
吴恩达深度学习网课 通俗版笔记——(02.改善深层神经网络)第二周 优化算法
改善深层神经网络——优化算法
前面已经学会了基本的神经网络搭建,但只有把参数调好,使各项设置更符合自己的问题,才能最大化网络性能
2.1 Mini-batch梯度下降法
在前面的梯度下降法中,使用向量化的方法对多样本进行了处理,当数据量非常大时(百万级以上),一次性迭代遍历所有训练集运算速度会很慢。

Mini-batch:将训练集分割成k个子集,在每个子集上进行梯度下降,这样每一次迭代都会进行k次梯度下降,这会使运算速度更快。

2.2 理解Mini-batch梯度下降法
普通batch的代价随迭代次数一般是下降且较为平滑,而Mini-batch一次迭代中随着每个子集的梯度下降往往会有很多噪声,一般不能单调下降。(可能第一个batch容易计算,而第二个batch不容易计算,因此会噪声抖动)
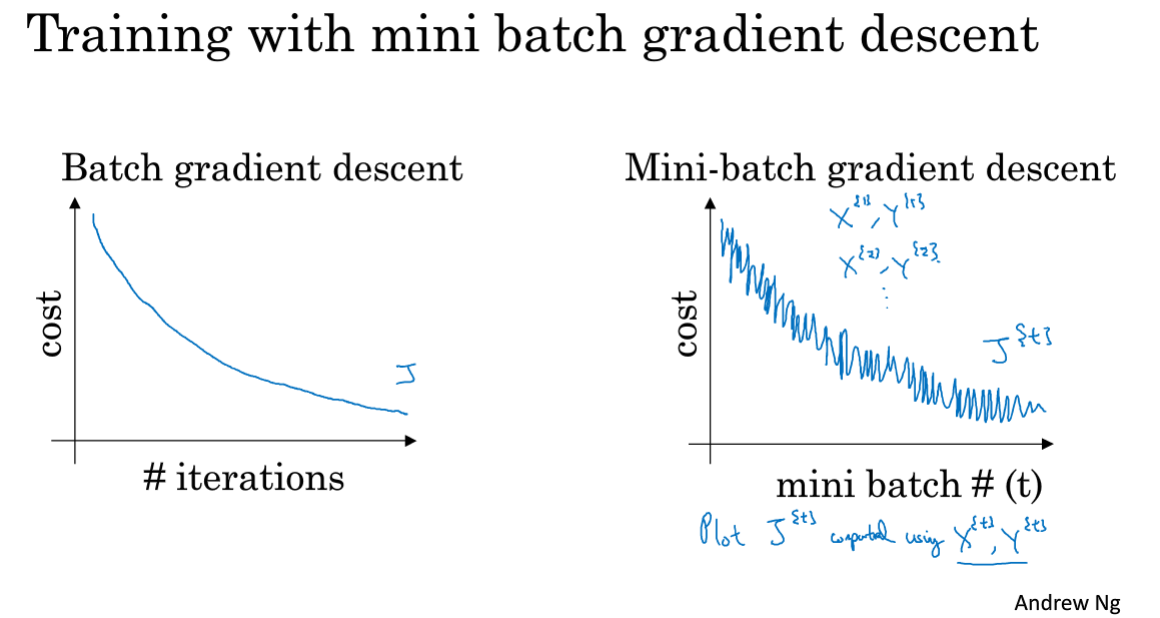
- 若Mini-batch大小选择为样本总数m,则等价于普通batch
