
集成学习中的随机森林
摘要:随机森林是集成算法最前沿的代表之一。随机森林是Bagging的升级,它和Bagging的主要区别在于引入了随机特征选择。
本文分享自华为云社区《集成学习中的随机森林》,原文作者:chengxiaoli。
随机森林是集成算法最前沿的代表之一。随机森林是Bagging的升级,它和Bagging的主要区别在于引入了随机特征选择。即:在每棵决策树选择分割点时,随机森林会先随机选择一个特征子集,然后在这个子集上进行传统的分割点选择。
随机森林
随机森林的构造过程:假如有N个样本,则有放回的随机选择N个样本(每次随机选择一个样本,然后返回继续选择)。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
决策树形成过程中每个节点都要按照上面步骤来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了)。一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
按照上述步骤建立大量的决策树,这样就构成了随机森林了。在建立每一棵决策树的过程中,有两点需要注意采样与完全分裂。
首先是两个随机采样的过程,random forest对输入的数据要进行行、列的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。然后进行列采样,从M个feature中,选择m个(m << M)。
之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。一般很多的决策树算法都一个重要的步骤——剪枝,但是这里不这样干,由于之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现over-fitting。
输入:数据集D={(x1,y1),(x2,y2),…,(xm,ym)};
特征子集大小K。
步骤:
- Nß给定数据集D构建节点;
- If所有样本属于一个类别 thenreturn N;
- Fß可以继续分类的特征集合;
- If F 为空 thenreturn N;
- Fiß从F中随机选择K个特征;
- N.fß特征Fi中具有最好分割点的特征;
- N.pßf中最好的分割点;
- DlßD中N.f值小于N.p的样本子集;
- DrßD中N.f值不小于N.p的样本子集;
- Nlß以参数(Dl,K)继续调用本程序;
- Nrß以参数(Dr,K)继续调用本程序;
- Return N.
输出:一棵随机决策树。
随机森林和Bagging
以上是随机森林中使用的随机决策树算法。参数K用来控制随机性。当K等于所有特征总数时,构建的决策树等价于传统确定性的决策树;当K=1时,会随机选择一个特征;建议K值为特征数的对数。随机树只在特征选择阶段引入随机性,在选择分割点时不会引入。
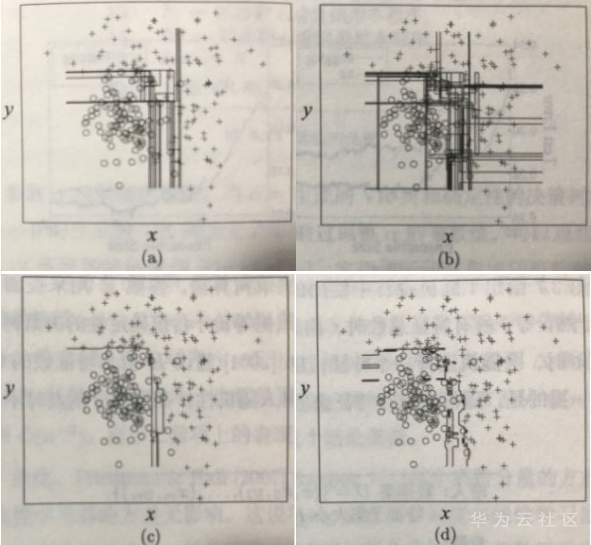
图a:Bagging的10个基学习器;图b:随机森林的10个基学习器;图c:Bagging;图d:随机森林。
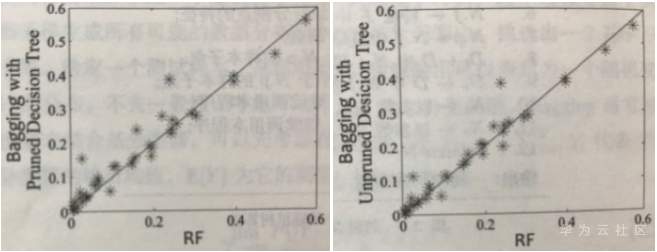
随机森林和Bagging在40个UCI数据集上预测错误的对比。每个点为一个数据集,点的坐标为两个对比算法的预测误差。对角线标出两个对比算法相同预测误差的位置。
比较了随机森林,Bagging和它们基分类器的决策边界。由图可见随机森林和它的基学习器的决策边界比较灵活,因而具有更好的泛化能力。在高斯数据集上,随机森林的测试错误率为7.85%,而Bagging为8.3%。以上图中比较了随机森林和Bagging在40个UCI数据集上的预测错误。很明显,无论使用剪枝还是未剪枝的决策树,随机森林的预测精度都优于Bagging的结果。
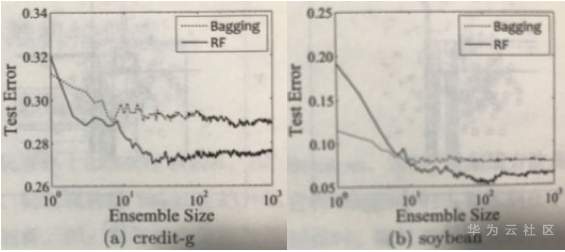
集成规模在2个UCI数据集上对随机森林和Bagging的影响。
随机森林的收敛性和Bagging相似。随机森林的起始点一般较差,特别是当集成规模为1时,随机特征选择会导致决策树性能退化;但是,它通常可以收敛到很低的测试误差。在训练的阶段,随机森林的收敛比Bagging更快速。这是因为,在决策树的构建阶段,Bagging使用的全量的特征进行分割选择,进而生成确定性的决策树,而随机森林仅需要使用随机选择的特征来生成随机决策树。
总结:
组合分类器比单一分类器的分类效果好,随机森林(random forest)是一种利用多个分类树对数据进行判别与分类的方法,它在对数据进行分类的同时,还可以给出各个变量(基因)的重要性评分,评估各个变量在分类中所起的作用。
[1] 陈雷.深度学习与MindSpore实践[M].清华大学出版社:2020.
[2] 诸葛越,葫芦娃.百面机器学习[M].人民邮电出版社:2020.
[3] 周志华.机器学习[M].清华大学出版社:2016.
相关文章
- cdh集成Spark2.2后spark-shell启动报错解决
- Jmeter集成Jira提交缺陷
- 机器学习 - pycharm, pyspark, spark集成篇
- Jenkins+Git 集成测试(build、zip、curl)
- 支付宝支付集成,上传RSA公钥一直显示格式错误
- Python视觉深度学习系列教程 第二卷 第5章 使用神经网络集成提高准确性
- 机器学习笔记 - 基于python库Scikit-Learn的集成学习
- activiti-study 集成 学习
- 使用JAD集成到Eclipse里去,方便地查看任意Java类的源代码
- php学习: WAMPServer集成环境的下载、安装、配置
- ML之回归预测:利用Lasso、ElasticNet、GBDT等算法构建集成学习算法AvgModelsR对国内某平台上海2020年6月份房价数据集【12+1】进行回归预测(模型评估、模型推理)
- 机器学习(九):集成学习(bagging和boosting),随机森林、XGBoost、AdaBoost
- 机器学习的集成方法(bagging、boosting)
- 学习Spring Boot:(六) 集成Swagger2
- SpringBoot学习笔记(四)——Spring Boot集成MyBatis起步
- 集成学习-幸福感预测案例分析
- Jenkins+Docker+SpringCloud微服务持续集成(上)
- 【Ensemble Learning】第 5 章: 使用集成学习库
- UVM寄存器模型:reg adapter实现和集成