
基于形态学处理的车牌提取,字符分割和车牌识别算法matlab仿真
目录
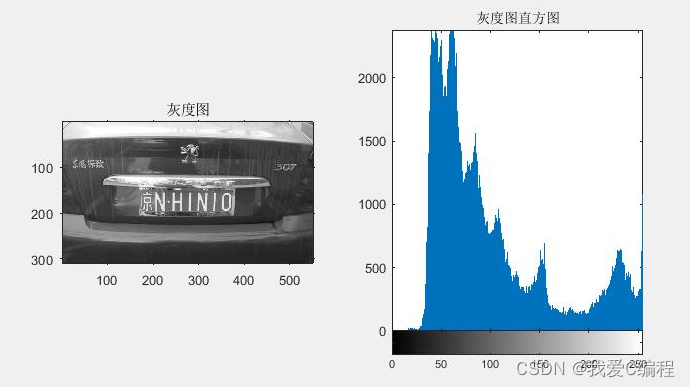
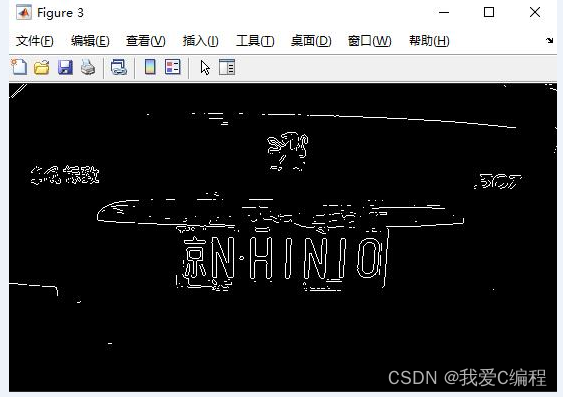
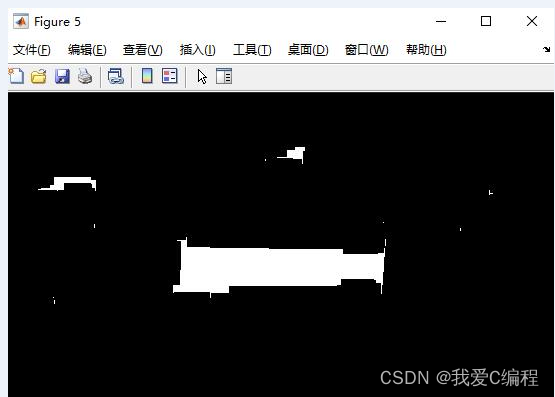
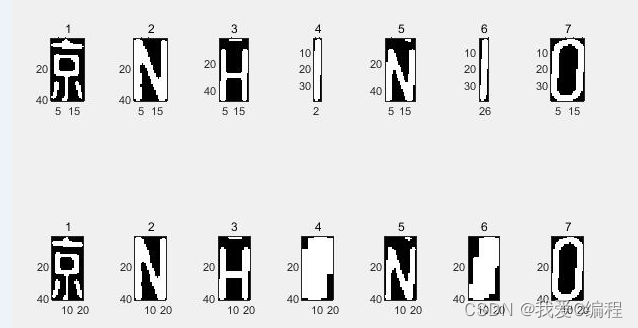
1.算法仿真效果
matlab2022a仿真结果如下:



2.MATLAB核心程序
...........................................................................
figure(8);subplot(3,2,2),imshow(d),title('2.车牌二值图像')
figure(8),subplot(3,2,3),imshow(d),title('3.均值滤波前')
% 均值滤波处理
h=fspecial('average',3);
d=im2bw(round(filter2(h,d)));%filter2(B,X),B为滤波器.X为要滤波的数据,这里将B放在X上,一个一个移动进行模板滤波.
figure(8),subplot(3,2,4),imshow(d),title('4.均值滤波后')
se=eye(2);%产生m×n的单位矩阵
[m,n]=size(d);
if bwarea(d)/m/n>=0.365 %bwarea是计算二值图像中对象的总面积的函数
d=imerode(d,se);%腐蚀
elseif bwarea(d)/m/n<=0.235
d=imdilate(d,se);%膨胀
end
.........................................................
