def init_weights(m):
for name, param in m.named_parameters():
if 'weight' in name:
nn.init.normal_(param.data, mean=0, std=0.01)
else:
nn.init.constant_(param.data, 0)
model.apply(init_weights)Seq2Seq(
(encoder): Encoder(
(embedding): Embedding(7853, 256)
(rnn): GRU(256, 512, bidirectional=True)
(fc): Linear(in_features=1024, out_features=512, bias=True)
(dropout): Dropout(p=0.5, inplace=False)
)
(decoder): Decoder(
(attention): Attention(
(attn): Linear(in_features=1536, out_features=512, bias=True)
(v): Linear(in_features=512, out_features=1, bias=False)
)
(embedding): Embedding(5893, 256)
(rnn): GRU(1280, 512)
(fc_out): Linear(in_features=1792, out_features=5893, bias=True)
(dropout): Dropout(p=0.5, inplace=False)
)
)
计算参数的数量。从上一个模型中,我们的参数数量增加了近50%。
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')The model has 20,518,405 trainable parameters
我们创建一个优化器。
optimizer = optim.Adam(model.parameters())我们初始化损失函数。
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)然后,我们创建训练循环...
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg)
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)...和评估循环,记住将模型设置为评估模式并关闭teaching forcing。
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output = model(src, trg, 0) #turn off teacher forcing
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)最后,定义一个定时函数。
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs然后,我们训练模型,保存给我们最佳验证损失的参数。
N_EPOCHS = 10
CLIP = 1
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut3-model.pt')
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')Epoch: 01 | Time: 0m 55s Train Loss: 5.018 | Train PPL: 151.167 Val. Loss: 4.869 | Val. PPL: 130.233 Epoch: 02 | Time: 0m 55s Train Loss: 4.143 | Train PPL: 63.018 Val. Loss: 4.677 | Val. PPL: 107.422 Epoch: 03 | Time: 0m 55s Train Loss: 3.490 | Train PPL: 32.780 Val. Loss: 3.803 | Val. PPL: 44.853 Epoch: 04 | Time: 0m 55s Train Loss: 2.913 | Train PPL: 18.421 Val. Loss: 3.438 | Val. PPL: 31.138 Epoch: 05 | Time: 0m 55s Train Loss: 2.505 | Train PPL: 12.238 Val. Loss: 3.300 | Val. PPL: 27.115 Epoch: 06 | Time: 0m 56s Train Loss: 2.207 | Train PPL: 9.088 Val. Loss: 3.267 | Val. PPL: 26.227 Epoch: 07 | Time: 0m 55s Train Loss: 1.960 | Train PPL: 7.103 Val. Loss: 3.220 | Val. PPL: 25.033 Epoch: 08 | Time: 0m 55s Train Loss: 1.745 | Train PPL: 5.725 Val. Loss: 3.234 | Val. PPL: 25.376 Epoch: 09 | Time: 0m 55s Train Loss: 1.570 | Train PPL: 4.806 Val. Loss: 3.249 | Val. PPL: 25.760 Epoch: 10 | Time: 0m 55s Train Loss: 1.461 | Train PPL: 4.311 Val. Loss: 3.362 | Val. PPL: 28.854
最后,我们使用这些“最佳”参数在测试集上测试模型。
model.load_state_dict(torch.load('tut3-model.pt'))
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')| Test Loss: 3.179 | Test PPL: 24.027 |
我们在之前的模型上进行了改进,但这是以将训练时间加倍为代价的。
在下一个笔记本中,我们将使用相同的架构,但使用一些适用于所有RNN架构的技巧 - 填充序列和掩码。我们还将实现代码,这将使我们能够查看RNN在解码输出时注意输入中的哪些单词。
相关文章
- 【原创】机器学习之PageRank算法应用与C#实现(2)球队排名应用与C#代码
- 深度学习 | 如何开发、部署 Serverless 应用?
- 通过这些示例快速学习Java lambda语法
- 【学习总结】网络-应用层-万维网和HTTP
- 【学习总结】GirlsInAI ML-diary day-20-初识 Kaggle
- Scala - 快速学习08 - 函数式编程:高阶函数
- Lucene5学习之多索引目录查询以及多线程查询
- 机器学习笔记 - R语言学习入门系列一
- 83. 一静一动,一张一弛 - 通过具体的两个例子,学习 ABAP 动态断点的使用诀窍
- 通过最简单的button控件,深入学习SAP UI5框架代码系列之零
- 通过一个具体的例子学习Threadlocal Test
- 通过 describe 命令学习 Kubernetes 的 pod 属性详解
- [转]向facebook学习,通过协程实现mysql查询的异步化
- Atitit 人工智能 统计学 机器学习的相似性 一些文摘收集 没有人工智能这门功课,人工智能的本质是统计学和数学,就是通过机器对数据的识别、计算、归纳和学习,然后做出下一步判断和决策的科学
- 通过一个实际的例子学习 combineLatest
- FedDG:在连续频率空间中通过情景学习进行医学图像分割的联合域泛化
- Python Flask框架学习29:项目管理器Manager/传递参数/优化项目代码结构
- 迁移学习(DANN)《Unsupervised Domain Adaptation by Backpropagation》
- 2022年你应该掌握这些机器学习算法
- 机器学习——最小二乘法
- 3.1日学习笔记|3.2日学习笔记
- SENet(Squeeze-and-Excitation Networks)算法笔记---通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征
- 迁移学习
- Wireshark基本介绍和学习TCP三次握手 转
- Python学习之CSDN21天学习挑战赛计划 day1
- 【机器学习】3、决策树
- Binder基本概念流程学习