- 若选择为1,则称之为随机梯度下降,这种方式失去了向量化的优势,每个样本都做一次梯度下降,会有很多噪声,且不能收敛
- 最好选择中间值

具体的大小选择: - 样本数较小,直接用batch梯度下降法
- 尝试2的次方数,用的比较多的是64、128、256、512
- 选择的大小至少得要电脑的CPU/GPU能接受
2.3 指数加权平均
该节用一个计算天气变化趋势的例子,给了一个指数加权平均的直观印象。通过给前一天温度和当天温度设置权重,计算每日温度的指数加权平均值。
(1-β)*当天温度可以这么理解:当天温度所占权重为1-β,则说明总天数一共有1/1-β。比如权重0.5,在说明计算的是两天的温度平均值,影响占了一半嘛。
β越大,平均的天数更多,曲线右移,且更加平坦
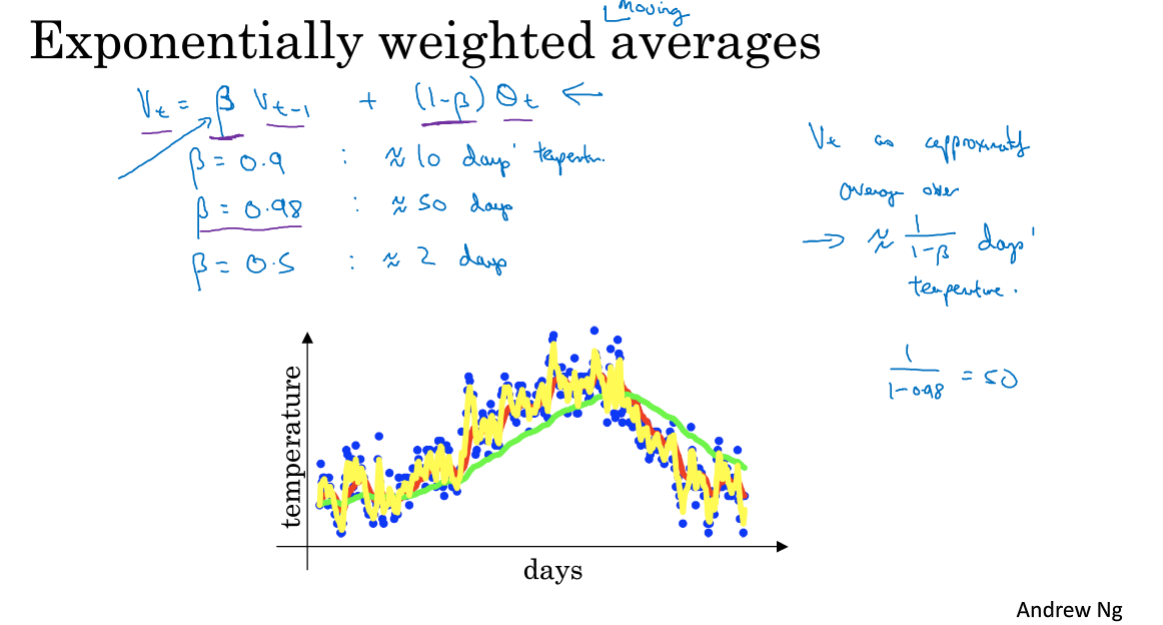
不要太细抠这一节。
2.4 理解指数加权平均
接上一节天气数据的例子,把式子倒过来写,其实是一个递归过程,用后面的项替换到前面的项。V100相当于设置一个权重衰减函数对应系数,和天气温度数据相乘再累和起来。
