
机器学习笔记 - 神经网络的类型简介
一、全连接神经网络
全连接网络的每个输出单元都是输入的加权和。“全连接”一词是由神经网络每个输出都与输入相连接这个特性而来的。可以写成下面的公式:
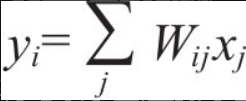
为简化表示,很多论文使用矩阵符号表示全连接网络。这里,我们用一个权重矩阵W与输入向量相乘得到输出向量:y=Wx
因为矩阵相乘是一个线性操作,只包含矩阵乘法的神经网络将只能做线性映射学习。为了增强网络表现力,我们在矩阵乘法的后面加上一个非线性的激活函数。这个函数可以是任何可微的函数,但是常用的函数只有几个。
tanh激活函数

ReLU激活函数

sigmoid激活函数

二、卷积神经网络
卷积神经网络 (CNN) 可用于逐步提取越来越高级别的图像内容表示结果,这一发现标志着图像分类模型的构建取得了重大突破。CNN 不会通过预处理数据得出纹理和形状等特征,而是仅将图像的原始像素数据用作输入,然后“学习”如何提取这些特征,最终推断出这些特征构成的对象。
首先,CNN 会接收一个输入特征图:三维矩阵,其中前两个维度的大小分别与图像的长度和宽度(以像素为单位)对应。第三个维度的大小为 3(对应于彩色图像的 3 个通道:红色、绿色和蓝色)。CNN 包括多个模块,每个模块执行三个操作。
1. 卷积
卷积会提取输入特征图的图块,并向这些图块应用过滤器以计算新特征,生成输出特征图(也称为“卷积特征”,大小和深度可能与输入特征图的不同)。卷积由以下两个参数定义:
- 所提取图块的大小(通常为 3x3 或 5x5 像素)。
- 输出特征图的深度,对应于应用的过滤器数量。
在进行卷积期间,过滤器(大小与图块大小相同的矩阵)会有效地在输入特征图的网格上沿水平和垂直方向滑动,一次移动一个像素,从而提取每个对应的图块(参见图 3)。
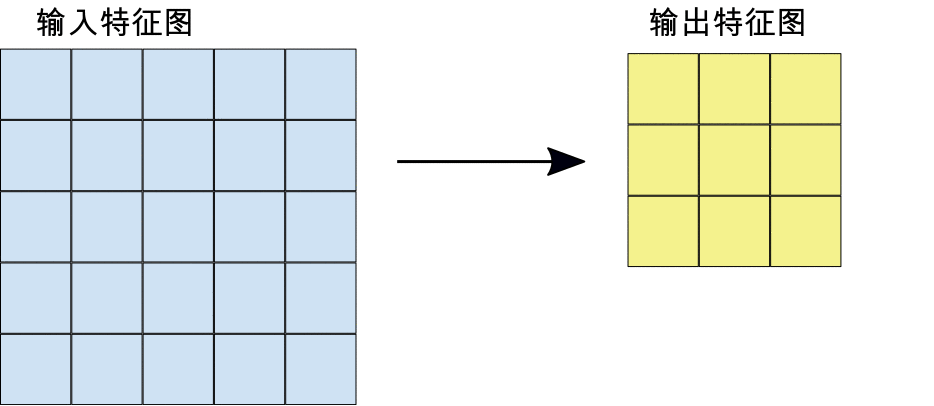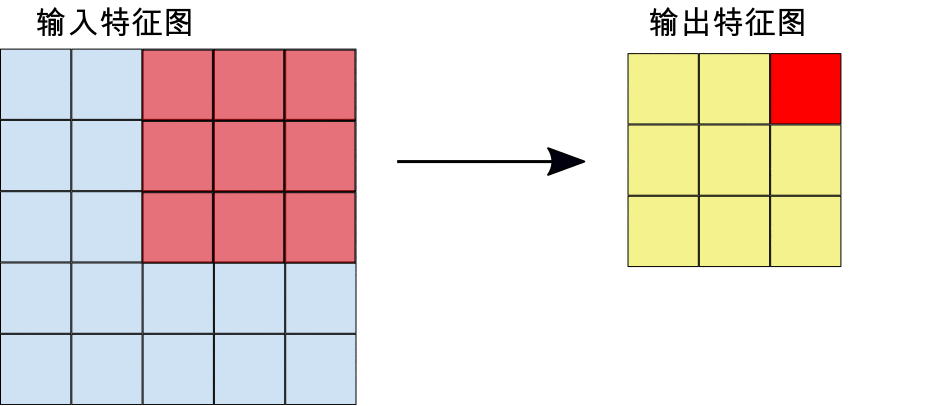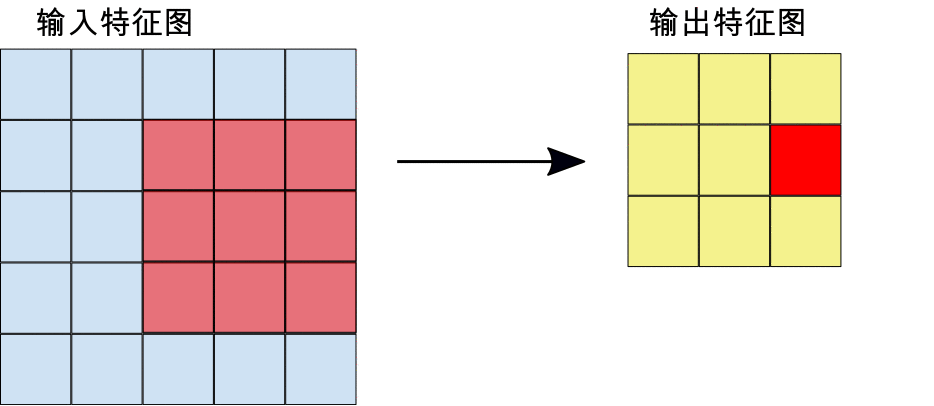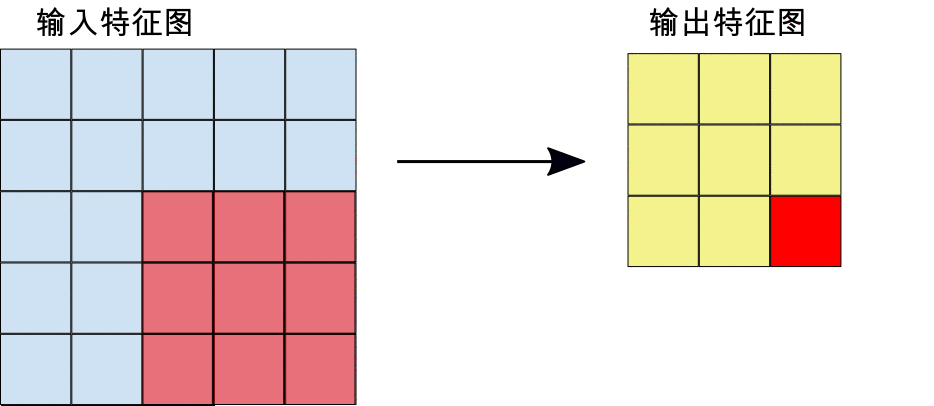
在图 3 中,输出特征图 (3x3) 比输入特征图 (5x5) 小。如果您希望输出特征图的大小与输入特征图相同,则可以向输入特征图的每一侧添加内边距(全部采用零值的空白行/列),生成一个具有 5x5 个可能的位置来提取 3x3 图块的 7x7 矩阵。
对于每个过滤器-图块对,CNN 会对过滤器矩阵和图块矩阵执行元素级乘法运算,然后对所得矩阵的所有元素求和,得出一个值。每个过滤器-图块对的每个结果值都会输出到卷积特征矩阵中(参见图 4a 和 4b)。


