
机器学习笔记 - 1、CNN中的参数解释
一、引言
设计深度学习模型的时候,不管是自己从头搭建还是修改别人的,都离不开相关参数的计算,主要是输入图形先后经过卷积、池化层后输出尺寸的变化,尤其是涉及多个卷积或池化层时,如果对这两种操作的原理不清楚,就会对网络的各个参数产生困惑,不知道如何去修改以便适配自己的业务场景。
这里对CNN(卷积神经网络)中的主要参数的计算做一个归纳整理,方便参考。我们先用图示的方式给出这两种操作的运行过程,最后再归纳出数学公式。
注意:本文主要是结合Tensorflow来讲的,不同的平台会有所差异。
二、术语解释
CNN网络的主要参数有下面这么几个:
- 卷积核Kernal(在Tensorflow中称为filter);
- 填充Padding;
- 滑动步长Strides;
- 池化核Kernal(在Tensorflow中称为filter);
- 通道数Channels。
2.1 卷积核
顾名思义,卷积核是在进行卷积操作的时候使用的,在Tensorflow中,被称为filter,通过一个四元列表传递。文档中对该参数的说明如下:
"""
filter: A `Tensor`. Must have the same type as `input`.
A 4-D tensor of shape
`[filter_height, filter_width, in_channels, out_channels]`
"""
# 定义一个大小为3*2,输入channel为3,输出channel为64的filter
conv_kernal = [3, 2, 3, 64]卷积核的示意图如下图中间部分(这里的卷积核大小为3*3)所示:
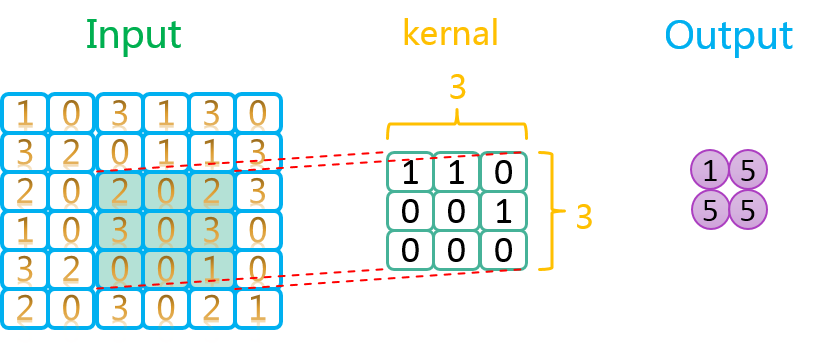
由上图可知,卷积这一步的操作,实际上是在输入数据上取与卷积核大小相同的矩阵,然后与卷积核矩阵进行逐元素乘积
),然后求这个乘积矩阵所有元素的和,作为卷积的结果。
需要说明的是,这里的卷积跟我们信号与系统里面的卷积有所差异。
上面提到的通道数(in_channels、out_channels)实际上就是我们的feature_map的数量。因为不同的卷积核卷积出来的feature_map是不一样的,因此有多少个out_channels,就有多少个不同的卷积核。关于这点,会在后边的通道参数里面解释。
对于直接与输入层连接的卷积层来说,输入通道数in_channels,图片通常为3(因为包含R、G、B三色矩阵),文本则通常为1。
2.2 填充
填充在卷积和池化这两个操作里面都可能会用到,填充的作用主要是尽可能充分的保留和使用输入特征(如果不使用填充,网络层数越深,所丢失的边缘数据就越多,到最后可能无特征可用),同时也应注意填充的尺寸不宜过大,避免引入过多无用的数据。
关于填充作用的说明还可以参考知乎上的这篇文章。Tensorflow中的填充只有两种类型,说明如下:
"""
padding: A `string` from: `"SAME", "VALID"`.
The type of padding algorithm to use.