具体算的是多少天的平均温度就看权重的多少次方约等于1/e,和之前的1/1-β结果一致。
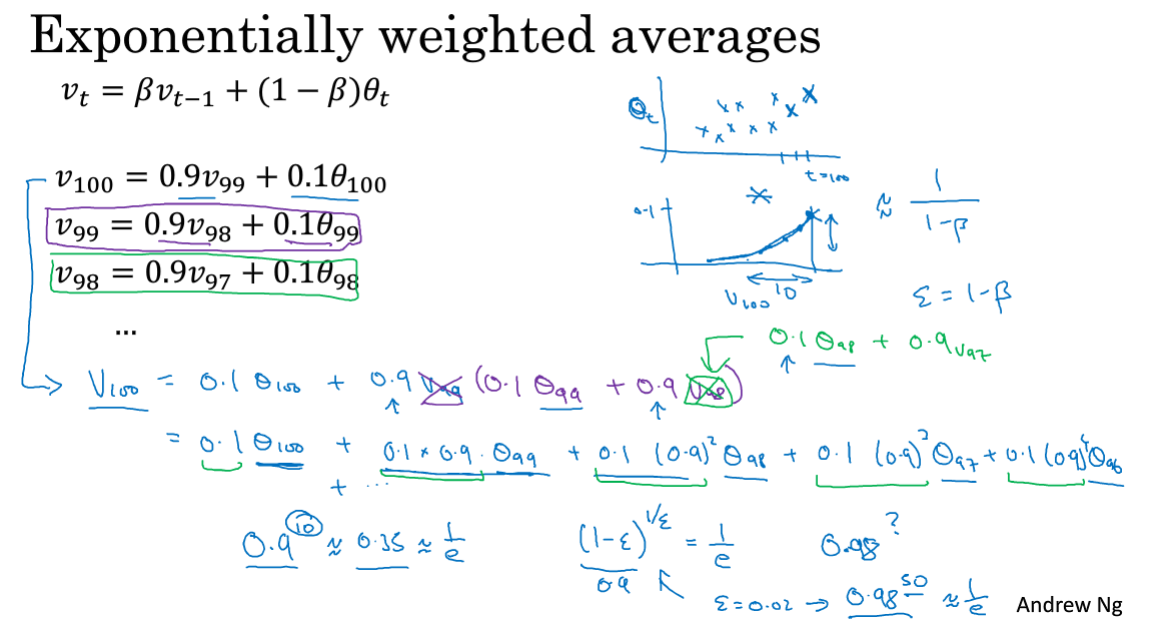
具体实现就只设置一个变量v,不断重复累和计算即可。

这节也别细抠,知道大概过程就行了。
2.5 指数加权平均的偏差修正
在指数加权平均数的计算中,初期的估测值往往不怎么准,如果对于这些值比较看重的话,可以使用偏差修正。
偏差修正就是在原来公式计算的基础上,再做一个运算,得到的值会更加准确一些。注意公式中有个t次方!
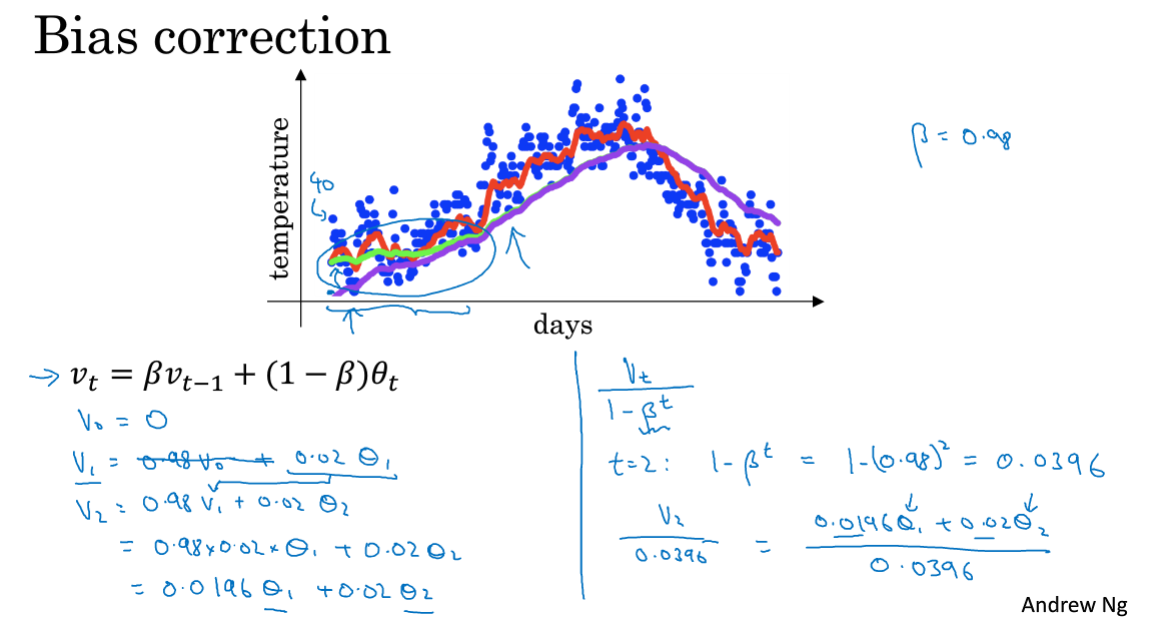
2.6 动量梯度下降法
该节介绍动量梯度下降法,这是一种比普通梯度下降法性能更好的参数更新方法,它在收敛到最小值时波动更小,且往最小值的移动速度更快。

该方法利用的是前面几节介绍的指数加权平均数的思想,计算完dw、db后进行一次加权平均后,再进行参数更新。
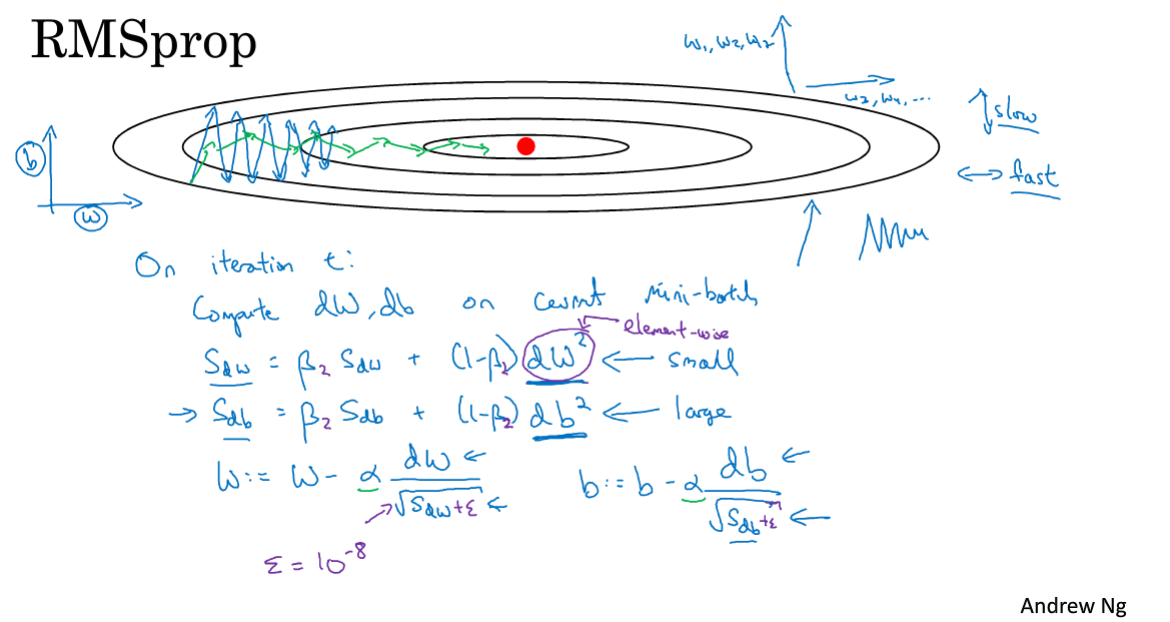
2.7 RMSprop