% 再切割
d=qiege(d);
% 切割出 7 个字符
y1=10;y2=0.25;flag=0;word1=[];
while flag==0
[m,~]=size(d);
left=1;wide=0;
while sum(d(:,wide+1))~=0
wide=wide+1;
end
if wide<y1 % 认为是左侧干扰
d(:,1:wide)=0;
d=qiege(d);
else
temp=qiege(imcrop(d,[1 1 wide m]));
[m,~]=size(temp);
all=sum(sum(temp));
two_thirds=sum(sum(temp(round(m/3):2*round(m/3),:)));
if two_thirds/all>y2
flag=1;word1=temp; % 此处为切割出来的WORD 1
end
d(:,1:wide)=0;d=qiege(d);
end
end
.....................................................................
JG=zeros(40,20);%产生一个40*20大小的零矩阵
l=1;
L=toc;
for I=1:7 %I为待识别的字符位
ii=int2str(I);%整形数据转化为字符串类型
t=imread([ii,'.jpg']);
MB=imresize(t,[40 20],'nearest');%缩放处理
if l==1 %车牌号第一位为汉字识别,使用37-53号样本库
kmin=37;
kmax=53;
elseif l==2 %车票号第二位为 A~Z 大写字母识别,使用11-36号样本库
kmin=11;
kmax=36;
else l>=3; %第三位以后是字母或数字识别,使用1-36号样本库
kmin=1;
kmax=36;
end
for k2=kmin:kmax
fname=strcat('样本库\',liccode(k2),'.bmp');
YB = imread(fname); %调用样本库图像文件
for i=1:40
for j=1:20
JG(i,j)=MB(i,j)-YB(i,j); % 这里是将待识别图像与模板图像两幅图相减得到第三幅图
end
end
Dmax=0;
for k1=1:40
for l1=1:20
if ( JG(k1,l1) > 0 || JG(k1,l1) <0 )
Dmax=Dmax+1;
end
end
end
Error(k2)=Dmax;
end
Error1=Error(kmin:kmax);
MinError=min(Error1);
findc=find(Error1==MinError);
Code(l*2-1)=liccode(findc(1)+kmin-1);
Code(l*2)=' ';
l=l+1;
end
t=toc;
figure(10),imshow(dw),title (['车牌号:', Code]);
A3893.算法涉及理论知识概要
车牌识别系统(Vehicle License Plate Recognition,VLPR) 是计算机视频图像识别技术在车辆牌照识别中的一种应用。车牌识别在高速公路车辆管理中得到广泛应用,电子收费(ETC)系统中,也是结合DSRC技术识别车辆身份的主要手段。
车牌识别技术要求能够将运动中的汽车牌照从复杂背景中提取并识别出来,通过车牌提取、图像预处理、特征提取、车牌字符识别等技术,识别车辆牌号、颜色等信息,最新的技术水平为字母和数字的识别率可达到99.7%,汉字的识别率可达到99%。在停车场管理中,车牌识别技术也是识别车辆身份的主要手段。在深圳市公安局建设的《停车库(场)车辆图像和号牌信息采集与传输系统技术要求》中,车牌识别技术成为车辆身份识别的主要手段。
车牌识别技术结合电子不停车收费系统(ETC)识别车辆,过往车辆通过道口时无须停车,即能够实现车辆身份自动识别、自动收费。在车场管理中,为提高出入口车辆通行效率,车牌识别针对无需收停车费的车辆(如月卡车、内部免费通行车辆),建设无人值守的快速通道,免取卡、不停车的出入体验,正改变出入停车场的管理模式。