"""
# VALID 对应的是不填充,即不做任何处理。
# SAME 这种填充方式在strides=1的情况下,使得输出能够保持和输入尺寸一致。 Theano中的填充则有不填充、半填充、全填充三种,它的半填充对应Tensorflow的SAME。
SAME类型以0进行填充的示意图如下:
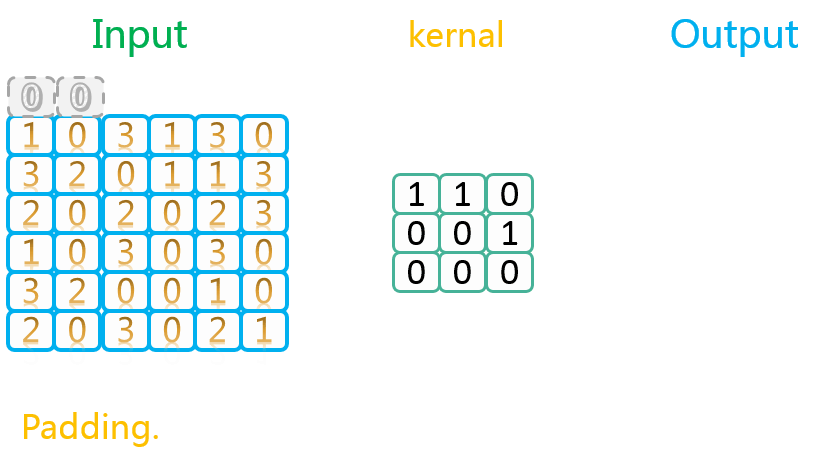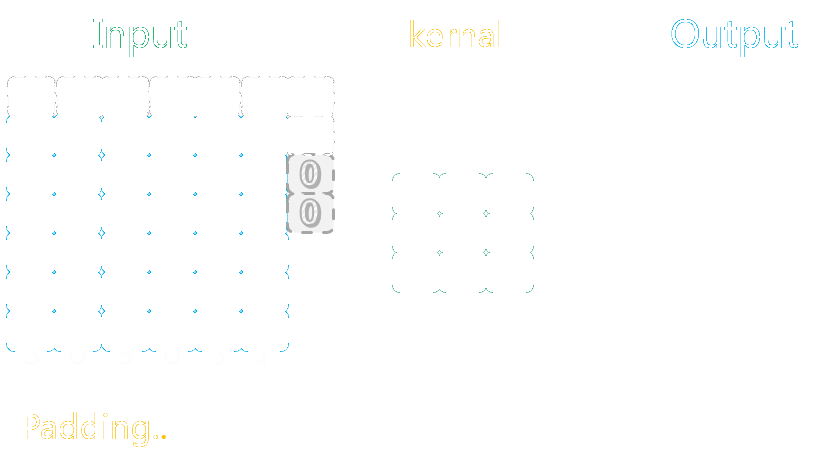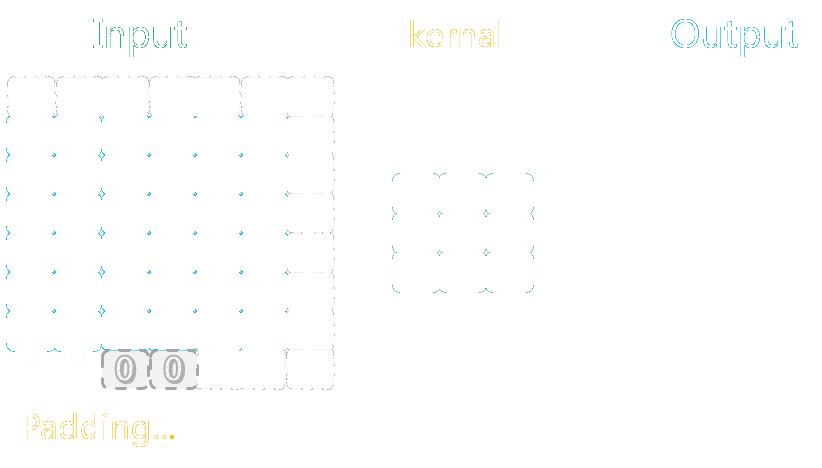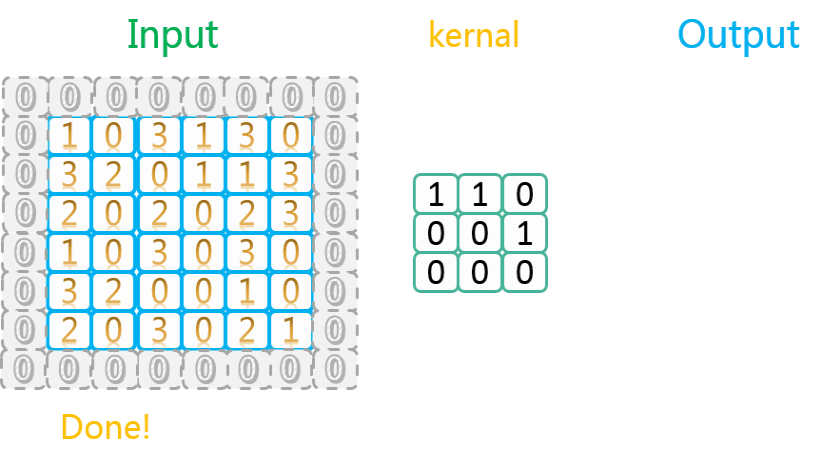
可以看到,这个操作实际上是在原始数据外面包裹了一层填充数据。
2.3 滑动步长
滑动步长决定了在卷积或者池化的过程中,每次操作后移动的步数。在Tensorflow中,该参数也是一个四元列表,关于该参数的解释如下:
"""
strides: A list of `ints`.
