
DBSCAN聚类算法原理及其实现
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)聚类算法,它是一种基于高密度连通区域的、基于密度的聚类算法,能够将具有足够高密度的区域划分为簇,并在具有噪声的数据中发现任意形状的簇。我们总结一下DBSCAN聚类算法原理的基本要点:
DBSCAN算法需要选择一种距离度量,对于待聚类的数据集中,任意两个点之间的距离,反映了点之间的密度,说明了点与点是否能够聚到同一类中。由于DBSCAN算法对高维数据定义密度很困难,所以对于二维空间中的点,可以使用欧几里德距离来进行度量。 DBSCAN算法需要用户输入2个参数:一个参数是半径(Eps),表示以给定点P为中心的圆形邻域的范围;另一个参数是以点P为中心的邻域内最少点的数量(MinPts)。如果满足:以点P为中心、半径为Eps的邻域内的点的个数不少于MinPts,则称点P为核心点。 DBSCAN聚类使用到一个k-距离的概念,k-距离是指:给定数据集P={p(i); i=0,1,…n},对于任意点P(i),计算点P(i)到集合D的子集S={p(1), p(2), …, p(i-1), p(i+1), …, p(n)}中所有点之间的距离,距离按照从小到大的顺序排序,假设排序后的距离集合为D={d(1), d(2), …, d(k-1), d(k), d(k+1), …,d(n)},则d(k)就被称为k-距离。也就是说,k-距离是点p(i)到所有点(除了p(i)点)之间距离第k近的距离。对待聚类集合中每个点p(i)都计算k-距离,最后得到所有点的k-距离集合E={e(1), e(2), …, e(n)}。 根据经验计算半径Eps:根据得到的所有点的k-距离集合E,对集合E进行升序排序后得到k-距离集合E’,需要拟合一条排序后的E’集合中k-距离的变化曲线图,然后绘出曲线,通过观察,将急剧发生变化的位置所对应的k-距离的值,确定为半径Eps的值。 根据经验计算最少点的数量MinPts:确定MinPts的大小,实际上也是确定k-距离中k的值,DBSCAN算法取k=4,则MinPts=4。 另外,如果觉得经验值聚类的结果不满意,可以适当调整Eps和MinPts的值,经过多次迭代计算对比,选择最合适的参数值。可以看出,如果MinPts不变,Eps取得值过大,会导致大多数点都聚到同一个簇中,Eps过小,会导致一个簇的分裂;如果Eps不变,MinPts的值取得过大,会导致同一个簇中点被标记为离群点,MinPts过小,会导致发现大量的核心点。