
Kafka+Spark Streaming+Redis实时计算整合实践
基于Spark通用计算平台,可以很好地扩展各种计算类型的应用,尤其是Spark提供了内建的计算库支持,像Spark Streaming、Spark SQL、MLlib、GraphX,这些内建库都提供了高级抽象,可以用非常简洁的代码实现复杂的计算逻辑、这也得益于Scala编程语言的简洁性。这里,我们基于1.3.0版本的Spark搭建了计算平台,实现基于Spark Streaming的实时计算。
我们的应用场景是分析用户使用手机App的行为,描述如下所示:
Spark Streaming介绍
Spark Streaming提供了一个叫做DStream(Discretized Stream)的高级抽象,DStream表示一个持续不断输入的数据流,可以基于Kafka、TCP Socket、Flume等输入数据流创建。在内部,一个DStream实际上是由一个RDD序列组成的。Sparking Streaming是基于Spark平台的,也就继承了Spark平台的各种特性,如容错(Fault-tolerant)、可扩展(Scalable)、高吞吐(High-throughput)等。
在Spark Streaming中,每个DStream包含了一个时间间隔之内的数据项的集合,我们可以理解为指定时间间隔之内的一个batch,每一个batch就构成一个RDD数据集,所以DStream就是一个个batch的有序序列,时间是连续的,按照时间间隔将数据流分割成一个个离散的RDD数据集,如图所示(来自官网):
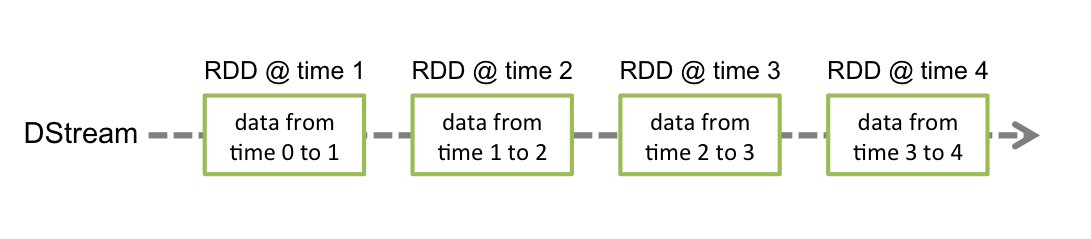
我们都知道,Spark支持两种类型操作:Transformations和Actions。Transformation从一个已知的RDD数据集经过转换得到一个新的RDD数据集,这些Transformation操作包括map、filter、flatMap、union、join等,而且Transformation具有lazy的特性,调用这些操作并没有立刻执行对已知RDD数据集的计算操作,而是在调用了另一类型的Action操作才会真正地执行。Action执行,会真正地对RDD数据集进行操作,返回一个计算结果给Driver程序,或者没有返回结果,如将计算结果数据进行持久化,Action操作包括reduceByKey、count、foreach、collect等。关于Transformations和Actions更详细内容,可以查看官网文档。
同样、Spark Streaming提供了类似Spark的两种操作类型,分别为Transformations和Output操作,它们的操作对象是DStream,作用也和Spark类似:Transformation从一个已知的DStream经过转换得到一个新的DStream,而且Spark Streaming还额外增加了一类针对Window的操作,当然它也是Transformation,但是可以更灵活地控制DStream的大小(时间间隔大小、数据元素个数),例如window(windowLength, slideInterval)、countByWindow(windowLength, slideInterval)、reduceByWindow(func, windowLength, slideInterval)等。Spark Streaming的Output操作允许我们将DStream数据输出到一个外部的存储系统,如数据库或文件系统等,执行Output操作类似执行Spark的Action操作,使得该操作之前lazy的Transformation操作序列真正地执行。
Kafka+Spark Streaming+Redis编程实践
下面,我们根据上面提到的应用场景,来编程实现这个实时计算应用。首先,写了一个Kafka Producer模拟程序,用来模拟向Kafka实时写入用户行为的事件数据,数据是JSON格式,示例如下:
{"uid":"068b746ed4620d25e26055a9f804385f","event_time":"1430204612405","os_type":"Android","click_count":6}一个事件包含4个字段:
uid:用户编号 event_time:事件发生时间戳 os_type:手机App操作系统类型 click_count:点击次数下面是我们实现的代码,如下所示:
package org.shirdrn.spark.streaming.utils// bin/kafka-topics.sh --zookeeper zk1:2181,zk2:2181,zk3:2181/kafka --create --topic user_events --replication-factor 2 --partitions 2
// bin/kafka-topics.sh --zookeeper zk1:2181,zk2:2181,zk3:2181/kafka --describe user_events
// bin/kafka-console-consumer.sh --zookeeper zk1:2181,zk2:2181,zk3:22181/kafka --topic test_json_basis_event --from-beginning