1-D tensor of length 4. The stride of the sliding window for each
dimension of `input`. The dimension order is determined by the value of `data_format`, see below for details.
strides = [batch, height, width, channels]
"""
# 定义一个不跳过任何样本、不跳过任何颜色通道,垂直方向步长为2,水平方向步长为2的strides
strides = [1, 2, 2, 1]它的第2、3个参数分别对应在数据垂直和水平方向上的滑动步长。第1个参数表示在样本上的跳跃幅度,一般都是置为1(表示不会跳过任何样本)。第4个参数表示在通道上的跳跃幅度,通常也是置为1。更详细的可参见Stackoverflow上的讨论以及该博客。
python - Tensorflow Strides Argument - Stack Overflow![]() https://stackoverflow.com/questions/34642595/tensorflow-strides-argumentTensorFlow strides 参数讨论_https://space.bilibili.com/59807853-CSDN博客更详细地讨论见 stackoverflow:Tensorflow Strides Argument卷积神经网络(CNN)在 TensorFlow 实现时涉及的 tf.nn.con2d(二维卷积)、tf.nn.max_pool(最大池化)、tf.nn.avg_pool(平均池化)等操作都有关于 strides(步长)的指定,因为无论是卷积操作还是各种类型的池化操作,都是某种形式的滑动窗口(slidin