我们需要知道的是,DBSCAN算法,需要输入2个参数,这两个参数的计算都来自经验知识。半径Eps的计算依赖于计算k-距离,DBSCAN取k=4,也就是设置MinPts=4,然后需要根据k-距离曲线,根据经验观察找到合适的半径Eps的值,下面的算法实现过程中,我们会详细说明。
对于算法的实现,首先我们概要地描述一下实现的过程:
然后,再详细描述聚类过程的具体实现。
计算欧几里德距离
我们使用的样本数据,来自一组经纬度坐标数据,数据文件格式类似如下所示:
116.389463 39.87194return this.x.doubleValue() == other.x.doubleValue() this.y.doubleValue() == other.y.doubleValue();
我们可以将解析后的点的对象放到一个List Point2D allPoints集合里面,以便后续使用时迭代集合。在计算两点之间的欧几里德距离时,需要迭代前面生成的Point2D的集合,计算欧几里德距离,实现方法如下所示:
public static double euclideanDistance(Point2D p1, Point2D p2) {如果需要,可以将计算的所有点之间的距离缓存,因为计算k-距离需要多次访问点的欧几里德距离,比如,可以使用Guava库中的Cache工具:
Cache Set Point2D , Double distanceCache =上面代码中,设置缓存容纳足够多(Integer.MAX_VALUE)的对象,将计算出的全部的欧几里德距离放在内存中,便于后续迭代时重用。
计算k-距离
每个点都要计算k-距离,在计算一个点的k-距离的时候,首先要计算该点到其他所有点的欧几里德距离,按照距离升序排序后,选择第k小的距离作为k-距离的值,实现代码如下所示:
Task task = q.poll(); // 从队列q中取出一个Task,就是计算一个点的k-距离的任务final TreeSet Double sortedDistances = Sets.newTreeSet(new Comparator Double () { // 创建一个降序排序TreeSet
Double distance = distanceCache.getIfPresent(set); // 从缓存中取出欧几里德距离(可能不存在)
