
Hbase 学习(四) hbase客户端设置缓存优化查询
2023-09-14 09:00:24 时间
最近在狂啃hadoop的书籍,这部《hbase:权威指南》就进入我的视野里面了,啃吧,因为是英文的书籍,有些个人理解不对的地方,欢迎各位拍砖。
我们在用hbase的api对hbase进行scan操作的时候,可以设置caching和batch来提交查询效率,那它们之间的关系是啥样的呢,我们又应该如何去设置? 首先是我们的客户端代码。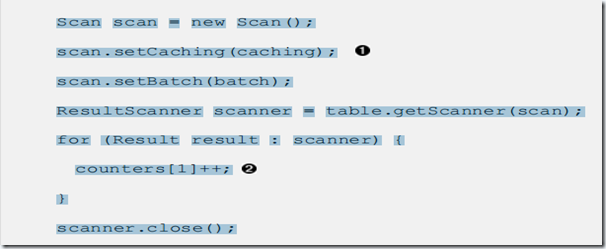
当caching和batch都为1的时候,我们要返回10行具有20列的记录,就要进行201次RPC,因为每一列都作为一个单独的Result来返回,这样是我们不可以接受的。

一次查询20条记录的话,只需要3次RPCs,列数在10列以内的数据,取20条,20/10即可,为什么是3呢,因为还有一次RPC是用来确认的。
有个公式RPCs = (Rows * Cols per Row) / Min(Cols per Row, Batch Size)/ Scanner Caching 。 这就好说啦,这样我们就可以用来优化我们的scan查询了,在查询的时候,按照查询的列数动态设置batch,如果全查,则根据自己所有的表的大小设置一个折中的数值,caching就和分页的值一样就行。
Spark查询Hbase小案例 写作目的 1)正好有些Spark连接HBase的需求,当个笔记本,到时候自己在写的时候,可以看 2)根据rowkey查询其实我还是查询了好久才找到,所以整理了一下 3)好久没发博客了,水一篇
云HBase发布全文索引服务,轻松应对复杂查询 云HBase发布了“全文索引服务”功能,自2019年01月25日后创建的云HBase实例,可以在控制台免费开启此“全文索引服务”功能。使用此功能可以让用户在HBase之上构建功能更丰富的搜索业务
用HBase做高性能键值查询? 最近碰到几家用户在使用HBase或者试图使用HBase来做高性能查询,场景也比较类似,就是从几十亿甚至上百亿记录中按键值找出相关记录来。按说,这种key-value式的数据库很适合用键值查询,HBase看起来就是个不错的选择。
第十二届 BigData NoSQL Meetup — 基于hbase的New sql落地实践 立即下载
我们在用hbase的api对hbase进行scan操作的时候,可以设置caching和batch来提交查询效率,那它们之间的关系是啥样的呢,我们又应该如何去设置? 首先是我们的客户端代码。
当caching和batch都为1的时候,我们要返回10行具有20列的记录,就要进行201次RPC,因为每一列都作为一个单独的Result来返回,这样是我们不可以接受的。
一次查询20条记录的话,只需要3次RPCs,列数在10列以内的数据,取20条,20/10即可,为什么是3呢,因为还有一次RPC是用来确认的。
有个公式RPCs = (Rows * Cols per Row) / Min(Cols per Row, Batch Size)/ Scanner Caching 。 这就好说啦,这样我们就可以用来优化我们的scan查询了,在查询的时候,按照查询的列数动态设置batch,如果全查,则根据自己所有的表的大小设置一个折中的数值,caching就和分页的值一样就行。
Spark查询Hbase小案例 写作目的 1)正好有些Spark连接HBase的需求,当个笔记本,到时候自己在写的时候,可以看 2)根据rowkey查询其实我还是查询了好久才找到,所以整理了一下 3)好久没发博客了,水一篇
云HBase发布全文索引服务,轻松应对复杂查询 云HBase发布了“全文索引服务”功能,自2019年01月25日后创建的云HBase实例,可以在控制台免费开启此“全文索引服务”功能。使用此功能可以让用户在HBase之上构建功能更丰富的搜索业务
用HBase做高性能键值查询? 最近碰到几家用户在使用HBase或者试图使用HBase来做高性能查询,场景也比较类似,就是从几十亿甚至上百亿记录中按键值找出相关记录来。按说,这种key-value式的数据库很适合用键值查询,HBase看起来就是个不错的选择。
第十二届 BigData NoSQL Meetup — 基于hbase的New sql落地实践 立即下载
相关文章
- HBase面试题精讲「建议收藏」
- HBase面试题总结1「建议收藏」
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别
- Hbase(三) hbase协处理器与二级索引详解大数据
- Hbase(六) hbase Java API详解大数据
- HBase学习之路 (九)HBase phoenix的使用详解大数据
- HBase学习之路 (八)HBase大牛博客详解大数据
- HBase学习之路 (五)MapReduce操作Hbase详解大数据
- HBase Region合并分析详解大数据
- MySQL数据导入HBase:构建NoSQL数据库(mysql导入hbase)
- 比较两者:HBase vs MySQL(hbase和mysql)
- 详解hbase搭建遇到问题及解决方法
- 如何在Linux上启动HBase?(linux启动hbase)
- HBase vs. Oracle: A Comparison of Two Leading Database Management Systems(hbase和oracle)
- 整合完美HBase与Oracle的联姻(hbase加oracle)