https://stackoverflow.com/questions/34642595/tensorflow-strides-argumentTensorFlow strides 参数讨论_https://space.bilibili.com/59807853-CSDN博客更详细地讨论见 stackoverflow:Tensorflow Strides Argument卷积神经网络(CNN)在 TensorFlow 实现时涉及的 tf.nn.con2d(二维卷积)、tf.nn.max_pool(最大池化)、tf.nn.avg_pool(平均池化)等操作都有关于 strides(步长)的指定,因为无论是卷积操作还是各种类型的池化操作,都是某种形式的滑动窗口(slidinhttps://blog.csdn.net/lanchunhui/article/details/61615714 卷积过程中的滑动过程示意如下:
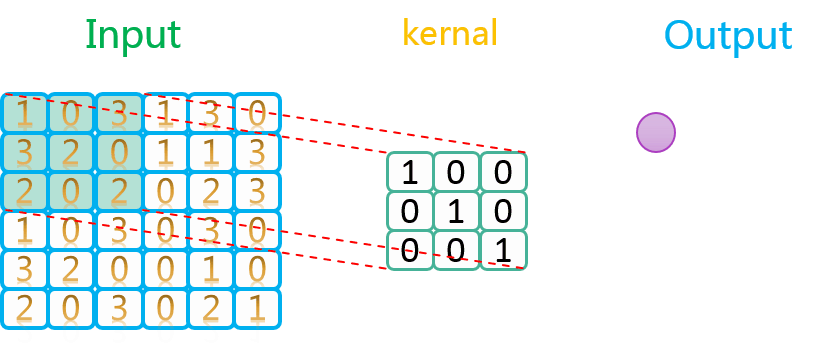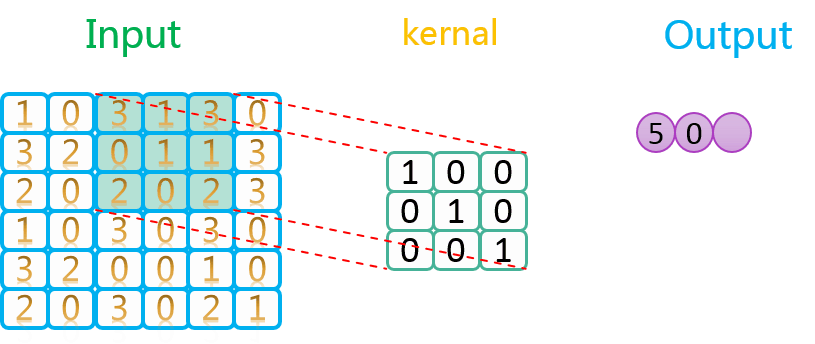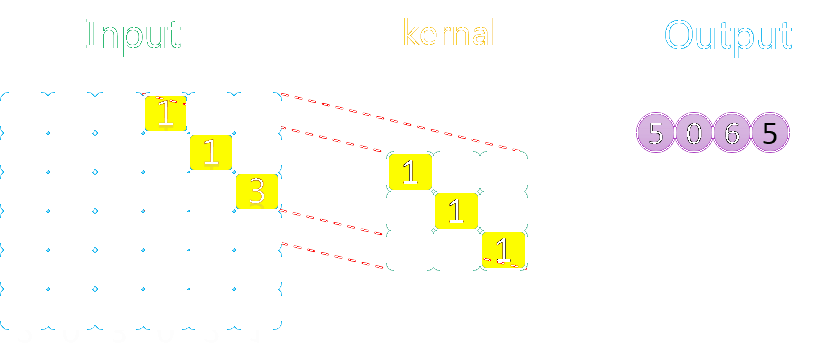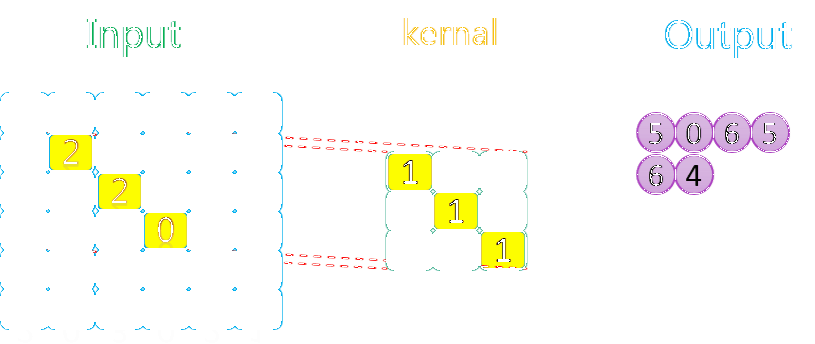
由上图可知,卷积核在输入数据上的操作顺序是先沿着水平方向,再沿着垂直方向。因为水平方向上步长为1,所以卷积核在水平方向上每操作一次,就往右移动一格,再进行下一次操作。当水平方向上操作完了以后,就回到最左边,在垂直方向向下移动一格,然后进行操作,如此往复循环,直到所有数据均处理完。