通过控制上面程序最后一行的时间间隔来控制模拟写入速度。下面我们来讨论实现实时统计每个用户的点击次数,它是按照用户分组进行累加次数,逻辑比较简单,关键是在实现过程中要注意一些问题,如对象序列化等。先看实现代码,稍后我们再详细讨论,代码实现如下所示:
object UserClickCountAnalytics {"metadata.broker.list" - brokers, "serializer.class" - "kafka.serializer.StringEncoder")
val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
val userClicks = events.map(x = (x.getString("uid"), x.getInt("click_count"))).reduceByKey(_ + _)
上面代码使用了Jedis客户端来操作Redis,将分组计数结果数据累加写入Redis存储,如果其他系统需要实时获取该数据,直接从Redis实时读取即可。RedisClient实现代码如下所示:
object RedisClient extends Serializable {lazy val pool = new JedisPool(new GenericObjectPoolConfig(), redisHost, redisPort, redisTimeout)
上面代码我们分别在local[K]和Spark Standalone集群模式下运行通过。
如果我们是在开发环境进行调试的时候,也就是使用local[K]部署模式,在本地启动K个Worker线程来计算,这K个Worker在同一个JVM实例里,上面的代码默认情况是,如果没有传参数则是local[K]模式,所以如果使用这种方式在创建Redis连接池或连接的时候,可能非常容易调试通过,但是在使用Spark Standalone、YARN Client(YARN Cluster)或Mesos集群部署模式的时候,就会报错,主要是由于在处理Redis连接池或连接的时候出错了。我们可以看一下Spark架构,如图所示(来自官网):
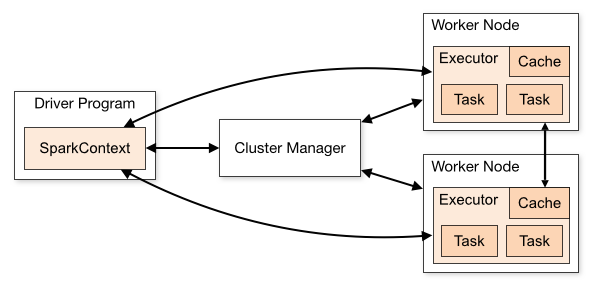
无论是在本地模式、Standalone模式,还是在Mesos或YARN模式下,整个Spark集群的结构都可以用上图抽象表示,只是各个组件的运行环境不同,导致组件可能是分布式的,或本地的,或单个JVM实例的。如在本地模式,则上图表现为在同一节点上的单个进程之内的多个组件;而在YARN Client模式下,Driver程序是在YARN集群之外的一个节点上提交Spark Application,其他的组件都运行在YARN集群管理的节点上。
在Spark集群环境部署Application后,在进行计算的时候会将作用于RDD数据集上的函数(Functions)发送到集群中Worker上的Executor上(在Spark Streaming中是作用于DStream的操作),那么这些函数操作所作用的对象(Elements)必须是可序列化的,通过Scala也可以使用lazy引用来解决,否则这些对象(Elements)在跨节点序列化传输后,无法正确地执行反序列化重构成实际可用的对象。上面代码我们使用lazy引用(Lazy Reference)来实现的,代码如下所示:
lazy val pool = new JedisPool(new GenericObjectPoolConfig(), redisHost, redisPort, redisTimeout)
另一种方式,我们将代码修改为,把对Redis连接的管理放在操作DStream的Output操作范围之内,因为我们知道它是在特定的Executor中进行初始化的,使用一个单例的对象来管理,如下所示:
package org.shirdrn.spark.streaming"metadata.broker.list" - brokers, "serializer.class" - "kafka.serializer.StringEncoder")
val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
val userClicks = events.map(x = (x.getString("uid"), x.getInt("click_count"))).reduceByKey(_ + _)
* Internal Redis client for managing Redis connection {@link Jedis} based on {@link RedisPool}
makePool(redisHost, redisPort, redisTimeout, maxTotal, maxIdle, minIdle,true, false, 10000)
InternalRedisClient.makePool(redisHost, redisPort, redisTimeout, maxTotal, maxIdle, minIdle)