p1.kDistance = sortedDistances.iterator().next(); // 此时,TreeSet中最大的,就是第k最小的距离
上述代码中,KPoint2D类是Point2D的子类,不过比基类Point2D多了一个k-距离的属性,代码如下所示:
private class KPoint2D extends Point2D {绘制k-距离曲线,寻找半径Eps
x轴坐标点我们直接使用递增的自然数序列,每个点对应一个自然数,y轴就是所有点的k-距离的大小,我们在代码中可以进行处理,实现如下:
for(int i=0; i allPoints.size(); i++) {我们把输出数据复制到Excel表格中,使用上述数据生成散点图,基于x坐标取了4个不同的范围,观察曲线的变化情况,0~2600、0~2000、2001~2630、0~2500各个x坐标范围内的点,对应的散点图分别如下所示:
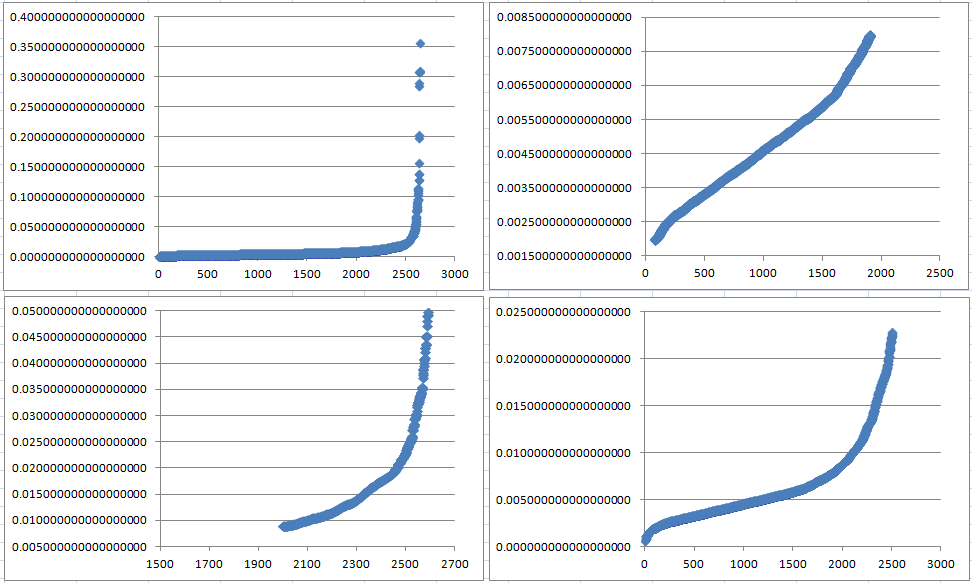
通过上图可以看出:
左上图(0~2600):由于x=2500之后店的k-距离变化太快(可以忽略),导致前面点的k-距离的变化趋势无法观察出来。 右上图(0~2000):去掉尾部的一些点的k-距离,可以看出曲线的变化趋势。 左下图(2001~2630):x坐标轴后半部分的距离的变化趋势。 右下图(0~2500):去掉尾部一些k-距离点,展示大部分k-距离点的变化趋势。综合上面4个图,可以选择得到半径Eps的范围大致在0.002~0.006之间,已知MinPts=4,具体我们可以选择下面3个k-距离的值作为半径Eps:
0.0025094814205335555通过下一步进行聚类,看一下使用选择的Eps的这几个值进行聚类的效果对比。另外,对半径Eps=8也进行聚类,主要是为了看一下半径变化对聚类效果的影响。
计算核心点
聚类过程需要知道半径Eps,半径已知,首先需要计算有哪些核心点,给定点,如果以该点为中心半径为Eps的邻域内的其他点的数量大于等于MinPts,则该点就为核心点。计算核心点的实现代码如下所示:
Point2D p1 = taskQueue.poll();if(set.size() = minPts) { // 计算收集到的邻域内的点的个数,小于等于MinPts,则加入到映射表Map Point2D, Set Point2D corePointWithNeighbours中