此外需要说明的是,由于卷积核中值为0的部分对最终的结果没有任何贡献,因此在动图中卷积的时候没有高亮(黄色)显示,并不代表它们没有参与卷积。另外输入和卷积核的元素可以是任意值(上图只是为方便举的简单例子)。
如果你把卷积核看做单反的取景框,把输入数据当作我们的风景,卷积核在输入上的移动过程就类似于我们拍全景照的过程,从左往右,从上往下。
我们再来看看水平、垂直方向上滑动步长均为2并且使用了SAME方式填充的情况,如下图所示:

由上图可知,其操作流程与步长为1时并没有区别,只不过每次沿水平/垂直方向挪动的步长为2。另外不太一样的地方是,对于有填充的数据,卷积核的取景(取值)范围不会超出填充数据(第一行最后一次移动)。
2.4 池化核
池化核则是在进行池化操作时候的Kernal,池化的作用类似于PCA,可以有效的对数据降维同时保留关键特征。常用的池化核有如下几种类型:
- 最大池化核,取池化数据(
取景框取出来的所有数据)的最大值; - 平均池化核,取池化数据的平均值;
- 最小池化核,取池化数据的最小值;
- L2池化核,取池化数据的L2范数;
下图分别展示了步长分别为1、2时的最大池化过程:
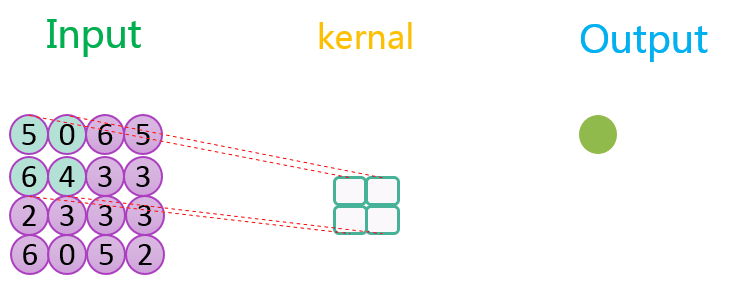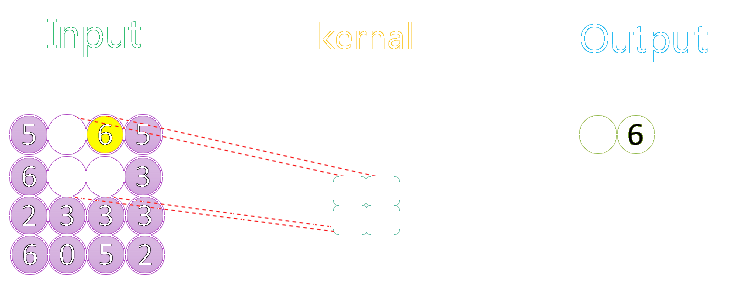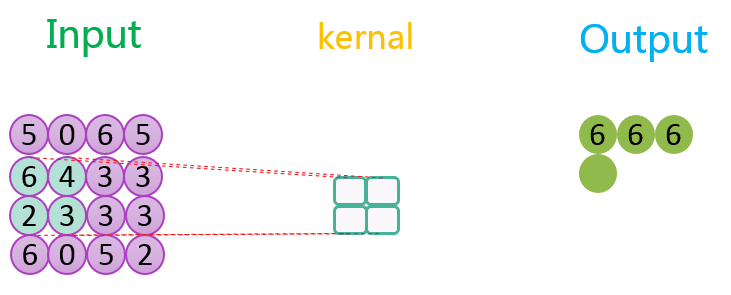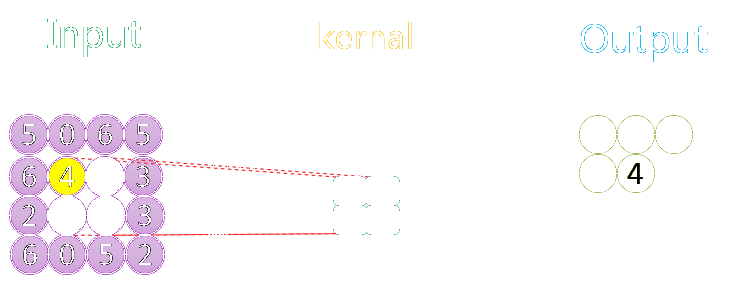