在训练期间,CNN 会“学习”过滤器矩阵的最优值,以便能够从输入特征图中提取有意义的特征(纹理、边缘、形状)。随着应用于输入特征图的过滤器数量(输出特征图的深度)不断增加,CNN 可以提取的特征数量也会增加。但需要做出权衡的地方是,过滤器构成了 CNN 要使用的大部分资源,因此,添加的过滤器越多,训练时间越长。此外,添加到网络的每个过滤器带来的增量价值都比上一个过滤器少,因此,工程师希望构建这样一种网络:尽量使用最少的过滤器提取出正确分类图像所需的必要特征。
2. ReLU
每次执行卷积运算后,CNN 都会向卷积特征应用修正线性单元 (ReLU) 转换,以便将非线性规律引入模型中。ReLU 函数 F(x)=max(0,x) 会针对 x > 0 的所有值返回 x,针对 x ≤ 0 的所有值返回 0。
ReLU 在各种神经网络中用作激活函数;有关更多背景信息,请参阅机器学习速成课程中的神经网络简介部分。
3. 池化
ReLU 之后是池化步骤,即 CNN 会降低卷积特征的采样率(以节省处理时间),从而减少特征图的维数,同时仍保留最关键的特征信息。此过程常用的算法称为最大池化。
最大池化采用的运算方式与卷积的运算方式类似。我们在特征图上滑动并提取指定大小的图块。对于每个图块,最大值会输出到新的特征图,所有其他值都被舍弃。最大池化运算采用以下两个参数:
- 最大池化过滤器的大小(通常为 2x2 像素)
- 步长:各提取图块间隔的距离(以像素为单位)。最大池化与卷积不同:在执行卷积期间,过滤器在特征图上逐个像素滑动,而在最大池化过程中,步长会确定每个图块的提取位置。对于 2x2 过滤器,距离为 2 的步长表示最大池化运算将从特征图中提取所有非重叠 2x2 图块(参见图 5)。
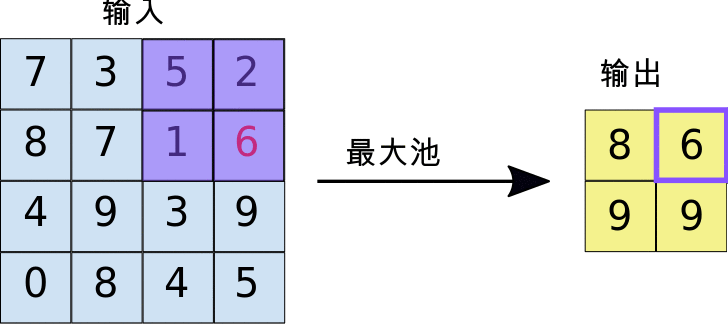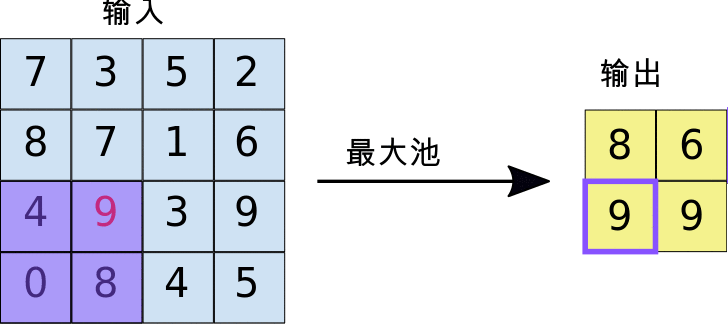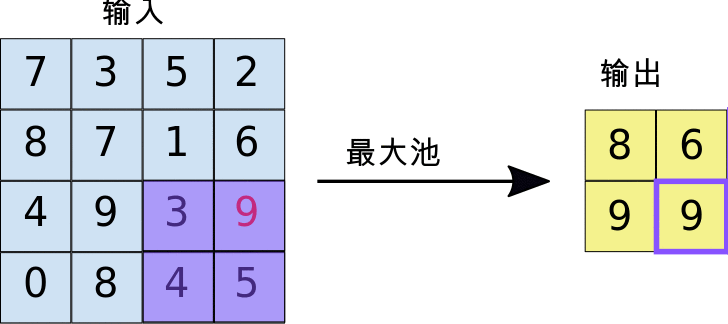
图 5. 左图:使用 2x2 过滤器和步长 2 在 4x4 特征图上执行最大池化运算。右图:最大池化运算的输出。请注意,此时生成的特征图为 2x2,仅保留了每个图块的最大值。
全连接层
卷积神经网络的末端是一个或多个全连接层(当两个层“完全连接”时,第一层中的每个节点都与第二层中的每个节点相连)。全连接层的作用是根据卷积提取的特征进行分类。通常,最后的全连接层会包含一个 softmax 激活函数,该函数会针对模型尝试预测的每个分类标签输出一个概率值(范围为:0-1)。