该节介绍RMSprop算法(root mean square),它与momentum近似,都可以加快梯度下降。
实现思路就是momentum做一点变形,目的都是为了消除原始梯度下降中的一些摆动,如下图。
2.8 Adam优化算法
该节介绍Adam优化算法,该算法是momentum和RMSprop算法的结合。

偏差修正可根据情况看是否使用,两个β区分开来,更新参数时V和S均用上。
2.9 学习率衰减
该节介绍学习率衰减,它是为了在迭代中让参数值更好地收敛到最优,加快训练速度。
每次迭代均会过一遍整个训练集,学习率衰减就是在每次迭代后都减小α的值,使下一次迭代收敛地更慢,方法如下图。
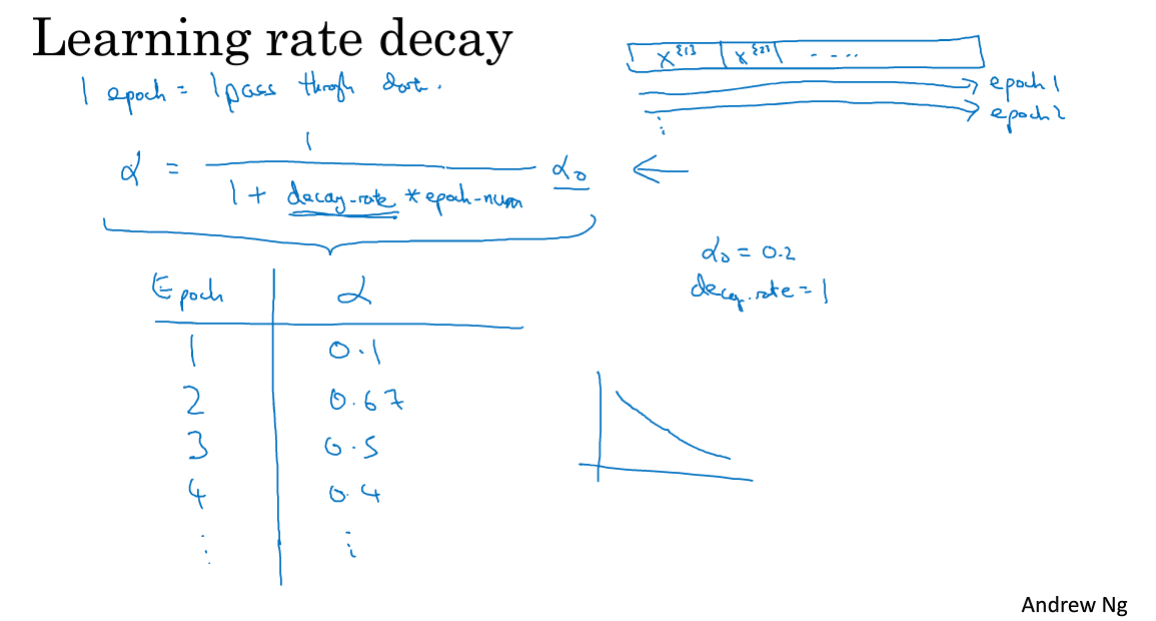
衰减公式也可以采用其他的指数衰减,平方根衰减以及手动衰减等等。

2.10 局部最优的问题
梯度为0的地方并不是局部最优点,一般称为鞍点。
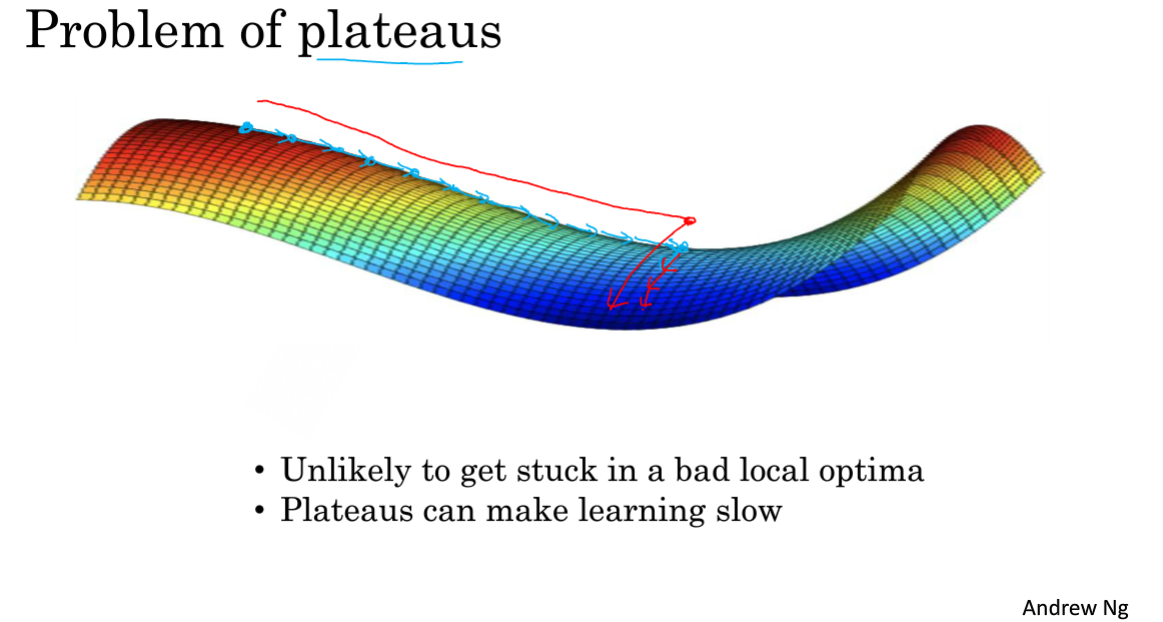
本节只需知道两个问题:
- 局部最优基本上找不到,尤其高维空间里