if(!outliers.contains(p1)) { // 这里,会把一些点错误地加入到离群点集合outliers中,后面会进行修正
那些被错误放入离群点集合的点,需要在计算核心点完成之后,遍历离群点集合,与核心点集合(及其对应的映射点集合)进行比对,代码如下所示:
// process outliers连通核心点生成簇
核心点能够连通(有些书籍中称为:“密度可达”),它们构成的以Eps长度为半径的圆形邻域相互连接或重叠,这些连通的核心点及其所处的邻域内的全部点构成一个簇。假设MinPts=4,则连通的核心点示例,如下图所示:
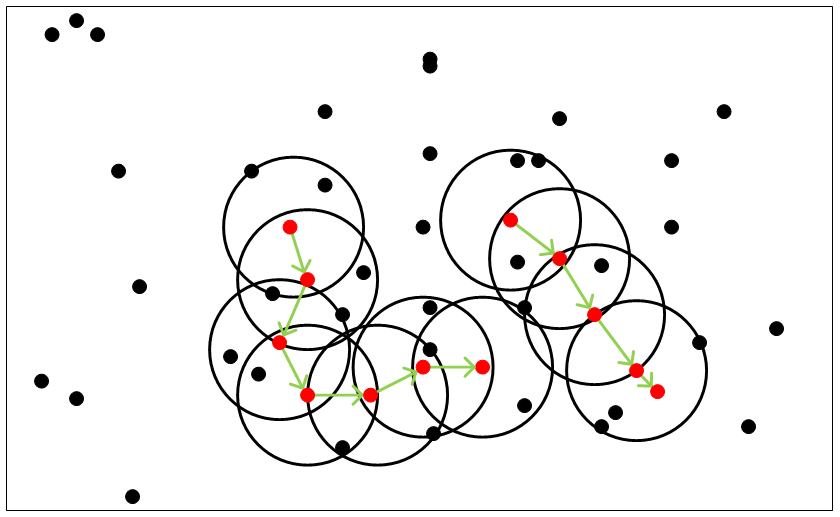
假设MinPts=4,上图中存在两个簇,每个簇都是通过核心点连通在一起的,每个簇是由连通的核心点及其核心点半径Eps圆形邻域内的点组成的,在这两个簇所覆盖的范围外部的点,都是离群点(Outliers)。
计算连通的核心点的思路是,基于广度遍历与深度遍历集合的方式:从核心点集合S中取出一个点p,计算点p与S集合中每个点(除了p点)是否连通,可能会得到一个连通核心点的集合C1,然后从集合S中删除点p和C1集合中的点,得到核心点集合S1;再从S1中取出一个点p1,计算p1与核心点集合S1集中每个点(除了p1点)是否连通,可能得到一个连通核心点集合C2,再从集合S1中删除点p1和C2集合中所有点,得到核心点集合S2,……最后得到p、p1、p2、……,以及C1、C2、……就构成一个簇的核心点。最终将核心点集合S中的点都遍历完成,得到所有的簇。具体代码实现,如下所示:
上面调用了重载的两个方法joinConnectedCorePoints,分别根据参数不同计算连通的核心点集合:计算核心点集合中一个点,与该核心点集合中其它的所有核心点是否连通,调用如下方法:
private Set Point2D joinConnectedCorePoints(Point2D p1, Set Point2D leftCorePoints) {还有一个方法是,上面第一个参数变为一个集合,它调用上面的方法处理每一个点,方法代码实现如下所示:
private Set Point2D joinConnectedCorePoints(Set Point2D connectedPoints, Set Point2D leftCorePoints) {最后,集合clusteredPoints存储的就是聚类后的核心点的信息,再根据核心点到其邻域内半径小于等于Eps的点的集合的映射,就能将所有的点生成聚类了。
聚类效果比较
选择不同的半径Eps进行聚类分析, 聚类的结果也不相同,有些情况下差异很大,有些情况差异较小。比如,在MinPts=4的情况下,如何绘制k-距离曲线,已经在前面详细说明了处理过程,我们根据k-距离趋势增长曲线,选择了一组半径Eps的值,执行DBSCAN聚类算法,下面我们比较在MinPts=4和MinPts=8的情况下,再分别选择不同的半径Eps,执行DBSCAN聚类算法生成簇,对分布情况进行对比。
参数:MinPts=4选择半径Eps的值分别为如下3个观察值:
0.0025094814205335555最终得到的聚类效果图在下面可以看到,其中,左侧为没有离群点的情况各个簇的分布情况,右侧是将离群点全部加入到图上显示,图中图例中的9999表示离群点,其他的都是聚类生成的簇,如下图所示:
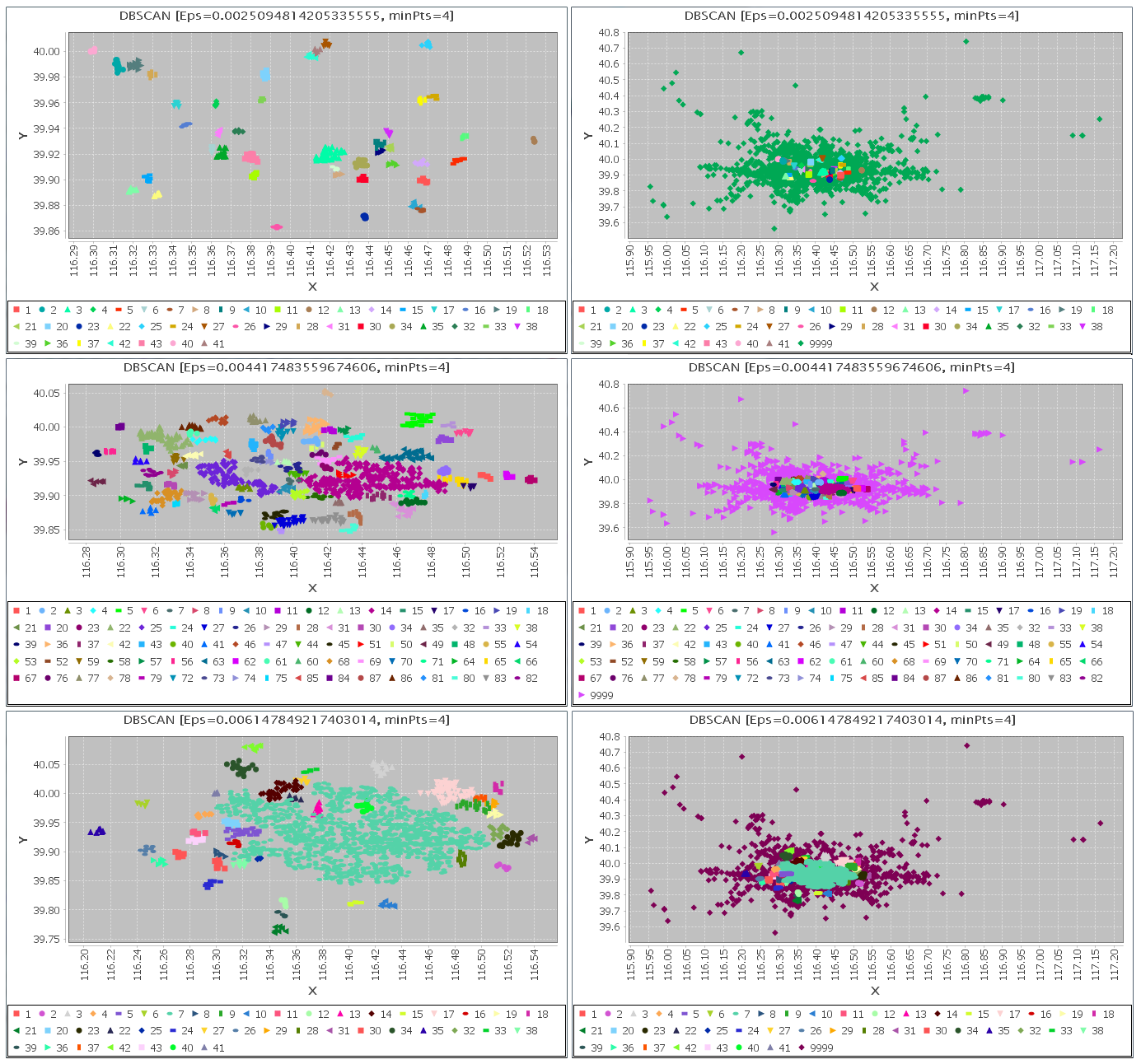
通过上图可以看出,半径Eps选择的较小时,会产生大量的离群点,其实我们想一下,半径小了,自然落在某个点的邻域内的点减少的可能性就增加了,导致很多点可能就无法成为核心点,自然也就无法成为某个簇的点,而且很生成的簇包含的点的数量都比较少,某些本来很接近的点应该可以成为同一个簇,但是被分裂了。
当半径比较大一些时,生成的一个簇包含了比较多的点,而且这个簇的形状中间可能出现一些“空洞”,因为点之间的距离大一些也能满足成为核心点的要求,所以这些点聚到一簇中可能确实比较合理。
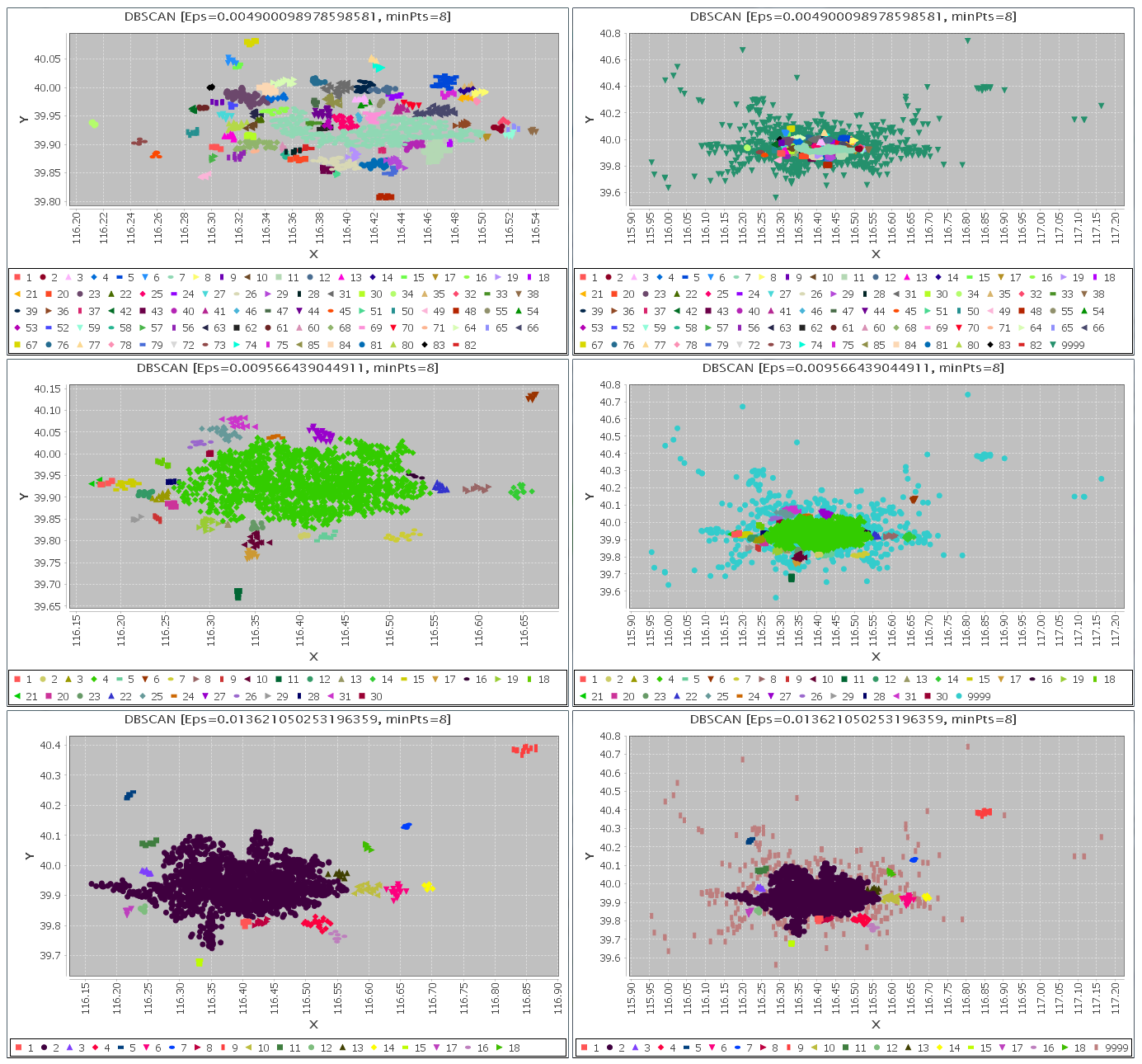
选择半径Eps的值分别为如下3个观察值:
0.004900098978598581使用我们实现的DBSCAN聚类算法进行分析处理,得到的聚类结果,如下图所示:
总结
因为DBSCAN聚类算法,是基于密度的聚类算法,所以对于密度分别不均,各个簇的密度变化较大时,可能会导致一些问题:比如半径Eps较大时,本来不属于同一个的簇的点被聚到一个簇中;比如半径Eps比较小时,会出现大量比较小的簇(即每个簇中含有的点不较少,但是这些点组成的小簇密度确实很大),同时出现了大量的点不满足成为核心点的要求,MinPts越大越容易出现这种情况。