图 6. 上图中显示的 CNN 包含两个用于提取特征的卷积模块(卷积 + ReLU + 池化)和两个用于分类的全连接层。其他 CNN 可能包含更多或更少的卷积模块和全连接层。工程师会经常进行试验,以便为模型找出可产生最佳结果的配置。
三、循环神经网络
1、循环神经网络简介
循环神经网络(RNN)与CNN在概念上相似,但在结构上却非常不同。循环神经网络常用于处理序列输入。这类输入在处理文本或语音时经常碰到。序列问题一次处理问题的一部分,而不是完整处理单个示例(就像用CNN处理图像一样)。
例如,考虑建立一个神经网络为我们写莎士比亚的剧本。输入自然就是莎士比亚自已写的剧本:

我们希望神经网络学习预测该剧本的下一个单词。为实现这个功能,神经网络需要“记住”到目前为止它所看到过的东西。循环网络提供了这样一种机制。这允许我们建立一个能够处理不同输入长度的模型(例如句子或语音片段)。
最基本的RNN结构形式如下:
 从概念上讲,你可以认为RNN是一个被我们“展开”了的非常深的全连接网络。在这个概念模型之中,每层神经网络有2个输入,而不是我们过去常用的1个输入:
从概念上讲,你可以认为RNN是一个被我们“展开”了的非常深的全连接网络。在这个概念模型之中,每层神经网络有2个输入,而不是我们过去常用的1个输入:

回想一下,在原来的全连接网络中,我们有一个矩阵乘法运算:y=Wx'
在该操作中增加第二个输入最简单的方法就是将它与隐状态相连接:hiddeni=W{hiddeni-1|x}这里“|”表示连接。
正如全连接网络一样,我们可以在矩阵乘法输出上使用激活函数,以获得新的状态:hiddeni=f(W{hiddeni-1|x})
有了RNN的说明,我们可以很容易理解如何训练RNN:简单地将RNN作为未展开的全连接网络,并照常训练它。在文献中这称为基于时间的反向传播算法(BPTT)。如果我们的输入太长,通常需要将它们分割为较小尺寸的片段,并独立训练每个片段。然而,这种技术并不是对每个问题都奏效,只是比较稳妥和常用。
2、梯度消失和LSTM
朴素RNN对长输入序列的效果比我们预期的差很多。这主要是因为它的结构更容易遇到“梯度消失问题”,造成梯度消失的主要原因是未展开的网络非常深。每次通过激活函数,都有一定概率导致较小的梯度通过(例如ReLU激活函数在输入小于0时,梯度等于0)。一旦某个单元出现这种情况,训练就无法通过此单元传递到网络。这导致训练信号不断下降。观察到的结果是学习极其缓慢或整个网络不再继续学习。
为解决此问题,研究人员开发了构建RNN的替代机制。在时间维度展开状态的基本模型得到了保留,我们不再使用简单的矩阵乘法以及后面的激活函数,而是使用一个更复杂的方式进行状态前向传播(下图来自维基百科):

长短期记忆网络(LSTM)使用四个矩阵乘法替换一个矩阵乘法,并引入了可以与向量相乘的门的概念。其关键是始终有一条从最终预测结果到任何层的路径,该路径可以保留梯度,这使得LSTM比普通的RNN能更加有效地学习。
关于LSTM的其它参考:
四、对抗网络与自动编码器
对抗网络和自动编码器没有引入新的网络结构。相反,它们使用更加适合特定问题的结构。例如,处理图像的对抗网络或自动编码器会使用卷积。不同的地方在于如何训练它们。最常用的网络训练方法是从输入(一个图像)预测输出(是否是一只猫):

训练后的自动编码器输出提供的图像:

为什么要这样做呢?如果神经网络中间的隐层包含输入图像的一个表示,这个表示包含了明显比输入图像少的信息,通过这个表示可以重构原始图像,这就产生一种压缩形式:我们可以使用神经网络中间层的一些值表示任何图像。从另外一个角度思考就是,对于原始图像,我们使用神经网络将它映射到抽象空间。该空间的每个点可以被转换回这个图像。
自动编码器已经成功应用在小图像上,但是其训练机制不能很好地扩展到更大的问题上。实际上,这个用于图像绘制的空间并不是足够“密集”,很多点事实上并没有表示相关的图像。
对抗网络是更新一点的模型,可以用来生成逼真的图像。对抗网络把问题分为两部分进行处理:生成网络和判别网络。生成网络输入一个小的随机种子,产生一个图像(或文本)。判别网络尝试去判断输入的图像是否是“真的”或者是否是来自于生成网络。

我们从生成网络中采集一些图像送到判别网络。如果生成网络产生的图像可以欺骗判别网络,生成网络就会受到奖励。判别网络也不得不正确地识别真实的图像(它不能总说图像是假的)。通过两个网络的互相竞争,会产生一个可以生成高质量自然图像的生成网络。
相关文章
- Coursera台大机器学习课程笔记14 -- Validation
- 机器学习笔记----最小二乘法,局部加权,岭回归讲解
- 机器学习笔记 - MediaPipe结合OpenCV分析人体标准运动姿势
- 机器学习笔记 c#调用python脚本文件进行模型推理
- 机器学习笔记 - 什么是标准正态分布表?
- 机器学习笔记 - 什么是联合概率分布?
- 机器学习笔记 - 特征分解
- 机器学习笔记 - 特征向量和特征值
- 机器学习笔记 - 矩阵乘法
- 机器学习笔记 - 使用Keras和深度学习进行乳腺癌分类
- 机器学习笔记 - 在Vehicles数据集上训练 YOLOv5 目标检测器
- 机器学习笔记 - 前馈神经网络(FFNN)用作回归问题的波士顿房价预测
- 机器学习笔记 - 在QT/PyTorch/C++ 中加载 TORCHSCRIPT 模型
- 机器学习笔记 - 什么是图注意力网络?
- 机器学习笔记 - YOLO家族简介
- 机器学习笔记 - 探索性数据分析(EDA) 入门案例三
- 机器学习笔记 - 探索性数据分析(EDA) 概念理解
- 机器学习笔记 - 杂记一
- 机器学习笔记(八)---- 神经网络【华为云分享】
- 机器学习笔记(三)---- 逻辑回归(二分类)