随着交通现代化的发展要求,汽车牌照自动识别技术已经越来越受到人们的重视。车牌自动识别技术中车牌定位、字符切割、字符识别及后期处理是其关键技术。由于受到运算速度及内存大小的限制,以往的车牌识别大都是基于灰度图象处理的识别技术。其中首先要求正确可靠地检出车牌区域,为此提出了许多方法,如Hough变换以检测直线来提取车牌边界区域、使用灰度分割及区域生长进行区域分割,或使用纹理特征分析技术等。Hough变换方法对车牌区域变形或图象被污损时失效的可能性会大大增加,而灰度分割则比直线检测的方法要稳定,但当图象在有许多与车牌的灰度非常相似的区域时,该方法也就无能为力了。纹理分析在遇到类似车牌纹理特征的其他干扰时,车牌定位正确率也会受到影响。本文提出基于车牌彩色信息的彩色分割方法。
主要模块如下:颜色信息提取、车牌区域定位、识别、提取、检测倾斜度、车牌校正、车牌区域二值化、擦除干扰区域、文字分割、模版匹配、结果输出。
1 颜色信息提取
针对家庭小型车蓝底白字车牌进行识别。根据彩色图像的RGB比例定位出近似蓝色的候选区域。但是由于RGB三原色空间中两点间的欧氏距离与颜色距离不成线性比例,在设定蓝色区域的定位范围时不能很好的控制。因此造成的定位出错是最主要的。这样在图片中出现较多的蓝色背景情况下识别率会下降,不能有效提取车牌区域。
2 倾斜校正
针对倾斜角度的图片采取rando算法进行倾斜角度计算,并对倾斜图片进行修正,从而得到与水平方向一致的图片,有利于后期的图片分割及图像识别。
3.字符分割
计算得到车牌区域分割后的图象,对其白色像素进行水平垂直投影,并计算水平垂直峰值,检测合理的字符高宽比。可用与区域分割相同的方法进行峰值的删除与合并。但在字符分割时,往往由于阈值取得不好,导致字符分割不准确。针对这种情况,可以由车牌格式的先验知识,对分割出的字符宽度进行统计分析,用以指导分割,对因错误分割过宽的字符进行分裂处理。
4.字体识别
常用做法是采用神经网络模型对系统进行训练。但是这种做法增加了系统的复杂度,对实时性要求较高的场合不适应。这里采用简单模版匹配算法。由于在前期的有效处理使得分割后的字体清晰度完整度都能保持较高的水平。有利于提高模版匹配的成功率。
4.完整MATLAB
V
相关文章
- 微信小程序二维码是无法识别二维码跳转到小程序
- atitit.短信 验证码 破解 v3 p34 识别 绕过 系统方案规划----业务相关方案 手机验证码 .doc
- 基于RBF神经网络的非线性系统识别(Matlab代码实现)
- 基于时空RBF-NN进行非线性系统识别(Matlab代码实现)
- 基于汉克尔矩阵 (BMIDHM) 的盲模态识别研究(Matlab代码实现)
- 【目标识别】检测具有相同背景的不同图像并找到图像中的红色圆圈目标(Matlab代码实现)
- 使用 KTH 数据集进行人类行为识别(Matlab代码实现)
- OpenCV头像识别采集训练数据
- 【图像处理】基于MATLAB的RGB车牌识别
- 跟我读论文丨ACL2021 NER 模块化交互网络用于命名实体识别
- m分别通过matlab和FPGA实现基于高阶循环谱的信号载波调制识别(四阶循环累量)仿真
- m基于GRNN广义回顾神经网络的车牌字符分割和识别算法matlab仿真
- m基于SVM和拍摄照片特征的相机品牌类型识别matlab仿真
- 使用matlab机器视觉工具箱实现人脸特征的检测和定位,识别并标注眉毛,眼睛,鼻子,嘴巴
- 基于OCR模板匹配的手写英文字母数字识别matlab仿真
- m基于HMM和博弈模型的LSTM互联网情感词性分类识别matlab仿真
- m基于CNN卷积网络和GEI步态能量图的步态识别算法MATLAB仿真,测试样本采用现实拍摄的场景进行测试,带GUI界面
- 基于步态能量图和CNN卷积神经网络的人体步态识别matlab仿真
- Python爬虫:tesseract识别图片验证码
- 网页浏览器内核识别及版本号差异
- 解决erlang R17无法识别中文问题
- Paddle入门实战系列(三):基于CRNN的文本字符交易验证码识别
- 华为RH2288 V3服务器新加硬盘不识别
- 基于汉克尔矩阵 (BMIDHM) 的盲模态识别研究(Matlab代码实现)
- 基于人工神经网络的类噪声环境声音声学识别(Matlab代码实现)
- Pytorch总结十六之优化算法:图像增广训练模型、微调(迁移学习)实现热狗识别
- 【Transformers】第 4 章 :多语言命名实体识别
- 一、贴片电阻大小的识别与常用的原理图标注规范