上面代码实现,得益于Scala语言的特性,可以在代码中任何位置进行class或object的定义,我们将用来管理Redis连接的代码放在了特定操作的内部,就避免了瞬态(Transient)对象跨节点序列化的问题。这样做还要求我们能够了解Spark内部是如何操作RDD数据集的,更多可以参考RDD或Spark相关文档。
在集群上,以Standalone模式运行,执行如下命令:
./bin/spark-submit --class org.shirdrn.spark.streaming.UserClickCountAnalytics --master spark://hadoop1:7077 --executor-memory 1G --total-executor-cores 2 ~/spark-0.0.SNAPSHOT.jar spark://hadoop1:7077
可以查看集群中各个Worker节点执行计算任务的状态,也可以非常方便地通过Web页面查看。
下面,看一下我们存储到Redis中的计算结果,如下所示:
附录
这里,附上前面开发的应用所对应的依赖,以及打包Spark Streaming应用程序的Maven配置,以供参考。如果使用maven-shade-plugin插件,配置有问题的话,打包后在Spark集群上提交Application时候可能会报错Invalid signature file digest for Manifest main attributes。参考的Maven配置,如下所示:
project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/
implementation="org.apache.maven.plugins.shade.resource.DontIncludeResourceTransformer"
Flume+Kafka+Spark Streaming+MySQL实时日志分析 网络发展迅速的时代,越来越多人通过网络获取跟多的信息或通过网络作一番自己的事业,当投身于搭建属于自己的网站、APP或小程序时会发现,经过一段时间经营和维护发现浏览量和用户数量的增长速度始终没有提升。在对其进行设计改造时无从下手,当在不了解用户的浏览喜欢和个用户群体的喜好。虽然服务器日志中明确的记载了用户访浏览的喜好但是通过普通方式很难从大量的日志中及时有效的筛选出优质信息。Spark Streaming是一个实时的流计算框架,该技术可以对数据进行实时快速的分析,通过与Flume、Kafka的结合能够做到近乎零延迟的数据统计分析。
Spark Streaming连接Kafka入门教程 首先要安装好kafka,这里不做kafka安装的介绍(这里用的是ambari安装的kafka),若想了解如何安装可参考Kafka安装启动入门教程和centos7 ambari2.6.1.5+hdp2.6.4.0 大数据集群安装部署,本文是Spark Streaming入门教程,只是简单的介绍如何利用spark 连接kafka,并消费数据,由于博主也是才学,所以其中代码以实现为主,可能并不是最好的实现方式。
相关文章
- windows redis:Uncaught exception 'RedisException' with message 'Redis server went away'
- Python的Flask框架应用调用Redis队列数据的方法
- Spring中使用RedisTemplate操作Redis(spring-data-redis)
- Redis实战 内存淘汰机制
- Redis学习(8)-redis持久化
- Redis学习(2)-redis安装
- 如何设置redis中hash的field的expire ?
- 深入理解Spring Redis的使用 (六)、用Spring Aop 实现注解Dao层的自动Spring Redis缓存
- redis-cli 连接远程服务器
- redis监控
- innodb为什么选择B+ Tree而不是跳表,Redis为什么选择跳表而不是B+ Tree
- redis 简单整理——redis 的哈希基本结构和命令[三]
- LAMP+redis搭建discuz论坛,基于mysql-proxy插件主从同步
- Redis 优化之swap分区
- Prometheus 基于endpoints服务发现监控redis
- kafka可视化客户端工具(Kafka Tool)的基本使用
- 【服务器安装Redis】Centos7离线安装redis
- 〖Python 数据库开发实战 - Python与Redis交互篇③〗- 利用 redis-py 实现列表数据类型的常用指令操作
- KAFKA EAGLE 监控MRS kafka之操作实践
- Redis的那些事儿:关系型和非关系型数据库,非关系型数据库的类型,redis数据类型、编码格式、高性能、可以做什么、分布式锁失效的原因,string为采用sds数据类型,为什么是二进制安全的,
- 深入浅出Redis-redis哨兵集群
- redis_02 _ 数据结构:快速的Redis有哪些慢操作?
- redis扩展
- 深入学习Redis(3):主从复制
- 解开Kafka神秘的面纱(四):kafka stream及interceptor
- Redis系列五 | 主从复制和哨兵模式
- Ubuntu 安装redis desktop manager