DBSCAN聚类算法的思想非常明确易懂,虽然需要用户输入2个参数,但是正是输入参数的灵活性,我们可以根据自己实际应用的需要,适当调整参数值,在特定应用场景下进行聚类分析,得到合适的簇划分。通过上面选择不同参数进行聚类的结果对比,如果希望局部比较密集的点都能够生成簇,那么在固定MinPts的值的条件下,半径Eps通过调整变小,可能达到这一需要,产生的簇的数量比较多,但是同时也产生了大量分散的离群点,实际上应该可以进行二次聚类,将离群点也通过合适的方式归到指定的簇中;如果希望生成全局比较大的簇,可以适当调整半径Eps变大,生成的簇的数量较少,离群点的数量也相对较少。
KNN最近邻算法 最近邻算法是一种基于实例的学习,或者是局部近似和将所有计算推迟到分类之后的惰性学习,可以用于基本的**分类与回归方法**。
聚类算法简单总结 在无监督学习中,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律。在这类任务中,常用的算法是聚类(cluster)算法。聚类算法试图将样本划分为若干个通常是不相交的子集,每个子集表明一个簇,也叫类别,通过这样的操作,可以将无规律的样本划分为一堆堆的样本子集合。
相关文章
- 一致性哈希算法 CARP 原理解析, 附 Golang 实现
- 空中鼠标算法原理讨论
- Java实现 蓝桥杯 算法训练 纪念品分组
- MySQL索引背后的数据结构及算法原理
- 基于用户的协同过滤推荐算法原理和实现
- Atitti 文本分类 以及 垃圾邮件 判断原理 以及贝叶斯算法的应用解决方案
- Algorithm:C++语言实现之SimHash和倒排索引算法相关(抽屉原理、倒排索、建立查找树、处理Hash冲突、Hash查找)
- 第十四届蓝桥杯集训——练习解题阶段(无序阶段)-ALGO-4 算法训练 结点选择
- 孤立森林异常检测算法原理和实战(附代码)
- 智能优化算法:入侵杂草优化算法-附代码
- B-树(B-Tree)与二叉搜索树(BST):讲讲数据库和文件系统背后的原理(读写比较大块数据的存储系统数据结构与算法原理)...
- 【数据结构与算法】K 近邻算法—— KD 树 算法原理讲解和C语言实现代码
- 机器学习算法二之DBSCAN聚类原理与实现(二维及三维)
- 基于 LinkedHashMap 实现LRU缓存调度算法原理
- ISP(图像信号处理)算法概述、工作原理、架构、处理流程