
数据的归一化处理
数据的标准化(normalization)和归一化
数据的标准化
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
目前数据标准化方法:直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。不同的标准化方法,对系统的评价结果会产生不同的影响,然而不幸的是,在数据标准化方法的选择上,还没有通用的法则可以遵循。
归一化
数据标准化中最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上。
归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在-1--+1之间是统计的坐标分布。归一化有同一、统一和合一的意思。无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测的,且sigmoid函数的取值是0到1之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。归一化是统一在0-1之间的统计概率分布,当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。另外在数据中常存在奇异样本数据,奇异样本数据存在所引起的网络训练时间增加,并可能引起网络无法收敛。为了避免出现这种情况及后面数据处理的方便,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于0或与其均方差相比很小。
归一化的目标
1 把数变为(0,1)之间的小数
2 把有量纲表达式变为无量纲表达式
归一化的好处
1. 提升模型的收敛速度
2.提升模型的精度
常见的数据归一化方法
最常用的是 min-max标准化 和 z-score 标准化。
min-max标准化
是对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下:
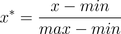
其中max为样本数据的最大值,min为样本数据的最小值。
def Normalization(x):
return [(float(i)-min(x))/float(max(x)-min(x)) for i in x]
如果想要将数据映射到[-1,1],则将公式换成:
x* = x* * 2 -1
或者进行一个近似
x* = (x - x_mean)/(x_max - x_min), x_mean表示数据的均值。
def Normalization2(x):
return [(float(i)-np.mean(x))/(max(x)-min(x)) for i in x]
这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
ps: 将数据归一化到[a,b]区间范围的方法:
(1)首先找到原本样本数据X的最小值Min及最大值Max
(2)计算系数:k=(b-a)/(Max-Min)
(3)得到归一化到[a,b]区间的数据:Y=a+k(X-Min) 或者 Y=b+k(X-Max)
即一个线性变换,在坐标上就是求直线方程,先求出系数,代入一个点对应的值(x的最大/最小就对应y的最大/最小)就ok了。
z-score 标准化(zero-mean normalization)
参考:
https://blog.csdn.net/Orange_Spotty_Cat/article/details/80312154
https://blog.csdn.net/pipisorry/article/details/52247379
log函数转换
通过以10为底的log函数转换的方法同样可以实现归一下,具体方法如下:

使用注意:max为样本数据最大值,并且所有的数据都要大于等于1。
atan函数转换
通过反正切函数也可以实现数据的归一化:

使用这个方法需要注意的是如果想映射的区间为[0,1],则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上,而并非所有数据标准化的结果都映射到[0,1]区间上。
相关文章
- mvc.net分页查询案例——DLL数据访问层(HouseDLL.cs)
- [Aaronyang] 写给自己的WPF4.5 笔记7[三巴掌-ItemsControl数据绑定详解与binding二次处理 3/3]
- java对ORACLE中的于NCHAR数据的处理,查询
- 基于 RocketMQ Connect 构建数据流转处理平台
- r 数据分组处理
- EasyNVR网页摄像机无插件H5、谷歌Chrome直播方案之使用ffmpeg保存快照数据方法与代码
- 使用Excel表格的记录单功能轻松处理工作表中数据的方法
- 大数据时代精髓-“精准”
- 读书笔记--SQL必知必会08--使用函数处理数据
- ch5-处理数据,抽取-整理-推导
- thinkphp6:自定义异常处理使统一返回json数据(thinkphp6.0.5 / php 7.4.9)
- postman:用postman实现post提交json数据(postman 7.31.1)
- Flink(29):Flink中对迟到数据的处理(Allowed Lateness 和 SideOutput)
- 48 行代码给 ABAP ALV 报表的数据行增添颜色效果
- Atitit 怎么阅读一本书 消化 分析 检索 attilax总结 1. 读书的本质 是数据的处理,大量的数据,处理能力有限的大脑2 2. ETL数据清洗转换 摘要,缩小数据规模2 2.1
- Java 大型系统高并发大数据的处理方式
- YoloV6实战:手把手教你使用Yolov6进行物体检测(附数据集)
- 不care工具,在大数据平台中Hive能自动处理SQL
- 【华为云技术分享】Spark如何与深度学习框架协作,处理非结构化数据
- Go Programming Blueprints 读书笔记(谈到了nsq/mgo处理数据持久化,可是业务逻辑不够复杂)
- 窗体和线程漫谈之工作线程怎样将数据的处理结果显示到窗体
- 一文读懂机器学习,大数据/自然语言处理/算法全有了……
- Batch Normalization的算法本质是在网络每一层的输入前增加一层BN层(也即归一化层),对数据进行归一化处理,然后再进入网络下一层,但是BN并不是简单的对数据进行求归一化,而是引入了两个参数λ和β去进行数据重构
- 【2021 年 MathorCup 高校数学建模挑战赛—赛道A二手车估价问题】2 问题一 数据预处理、特征工程及模型训练Baseline 和数据
- 2022 年度中国时序数据应用创新奖公布,涉及工业互联网、车联网等多个行业
- 【pandas】教程:1-处理什么样的数据
- 跟我一起学点数据分析 --第六天:数据可视化(seaborn部)
- 使用wget批量下载geo数据集的全部文件 linux下载geo数据 geo处理的数据不是下载原始数据 Linux如何下载ftp文件 geo ftp geo ftp下载 geo下载