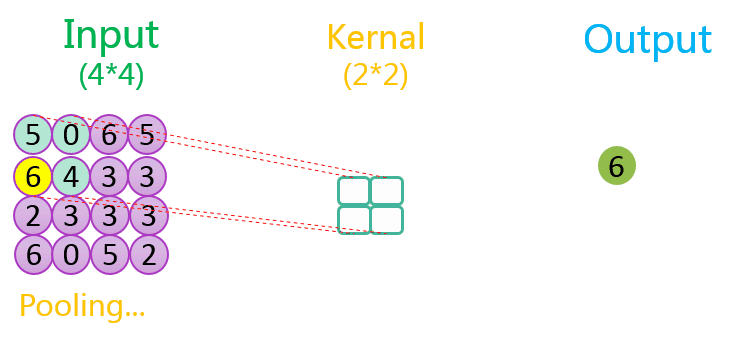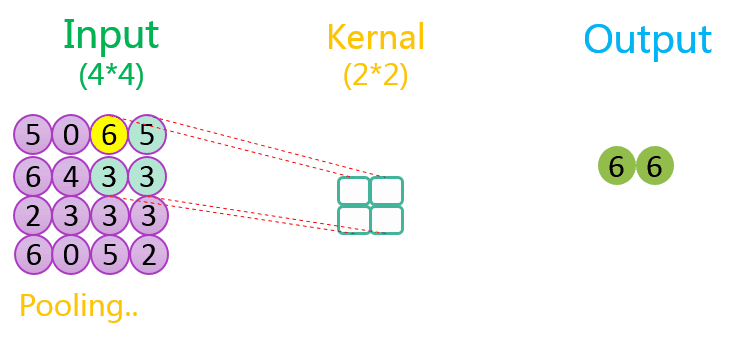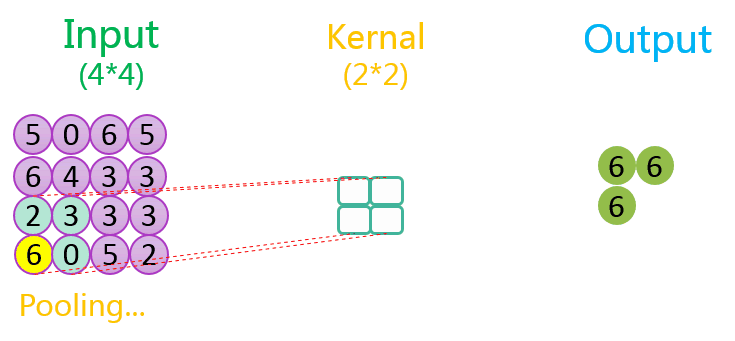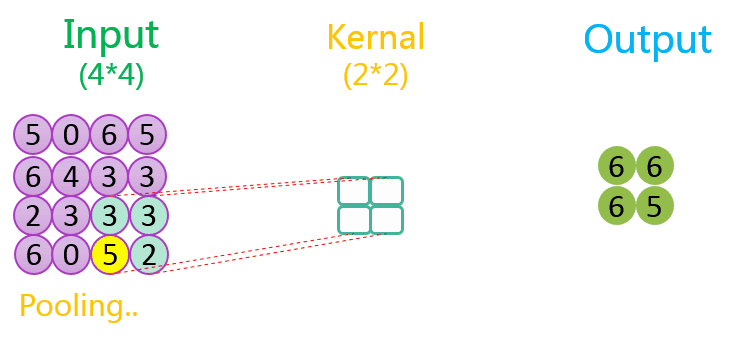
关于池化的作用可参考该CSDN博客。
2.5 通道数
从上面的介绍我们可以看出,对于同一个输入矩阵,改变卷积核的元素值,将会产生不同的输出。因此,卷积核的数量决定了卷积操作之后生成的feature map(卷积核在输入上卷积后的输出矩阵我们称为feature map)数量。
对于CNN来说,其隐藏层部分,上一层的卷积核(即为该层的输出通道数out_channels)数量决定了下一层的输入通道数(in_channels)。输入层部分,输入的类型决定了第一个隐藏层的输入通道数。对于图片数据来说,会拆分成3个输入矩阵,分别对应RGB三原色,如下图所示:
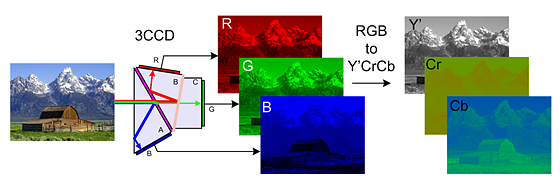
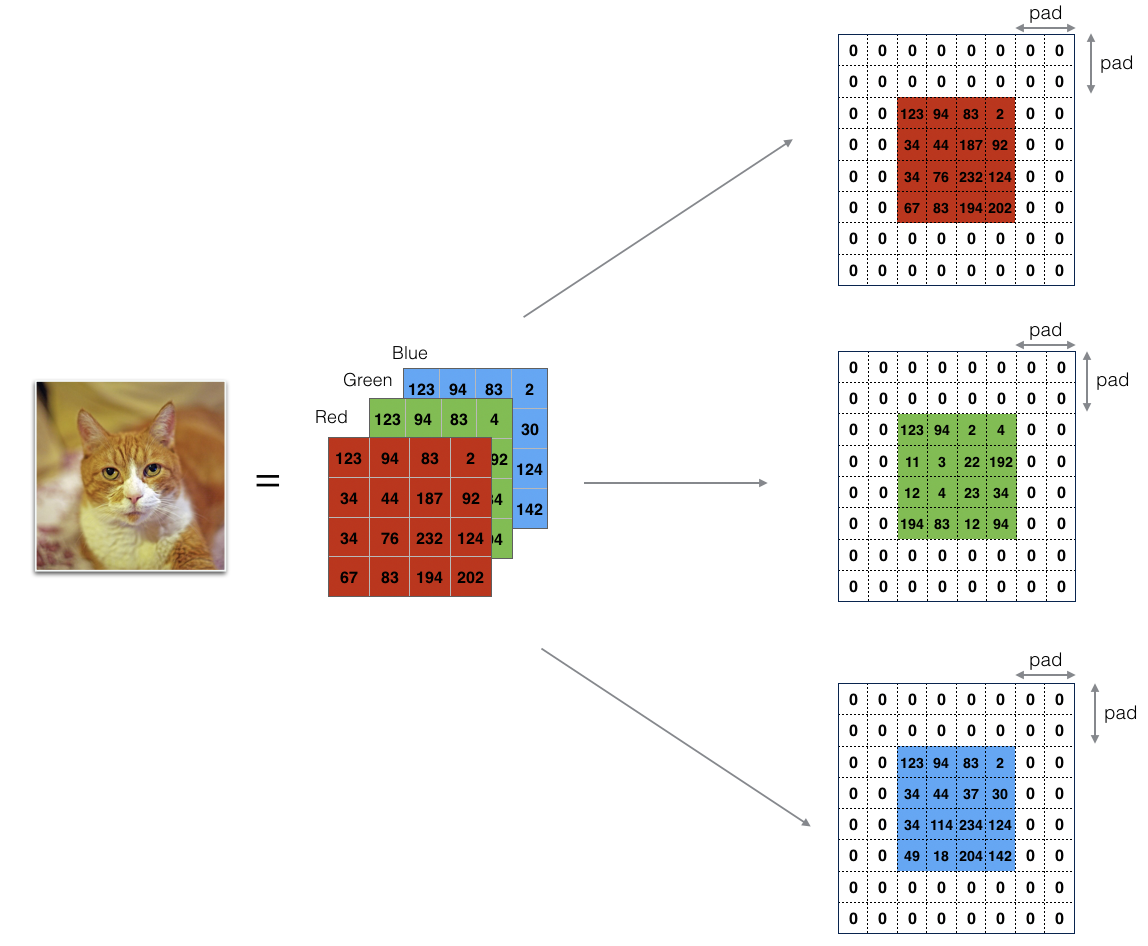
当然图片如果是以CMYK格式存储的,那么输入通道数就会变成4个。而对于文本类的输入,其通道数则只有1个。当然,也可以通过reshape操作后把文本输入变成3通道的数据(将文本数据模拟成图像,360曾经把网络流量转换成黑白图片,并用来训练DNN模型,从而判别是否包含恶意数据,这个想法真的是非常有创意。详见下面链接)。