- 平稳段会导致学习非常慢,前面介绍的几个加快梯度下降的优化算法起作用
相关文章
- 神经网络与机器学习 笔记—LMS(最小均方算法)和学习率退火
- 算法(第四版)学习笔记之java实现希尔排序
- 数据结构(逻辑结构,物理结构,特点) C#多线程编程的同步也线程安全 C#多线程编程笔记 String 与 StringBuilder (StringBuffer) 数据结构与算法-初体验(极客专栏)
- [吴恩达机器学习笔记]16推荐系统5-6协同过滤算法/低秩矩阵分解/均值归一化
- [吴恩达机器学习笔记]16推荐系统3-4协同过滤算法
- [吴恩达机器学习笔记]15.1-3非监督学习异常检测算法/高斯回回归模型
- [DeeplearningAI笔记]卷积神经网络3.6-3.9交并比/非极大值抑制/Anchor boxes/YOLO算法
- 【TEA算法】基于FPGA的TEA算法的实现
- C#,自平衡二叉查找树(AVL Tree)的算法与源代码
- 《模式识别》学习笔记(六)聚类算法之简单聚类算法和谱系聚类算法
- 《数据挖掘:理论与算法》学习笔记(十)—推荐算法
- 《数据挖掘:理论与算法》学习笔记(二)—数据预处理(上)
- KM算法小结
- Java 并发编程学习笔记 理解CLH队列锁算法
- Memcached 笔记与总结(8)Memcached 的普通哈希分布算法和一致性哈希分布算法命中率对比
- 贪心算法之拼接最大数字问题
- python 朴素算法
- [算法课]球员组队
- 《Mahout算法解析与案例实战》一一1.3 Mahout应用
- 算法复习笔记(二)蛮力法
- 算法基础复盘笔记Day10【动态规划】—— 线性DP
- 算法基础复盘笔记Day08【数学知识】—— 质数、约数、快速幂
- 算法基础复盘笔记Day02【算法基础】—— 前缀和与差分、双指针算法、位运算、离散化、区间合并
- 华为OD机试 - 获得完美走位(JavaScript) | 机试题+算法思路+考点+代码解析 【2023】
- 惯性导航算法(八)-姿态表达式的相互转换
- 【bzoj2506】calc 根号分治+STL-vector+二分+莫队算法
- leetcode算法69.x 的平方根