
数据重组:对一堆相似字典进行分类统计(shidebin)
2023-09-14 09:00:35 时间
数据重组
# 需求说明:将data_source分类统计,并输出为如下data_final的形式:
# data_final ===》
# {
# 'area': [{'place': '南山区', 'amount': 3}, {'place': '宝安区', 'amount': 3}],
# 'type': {'other': 3, 'govenment': 1, 'education': 1, 'business': 1}
# }
def class_sum(data_source_list, class_key_name, sum_key_name):
'''对一堆相似字典进行分类统计
:param data_source_list: 原始数据,列表中放字典。如:[{"c":"c1","count":2},{"c":"c2","count":1},{"c":"c1","count":1}]
:param class_key_name: 分类的key名称。如"c"
:param sum_key_name: 统计计数的key名称。如"count"
:return:分类清单 和 对应的统计计数。如:list_class=["c1", "c2"] 和 list_sum=[3, 1]
'''
list_class = []
list_sum = []
for dict_tmp in data_source_list:
sum_tmp = 0
# print(dict_tmp)
if class_key_name in dict_tmp:
if dict_tmp[class_key_name] not in list_class:
list_class.append(dict_tmp[class_key_name])
sum_tmp += dict_tmp[sum_key_name]
list_sum.append(sum_tmp)
else:
sum_index = list_class.index(dict_tmp[class_key_name])
sum_tmp = list_sum[sum_index]+dict_tmp[sum_key_name]
list_sum[sum_index] = sum_tmp
return (list_class, list_sum)
data_source = [
{
"town_name": "南山区",
"type": "other",
"count": 1
},
{
"town_name": "南山区",
"type": "govenment",
"count": 1
},
{
"town_name": "南山区",
"type": "education",
"count": 1
},
{
"town_name": "宝安区",
"type": "other",
"count": 2
},
{
"town_name": "宝安区",
"type": "business",
"count": 1
}
]
for dict_tmp in data_source:
print(dict_tmp)
data_final = {}
data_final['area'] = []
data_final['type'] = {}
# 1.1、按照town_name分类和统计count
list_class, list_sum = class_sum(data_source, "town_name", 'count')
print(1111111111111)
print(list_class)
print(list_sum)
# 2.1 组装area:根据town_name分类和统计
data_final["area"] = list(map(lambda x, y: {"place": x, "amount": y}, list_class, list_sum))
# 1.2、按照type分类和统计count
list_class, list_sum = class_sum(data_source, "type", 'count')
print(2222222222222)
print(list_class)
print(list_sum)
# 2.2 组装type:根据type分类和统计
for c in list_class:
data_final["type"][c] = list_sum[list_class.index(c)]
print(data_final)
# 想要的 {'area': [{'amount': 3, 'place': '南山区'}, {'amount': 3, 'place': '宝安区'}], 'type':{'other': 3, 'govenment': 1, 'education': 1, 'business': 1}}
输出:

数据重组案例2:
元组转字典
字典转元组
print()
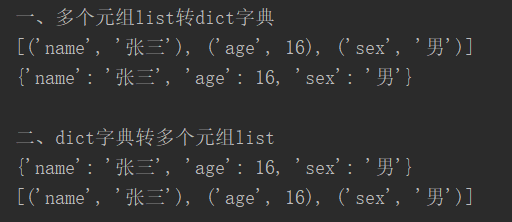
print("一、多个元组list转dict字典")
my_list1 = [('name', "张三"), ('age', 16), ('sex', "男")]
dic1 = dict(my_list1)
print(my_list1)
print(dic1)
print()
print("二、dict字典转多个元组list")
dic2 = dic1
my_list2 = list(zip(dic2.keys(), dic2.values()))
print(dic2)
print(my_list2)
输出:
相关文章
- 上线新系统后,统计从旧系统切换到新系统的数据
- R_Studio(学生成绩)对数值型数据进行统计量分析
- 手机上怎么实时文档统计字数?
- 博客园如何统计个人博客的访问量
- 数位类统计问题--数位DP
- Java实现 蓝桥杯VIP 算法提高 分数统计
- 统计之 - 协方差_数据分析师
- Data - 【转】数据统计、数据挖掘、大数据、OLAP的区别
- Data - 【转】数据统计、数据挖掘、大数据、OLAP的区别
- mysql 统计当天,本周,本月,上一月的数据
- 莽荒纪人物出场数据统计
- Database之SQLSever:SQL命令实现的高级案例集合之单表/多表(筛选、统计个数)之详细攻略
- 机器学习、数据挖掘和统计模式识别学习(Matlab代码实现)
- 【预测模型】统计的基本概念
- 数学建模学习(4):数据统计与分析之假设检验
- 数学建模学习(1):数据统计与分析之平均数,中位数,方差,标准差,极差
- 【阶段二】Python数据分析数据可视化工具使用05篇:统计直方图、面积图与箱型图
- 【SQL干货】一条sql按季度统计交易数据
- 【Linux之shell脚本实战】统计 Linux 进程相关数量信息
- 用Python做数据分析之数据统计
- 参数检验——当总体分布已知(如总体为正态分布),根据样本数据对总体分布的统计参数进行推断 非参数检验——利用样本数据对总体分布形态等进行推断的方法。