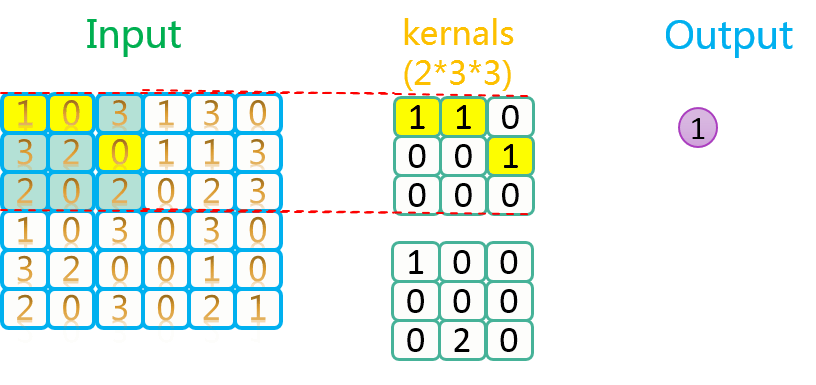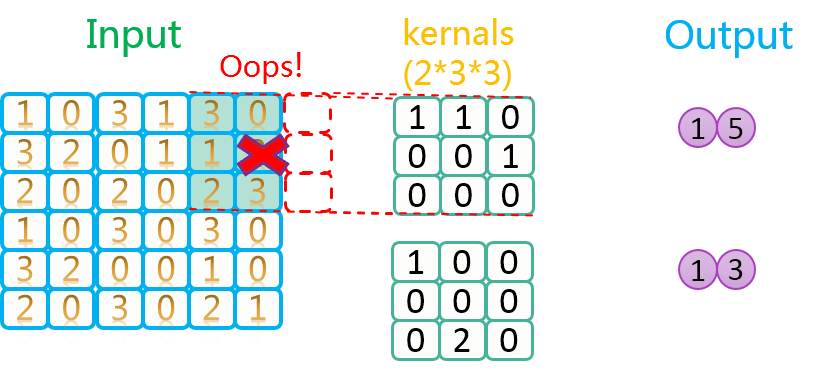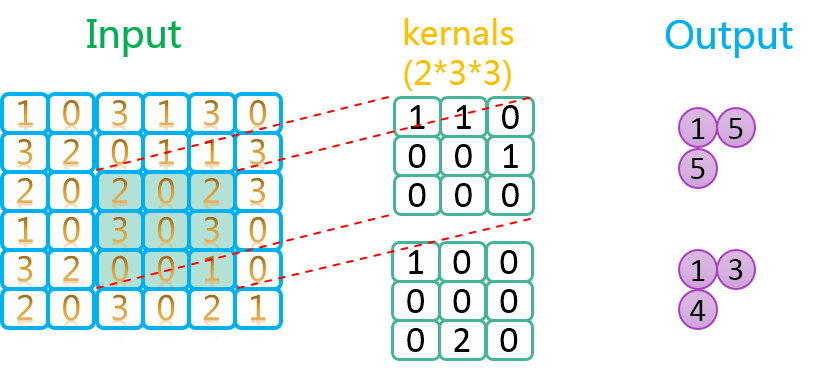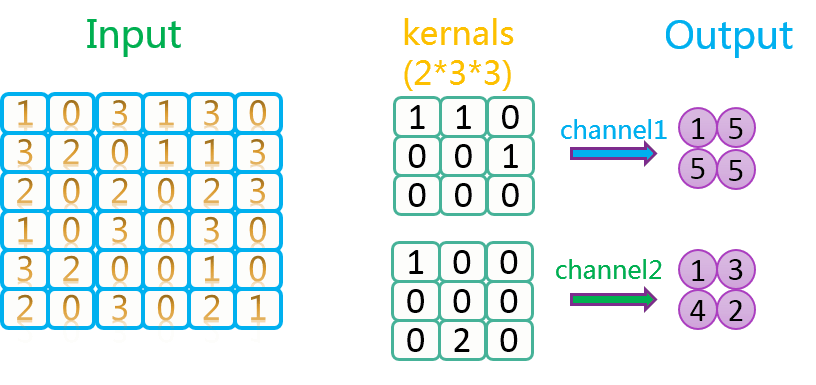
专访360王占一:如何通过深度学习实现对应用流量识别-InfoQ对网络的入口处对应用程序识别是非常重要的,无论是网络安全产品,还是专业的流量分析引擎,应用流量的准确识别不但能洞悉整个企业内网的运行情况,还能针对具体需求做用户行为的准确管控,在一定程度上既可保证业务流的高效运行,也可预防由于内网中毒引起的断网事件。基于此,我们采访了北京邮电大学信号与信息处理专业博士、360企业安全部研究员王占一,就如何利用深度学习、机器学习等方法来对网站流量进行监控识别做深入的 https://www.infoq.cn/article/deep-learning-and-app-flow-identification/ 总之,数据是死的,人脑是活的,怎么玩,就靠你自己去发挥想象力了。下图是步长为2,卷积核数量为2上的卷积过程示意图:
https://www.infoq.cn/article/deep-learning-and-app-flow-identification/ 总之,数据是死的,人脑是活的,怎么玩,就靠你自己去发挥想象力了。下图是步长为2,卷积核数量为2上的卷积过程示意图:
篇幅太长,看得费劲,参数计算请看下一篇
相关文章
- 机器学习笔记(五)---- 决策树
- 机器学习笔记(三)---- 逻辑回归(二分类)
- Coursera台大机器学习技法课程笔记01-linear hard SVM
- Coursera台大机器学习课程笔记5 -- Theory of Generalization
- Coursera台大机器学习课程笔记3 – 机器学习的分类和机器学习的可能性
- 机器学习笔记 - SVD奇异值分解(2)
- 机器学习笔记 - 生成对抗网络 (GAN)概述和入门示例
- 机器学习笔记 基于tensorflow2.0的手写数字识别,并导出pb模型供OpenCV的C++版本的DNN模块调用
- 机器学习笔记 - 基于Torch Hub的渐进式GAN架构
- 机器学习笔记 - 使用 Pix2Pix 进行图像翻译
- 机器学习笔记 - Py-Feat基于Python的面部表情分析
- 机器学习笔记 - 简单了解模式识别
- 机器学习笔记 - 构建推荐系统(3) 深度推荐系统的6个研究方向
- 机器学习笔记 - LUX:用于自动探索性数据分析的 Python API
- 机器学习笔记 - 深度学习技巧备忘清单
- 机器学习笔记 - Transformer/Attention论文解读
- 机器学习笔记 - 什么是高斯混合模型(GMM)?
- 机器学习笔记 - 关注神经魔法和DeepSparse引擎
- 机器学习笔记 - 什么是图注意力网络?
- 机器学习笔记 - 什么是图神经网络?
- 机器学习笔记 - 使用ARIMA模型时间序列预测
- 机器学习笔记 - 同步定位与地图构建 (SLAM)
- 机器学习笔记 - 线性回归与逻辑回归
- 机器学习笔记 - 深度学习常见问题一
- 机器学习笔记 - Kaggle表格游乐场 Jan 2022 学习二
- 机器学习笔记 - 神经网络的类型简介
- 2机器学习实践笔记(k-最近邻)
- LR 算法总结--斯坦福大学机器学习公开课学习笔记